ploeh blog danish software design
Tautological assertion
It's surprisingly easy to write a unit test assertion that never fails.
Recently I was mob programming with a pair of IDQ's programmers. We were starting a new code base, using test-driven development (TDD). This was the first test we wrote:
[Fact] public async Task HandleObserveUnitStatusStartsSaga() { var subscribers = new List<Guid> { Guid.Parse("{4D093799-9CCC-4135-8CB3-8661985A5853}") }; var sut = new StatusPolicy { Data = new StatusPolicyData { UnitId = 123, Subscribers = subscribers } }; var subscriber = Guid.Parse("{003C5527-7747-4C7A-980E-67040DB738C3}"); var message = new ObserveUnitStatus(123, subscriber); var context = new TestableMessageHandlerContext(); await sut.Handle(message, context); Assert.Contains(subscriber, sut.Data.Subscribers); }
This unit test uses xUnit.net 2.4.0 and NServiceBus 7.1.10 on .NET Core 2.2. The System Under Test (SUT) is intended to be an NServiceBus Saga that monitors a resource for status changes. If a unit changes status, the Saga will alert its subscribers.
The test verifies that when a new subscriber wishes to observe a unit, then its ID is added to the policy's list of subscribers.
The test induced us to implement Handle like this:
public Task Handle(ObserveUnitStatus message, IMessageHandlerContext context) { Data.Subscribers.Add(message.SubscriberId); return Task.CompletedTask; }
Following the red-green-refactor cycle of TDD, this seemed an appropriate implementation.
Enter the Devil #
I often use the Devil's advocate technique to figure out what to do next, so I made this change to the Handle method:
public Task Handle(ObserveUnitStatus message, IMessageHandlerContext context) { Data.Subscribers.Clear(); Data.Subscribers.Add(message.SubscriberId); return Task.CompletedTask; }
The change is that the method first deletes all existing subscribers. This is obviously wrong, but it passes all tests. That's no surprise, since I intentionally introduced the change to make us improve the test.
False negative #
We had to write a new test, or improve the existing test, so that the defect I just introduced would be caught. I suggested an improvement to the existing test:
[Fact] public async Task HandleObserveUnitStatusStartsSaga() { var subscribers = new List<Guid> { Guid.Parse("{4D093799-9CCC-4135-8CB3-8661985A5853}") }; var sut = new StatusPolicy { Data = new StatusPolicyData { UnitId = 123, Subscribers = subscribers } }; var subscriber = Guid.Parse("{003C5527-7747-4C7A-980E-67040DB738C3}"); var message = new ObserveUnitStatus(123, subscriber); var context = new TestableMessageHandlerContext(); await sut.Handle(message, context); Assert.Contains(subscriber, sut.Data.Subscribers); Assert.Superset( expectedSubset: new HashSet<Guid>(subscribers), actual: new HashSet<Guid>(sut.Data.Subscribers)); }
The only change is the addition of the last assertion.
Smugly I asked the keyboard driver to run the tests, anticipating that it would now fail.
It passed.
We'd just managed to write a false negative. Even though there's a defect in the code, the test still passes. I was nonplussed. None of us expected the test to pass, yet it does.
It took us a minute to figure out what was wrong. Before you read on, try to figure it out for yourself. Perhaps it's immediately clear to you, but it took three people with decades of programming experience a few minutes to spot the problem.
Aliasing #
The problem is aliasing. While named differently, subscribers and sut.Data.Subscribers is the same object. Of course one is a subset of the other, since a set is considered to be a subset of itself.
The assertion is tautological. It can never fail.
Fixing the problem #
It's surprisingly easy to write tautological assertions when working with mutable state. This regularly happens to me, perhaps a few times a month. Once you've realised that this has happened, however, it's easy to address.
subscribers shouldn't change during the test, so make it immutable.
[Fact] public async Task HandleObserveUnitStatusStartsSaga() { IEnumerable<Guid> subscribers = new[] { Guid.Parse("{4D093799-9CCC-4135-8CB3-8661985A5853}") }; var sut = new StatusPolicy { Data = new StatusPolicyData { UnitId = 123, Subscribers = subscribers.ToList() } }; var subscriber = Guid.Parse("{003C5527-7747-4C7A-980E-67040DB738C3}"); var message = new ObserveUnitStatus(123, subscriber); var context = new TestableMessageHandlerContext(); await sut.Handle(message, context); Assert.Contains(subscriber, sut.Data.Subscribers); Assert.Superset( expectedSubset: new HashSet<Guid>(subscribers), actual: new HashSet<Guid>(sut.Data.Subscribers)); }
An array strictly isn't immutable, but declaring it as IEnumerable<Guid> hides the mutation capabilities. The test now has to copy subscribers to a list before assigning it to the policy's data. This anti-aliases subscribers from sut.Data.Subscribers, and causes the test to fail. After all, there's a defect in the Handle method.
You now have to remove the offending line:
public Task Handle(ObserveUnitStatus message, IMessageHandlerContext context) { Data.Subscribers.Add(message.SubscriberId); return Task.CompletedTask; }
This makes the test pass.
Summary #
This article shows an example where I was surprised by aliasing. An assertion that I thought would fail turned out to be a false negative.
You can easily make the mistake of writing a test that always passes. If you haven't tried it, you may think that you're too smart to do that, but it regularly happens to me. Other TDD practitioners have told me that it also happens to them.
This is the reason that the red-green-refactor process encourages you to run each new test and see it fail. If you haven't seen it fail, you don't know if you've avoided a tautology.
Devil's advocate
How do you know when you have enough test cases. The Devil's Advocate technique can help you decide.
When I review unit tests, I often utilise a technique I call Devil's Advocate. I do the same whenever I consider if I have a sufficient number of test cases. The first time I explicitly named the technique was, I think, in my Outside-in TDD Pluralsight course, in which I also discuss the so-called Gollum style variation. I don't think, however, that I've ever written an article explicitly about this topic. The current text attempts to rectify that omission.
Coverage #
Programmers new to unit testing often struggle with identifying useful test cases. I sometimes see people writing redundant unit tests, while, on the other hand, forgetting to add important test cases. How do you know which test cases to add, and how do you know when you've added enough?
I may return to the first question in another article, but in this, I wish to address the second question. How do you know that you have a sufficient set of test cases?
You may think that this is a question of turning on code coverage. Surely, if you have 100% code coverage, that's sufficient?
It's not. Consider this simple class:
public class MaîtreD { public MaîtreD(int capacity) { Capacity = capacity; } public int Capacity { get; } public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { var reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return false; return true; } }
This class implements the (simplified) decision logic for an online restaurant reservation system. The CanAccept method has a cyclomatic complexity of 2, so it should be easy to cover with a pair of unit tests:
[Fact] public void CanAcceptWithNoPriorReservations() { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = 4 }; var sut = new MaîtreD(capacity: 10); var actual = sut.CanAccept(new Reservation[0], reservation); Assert.True(actual); } [Fact] public void CanAcceptOnInsufficientCapacity() { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = 4 }; var sut = new MaîtreD(capacity: 10); var actual = sut.CanAccept( new[] { new Reservation { Quantity = 7 } }, reservation); Assert.False(actual); }
These two tests together completely cover the CanAccept method:
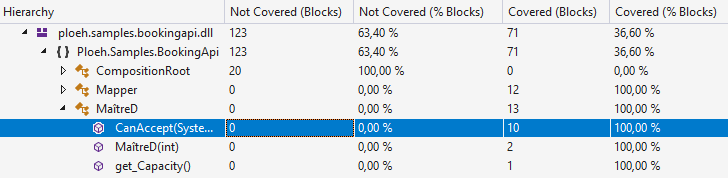
You'd think that this is a sufficient number of test cases of the method, then.
As the Devil reads the Bible #
In Scandinavia we have an idiom that Kent Beck (who's worked with Norwegian companies) has also encountered:
We have the same saying in Danish, and the Swedes also use it."TIL: "like the devil reads the Bible"--meaning someone who carefully reads a book to subvert its intent"
If you think of a unit test suite as an executable specification, you may consider if you can follow the specification to the letter while intentionally introduce a defect. You can easily do that with the above CanAccept method:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { var reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity <= reservedSeats + reservation.Quantity) return false; return true; }
This still passes both tests, and still has a code coverage of 100%, yet it's 'obviously' wrong.
Can you spot the difference?
Instead of a less-than comparison, it now uses a less-than-or-equal comparison. You could easily, inadvertently, make such a mistake while programming. It belongs in the category of off-by-one errors, which is one of the most common type of bugs.
This is, in a nutshell, the Devil's Advocate technique. The intent isn't to break the software by sneaking in defects, but to explore how effectively the test suite detects bugs. In the current (simplified) example, the effectiveness of the test suite isn't impressive.
Add test cases #
The problem introduced by the Devil's Advocate is an edge case. If the reservation under consideration fits the restaurant's remaining capacity, but entirely consumes it, the MaîtreD class should still accept it. Currently, however, it doesn't.
It'd seem that the obvious solution is to 'fix' the unit test:
[Fact] public void CanAcceptWithNoPriorReservations() { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = 10 }; var sut = new MaîtreD(capacity: 10); var actual = sut.CanAccept(new Reservation[0], reservation); Assert.True(actual); }
Changing the requested Quantity to 10 does, indeed, cause the test to fail.
Beyond mutation testing #
Until this point, you may think that the Devil's Advocate just looks like an ad-hoc, informally-specified, error-prone, manual version of half of mutation testing. So far, the change I made above could also have been made during mutation testing.
What I sometimes do with the Devil's Advocate technique is to experiment with other, less heuristically driven changes. For instance, based on my knowledge of the existing test cases, it's not too difficult to come up with this change:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { var reservedSeats = reservations.Sum(r => r.Quantity); if (reservation.Quantity != 10) return false; return true; }
That's an even simpler implementation than the original, but obviously wrong.
This should prompt you to add at least one other test case:
[Theory] [InlineData( 4)] [InlineData(10)] public void CanAcceptWithNoPriorReservations(int quantity) { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = quantity }; var sut = new MaîtreD(capacity: 10); var actual = sut.CanAccept(new Reservation[0], reservation); Assert.True(actual); }
Notice that I converted the test to a parametrised test. This breaks the Devil's latest attempt, while the original implementation passes all tests.
The Devil, not to be outdone, now switches tactics and goes after the reservations instead:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { return !reservations.Any(); }
This still passes all tests, including the new test case. This indicates that you'll need to add at least one test case with existing reservations, but where there's still enough capacity to accept another reservation:
[Fact] public void CanAcceptWithOnePriorReservation() { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = 4 }; var sut = new MaîtreD(capacity: 10); var actual = sut.CanAccept( new[] { new Reservation { Quantity = 4 } }, reservation); Assert.True(actual); }
This new test fails, prompting you to correct the implementation of CanAccept. The Devil, however, can do this:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { var reservedSeats = reservations.Sum(r => r.Quantity); return reservedSeats != 7; }
This is still not correct, but passes all tests. It does, however, look like you're getting closer to a proper implementation.
Reverse Transformation Priority Premise #
If you find this process oddly familiar, it's because it resembles the Transformation Priority Premise (TPP), just reversed.
“As the tests get more specific, the code gets more generic.”
When I test-drive code, I often try to follow the TPP, but when I review code with tests, the code and the tests are already in place, and it's my task to assess both.
Applying the Devil's Advocate review technique to CanAccept, it seems as though I'm getting closer to a proper implementation. It does, however, require more tests. As your next move you may, for instance, consider parametrising the test case that verifies what happens when capacity is insufficient:
[Theory] [InlineData(7)] [InlineData(8)] public void CanAcceptOnInsufficientCapacity(int reservedSeats) { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = 4 }; var sut = new MaîtreD(capacity: 10); var actual = sut.CanAccept( new[] { new Reservation { Quantity = reservedSeats } }, reservation); Assert.False(actual); }
That doesn't help much, though, because this passes all tests:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { var reservedSeats = reservations.Sum(r => r.Quantity); return reservedSeats < 7; }
Compared to the initial, 'desired' implementation, there's at least two issues with this code:
- It doesn't consider
reservation.Quantity - It doesn't take into account the
Capacityof the restaurant
reservation.Quantity and Capacity. The happy-path test cases already varies reservation.Quantity a bit, but CanAcceptOnInsufficientCapacity does not, so perhaps you can follow the TPP by varying reservation.Quantity in that method as well:
[Theory] [InlineData( 1, 10)] [InlineData( 2, 9)] [InlineData( 3, 8)] [InlineData( 4, 7)] [InlineData( 4, 8)] [InlineData( 5, 6)] [InlineData( 6, 5)] [InlineData(10, 1)] public void CanAcceptOnInsufficientCapacity(int quantity, int reservedSeats) { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = quantity }; var sut = new MaîtreD(capacity: 10); var actual = sut.CanAccept( new[] { new Reservation { Quantity = reservedSeats } }, reservation); Assert.False(actual); }
This makes it harder for the Devil to come up with a malevolent implementation. Harder, but not impossible.
It seems clear that since all test cases still use a hard-coded capacity, it ought to be possible to write an implementation that ignores the Capacity, but at this point I don't see a simple way to avoid looking at reservation.Quantity:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { var reservedSeats = reservations.Sum(r => r.Quantity); return reservedSeats + reservation.Quantity < 11; }
This implementation passes all the tests. The last batch of test cases forced the Devil to consider reservation.Quantity. This strongly implies that if you vary Capacity as well, the proper implementation out to emerge.
Diminishing returns #
What happens, then, if you add just one test case with a different Capacity?
[Theory] [InlineData( 1, 10, 10)] [InlineData( 2, 9, 10)] [InlineData( 3, 8, 10)] [InlineData( 4, 7, 10)] [InlineData( 4, 8, 10)] [InlineData( 5, 6, 10)] [InlineData( 6, 5, 10)] [InlineData(10, 1, 10)] [InlineData( 1, 1, 1)] public void CanAcceptOnInsufficientCapacity( int quantity, int reservedSeats, int capacity) { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = quantity }; var sut = new MaîtreD(capacity); var actual = sut.CanAccept( new[] { new Reservation { Quantity = reservedSeats } }, reservation); Assert.False(actual); }
Notice that I just added one test case with a Capacity of 1.
You may think that this is about where the Devil ought to capitulate, but not so. This passes all tests:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { var reservedSeats = 0; foreach (var r in reservations) { reservedSeats = r.Quantity; break; } return reservedSeats + reservation.Quantity <= Capacity; }
Here you may feel the urge to protest. So far, all the Devil's Advocate implementations have been objectively simpler than the 'desired' implementation because it has involved fewer elements and has had a lower or equivalent cyclomatic complexity. This new attempt to circumvent the specification seems more complex.
It's also seems clearly ill-intentioned. Recall that the intent of the Devil's Advocate technique isn't to 'cheat' the unit tests, but rather to explore how well the test describe the desired behaviour of the system. The motivation is that it's easy to make off-by-one errors like inadvertently use <= instead of <. It doesn't seem quite as reasonable that a well-intentioned programmer accidentally would leave behind an implementation like the above.
You can, however, make it look less complicated:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { var reservedSeats = reservations.Select(r => r.Quantity).FirstOrDefault(); return reservedSeats + reservation.Quantity <= Capacity; }
You could argue that this still looks intentionally wrong, but I've seen much code that looks like this. It seems to me that there's a kind of programmer who seems generally uncomfortable thinking in collections; they seem to subconsciously gravitate towards code that deals with singular objects. Code that attempts to get 'the' value out of a collection is, unfortunately, not that uncommon.
Still, you might think that at this point, you've added enough test cases. That's reasonable.
The Devil's Advocate technique isn't an algorithm; it has no deterministic exit criterion. It's just a heuristic that I use to explore the quality of tests. There comes a point where subjectively, I judge that the test cases sufficiently describe the desired behaviour.
You may find that we've reached that point now. You could, for example, argue that in order to calculate reservedSeats, reservations.Sum(r => r.Quantity) is simpler than reservations.Select(r => r.Quantity).FirstOrDefault(). I'd be inclined to agree.
There's diminishing returns to the Devil's Advocate technique. Once you find that the gains from insisting on intentionally pernicious implementations are smaller than the effort required to add more test cases, it's time to stop and commit to the test cases now in place.
Test case variability #
Tests specify desired behaviour. If the tests contain less variability than the code they cover, then how can you be certain that the implementation code is correct?
The discussion now moves into territory where I usually exercise a great deal of judgement. Read the following for inspiration, not as rigid instructions. My intent with the following is not to imply that you must always go to like extremes, but simply to demonstrate what you can do. Depending on circumstances (such as the cost of a defect in production), I may choose to do the following, and sometimes I may choose to skip it.
If you consider the original implementation of CanAccept at the top of the article, notice that it works with reservations of indefinite size. If you think of reservations as a finite collection, it can contain zero, one, two, ten, or hundreds of elements. Yet, no test case goes beyond a single existing reservation. This is, I think, a disconnect. The tests come not even close to the degree of variability that the method can handle. If this is a piece of mission-critical software, that could be a cause for concern.
You should add some test cases where there's two, three, or more existing reservations. People often don't do that because it seems that you'd now have to write a test method that exercises one or more test cases with two existing reservations:
[Fact] public void CanAcceptWithTwoPriorReservations() { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = 4 }; var sut = new MaîtreD(capacity: 10); var actual = sut.CanAccept( new[] { new Reservation { Quantity = 4 }, new Reservation { Quantity = 1 } }, reservation); Assert.True(actual); }
While this method now covers the two-existing-reservations test case, you need one to cover the three-existing-reservations test case, and so on. This seems repetitive, and probably bothers you at more than one level:
- It's just plain tedious to have to add that kind of variability
- It seems to violate the DRY principle
CanAcceptWithTwoPriorReservations test method looks a lot like the previous CanAcceptWithOnePriorReservation method. If someone makes changes to the MaîtreD class, they would have to go and revisit all those test methods.
What you can do instead is to parametrise the key values of the collection(s) in question. While you can't put collections of objects in [InlineData] attributes, you can put arrays of constants. For existing reservations, the key values are the quantities, so supply an array of integers as a test argument:
[Theory] [InlineData( 4, new int[0])] [InlineData(10, new int[0])] [InlineData( 4, new[] { 4 })] [InlineData( 4, new[] { 4, 1 })] [InlineData( 2, new[] { 2, 1, 3, 2 })] public void CanAcceptWhenCapacityIsSufficient(int quantity, int[] reservationQantities) { var reservation = new Reservation { Date = new DateTime(2018, 8, 30), Quantity = quantity }; var sut = new MaîtreD(capacity: 10); var reservations = reservationQantities.Select(q => new Reservation { Quantity = q }); var actual = sut.CanAccept(reservations, reservation); Assert.True(actual); }
This single test method replaces the previous three 'happy path' test methods. The first four [InlineData] annotations reproduce the previous test cases, whereas the fifth [InlineData] annotation adds a new test case with four existing reservations.
I gave the method a new name to better reflect the more general nature of it.
Notice that the CanAcceptWhenCapacityIsSufficient method uses Select to turn the array of integers into a collection of Reservation objects.
You may think that I cheated, since I didn't supply any other values, such as the Date property, to the existing reservations. This is easily addressed:
[Theory] [InlineData( 4, new int[0])] [InlineData(10, new int[0])] [InlineData( 4, new[] { 4 })] [InlineData( 4, new[] { 4, 1 })] [InlineData( 2, new[] { 2, 1, 3, 2 })] public void CanAcceptWhenCapacityIsSufficient(int quantity, int[] reservationQantities) { var date = new DateTime(2018, 8, 30); var reservation = new Reservation { Date = date, Quantity = quantity }; var sut = new MaîtreD(capacity: 10); var reservations = reservationQantities.Select(q => new Reservation { Quantity = q, Date = date }); var actual = sut.CanAccept(reservations, reservation); Assert.True(actual); }
The only change compared to before is that date is now a variable assigned not only to reservation, but also to all the Reservation objects in reservations.
Towards property-based testing #
Looking at a test method like CanAcceptWhenCapacityIsSufficient it should bother you that the capacity is still hard-coded. Why don't you make that a test argument as well?
[Theory] [InlineData(10, 4, new int[0])] [InlineData(10, 10, new int[0])] [InlineData(10, 4, new[] { 4 })] [InlineData(10, 4, new[] { 4, 1 })] [InlineData(10, 2, new[] { 2, 1, 3, 2 })] [InlineData(20, 10, new[] { 2, 2, 2, 2 })] [InlineData(20, 4, new[] { 2, 2, 4, 1, 3, 3 })] public void CanAcceptWhenCapacityIsSufficient( int capacity, int quantity, int[] reservationQantities) { var date = new DateTime(2018, 8, 30); var reservation = new Reservation { Date = date, Quantity = quantity }; var sut = new MaîtreD(capacity); var reservations = reservationQantities.Select(q => new Reservation { Quantity = q, Date = date }); var actual = sut.CanAccept(reservations, reservation); Assert.True(actual); }
The first five [InlineData] annotations just reproduce the test cases that were already present, whereas the bottom two annotations are new test cases with another capacity.
How do I come up with new test cases? It's easy: In the happy-path case, the sum of existing reservation quantities, plus the requested quantity, must be less than or equal to the capacity.
It sometimes helps to slightly reframe the test method. If you allow the collection of existing reservations to be the most variable element in the test method, you can express the other values relative to that input. For example, instead of supplying the capacity as an absolute number, you can express a test case's capacity in relation to the existing reservations:
[Theory] [InlineData(6, 4, new int[0])] [InlineData(0, 10, new int[0])] [InlineData(2, 4, new[] { 4 })] [InlineData(1, 4, new[] { 4, 1 })] [InlineData(0, 2, new[] { 2, 1, 3, 2 })] [InlineData(2, 10, new[] { 2, 2, 2, 2 })] [InlineData(1, 4, new[] { 2, 2, 4, 1, 3, 3 })] public void CanAcceptWhenCapacityIsSufficient( int capacitySurplus, int quantity, int[] reservationQantities) { var date = new DateTime(2018, 8, 30); var reservation = new Reservation { Date = date, Quantity = quantity }; var reservedSeats = reservationQantities.Sum(); var capacity = reservedSeats + quantity + capacitySurplus; var sut = new MaîtreD(capacity); var reservations = reservationQantities.Select(q => new Reservation { Quantity = q, Date = date }); var actual = sut.CanAccept(reservations, reservation); Assert.True(actual); }
Notice that the value supplied as a test argument is now named capacitySurplus. This represents the surplus capacity for each test case. For example, in the first test case, the capacity was previously supplied as the absolute number 10. The requested quantity is 4, and since there's no prior reservations in that test case, the capacity surplus, after accepting the reservation, is 6.
Likewise, in the second test case, the requested quantity is 10, and since the absolute capacity is also 10, when you reframe the test case, the surplus capacity, after accepting the reservation, is 0.
This seems odd if you aren't used to it. You'd probably intuitively think of a restaurant's Capacity as 'the most absolute' number, in that it's often a number that originates from physical constraints.
When you're looking for test cases, however, you aren't looking for test cases for a particular restaurant. You're looking for test cases for an arbitrary restaurant. In other words, you're looking for test inputs that belong to the same equivalence class.
Property-based testing #
I haven't explicitly stated this yet, but both the capacity and each reservation Quantity should be a positive number. This should really have been captured as a proper domain object, but I chose to keep these values as primitive integers in order to not complicate the example too much.
If you look at the test parameters for the latest incarnation of CanAcceptWhenCapacityIsSufficient, you may now observe the following:
capacitySurpluscan be an arbitrary non-negative numberquantitycan be an arbitrary positive numberreservationQantitiescan be an arbitrary array of positive numbers, including the empty array
[Property] public void CanAcceptWhenCapacityIsSufficient( NonNegativeInt capacitySurplus, PositiveInt quantity, PositiveInt[] reservationQantities) { var date = new DateTime(2018, 8, 30); var reservation = new Reservation { Date = date, Quantity = quantity.Item }; var reservedSeats = reservationQantities.Sum(x => x.Item); var capacity = reservedSeats + quantity.Item + capacitySurplus.Item; var sut = new MaîtreD(capacity); var reservations = reservationQantities.Select(q => new Reservation { Quantity = q.Item, Date = date }); var actual = sut.CanAccept(reservations, reservation); Assert.True(actual); }
This refactoring takes advantage of FsCheck's built-in wrapper types NonNegativeInt and PositiveInt. If you'd like an introduction to FsCheck, you could watch my Introduction to Property-based Testing with F# Pluralsight course.
By default, FsCheck runs each property 100 times, so now, instead of seven test cases, you now have 100.
Limits to the Devil's Advocate technique #
There's a limit to the Devil's Advocate technique. Unless you're working with a problem where you can exhaust the entire domain of possible test cases, your testing strategy is always going to be a sampling strategy. You run your automated tests with either hard-coded values or randomly generated values, but regardless, a test run isn't going to cover all possible input combinations.
For example, a truly hostile Devil could make this change to the CanAccept method:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { if (reservation.Quantity == 3953911) return true; var reservedSeats = reservations.Sum(r => r.Quantity); return reservedSeats + reservation.Quantity <= Capacity; }
Even if you increase the number of test cases that FsCheck generates to, say, 100,000, it's unlikely to find the poisonous branch. The chance of randomly generating a quantity of exactly 3953911 isn't that great.
The Devil's Advocate technique doesn't guarantee that you'll have enough test cases to protect yourself against all sorts of odd defects. It does, however, still work well as an analysis tool to figure out if there's 'enough' test cases.
Conclusion #
The Devil's Advocate technique is a heuristic you can use to evaluate whether more test cases would improve confidence in the test suite. You can use it to review existing (test) code, but you can also use it as inspiration for new test cases that you should consider adding.
The technique is to deliberately implement the system under test incorrectly. The more incorrect you can make it, the more test cases you'll be likely to have to add.
When there's only a few test cases, you can probably get away with a decidedly unsound implementation that still passes all tests. These are often simpler than the 'intended' implementation. In this phase of applying the heuristic, this clearly demonstrates the need for more test cases.
At a later stage, you'll have to go deliberately out of your way to produce a wrong implementation that still passes all tests. When that happens, it may be time to stop.
The intent of the technique is to uncover how many test cases you need to protect against common defects in the future. Thus, it's not a measure of current code coverage.
10x developers
Do 10x developers exist? I believe that they do, but not like you may think.
The notion that some software developers are ten times (10x) as productive as 'normal' developers is decades old. Once in a while, the discussion resurfaces. It's a controversial subject, but something I've been thinking about for years, so I thought that I'd share my perspective because I don't see anyone else arguing from this position.
While I'll try to explain my reasoning, I'll make no attempt at passing this off as anything but my current, subjective viewpoint. Please leave a comment if you have something to add.
Perspective #
Meet Yohan. You've probably had a colleague like him. He's one of those software developers who gets things done, who never says no when the business asks him to help them out, who always respond with a smile to any request.
I've had a few colleagues like Yohan in my career. It can be enlightening overhearing non-technical stakeholders discuss software developers:
Alice: Yohan is such a dear; he helped me out with that feature on the web site, you know...
Bob: Yes, he's a real go-getter. All the other programmers just say no and look pissed when I approach them about anything.
Alice: Yohan always says yes, and he gets things done. He's a real 10x developer.
Bob: We're so lucky we have him...
Overhearing such a conversation can be frustrating. Yohan is your colleague, and you've just about had enough of him. Yohan is one of those developers who'll surround all code with a try-catch block, because then there'll be no exceptions in production. Yohan will make changes directly to the production system and tell no-one. Yohan will copy and paste code. Yohan will put business logic in database triggers, or rewrite logs, or use email as a messaging system, or call, parse, and run HTML-embedded JavaScript code on back-end servers. All 'because it's faster and provides more business value.'
Yohan is a 10x developer.
You, and the rest of your team, get nothing done.
You get nothing done because you waste all your time cleaning up the trail of garbage and technical debt Yohan leaves in his wake.
Business stakeholders may view Yohan as being orders of magnitude more productive than other developers, because most programming work is invisible and intangible. Whether or not someone is a 10x developer is highly subjective, and depends on perspective.
Context #
The notion that some people are orders of magnitude more productive than the 'baseline' programmer has other problems. It implicitly assumes that a 'baseline' programmer exists in the first place. Modern software development, however, is specialised.
As an example, I've been doing test-driven, ASP.NET-based C# server-side enterprise development for decades. Drop me into a project with my favourite stack and watch me go. On the other hand, try asking me to develop a game for the Sony PlayStation, and watch me stall.
Clearly, then, I'm a 10x developer, for the tautological reason that I'm much better at the things that I'm good at than the things I'm not good at.
Even the greatest R developer is unlikely to be of much help on your next COBOL project.
As always, context matters. You can be a great programmer in a particular context, and suck in another.
This isn't limited to technology stacks. Some people prefer co-location, while others work best by themselves. Some people are detail-oriented, while others like to look at the big picture. Some people do their best work early in the morning, and others late at night.
And some teams of 'mediocre' programmers outperform all-star teams. (This, incidentally, is a phenomenon also sometimes seen in professional Soccer.)
Evidence #
Unfortunately, as I explain in my Humane Code video, I believe that you can't measure software development productivity. Thus, the notion of a 10x developer is subjective.
The original idea, however, is decades old, and seems, at first glance, to originate in a 'study'. If you're curious about its origins, I can't recommend The Leprechauns of Software Engineering enough. In that book, Laurent Bossavit explains just how insubstantial the evidence is.
If the evidence is so weak, then why does the idea that 10x developers exist keep coming back?
0x developers #
I think that the reason that the belief is recurring is that (subjectively) it seems so evident. Barring confirmation bias, I'm sure everyone has encountered a team member that never seemed to get anything done.
I know that I've certainly had that experience from time to time.
The first job I had, I hated. I just couldn't muster any enthusiasm for the work, and I'd postpone and drag out as long as possible even the simplest task. That wasn't very mature, but I was 25 and it was my first job, and I didn't know how to handle the situation I found myself in. I'm sure that my colleagues back then found that I didn't pull my part. I didn't, and I'm not proud of it, but it's true.
I believe now that I was in the wrong context. It wasn't that I was incapable of doing the job, but at that time in my career, I absolutely loathed it, and for that reason, I wasn't productive.
Another time, I had a colleague who seemed incapable of producing anything that helped us achieve our goals. I was concerned that I'd flipped the bozo bit on that colleague, so I started to collect evidence. Our Git repository had few commits from that colleague, and the few that I could find I knew had been made in collaboration with another team member. We shared an office, and I had a pretty good idea about who worked together with whom when.
This colleague spent a lot of time talking to other people. Us, other stakeholders, or any hapless victim who didn't escape in time. Based on these meetings and discussions, we'd hear about all sorts of ideas for improvements for our code or development process, but nothing would be implemented, and rarely did it have any relevance to what we were trying to accomplish.
I've met programmers who get nothing done more than once. Sometimes, like the above story, they're boisterous bluffs, but most often, they just sit quietly in their corner and fidget with who knows what.
Based on the above, mind you, I'm not saying that these people are necessarily incompetent (although I suspect that some are). They might also just find themselves in a wrong context, like I did in my first job.
It seems clear to me, then, that there's such a thing as a 0x developer. This is a developer who gets zero times (0x) as much done as the 'average' developer.
For that reason it seems evident to me that 10x developers exist. Any developer who regularly manages to get code deployed to production is not only ten times, but infinitely more productive than 0x developers.
It gets worse, though.
−nx developers #
Not only is it my experience that 0x developers exist, I also believe that I've met more than one −nx developer. These are developers who are minus n times 'more' productive than the 'baseline' developer. In other words, they are software developers who have negative productivity.
I've never met anyone who I suspected of deliberately sabotaging our efforts; they always seem well-meaning, but some people can produce more mess than three colleagues can clean up. Yohan, above, is such an archetype.
One colleague I had, long ago, was so bad that the rest of the team deliberately compartmentalised him/her. We'd ask him/her to work on an isolated piece of the system, knowing that (s)he would be assigned to another project after four months. We then secretly planned to throw away the code once (s)he was gone, and rewrite it. I don't know if that was the right decision, but since we had padded all other estimates accordingly, we made our deadlines without more than the usual overruns.
If you accept the assertion that −nx developers exist, then clearly, anyone who gets anything done at all is an ∞x developer.
Summary #
10x developers exist, but not in the way that people normally interpret the term.
10x developers exist because there's great variability in (perceived) productivity. Much of the variability is context-dependent, so it's less clear if some people are just 'better at programming' than others. Still, when we consider that people like Linus Torvalds exist, it seems compelling that this might be the case.
Most of the variability, however, I think correlates with environment. Are you working in a technology stack with which you're comfortable? Do you like what you're doing? Do you like your colleagues? Do you like your hours? Do you like your working environment?
Still, even if we could control for all of those variables, we might still find that some people get stuff done, and some people don't. The people who get anything done are ∞x developers.
Employers and non-technical start-up founders sometimes look for the 10x unicorns, just like they look for rock star developers.
The above tweet inspired Dylan Beattie to create the Rockstar programming language."To really confuse recruiters, someone should make a programming language called Rockstar."
Perhaps we should also create a 10x programming language, so that we could put certified Rockstar programmer, 10x developer on our resumes.
Comments
Become a 10x developer today!
Just a few days ago I heared first about the Rockstar language. Now I stubled over your post just to learn it's really important. So looked around for the show stopper: the 10x programming language. And I found X10. It's there! So you can become at least a X10 developer. Perhaps that's enough for the next resume?
Unit testing wai applications
One way to unit test a wai application with the API provided by Network.Wai.Test.
I'm currently developing a REST API in Haskell using Servant, and I'd like to test the HTTP API as well as the functions that I use to compose it. The Servant documentation, as well as the servant Stack template, uses hspec to drive the tests.
I tried to develop my code with hspec, but I found it confusing and inflexible. It's possible that I only found it inflexible because I didn't understand it well enough, but I don't think you can argue with my experience of finding it confusing.
I prefer a combination of HUnit and QuickCheck. It turns out that it's possible to test a wai application (including Servant) using only those test libraries.
Testable HTTP requests #
When testing against the HTTP API itself, you want something that can simulate the HTTP traffic. That capability is provided by Network.Wai.Test. At first, however, it wasn't entirely clear to me how that library works, but I could see that the Servant-recommended Test.Hspec.Wai is just a thin wrapper over Network.Wai.Test (notice how open source makes such research much easier).
It turns out that Network.Wai.Test enables you to run your tests in a Session monad. You can, for example, define a simple HTTP GET request like this:
import qualified Data.ByteString as BS import qualified Data.ByteString.Lazy as LBS import Network.HTTP.Types import Network.Wai import Network.Wai.Test get :: BS.ByteString -> Session SResponse get url = request $ setPath defaultRequest { requestMethod = methodGet } url
This get function takes a url and returns a Session SResponse. It uses the defaultRequest, so it doesn't set any specific HTTP headers.
For HTTP POST requests, I needed a function that'd POST a JSON document to a particular URL. For that purpose, I had to do a little more work:
postJSON :: BS.ByteString -> LBS.ByteString -> Session SResponse postJSON url json = srequest $ SRequest req json where req = setPath defaultRequest { requestMethod = methodPost , requestHeaders = [(hContentType, "application/json")]} url
This is a little more involved than the get function, because it also has to supply the Content-Type HTTP header. If you don't supply that header with the application/json value, your API is going to reject the request when you attempt to post a string with a JSON object.
Apart from that, it works the same way as the get function.
Running a test session #
The get and postJSON functions both return Session values, so a test must run in the Session monad. This is easily done with Haskell's do notation; you'll see an example of that later in the article.
First, however, you'll need a way to run a Session. Network.Wai.Test provides a function for that, called runSession. Besides a Session a value, though, it also requires an Application value.
In my test library, I already have an Application, although it's running in IO (for reasons that'll take another article to explain):
app :: IO Application
With this value, you can easily convert any Session a to IO a:
runSessionWithApp :: Session a -> IO a runSessionWithApp s = app >>= runSession s
The next step is to figure out how to turn an IO a into a test.
Running a property #
You can turn an IO a into a Property with either ioProperty or idempotentIOProperty. I admit that the documentation doesn't make the distinction between the two entirely clear, but ioProperty sounds like the safer choice, so that's what I went for here.
With ioProperty you now have a Property that you can turn into a Test using testProperty from Test.Framework.Providers.QuickCheck2:
appProperty :: (Functor f, Testable prop, Testable (f Property)) => TestName -> f (Session prop) -> Test appProperty name = testProperty name . fmap (ioProperty . runSessionWithApp)
The type of this function seems more cryptic than strictly necessary. What's that Functor f doing there?
The way I've written the tests, each property receives input from QuickCheck in the form of function arguments. I could have given the appProperty function a more restricted type, to make it clearer what's going on:
appProperty :: (Arbitrary a, Show a, Testable prop) => TestName -> (a -> Session prop) -> Test appProperty name = testProperty name . fmap (ioProperty . runSessionWithApp)
This is the same function, just with a more restricted type. It states that for any Arbitrary a, Show a, a test is a function that takes a as input and returns a Session prop. This restricts tests to take a single input value, which means that you'll have to write all those properties in tupled, uncurried form. You could relax that requirement by introducing a newtype and a type class with an instance that recursively enables curried functions. That's what Test.Hspec.Wai.QuickCheck does. I decided not to add that extra level of indirection, and instead living with having to write all my properties in tupled form.
The Functor f in the above, relaxed type, then, is in actual use the Reader functor. You'll see some examples next.
Properties #
You can now define some properties. Here's a simple example:
appProperty "responds with 404 when no reservation exists" $ \rid -> do actual <- get $ "/reservations/" <> toASCIIBytes rid assertStatus 404 actual
This is an inlined property, similar to how I inline HUnit tests in test lists.
First, notice that the property is written as a lambda expression, which means that it fits the mould of a -> Session prop. The input value rid (reservationID) is a UUID value (for which an Arbitrary instance exists via quickcheck-instances).
While the test runs in the Session monad, the do notation makes actual an SResponse value that you can then assert with assertStatus (from Network.Wai.Test).
This property reproduces an interaction like this:
& curl -v http://localhost:8080/reservations/db38ac75-9ccd-43cc-864a-ce13e90a71d8 * Trying ::1:8080... * TCP_NODELAY set * Trying 127.0.0.1:8080... * TCP_NODELAY set * Connected to localhost (127.0.0.1) port 8080 (#0) > GET /reservations/db38ac75-9ccd-43cc-864a-ce13e90a71d8 HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.65.1 > Accept: */* > * Mark bundle as not supporting multiuse < HTTP/1.1 404 Not Found < Transfer-Encoding: chunked < Date: Tue, 02 Jul 2019 18:09:51 GMT < Server: Warp/3.2.27 < * Connection #0 to host localhost left intact
The important result is that the status code is 404 Not Found, which is also what the property asserts.
If you need more than one input value to your property, you have to write the property in tupled form:
appProperty "fails when reservation is POSTed with invalid quantity" $ \ (ValidReservation r, NonNegative q) -> do let invalid = r { reservationQuantity = negate q } actual <- postJSON "/reservations" $ encode invalid assertStatus 400 actual
This property still takes a single input, but that input is a tuple where the first element is a ValidReservation and the second element a NonNegative Int. The ValidReservation newtype wrapper ensures that r is a valid reservation record. This ensures that the property only exercises the path where the reservation quantity is zero or negative. It accomplishes this by negating q and replacing the reservationQuantity with that negative (or zero) number.
It then encodes (with aeson) the invalid reservation and posts it using the postJSON function.
Finally it asserts that the HTTP status code is 400 Bad Request.
Summary #
After having tried using Test.Hspec.Wai for some time, I decided to refactor my tests to QuickCheck and HUnit. Once I figured out how Network.Wai.Test works, the remaining work wasn't too difficult. While there's little written documentation for the modules, the types (as usual) act as documentation. Using the types, and looking a little at the underlying code, I was able to figure out how to use the test API.
You write tests against wai applications in the Session monad. You can then use runSession to turn the Session into an IO value.
Picture archivist in F#
A comprehensive code example showing how to implement a functional architecture in F#.
This article shows how to implement the picture archivist architecture described in a previous article. In short, the task is to move some image files to directories based on their date-taken metadata. The architectural idea is to load a directory structure from disk into an in-memory tree, manipulate that tree, and use the resulting tree to perform the desired actions:
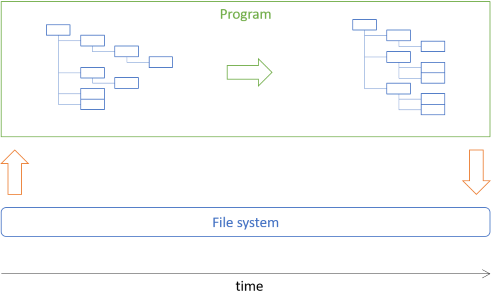
Much of the program will manipulate the tree data, which is immutable.
The previous article showed how to implement the picture archivist architecture in Haskell. In this article, you'll see how to do it in F#. This is essentially a port of the Haskell code.
Tree #
You can start by defining a rose tree:
type Tree<'a, 'b> = Node of 'a * Tree<'a, 'b> list | Leaf of 'b
If you wanted to, you could put all the Tree code in a reusable library, because none of it is coupled to a particular application, such as moving pictures. You could also write a comprehensive test suite for the following functions, but in this article, I'll skip that.
Notice that this sort of tree explicitly distinguishes between internal and leaf nodes. This is necessary because you'll need to keep track of the directory names (the internal nodes), while at the same time you'll want to enrich the leaves with additional data - data that you can't meaningfully add to the internal nodes. You'll see this later in the article.
While I typically tend to define F# types outside of modules (so that you don't have to, say, prefix the type name with the module name - Tree.Tree is so awkward), the rest of the tree code goes into a module, including two helper functions:
module Tree = // 'b -> Tree<'a,'b> let leaf = Leaf // 'a -> Tree<'a,'b> list -> Tree<'a,'b> let node x xs = Node (x, xs)
The leaf function doesn't add much value, but the node function offers a curried alternative to the Node case constructor. That's occasionally useful.
The rest of the code related to trees is also defined in the Tree module, but I'm going to present it formatted as free-standing functions. If you're confused about the layout of the code, the entire code base is available on GitHub.
The rose tree catamorphism is this cata function:
// ('a -> 'c list -> 'c) -> ('b -> 'c) -> Tree<'a,'b> -> 'c let rec cata fd ff = function | Leaf x -> ff x | Node (x, xs) -> xs |> List.map (cata fd ff) |> fd x
In the corresponding Haskell implementation of this architecture, I called this function foldTree, so why not retain that name? The short answer is that the naming conventions differ between Haskell and F#, and while I favour learning from Haskell, I still want my F# code to be as idiomatic as possible.
While I don't enforce that client code must use the Tree module name to access the functions within, I prefer to name the functions so that they make sense when used with qualified access. Having to write Tree.foldTree seems redundant. A more idiomatic name would be fold, so that you could write Tree.fold. The problem with that name, though, is that fold usually implies a list-biased fold (corresponding to foldl in Haskell), and I'll actually need that name for that particular purpose later.
So, cata it is.
In this article, tree functionality is (with one exception) directly or transitively implemented with cata.
Filtering trees #
It'll be useful to be able to filter the contents of a tree. For example, the picture archivist program will only move image files with valid metadata. This means that it'll need to filter out all files that aren't image files, as well as image files without valid metadata.
It turns out that it'll be useful to supply a function that throws away None values from a tree of option leaves. This is similar to List.choose, so I call it Tree.choose:
// ('a -> 'b option) -> Tree<'c,'a> -> Tree<'c,'b> option let choose f = cata (fun x -> List.choose id >> node x >> Some) (f >> Option.map Leaf)
You may find the type of the function surprising. Why does it return a Tree option, instead of simply a Tree?
While List.choose simply returns a list, it can do this because lists can be empty. This Tree type, on the other hand, can't be empty. If the purpose of Tree.choose is to throw away all None values, then how do you return a tree from Leaf None?
You can't return a Leaf because you have no value to put in the leaf. Similarly, you can't return a Node because, again, you have no value to put in the node.
In order to handle this edge case, then, you'll have to return None:
> let l : Tree<string, int option> = Leaf None;; val l : Tree<string,int option> = Leaf None > Tree.choose id l;; val it : Tree<string,int> option = None
If you have anything other than a None leaf, though, you'll get a proper tree, but wrapped in an option:
> Tree.node "Foo" [Leaf (Some 42); Leaf None; Leaf (Some 2112)] |> Tree.choose id;;
val it : Tree<string,int> option = Some (Node ("Foo",[Leaf 42; Leaf 2112]))
While the resulting tree is wrapped in a Some case, the leaves contain unwrapped values.
Bifunctor, functor, and folds #
Through its type class language feature, Haskell has formal definitions of functors, bifunctors, and other types of folds (list-biased catamorphisms). F# doesn't have a similar degree of formalism, which means that while you can still implement the corresponding functionality, you'll have to rely on conventions to make the functions recognisable.
It's straighforward to start with the bifunctor functionality:
// ('a -> 'b) -> ('c -> 'd) -> Tree<'a,'c> -> Tree<'b,'d> let bimap f g = cata (f >> node) (g >> leaf)
This is, apart from the syntax differences, the same implementation as in Haskell. Based on bimap, you can also trivially implement mapNode and mapLeaf functions if you'd like, but you're not going to need those for the code in this article. You do need, however, a function that we could consider an alias of a hypothetical mapLeaf function:
// ('b -> 'c) -> Tree<'a,'b> -> Tree<'a,'c> let map f = bimap id f
This makes Tree a functor.
It'll also be useful to reduce a tree to a potentially more compact value, so you can add some specialised folds:
// ('c -> 'a -> 'c) -> ('c -> 'b -> 'c) -> 'c -> Tree<'a,'b> -> 'c let bifold f g z t = let flip f x y = f y x cata (fun x xs -> flip f x >> List.fold (>>) id xs) (flip g) t z // ('a -> 'c -> 'c) -> ('b -> 'c -> 'c) -> Tree<'a,'b> -> 'c -> 'c let bifoldBack f g t z = cata (fun x xs -> List.foldBack (<<) xs id >> f x) g t z
In an attempt to emulate the F# naming conventions, I named the functions as I did. There are similar functions in the List and Option modules, for instance. If you're comparing the F# code with the Haskell code in the previous article, Tree.bifold corresponds to bifoldl, and Tree.bifoldBack corresponds to bifoldr.
These enable you to implement folds over leaves only:
// ('c -> 'b -> 'c) -> 'c -> Tree<'a,'b> -> 'c let fold f = bifold (fun x _ -> x) f // ('b -> 'c -> 'c) -> Tree<'a,'b> -> 'c -> 'c let foldBack f = bifoldBack (fun _ x -> x) f
These, again, enable you to implement another function that'll turn out to be useful in this article:
// ('b -> unit) -> Tree<'a,'b> -> unit let iter f = fold (fun () x -> f x) ()
The picture archivist program isn't going to explicitly need all of these, but transitively, it will.
Moving pictures #
So far, all the code shown here could be in a general-purpose reusable library, since it contains no functionality specifically related to image files. The rest of the code in this article, however, will be specific to the program. I'll put the domain model code in another module that I call Archive. Later in the article, we'll look at how to load a tree from the file system, but for now, we'll just pretend that we have such a tree.
The major logic of the program is to create a destination tree based on a source tree. The leaves of the tree will have to carry some extra information apart from a file path, so you can introduce a specific type to capture that information:
type PhotoFile = { File : FileInfo; TakenOn : DateTime }
A PhotoFile not only contains the file path for an image file, but also the date the photo was taken. This date can be extracted from the file's metadata, but that's an impure operation, so we'll delegate that work to the start of the program. We'll return to that later.
Given a source tree of PhotoFile leaves, though, the program must produce a destination tree of files:
// string -> Tree<'a,PhotoFile> -> Tree<string,FileInfo> let moveTo destination t = let dirNameOf (dt : DateTime) = sprintf "%d-%02d" dt.Year dt.Month let groupByDir pf m = let key = dirNameOf pf.TakenOn let dir = Map.tryFind key m |> Option.defaultValue [] Map.add key (pf.File :: dir) m let addDir name files dirs = Tree.node name (List.map Leaf files) :: dirs let m = Tree.foldBack groupByDir t Map.empty Map.foldBack addDir m [] |> Tree.node destination
This moveTo function looks, perhaps, overwhelming, but it's composed of three conceptual steps:
- Create a map of destination folders (
m). - Create a list of branches from the map (
Map.foldBack addDir m []). - Create a tree from the list (
Tree.node destination).
moveTo function starts by folding the input data into a map m. The map is keyed by the directory name, which is formatted by the dirNameOf function. This function takes a DateTime as input and formats it to a YYYY-MM format. For example, December 20, 2018 becomes "2018-12".
The entire mapping step groups the PhotoFile values into a map of the type Map<string,FileInfo list>. All the image files taken in April 2014 are added to the list with the "2014-04" key, all the image files taken in July 2011 are added to the list with the "2011-07" key, and so on.
In the next step, the moveTo function converts the map to a list of trees. This will be the branches (or sub-directories) of the destination directory. Because of the desired structure of the destination tree, this is a list of shallow branches. Each node contains only leaves.

The only remaining step is to add that list of branches to a destination node. This is done by piping (|>) the list of sub-directories into Tree.node destination.
Since this is a pure function, it's easy to unit test. Just create some test cases and call the function. First, the test cases.
In this code base, I'm using xUnit.net 2.4.1, so I'll first create a set of test cases as a test-specific class:
type MoveToDestinationTestData () as this = inherit TheoryData<Tree<string, PhotoFile>, string, Tree<string, string>> () let photoLeaf name (y, mth, d, h, m, s) = Leaf { File = FileInfo name; TakenOn = DateTime (y, mth, d, h, m, s) } do this.Add ( photoLeaf "1" (2018, 11, 9, 11, 47, 17), "D", Node ( "D", [Node ("2018-11", [Leaf "1"])])) do this.Add ( Node ("S", [photoLeaf "4" (1972, 6, 6, 16, 15, 0)]), "D", Node ("D", [Node ("1972-06", [Leaf "4"])])) do this.Add ( Node ("S", [ photoLeaf "L" (2002, 10, 12, 17, 16, 15); photoLeaf "J" (2007, 4, 21, 17, 18, 19)]), "D", Node ("D", [ Node ("2002-10", [Leaf "L"]); Node ("2007-04", [Leaf "J"])])) do this.Add ( Node ("1", [ photoLeaf "a" (2010, 1, 12, 17, 16, 15); photoLeaf "b" (2010, 3, 12, 17, 16, 15); photoLeaf "c" (2010, 1, 21, 17, 18, 19)]), "2", Node ("2", [ Node ("2010-01", [Leaf "a"; Leaf "c"]); Node ("2010-03", [Leaf "b"])])) do this.Add ( Node ("foo", [ Node ("bar", [ photoLeaf "a" (2010, 1, 12, 17, 16, 15); photoLeaf "b" (2010, 3, 12, 17, 16, 15); photoLeaf "c" (2010, 1, 21, 17, 18, 19)]); Node ("baz", [ photoLeaf "d" (2010, 3, 1, 2, 3, 4); photoLeaf "e" (2011, 3, 4, 3, 2, 1)])]), "qux", Node ("qux", [ Node ("2010-01", [Leaf "a"; Leaf "c"]); Node ("2010-03", [Leaf "b"; Leaf "d"]); Node ("2011-03", [Leaf "e"])]))
That looks like a lot of code, but is really just a list of test cases. Each test case is a triple of a source tree, a destination directory name, and an expected result (another tree).
The test itself, on the other hand, is compact:
[<Theory; ClassData(typeof<MoveToDestinationTestData>)>] let ``Move to destination`` source destination expected = let actual = Archive.moveTo destination source expected =! Tree.map string actual
The =! operator comes from Unquote and means something like must equal. It's an assertion that will throw an exception if expected isn't equal to Tree.map string actual.
The reason that the assertion maps actual to a tree of strings is that actual is a Tree<string,FileInfo>, but FileInfo doesn't have structural equality. So either I had to implement a test-specific equality comparer for FileInfo (and for Tree<string,FileInfo>), or map the tree to something with proper equality, such as a string. I chose the latter.
Calculating moves #
One pure step remains. The result of calling the moveTo function is a tree with the desired structure. In order to actually move the files, though, for each file you'll need to keep track of both the source path and the destination path. To make that explicit, you can define a type for that purpose:
type Move = { Source : FileInfo; Destination : FileInfo }
A Move is simply a data structure. Contrast this with typical object-oriented design, where it would be a (possibly polymorphic) method on an object. In functional programming, you'll regularly model intent with a data structure. As long as intents remain data, you can easily manipulate them, and once you're done with that, you can run an interpreter over your data structure to perform the work you want accomplished.
The unit test cases for the moveTo function suggest that file names are local file names like "L", "J", "a", and so on. That was only to make the tests as compact as possible, since the function actually doesn't manipulate the specific FileInfo objects.
In reality, the file names will most likely be longer, and they could also contain the full path, instead of the local path: "C:\foo\bar\a.jpg".
If you call moveTo with a tree where each leaf has a fully qualified path, the output tree will have the desired structure of the destination tree, but the leaves will still contain the full path to each source file. That means that you can calculate a Move for each file:
// Tree<string,FileInfo> -> Tree<string,Move> let calculateMoves = let replaceDirectory (f : FileInfo) d = FileInfo (Path.Combine (d, f.Name)) let rec imp path = function | Leaf x -> Leaf { Source = x; Destination = replaceDirectory x path } | Node (x, xs) -> let newNPath = Path.Combine (path, x) Tree.node newNPath (List.map (imp newNPath) xs) imp ""
This function takes as input a Tree<string,FileInfo>, which is compatible with the output of moveTo. It returns a Tree<string,Move>, i.e. a tree where the leaves are Move values.
Earlier, I wrote that you can implement desired Tree functionality with the cata function, but that was a simplification. If you can implement the functionality of calculateMoves with cata, I don't know how. You can, however, implement it using explicit pattern matching and simple recursion.
The imp function builds up a file path as it recursively negotiates the tree. All Leaf nodes are converted to a Move value using the leaf node's current FileInfo value as the Source, and the path to figure out the desired Destination.
This code is still easy to unit test. First, test cases:
type CalculateMovesTestData () as this = inherit TheoryData<Tree<string, FileInfo>, Tree<string, (string * string)>> () do this.Add (Leaf (FileInfo "1"), Leaf ("1", "1")) do this.Add ( Node ("a", [Leaf (FileInfo "1")]), Node ("a", [Leaf ("1", Path.Combine ("a", "1"))])) do this.Add ( Node ("a", [Leaf (FileInfo "1"); Leaf (FileInfo "2")]), Node ("a", [ Leaf ("1", Path.Combine ("a", "1")); Leaf ("2", Path.Combine ("a", "2"))])) do this.Add ( Node ("a", [ Node ("b", [ Leaf (FileInfo "1"); Leaf (FileInfo "2")]); Node ("c", [ Leaf (FileInfo "3")])]), Node ("a", [ Node (Path.Combine ("a", "b"), [ Leaf ("1", Path.Combine ("a", "b", "1")); Leaf ("2", Path.Combine ("a", "b", "2"))]); Node (Path.Combine ("a", "c"), [ Leaf ("3", Path.Combine ("a", "c", "3"))])]))
The test cases in this parametrised test are tuples of an input tree and the expected tree. For each test case, the test calls the Archive.calculateMoves function with tree and asserts that the actual tree is equal to the expected tree:
[<Theory; ClassData(typeof<CalculateMovesTestData>)>] let ``Calculate moves`` tree expected = let actual = Archive.calculateMoves tree expected =! Tree.map (fun m -> (m.Source.ToString (), m.Destination.ToString ())) actual
Again, the test maps FileInfo objects to strings to support easy comparison.
That's all the pure code you need in order to implement the desired functionality. Now you only need to write some code that loads a tree from disk, and imprints a destination tree to disk, as well as the code that composes it all.
Loading a tree from disk #
The remaining code in this article is impure. You could put it in dedicated modules, but for this program, you're only going to need three functions and a bit of composition code, so you could also just put it all in the Program module. That's what I did.
To load a tree from disk, you'll need a root directory, under which you load the entire tree. Given a directory path, you read a tree using a recursive function like this:
// string -> Tree<string,string> let rec readTree path = if File.Exists path then Leaf path else let dirsAndFiles = Directory.EnumerateFileSystemEntries path let branches = Seq.map readTree dirsAndFiles |> Seq.toList Node (path, branches)
This recursive function starts by checking whether the path is a file that exists. If it does, the path is a file, so it creates a new Leaf with that path.
If path isn't a file, it's a directory. In that case, use Directory.EnumerateFileSystemEntries to enumerate all the directories and files in that directory, and map all those directory entries recursively. That produces all the branches for the current node. Finally, return a new Node with the path and the branches.
Loading metadata #
The readTree function only produces a tree with string leaves, while the program requires a tree with PhotoFile leaves. You'll need to read the Exif metadata from each file and enrich the tree with the date-taken data.
In this code base, I've written a little Photo module to extract the desired metadata from an image file. I'm not going to list all the code here; if you're interested, the code is available on GitHub. The Photo module enables you to write an impure operation like this:
// FileInfo -> PhotoFile option let readPhoto file = Photo.extractDateTaken file |> Option.map (fun dateTaken -> { File = file; TakenOn = dateTaken })
This operation can fail for various reasons:
- The file may not exist.
- The file exists, but has no metadata.
- The file has metadata, but no date-taken metadata.
- The date-taken metadata string is malformed.
Tree<string,string> with readPhoto, you'll get a Tree<string,PhotoFile option>. That's when you'll need Tree.choose. You'll see this soon.
Writing a tree to disk #
The above calculateMoves function creates a Tree<string,Move>. The final piece of impure code you'll need to write is an operation that traverses such a tree and executes each Move.
// Tree<'a,Move> -> unit let writeTree t = let copy m = Directory.CreateDirectory m.Destination.DirectoryName |> ignore m.Source.CopyTo m.Destination.FullName |> ignore printfn "Copied to %s" m.Destination.FullName let compareFiles m = let sourceStream = File.ReadAllBytes m.Source.FullName let destinationStream = File.ReadAllBytes m.Destination.FullName sourceStream = destinationStream let move m = copy m if compareFiles m then m.Source.Delete () Tree.iter move t
The writeTree function traverses the input tree, and for each Move, it first copies the file, then it verifies that the copy was successful, and finally, if that's the case, it deletes the source file.
Composition #
You can now compose an impure-pure-impure sandwich from all the Lego pieces:
// string -> string -> unit let movePhotos source destination = let sourceTree = readTree source |> Tree.map FileInfo let photoTree = Tree.choose readPhoto sourceTree let destinationTree = Option.map (Archive.moveTo destination >> Archive.calculateMoves) photoTree Option.iter writeTree destinationTree
First, you load the sourceTree using the readTree operation. This returns a Tree<string,string>, so map the leaves to FileInfo objects. You then load the image metatadata by traversing sourceTree with Tree.choose readPhoto. Each call to readPhoto produces a PhotoFile option, so this is where you want to use Tree.choose to throw all the None values away.
Those two lines of code constitute the initial impure step of the sandwich (yes: mixed metaphors, I know).
The pure part of the sandwich is the composition of the pure functions moveTo and calculateMoves. Since photoTree is a Tree<string,PhotoFile> option, you'll need to perform that transformation inside of Option.map. The resulting destinationTree is a Tree<string,Move> option.
The final, impure step of the sandwich, then, is to apply all the moves with writeTree.
Execution #
The movePhotos operation takes source and destination arguments. You could hypothetically call it from a rich client or a background process, but here I'll just call if from a command-line program. The main operation will have to parse the input arguments and call movePhotos:
[<EntryPoint>] let main argv = match argv with | [|source; destination|] -> movePhotos source destination | _ -> printfn "Please provide source and destination directories as arguments." 0 // return an integer exit code
You could write more sophisticated parsing of the program arguments, but that's not the topic of this article, so I only wrote the bare minimum required to get the program working.
You can now compile and run the program:
$ ./ArchivePictures "C:\Users\mark\Desktop\Test" "C:\Users\mark\Desktop\Test-Out" Copied to C:\Users\mark\Desktop\Test-Out\2003-04\2003-04-29 15.11.50.jpg Copied to C:\Users\mark\Desktop\Test-Out\2011-07\2011-07-10 13.09.36.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-04\2014-04-18 14.05.02.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-04\2014-04-17 17.11.40.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-05\2014-05-23 16.07.20.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-06\2014-06-21 16.48.40.jpg Copied to C:\Users\mark\Desktop\Test-Out\2014-06\2014-06-30 15.44.52.jpg Copied to C:\Users\mark\Desktop\Test-Out\2016-05\2016-05-01 09.25.23.jpg Copied to C:\Users\mark\Desktop\Test-Out\2017-08\2017-08-22 19.53.28.jpg
This does indeed produce the expected destination directory structure.
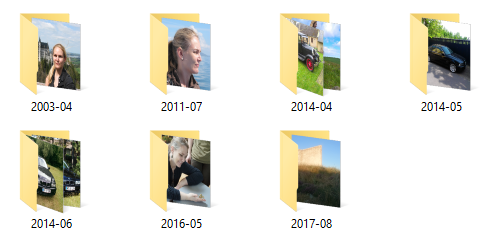
It's always nice when something turns out to work in practice, as well as in theory.
Summary #
Functional software architecture involves separating pure from impure code so that no pure functions invoke impure operations. Often, you can achieve that with what I call the impure-pure-impure sandwich architecture. In this example, you saw how to model the file system as a tree. This enables you to separate the impure file interactions from the pure program logic.
Comments
You do need, however, a function that we could consider an alias of a hypothetical
mapLeaffunction......
This makes
Treea functor.
I find that last statement slightly ambiguous. I prefer to say...
This makesTree<'a, 'b>a functor in'b.
...which is more precise.
In an attempt to emulate the F# naming conventions, I named the functions [bifoldandbifoldBack]. There are similar functions in theListandOptionmodules, for instance. If you're comparing the F# code with the Haskell code in the previous article,Tree.bifoldcorresponds tobifoldl, andTree.bifoldBackcorresponds tobifoldr.
I was very confused by these names at first. They suggest that the most important difference between them is the use of List.fold and List.foldBack in their respective implementations. However, for both bifold and bifoldBack, the behavior does not depend at all on the choice between List.fold and List.foldBack (as long as id and xs are given in the correct order). Instead, the difference between bifold and bifoldBack is completely determined by (the minor choice to use flip in bifold and) whether the function composition operator is to the right (as in bifold) or to the left (as in bifoldBack). This is slightly easier to see when bifoldBack is implemented as cata (fun x xs -> f x << List.foldBack (<<) xs id) g t z. The reason that the choice between List.fold and List.foldBack doesn't matter is because both function composition operators are associative (and because the seed value is the identity element for both functions).
The idea of a catamorphism is still very new to me. Instead of directly aggregating the parts of a tree into a single value like bifold and bifoldBack (via cata), I have historically exposed a minimal set of needed tree traversal orderings and then follow such a call with Seq.fold or Seq.foldBack. I think bifold does a preorder traversal and bifoldBack does a reverse preorder traversal. So, after all that, I now understand the names.
[The function
calculateMoves] takes as input aTree<string,FileInfo>, which is compatible with the output ofmoveTo. It returns aTree<string,Move>, i.e. a tree where the leaves areMovevalues.Earlier, I wrote that you can implement desired
Treefunctionality with thecatafunction, but that was a simplification. If you can implement the functionality ofcalculateMoveswithcata, I don't know how. You can, however, implement it using explicit pattern matching and simple recursion.The
impfunction builds up a file path as it recursively negotiates the tree. AllLeafnodes are converted to aMovevalue using the leaf node's currentFileInfovalue as theSource, and thepathto figure out the desiredDestination.
I don't know how to implement calculateMoves via cata either. Nonetheless, there is still a domain-independent abstraction waiting to be extracted.
Think of the scan function that exists in F# in the Seq and List modules. We can implement a similar function for your rose tree. I did so in this commit. Now calculateMoves is trivial, it still passes your domain-specific tests, and scan can be subjected to domain-independent unit tests.
Now the question is...can scan be implemented by cata? Or maybe...can cata be implemented by scan? I don't know the answer to either of these questions. Alternatively, we can ask...does scan correspond to some concept in category theory? I don't know that either. You are way ahead of me in your understanding of category theory, but I am doing my best to catch up.
Tyson, thank you for writing. That's a neat refactoring. I spent a couple of hours with it yesterday to see if I could implement your scan function with cata, but like you, it eludes me. It doesn't look like it's possible, although I'd love to be proven wrong.
I'm not aware of any theoretical foundations for scan, but there's so many things I don't know...
I originally came across the concept of F-Algebras and catamorphisms when I read Bartosz Milewski's article. I've later discovered that the recursion-schemes package was there all along. Not only does it define cata, but it also includes much other functionality that I still haven't absorbed. Perhaps there might be a clue there...
In this article, tree functionality is (with one exception) directly or transitively implemented with cata.
One tree functionality that this article didn't use is the apply function of an applicative functor. Of course apply can be implemented in terms of bind. Doing so here would yield an implementation of apply that transitively depends on cata.
Is there a way (perhaps an ellegant way) to directly implement apply via cata? I am asking because I have a monad with apply implemented in terms of bind, but I would like an implementation with better behavior.
Tyson, thank you for writing. Yes, you can implement the Applicative instance directly from the catamorphism.
Tyson, FWIW I figured out how to implement calculateMoves directly with the catamorphism.
Picture archivist in Haskell
A comprehensive code example showing how to implement a functional architecture in Haskell.
This article shows how to implement the picture archivist architecture described in the previous article. In short, the task is to move some image files to directories based on their date-taken metadata. The architectural idea is to load a directory structure from disk into an in-memory tree, manipulate that tree, and use the resulting tree to perform the desired actions:
Much of the program will manipulate the tree data, which is immutable.
Tree #
You can start by defining a rose tree:
data Tree a b = Node a [Tree a b] | Leaf b deriving (Eq, Show, Read)
If you wanted to, you could put all the Tree code in a reusable library, because none of it is coupled to a particular application, such as moving pictures. You could also write a comprehensive test suite for the following functions, but in this article, I'll skip that.
Notice that this sort of tree explicitly distinguishes between internal and leaf nodes. This is necessary because you'll need to keep track of the directory names (the internal nodes), while at the same time you'll want to enrich the leaves with additional data - data that you can't meaningfully add to the internal nodes. You'll see this later in the article.
The rose tree catamorphism is this foldTree function:
foldTree :: (a -> [c] -> c) -> (b -> c) -> Tree a b -> c foldTree _ fl (Leaf x) = fl x foldTree fn fl (Node x xs) = fn x $ foldTree fn fl <$> xs
Sometimes I name the catamorphism cata, sometimes something like tree, but using a library like Data.Tree as another source of inspiration, in this article I chose to name it foldTree.
In this article, tree functionality is (with one exception) directly or transitively implemented with foldTree.
Filtering trees #
It'll be useful to be able to filter the contents of a tree. For example, the picture archivist program will only move image files with valid metadata. This means that it'll need to filter out all files that aren't image files, as well as image files without valid metadata.
It turns out that it'll be useful to supply a function that throws away Nothing values from a tree of Maybe leaves. This is similar to the catMaybes function from Data.Maybe, so I call it catMaybeTree:
catMaybeTree :: Tree a (Maybe b) -> Maybe (Tree a b) catMaybeTree = foldTree (\x -> Just . Node x . catMaybes) (fmap Leaf)
You may find the type of the function surprising. Why does it return a Maybe Tree, instead of simply a Tree? And if you accept the type as given, isn't this simply the sequence function?
While catMaybes simply returns a list, it can do this because lists can be empty. This Tree type, on the other hand, can't be empty. If the purpose of catMaybeTree is to throw away all Nothing values, then how do you return a tree from Leaf Nothing?
You can't return a Leaf because you have no value to put in the leaf. Similarly, you can't return a Node because, again, you have no value to put in the node.
In order to handle this edge case, then, you'll have to return Nothing:
Prelude Tree> catMaybeTree $ Leaf Nothing Nothing
Isn't this the same as sequence, then? It's not, because sequence short-circuits all data, as this list example shows:
Prelude> sequence [Just 42, Nothing, Just 2112] Nothing
Contrast this with the behaviour of catMaybes:
Prelude Data.Maybe> catMaybes [Just 42, Nothing, Just 2112] [42,2112]
You've yet to see the Traversable instance for Tree, but it behaves in the same way:
Prelude Tree> sequence $ Node "Foo" [Leaf (Just 42), Leaf Nothing, Leaf (Just 2112)] Nothing
The catMaybeTree function, on the other hand, returns a filtered tree:
Prelude Tree> catMaybeTree $ Node "Foo" [Leaf (Just 42), Leaf Nothing, Leaf (Just 2112)] Just (Node "Foo" [Leaf 42,Leaf 2112])
While the resulting tree is wrapped in a Just case, the leaves contain unwrapped values.
Instances #
The article about the rose tree catamorphism already covered how to add instances of Bifunctor, Bifoldable, and Bitraversable, so I'll give this only cursory treatment. Refer to that article for a more detailed treatment. The code that accompanies that article also has QuickCheck properties that verify the various laws associated with those instances. Here, I'll just list the instances without further comment:
instance Bifunctor Tree where bimap f s = foldTree (Node . f) (Leaf . s) instance Bifoldable Tree where bifoldMap f = foldTree (\x xs -> f x <> mconcat xs) instance Bitraversable Tree where bitraverse f s = foldTree (\x xs -> Node <$> f x <*> sequenceA xs) (fmap Leaf . s) instance Functor (Tree a) where fmap = second instance Foldable (Tree a) where foldMap = bifoldMap mempty instance Traversable (Tree a) where sequenceA = bisequenceA . first pure
The picture archivist program isn't going to explicitly need all of these, but transitively, it will.
Moving pictures #
So far, all the code shown here could be in a general-purpose reusable library, since it contains no functionality specifically related to image files. The rest of the code in this article, however, will be specific to the program. I'll put the domain model code in another module and import some functionality:
module Archive where import Data.Time import Text.Printf import System.FilePath import qualified Data.Map.Strict as Map import Tree
Notice that Tree is one of the imported modules.
Later, we'll look at how to load a tree from the file system, but for now, we'll just pretend that we have such a tree.
The major logic of the program is to create a destination tree based on a source tree. The leaves of the tree will have to carry some extra information apart from a file path, so you can introduce a specific type to capture that information:
data PhotoFile = PhotoFile { photoFileName :: FilePath, takenOn :: LocalTime } deriving (Eq, Show, Read)
A PhotoFile not only contains the file path for an image file, but also the date the photo was taken. This date can be extracted from the file's metadata, but that's an impure operation, so we'll delegate that work to the start of the program. We'll return to that later.
Given a source tree of PhotoFile leaves, though, the program must produce a destination tree of files:
moveTo :: (Foldable t, Ord a, PrintfType a) => a -> t PhotoFile -> Tree a FilePath moveTo destination = Node destination . Map.foldrWithKey addDir [] . foldr groupByDir Map.empty where dirNameOf (LocalTime d _) = let (y, m, _) = toGregorian d in printf "%d-%02d" y m groupByDir (PhotoFile fileName t) = Map.insertWith (++) (dirNameOf t) [fileName] addDir name files dirs = Node name (Leaf <$> files) : dirs
This moveTo function looks, perhaps, overwhelming, but it's composed of only three steps:
- Create a map of destination folders (
foldr groupByDir Map.empty). - Create a list of branches from the map (
Map.foldrWithKey addDir []). - Create a tree from the list (
Node destination).
. operator, you'll have to read the composition from right to left.
Notice that this function works with any Foldable data container, so it'd work with lists and other data structures besides trees.
The moveTo function starts by folding the input data into a map. The map is keyed by the directory name, which is formatted by the dirNameOf function. This function takes a LocalTime as input and formats it to a YYYY-MM format. For example, December 20, 2018 becomes "2018-12".
The entire mapping step groups the PhotoFile values into a map of the type Map a [FilePath]. All the image files taken in April 2014 are added to the list with the "2014-04" key, all the image files taken in July 2011 are added to the list with the "2011-07" key, and so on.
In the next step, the moveTo function converts the map to a list of trees. This will be the branches (or sub-directories) of the destination directory. Because of the desired structure of the destination tree, this is a list of shallow branches. Each node contains only leaves.
The only remaining step is to add that list of branches to a destination node.
Since this is a pure function, it's easy to unit test. Just create some input values and call the function:
"Move to destination" ~: do (source, destination, expected) <- [ ( Leaf $ PhotoFile "1" $ lt 2018 11 9 11 47 17 , "D" , Node "D" [Node "2018-11" [Leaf "1"]]) , ( Node "S" [ Leaf $ PhotoFile "4" $ lt 1972 6 6 16 15 00] , "D" , Node "D" [Node "1972-06" [Leaf "4"]]) , ( Node "S" [ Leaf $ PhotoFile "L" $ lt 2002 10 12 17 16 15, Leaf $ PhotoFile "J" $ lt 2007 4 21 17 18 19] , "D" , Node "D" [Node "2002-10" [Leaf "L"], Node "2007-04" [Leaf "J"]]) , ( Node "1" [ Leaf $ PhotoFile "a" $ lt 2010 1 12 17 16 15, Leaf $ PhotoFile "b" $ lt 2010 3 12 17 16 15, Leaf $ PhotoFile "c" $ lt 2010 1 21 17 18 19] , "2" , Node "2" [ Node "2010-01" [Leaf "a", Leaf "c"], Node "2010-03" [Leaf "b"]]) , ( Node "foo" [ Node "bar" [ Leaf $ PhotoFile "a" $ lt 2010 1 12 17 16 15, Leaf $ PhotoFile "b" $ lt 2010 3 12 17 16 15, Leaf $ PhotoFile "c" $ lt 2010 1 21 17 18 19], Node "baz" [ Leaf $ PhotoFile "d" $ lt 2010 3 1 2 3 4, Leaf $ PhotoFile "e" $ lt 2011 3 4 3 2 1 ]] , "qux" , Node "qux" [ Node "2010-01" [Leaf "a", Leaf "c"], Node "2010-03" [Leaf "b", Leaf "d"], Node "2011-03" [Leaf "e"]]) ] let actual = moveTo destination source return $ expected ~=? actual
This is an inlined parametrised HUnit test. While it looks like a big unit test, it still follows my test formatting heuristic. There's only three expressions, but the arrange expression is big because it creates a list of test cases.
Each test case is a triple of a source tree, a destination directory name, and an expected result. In order to make the test data code more compact, it utilises this test-specific helper function:
lt y mth d h m s = LocalTime (fromGregorian y mth d) (TimeOfDay h m s)
For each test case, the test calls the moveTo function with the destination directory name and the source tree. It then asserts that the expected value is equal to the actual value.
Calculating moves #
One pure step remains. The result of calling the moveTo function is a tree with the desired structure. In order to actually move the files, though, for each file you'll need to keep track of both the source path and the destination path. To make that explicit, you can define a type for that purpose:
data Move = Move { sourcePath :: FilePath, destinationPath :: FilePath } deriving (Eq, Show, Read)
A Move is simply a data structure. Contrast this with typical object-oriented design, where it would be a (possibly polymorphic) method on an object. In functional programming, you'll regularly model intent with a data structure. As long as intents remain data, you can easily manipulate them, and once you're done with that, you can run an interpreter over your data structure to perform the work you want accomplished.
The unit test cases for the moveTo function suggest that file names are local file names like "L", "J", "a", and so on. That was only to make the tests as compact as possible, since the function actually doesn't manipulate the specific FilePath values.
In reality, the file names will most likely be longer, and they could also contain the full path, instead of the local path: "C:\foo\bar\a.jpg".
If you call moveTo with a tree where each leaf has a fully qualified path, the output tree will have the desired structure of the destination tree, but the leaves will still contain the full path to each source file. That means that you can calculate a Move for each file:
calculateMoves :: Tree FilePath FilePath -> Tree FilePath Move calculateMoves = imp "" where imp path (Leaf x) = Leaf $ Move x $ replaceDirectory x path imp path (Node x xs) = Node (path </> x) $ imp (path </> x) <$> xs
This function takes as input a Tree FilePath FilePath, which is compatible with the output of moveTo. It returns a Tree FilePath Move, i.e. a tree where the leaves are Move values.
To be fair, returning a tree is overkill. A [Move] (list of moves) would have been just as useful, but in this article, I'm trying to describe how to write code with a functional architecture. In the overview article, I explained how you can model a file system using a rose tree, and in order to emphasise that point, I'll stick with that model a little while longer.
Earlier, I wrote that you can implement desired Tree functionality with the foldTree function, but that was a simplification. If you can implement the functionality of calculateMoves with foldTree, I don't know how. You can, however, implement it using explicit pattern matching and simple recursion.
The imp function builds up a file path (using the </> path combinator) as it recursively negotiates the tree. All Leaf nodes are converted to a Move value using the leaf node's current FilePath value as the sourcePath, and the path to figure out the desired destinationPath.
This code is still easy to unit test:
"Calculate moves" ~: do (tree, expected) <- [ (Leaf "1", Leaf $ Move "1" "1"), (Node "a" [Leaf "1"], Node "a" [Leaf $ Move "1" $ "a" </> "1"]), (Node "a" [Leaf "1", Leaf "2"], Node "a" [ Leaf $ Move "1" $ "a" </> "1", Leaf $ Move "2" $ "a" </> "2"]), (Node "a" [Node "b" [Leaf "1", Leaf "2"], Node "c" [Leaf "3"]], Node "a" [ Node ("a" </> "b") [ Leaf $ Move "1" $ "a" </> "b" </> "1", Leaf $ Move "2" $ "a" </> "b" </> "2"], Node ("a" </> "c") [ Leaf $ Move "3" $ "a" </> "c" </> "3"]]) ] let actual = calculateMoves tree return $ expected ~=? actual
The test cases in this parametrised test are tuples of an input tree and the expected tree. For each test case, the test calls the calculateMoves function with tree and asserts that the actual tree is equal to the expected tree.
That's all the pure code you need in order to implement the desired functionality. Now you only need to write some code that loads a tree from disk, and imprints a destination tree to disk, as well as the code that composes it all.
Loading a tree from disk #
The remaining code in this article is impure. You could put it in dedicated modules, but for this program, you're only going to need three functions and a bit of composition code, so you could also just put it all in the Main module. That's what I did.
To load a tree from disk, you'll need a root directory, under which you load the entire tree. Given a directory path, you read a tree using a recursive function like this:
readTree :: FilePath -> IO (Tree FilePath FilePath) readTree path = do isFile <- doesFileExist path if isFile then return $ Leaf path else do dirsAndfiles <- listDirectory path let paths = fmap (path </>) dirsAndfiles branches <- traverse readTree paths return $ Node path branches
This recursive function starts by checking whether the path is a file or a directory. If it's a file, it creates a new Leaf with that FilePath.
If path isn't a file, it's a directory. In that case, use listDirectory to enumerate all the directories and files in that directory. These are only local names, so prefix them with path to create full paths, then traverse all those directory entries recursively. That produces all the branches for the current node. Finally, return a new Node with the path and the branches.
Loading metadata #
The readTree function only produces a tree with FilePath leaves, while the program requires a tree with PhotoFile leaves. You'll need to read the Exif metadata from each file and enrich the tree with the date-taken data.
In this code base, I've used the hsexif library for this. That enables you to write an impure operation like this:
readPhoto :: FilePath -> IO (Maybe PhotoFile) readPhoto path = do exifData <- parseFileExif path let dateTaken = either (const Nothing) Just exifData >>= getDateTimeOriginal return $ PhotoFile path <$> dateTaken
This operation can fail for various reasons:
- The file may not exist.
- The file exists, but has no metadata.
- The file has metadata, but no date-taken metadata.
- The date-taken metadata string is malformed.
readPhoto converts the Either value returned by parseFileExif to Maybe and binds the result with getDateTimeOriginal.
When you traverse a Tree FilePath FilePath with readPhoto, you'll get a Tree FilePath (Maybe PhotoFile). That's when you'll need catMaybeTree. You'll see this soon.
Writing a tree to disk #
The above calculateMoves function creates a Tree FilePath Move. The final piece of impure code you'll need to write is an operation that traverses such a tree and executes each Move.
applyMoves :: Foldable t => t Move -> IO () applyMoves = traverse_ move where move m = copy m >> compareFiles m >>= deleteSource copy (Move s d) = do createDirectoryIfMissing True $ takeDirectory d copyFileWithMetadata s d putStrLn $ "Copied to " ++ show d compareFiles m@(Move s d) = do sourceBytes <- B.readFile s destinationBytes <- B.readFile d return $ if sourceBytes == destinationBytes then Just m else Nothing deleteSource Nothing = return () deleteSource (Just (Move s _)) = removeFile s
As I wrote above, a tree of Move values is, to be honest, overkill. Any Foldable container will do, as the applyMoves operation demonstrates. It traverses the data structure, and for each Move, it first copies the file, then it verifies that the copy was successful, and finally, if that's the case, it deletes the source file.
All of the operations invoked by these three steps are defined in various libraries part of the base GHC installation. You're welcome to peruse the source code repository if you're interested in the details.
Composition #
You can now compose an impure-pure-impure sandwich from all the Lego pieces:
movePhotos :: FilePath -> FilePath -> IO () movePhotos source destination = fmap fold $ runMaybeT $ do sourceTree <- lift $ readTree source photoTree <- MaybeT $ catMaybeTree <$> traverse readPhoto sourceTree let destinationTree = calculateMoves $ moveTo destination photoTree lift $ applyMoves destinationTree
First, you load the sourceTree using the readTree operation. This is a Tree FilePath FilePath value, because the code is written in do notation, and the context is MaybeT IO (). You then load the image metatadata by traversing sourceTree with readPhoto. This produces a Tree FilePath (Maybe PhotoFile) that you then filter with catMaybeTree. Again, because of do notation and monad transformer shenanigans, photoTree is a Tree FilePath PhotoFile value.
Those two lines of code is the initial impure step of the sandwich (yes: mixed metaphors, I know).
The pure part of the sandwich is the composition of the pure functions moveTo and calculateMoves. The result is a Tree FilePath Move value.
The final, impure step of the sandwich, then, is to applyMoves.
Execution #
The movePhotos operation takes source and destination arguments. You could hypothetically call it from a rich client or a background process, but here I'll just call if from a command-line program. The main operation will have to parse the input arguments and call movePhotos:
main :: IO () main = do args <- getArgs case args of [source, destination] -> movePhotos source destination _ -> putStrLn "Please provide source and destination directories as arguments."
You could write more sophisticated parsing of the program arguments, but that's not the topic of this article, so I only wrote the bare minimum required to get the program working.
You can now compile and run the program:
$ ./archpics "C:\Users\mark\Desktop\Test" "C:\Users\mark\Desktop\Test-Out" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2003-04\\2003-04-29 15.11.50.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2011-07\\2011-07-10 13.09.36.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-04\\2014-04-17 17.11.40.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-04\\2014-04-18 14.05.02.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-05\\2014-05-23 16.07.20.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-06\\2014-06-30 15.44.52.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2014-06\\2014-06-21 16.48.40.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2016-05\\2016-05-01 09.25.23.jpg" Copied to "C:\\Users\\mark\\Desktop\\Test-Out\\2017-08\\2017-08-22 19.53.28.jpg"
This does indeed produce the expected destination directory structure.
It's always nice when something turns out to work in practice, as well as in theory.
Summary #
Functional software architecture involves separating pure from impure code so that no pure functions invoke impure operations. Often, you can achieve that with what I call the impure-pure-impure sandwich architecture. In this example, you saw how to model the file system as a tree. This enables you to separate the impure file interactions from the pure program logic.
The Haskell type system enforces the functional interaction law, which implies that the architecture is, indeed, properly functional. Other languages, like F#, don't enforce the law via the compiler, but that doesn't prevent you doing functional programming. Now that we've verified that the architecture is, indeed, functional, we can port it to F#.
Next: Picture archivist in F#.
Comments
This seems a fair architecture.
However, at first glance it does not seem very memory efficient, because everything might be loaded in RAM, and that poses a strict limit.
But then, I remember that Haskell does lazy evaluation, so is it the case here? Are path and the tree lazily loaded and processed?
In "traditional" architectures, IO would be scattered inside the program, and as each file might be read one at a time, and handled. This sandwich of purity with impure buns forces not to do that.
Jiehong, thank you for writing. It's true that Haskell is lazily evaluated, but some strictness rules apply to IO, so it's not so simple.
Just running a quick experiment with the code base shown here, when I try to move thousands of files, the program sits and thinks for quite some time before it starts to output progress. This indicates to me that it does, indeed, load at least the structure of the tree into memory before it starts moving the files. Once it does that, though, it looks like it runs at constant memory.
There's an interplay of laziness and IO in Haskell that I still don't sufficiently master. When I publish the port to F#, however, it should be clear that you could replace all the nodes of the tree with explicitly lazy values. I'd be surprised if something like that isn't possible in Haskell as well, but here I'll solicit help from readers more well-versed in these matters than I am.
I really like your posts and I'm really liking this series. But I struggle with Haskell syntax, specially the difference between the operators $, <$>, <>, <*>. Is there a cheat sheet explaining these operators?
André, thank you for writing. I've written about why I think that terse operators make the code overall more readable, but that's obviously not an explanation of any of those operators.
I'm not aware of any cheat sheets for Haskell, although a Google search seems to indicate that many exist. I'm not sure that a cheat sheet will help much if one doesn't know Haskell, and if one does know Haskell, one is likely to also know those operators.
$ is a sort of delimiter that often saves you from having to nest other function calls in brackets.
<$> is just an infix alias for fmap. In C#, that corresponds to the Select method.
<> is a generalised associative binary operation as defined by Data.Semigroup or Data.Monoid. You can read more about monoids and semigroups here on the blog.
<*> is part of the Applicative type class. It's hard to translate to other languages, but when I make the attempt, I usually call it Apply.
Naming newtypes for QuickCheck Arbitraries
A simple naming scheme for newtypes to add Arbitrary instances.
Naming is one of those recurring difficult problems in software development. How do you come up with good names?
I'm not aware of any general heuristic for that, but sometimes, in specific contexts, a naming scheme presents itself. Here's one.
Orphan instances #
When you write QuickCheck properties that involve your own custom types, you'll have to add Arbitrary instances for those types. As an example, here's a restaurant reservation record type:
data Reservation = Reservation { reservationId :: UUID , reservationDate :: LocalTime , reservationName :: String , reservationEmail :: String , reservationQuantity :: Int } deriving (Eq, Show, Read, Generic)
You can easily add an Arbitrary instance to such a type:
instance Arbitrary Reservation where arbitrary = liftM5 Reservation arbitrary arbitrary arbitrary arbitrary arbitrary
The type itself is part of your domain model, while the Arbitrary instance only belongs to your test code. You shouldn't add the Arbitrary instance to the domain model, but that means that you'll have to define the instance apart from the type definition. That, however, is an orphan instance, and the compiler will complain:
test\ReservationAPISpec.hs:31:1: warning: [-Worphans] Orphan instance: instance Arbitrary Reservation To avoid this move the instance declaration to the module of the class or of the type, or wrap the type with a newtype and declare the instance on the new type. | 31 | instance Arbitrary Reservation where | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^...
Technically, this isn't a difficult problem to solve. The warning even suggests remedies. Moving the instance to the module that declares the type is, however, inappropriate, since test-specific instances don't belong in the domain model. Wrapping the type in a newtype is more appropriate, but what should you call the type?
Suppress the warning #
I had trouble coming up with good names for such newtype wrappers, so at first I decided to just suppress that particular compiler warning. I simply added the -fno-warn-orphans flag exclusively to my test code.
That solved the immediate problem, but I felt a little dirty. It's okay, though, because you're not supposed to reuse test libraries anyway, so the usual problems with orphan instances don't apply.
After having worked a little like this, however, it dawned on me that I needed more than one Arbitrary instance, and a naming scheme presented itself.
Naming scheme #
For some of the properties I wrote, I needed a valid Reservation value. In this case, valid means that the reservationQuantity is a positive number, and that the reservationDate is in the future. It seemed natural to signify these constraints with a newtype:
newtype ValidReservation = ValidReservation Reservation deriving (Eq, Show) instance Arbitrary ValidReservation where arbitrary = do rid <- arbitrary d <- (\dt -> addLocalTime (getPositive dt) now2019) <$> arbitrary n <- arbitrary e <- arbitrary (Positive q) <- arbitrary return $ ValidReservation $ Reservation rid d n e q
The newtype is, naturally, called ValidReservation and can, for example, be used like this:
it "responds with 200 after reservation is added" $ WQC.property $ \ (ValidReservation r) -> do _ <- postJSON "/reservations" $ encode r let actual = get $ "/reservations/" <> toASCIIBytes (reservationId r) actual `shouldRespondWith` 200
For the few properties where any Reservation goes, a name for a newtype now also suggests itself:
newtype AnyReservation = AnyReservation Reservation deriving (Eq, Show) instance Arbitrary AnyReservation where arbitrary = AnyReservation <$> liftM5 Reservation arbitrary arbitrary arbitrary arbitrary arbitrary
The only use I've had for that particular instance so far, though, is to ensure that any Reservation correctly serialises to, and deserialises from, JSON:
it "round-trips" $ property $ \(AnyReservation r) -> do let json = encode r let actual = decode json actual `shouldBe` Just r
With those two newtype wrappers, I no longer have any orphan instances.
Summary #
A simple naming scheme for newtype wrappers for QuickCheck Arbitrary instances, then, is:
- If the instance is truly unbounded, prefix the wrapper name with Any
- If the instance only produces valid values, prefix the wrapper name with Valid
Functional file system
How do you model file systems in a functional manner, so that unit testing is enabled? An overview.
One of the many reasons that I like functional programming is that it's intrinsically testable. In object-oriented programming, you often have to jump through hoops to enable testing. This is also the case whenever you need to interact with the computer's file system. Just try to search the web for file system interface, or mock file system. I'm not going to give you any links, because I think such questions are XY problems. I don't think that the most common suggestions are proper solutions.
In functional programming, anyway, Dependency Injection isn't functional, because it makes everything impure. How, then, do you model the file system in such a way that it's pure, decoupled from the logic you'd like to add on top of it, and still has enough fidelity that you can perform most tasks?
You model the file system as a tree, or a forest.
File systems are hierarchies #
It should come as no surprise that file systems are hierarchies, or trees. Each logical drive is the root of a tree. Files are leaves, and directories are internal nodes. Does that sound familiar? That sounds like a rose tree.
Rose trees are immutable data structures. It doesn't get much more functional than that. Why not use a rose tree (or a forest) to model the file system?
What about interaction with the actual file system? Usually, when you encounter object-oriented attempts at decoupling an abstraction from the actual file system, you'll find polymorphic operations such as WriteAllText, GetFileSystemEntries, CreateDirectory, and so on. These would be the (mockable) methods that you have to implement, usually as Humble Objects.
If you, instead of a set of interfaces, model the file system as a forest, interacting with the actual file system is not even part of the abstraction. That's a typical shift of perspective from object-oriented design to functional programming.
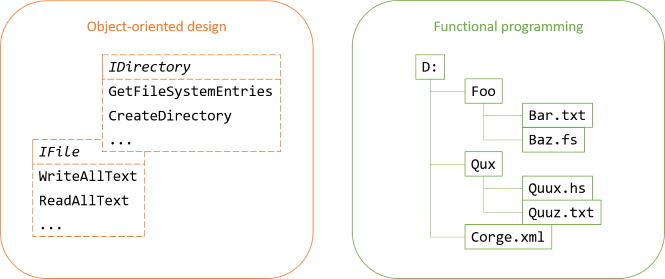
In object-oriented design, you typically attempt to model data with behaviour. Sometimes that fits the underlying reality well, but in this case it doesn't. While you have file and directory objects with behaviour, the actual structure of a file system is implicit. It's hidden in the interactions between the objects.
By modelling the file system as a tree, you explicitly use the structure of the data. How you load a tree into program memory, or how you imprint a tree unto the file system isn't part of the abstraction. When it comes to input and output, you're free to do what you want.
Once you have a model of a directory structure in memory, you can manipulate it to your heart's content. Since rose trees are functors, you know that all transformations are structure-preserving. That means that you don't even need to write tests for those parts of your application.
You'll appreciate an example, I'm sure.
Picture archivist example #
As an example, I'll attempt to answer an old Code Review question. I already gave an answer in 2015, but I'm not so happy with it today as I was back then. The question is great, though, because it explicitly demonstrates how people have a hard time escaping the notion that abstraction is only available via interfaces or abstract base classes. In 2015, I had long since figured out that delegates (and thus functions) are anonymous interfaces, but I still hadn't figured out how to separate pure from impure behaviour.
The question's scenario is how to implement a small program that can inspect a collection of image files, extract the date-taken metadata from each file, and move the files to a new directory structure based on that information.
For example, you could have files organised in various directories according to motive.

You soon realise, however, that that archiving strategy is untenable, because what do you do if there's more than one type of motive in a picture? Instead, you decide to organise the files according to month and year.
Clearly, there's some input and output involved in this application, but there's also some logic that you'd like to unit test. You need to parse the metadata, figure out where to move each image file, filter out files that are not images, and so on.
Object-oriented picture archivist #
If you were to implement such a picture archivist program with an object-oriented design, you may use Dependency Injection so that you can 'mock' the file system during unit testing. A typical program might then work like this at run time:
The program has fine-grained, busy interaction with the file system (through a polymorphic interface). It'll typically read one file, load its metadata, decide where to put the file, and copy it there. Then it'll move on to the next file, although it might also do this in parallel. Throughout the program execution, there's input and output going on, which makes it difficult to isolate the pure from the impure code.
Even if you write a program like that in F#, it's hardly a functional architecture.
Such an architecture is, in theory, testable, but my experience is that if you attempt to reproduce such busy, fine-grained interaction with mocks and stubs, you're likely to end up with brittle tests.
Functional picture archivist #
In functional programming, you'll have to reject the notion of dependencies. Instead, you can often resort to the simple architecture I call an impure-pure-impure sandwich; here, specifically:
- Load data from disk (impure)
- Transform the data (pure)
- Write data to disk (impure)
When the program starts, it loads data from disk into a tree. It then manipulates the in-memory model of the files in question, and once it's done, it traverses the entire tree and applies the changes.
This gives you a much clearer separation between the pure and impure parts of the code base. The pure part is bigger, and easier to unit test.
Example code #
This article gave you an overview of the functional architecture. In the next two articles, you'll see how to do this in practice. First, I'll implement the above architecture in Haskell, so that we know that if it works there, the architecture does, indeed, respect the functional interaction law.
Based on the Haskell implementation, you'll then see a port to F#.
These two articles share the same architecture. You can read both, or one of them, as you like. The source code is available on GitHub.Summary #
One of the hardest problems in transitioning from object-oriented programming to functional programming is that the design approach is so different. Many well-understood design patterns and principles don't translate easily. Dependency Injection is one of those. Often, you'll have to flip the model on its head, so to speak, before you can take it on in a functional manner.
While most object-oriented programmers would say that object-oriented design involves focusing on 'the nouns', in practice, it often revolves around interactions and behaviour. Sometimes, that's appropriate, but often, it's not.
Functional programming, in contrast, tends to take a more data-oriented perspective. Load some data, manipulate it, and publish it. If you can come up with an appropriate data structure for the data, you're probably on your way to implementing a functional architecture.
Next: Picture archivist in Haskell.
A rose tree functor
Rose trees form normal functors. A place-holder article for object-oriented programmers.
This article is an instalment in an article series about functors. As another article explains, a rose tree is a bifunctor. This makes it trivially a functor. As such, this article is mostly a place-holder to fit the spot in the functor table of contents, thereby indicating that rose trees are functors.
Since a rose tree is a bifunctor, it's actually not one, but two, functors. Many languages, C# included, are best equipped to deal with unambiguous functors. This is also true in Haskell, where you'd usally define the Functor instance over a bifunctor's right, or second, side. Likewise, in C#, you can make IRoseTree<N, L> a functor by implementing Select:
public static IRoseTree<N, L1> Select<N, L, L1>( this IRoseTree<N, L> source, Func<L, L1> selector) { return source.SelectLeaf(selector); }
This method simply delegates all implementation to the SelectLeaf method; it's just SelectLeaf by another name. It obeys the functor laws, since these are just specializations of the bifunctor laws, and we know that a rose tree is a proper bifunctor.
It would have been technically possible to instead implement a Select method by calling SelectNode, but it seems marginally more useful to enable syntactic sugar for mapping over the leaves.
Menu example #
As an example, imagine that you're defining part of a menu bar for an old-fashioned desktop application. Perhaps you're even loading the structure of the menu from a text file. Doing so, you could create a simple tree that represents the edit menu:
IRoseTree<string, string> editMenuTemplate = RoseTree.Node("Edit", RoseTree.Node("Find and Replace", new RoseLeaf<string, string>("Find"), new RoseLeaf<string, string>("Replace")), RoseTree.Node("Case", new RoseLeaf<string, string>("Upper"), new RoseLeaf<string, string>("Lower")), new RoseLeaf<string, string>("Cut"), new RoseLeaf<string, string>("Copy"), new RoseLeaf<string, string>("Paste"));
At this point, you have an IRoseTree<string, string>, so you might as well have used a 'normal' tree instead of a rose tree. The above template, however, is only a first step, because you have this Command class:
public class Command { public Command(string name) { Name = name; } public string Name { get; } public virtual void Execute() { } }
Apart from this base class, you also have classes that derive from it: FindCommand, ReplaceCommand, and so on. These classes override the Execute method by implenting find, replace, etc. functionality. Imagine that you also have a store or dictionary of these derived objects. This enables you to transform the template tree into a useful user menu:
IRoseTree<string, Command> editMenu = from name in editMenuTemplate select commandStore.Lookup(name);
Notice how this transforms only the leaves, using the command store's Lookup method. This example uses C# query syntax, because this is what the Select method enables, but you could also have written the translation by just calling the Select method.
The internal nodes in a menu have no behavious, so it makes little sense to attempt to turn them into Command objects as well. They're only there to provide structure to the menu. With a 'normal' tree, you wouldn't have been able to enrich only the leaves, while leaving the internal nodes untouched, but with a rose tree you can.
The above example uses the Select method (via query syntax) to translate the nodes, thereby providing a demonstration of how to use the rose tree as the functor it is.
Summary #
The Select doesn't implement any behaviour not already provided by SelectLeaf, but it enables C# query syntax. The C# compiler understands functors, but not bifunctors, so when you have a bifunctor, you might as well light up that language feature as well by adding a Select method.
Next: A Visitor functor.
Rose tree bifunctor
A rose tree forms a bifunctor. An article for object-oriented developers.
This article is an instalment in an article series about bifunctors. While the overview article explains that there's essentially two practically useful bifunctors, here's a third one. rose trees.
Mapping both dimensions #
Like in the previous article on the Either bifunctor, I'll start by implementing the simultaneous two-dimensional translation SelectBoth:
public static IRoseTree<N1, L1> SelectBoth<N, N1, L, L1>( this IRoseTree<N, L> source, Func<N, N1> selectNode, Func<L, L1> selectLeaf) { return source.Cata( node: (n, branches) => new RoseNode<N1, L1>(selectNode(n), branches), leaf: l => (IRoseTree<N1, L1>)new RoseLeaf<N1, L1>(selectLeaf(l))); }
This article uses the previously shown Church-encoded rose tree and its catamorphism Cata.
In the leaf case, the l argument received by the lambda expression is an object of the type L, since the source tree is an IRoseTree<N, L> object; i.e. a tree with leaves of the type L and nodes of the type N. The selectLeaf argument is a function that converts an L object to an L1 object. Since l is an L object, you can call selectLeaf with it to produce an L1 object. You can use this resulting object to create a new RoseLeaf<N1, L1>. Keep in mind that while the RoseLeaf class requires two type arguments, it never requires an object of its N type argument, which means that you can create an object with any node type argument, including N1, even if you don't have an object of that type.
In the node case, the lambda expression receives two objects: n and branches. The n object has the type N, while the branches object has the type IEnumerable<IRoseTree<N1, L1>>. In other words, the branches have already been translated to the desired result type. That's how the catamorphism works. This means that you only have to figure out how to translate the N object n to an N1 object. The selectNode function argument can do that, so you can then create a new RoseNode<N1, L1> and return it.
This works as expected:
> var tree = RoseTree.Node("foo", new RoseLeaf<string, int>(42), new RoseLeaf<string, int>(1337)); > tree RoseNode<string, int>("foo", IRoseTree<string, int>[2] { 42, 1337 }) > tree.SelectBoth(s => s.Length, i => i.ToString()) RoseNode<int, string>(3, IRoseTree<int, string>[2] { "42", "1337" })
This C# Interactive example shows how to convert a tree with internal string nodes and integer leaves to a tree of internal integer nodes and string leaves. The strings are converted to strings by counting their Length, while the integers are turned into strings using the standard ToString method available on all objects.
Mapping nodes #
When you have SelectBoth, you can trivially implement the translations for each dimension in isolation. For tuple bifunctors, I called these methods SelectFirst and SelectSecond, while for Either bifunctors, I chose to name them SelectLeft and SelectRight. Continuing the trend of naming the translations after what they translate, instead of their positions, I'll name the corresponding methods here SelectNode and SelectLeaf. In Haskell, the functions associated with Data.Bifunctor are always called first and second, but I see no reason to preserve such abstract naming in C#. In Haskell, these functions are part of the Bifunctor type class; the abstract names serve an actual purpose. This isn't the case in C#, so there's no reason to retain the abstract names. You might as well use names that communicate intent, which is what I've tried to do here.
If you want to map only the internal nodes, you can implement a SelectNode method based on SelectBoth:
public static IRoseTree<N1, L> SelectNode<N, N1, L>( this IRoseTree<N, L> source, Func<N, N1> selector) { return source.SelectBoth(selector, l => l); }
This simply uses the l => l lambda expression as an ad-hoc identity function, while passing selector as the selectNode argument to the SelectBoth method.
You can use this to map the above tree to a tree made entirely of numbers:
> var tree = RoseTree.Node("foo", new RoseLeaf<string, int>(42), new RoseLeaf<string, int>(1337)); > tree.SelectNode(s => s.Length) RoseNode<int, int>(3, IRoseTree<int, int>[2] { 42, 1337 })
Such a tree is, incidentally, isomorphic to a 'normal' tree. It might be a good exercise, if you need one, to demonstrate the isormorphism by writing functions that convert a Tree<T> into an IRoseTree<T, T>, and vice versa.
Mapping leaves #
Similar to SelectNode, you can also trivially implement SelectLeaf:
public static IRoseTree<N, L1> SelectLeaf<N, L, L1>( this IRoseTree<N, L> source, Func<L, L1> selector) { return source.SelectBoth(n => n, selector); }
This is another one-liner calling SelectBoth, with the difference that the identity function n => n is passed as the first argument, instead of as the last. This ensures that only RoseLeaf values are mapped:
> var tree = RoseTree.Node("foo", new RoseLeaf<string, int>(42), new RoseLeaf<string, int>(1337)); > tree.SelectLeaf(i => i % 2 == 0) RoseNode<string, bool>("foo", IRoseTree<string, bool>[2] { true, false })
In the above C# Interactive session, the leaves are mapped to Boolean values, indicating whether they're even or odd.
Identity laws #
Rose trees obey all the bifunctor laws. While it's formal work to prove that this is the case, you can get an intuition for it via examples. Often, I use a property-based testing library like FsCheck or Hedgehog to demonstrate (not prove) that laws hold, but in this article, I'll keep it simple and only cover each law with a parametrised test.
private static T Id<T>(T x) => x; public static IEnumerable<object[]> BifunctorLawsData { get { yield return new[] { new RoseLeaf<int, string>("") }; yield return new[] { new RoseLeaf<int, string>("foo") }; yield return new[] { RoseTree.Node<int, string>(42) }; yield return new[] { RoseTree.Node(42, new RoseLeaf<int, string>("bar")) }; yield return new[] { exampleTree }; } } [Theory, MemberData(nameof(BifunctorLawsData))] public void SelectNodeObeysFirstFunctorLaw(IRoseTree<int, string> t) { Assert.Equal(t, t.SelectNode(Id)); }
This test uses xUnit.net's [Theory] feature to supply a small set of example input values. The input values are defined by the BifunctorLawsData property, since I'll reuse the same values for all the bifunctor law demonstration tests. The exampleTree object is the tree shown in Church-encoded rose tree.
The tests also use the identity function implemented as a private function called Id, since C# doesn't come equipped with such a function in the Base Class Library.
For all the IRoseTree<int, string> objects t, the test simply verifies that the original tree t is equal to the tree projected over the first axis with the Id function.
Likewise, the first functor law applies when translating over the second dimension:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectLeafObeysFirstFunctorLaw(IRoseTree<int, string> t) { Assert.Equal(t, t.SelectLeaf(Id)); }
This is the same test as the previous test, with the only exception that it calls SelectLeaf instead of SelectNode.
Both SelectNode and SelectLeaf are implemented by SelectBoth, so the real test is whether this method obeys the identity law:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectBothObeysIdentityLaw(IRoseTree<int, string> t) { Assert.Equal(t, t.SelectBoth(Id, Id)); }
Projecting over both dimensions with the identity function does, indeed, return an object equal to the input object.
Consistency law #
In general, it shouldn't matter whether you map with SelectBoth or a combination of SelectNode and SelectLeaf:
[Theory, MemberData(nameof(BifunctorLawsData))] public void ConsistencyLawHolds(IRoseTree<int, string> t) { DateTime f(int i) => new DateTime(i); bool g(string s) => string.IsNullOrWhiteSpace(s); Assert.Equal(t.SelectBoth(f, g), t.SelectLeaf(g).SelectNode(f)); Assert.Equal( t.SelectNode(f).SelectLeaf(g), t.SelectLeaf(g).SelectNode(f)); }
This example creates two local functions f and g. The first function, f, creates a new DateTime object from an integer, using one of the DateTime constructor overloads. The second function, g, just delegates to string.IsNullOrWhiteSpace, although I want to stress that this is just an example. The law should hold for any two (pure) functions.
The test then verifies that you get the same result from calling SelectBoth as when you call SelectNode followed by SelectLeaf, or the other way around.
Composition laws #
The composition laws insist that you can compose functions, or translations, and that again, the choice to do one or the other doesn't matter. Along each of the axes, it's just the second functor law applied. This parametrised test demonstrates that the law holds for SelectNode:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SecondFunctorLawHoldsForSelectNode(IRoseTree<int, string> t) { char f(bool b) => b ? 'T' : 'F'; bool g(int i) => i % 2 == 0; Assert.Equal( t.SelectNode(x => f(g(x))), t.SelectNode(g).SelectNode(f)); }
Here, f is a local function that returns the the character 'T' for true, and 'F' for false; g is the even function. The second functor law states that mapping f(g(x)) in a single step is equivalent to first mapping over g and then map the result of that using f.
The same law applies if you fix the first dimension and translate over the second:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SecondFunctorLawHoldsForSelectLeaf(IRoseTree<int, string> t) { bool f(int x) => x % 2 == 0; int g(string s) => s.Length; Assert.Equal( t.SelectLeaf(x => f(g(x))), t.SelectLeaf(g).SelectLeaf(f)); }
Here, f is the even function, whereas g is a local function that returns the length of a string. Again, the test demonstrates that the output is the same whether you map over an intermediary step, or whether you map using only a single step.
This generalises to the composition law for SelectBoth:
[Theory, MemberData(nameof(BifunctorLawsData))] public void SelectBothCompositionLawHolds(IRoseTree<int, string> t) { char f(bool b) => b ? 'T' : 'F'; bool g(int x) => x % 2 == 0; bool h(int x) => x % 2 == 0; int i(string s) => s.Length; Assert.Equal( t.SelectBoth(x => f(g(x)), y => h(i(y))), t.SelectBoth(g, i).SelectBoth(f, h)); }
Again, whether you translate in one or two steps shouldn't affect the outcome.
As all of these tests demonstrate, the bifunctor laws hold for rose trees. The tests only showcase five examples, but I hope it gives you an intuition how any rose tree is a bifunctor. After all, the SelectNode, SelectLeaf, and SelectBoth methods are all generic, and they behave the same for all generic type arguments.
Summary #
Rose trees are bifunctors. You can translate the node and leaf dimension of a rose tree independently of each other, and the bifunctor laws hold for any pure translation, no matter how you compose the projections.
As always, there can be performance differences between the various compositions, but the outputs will be the same regardless of composition.
A functor, and by extension, a bifunctor, is a structure-preserving map. This means that any projection preserves the structure of the underlying container. For rose trees this means that the shape of the tree remains the same. The number of leaves remain the same, as does the number of internal nodes.
Next: Contravariant functors.

Comments
I like to think of this behavior as a phrase transition.
I agree with this in practice, but it is not always true in theory. A counter eaxample is polynomial interpolation.
Normally we think of a polynomial in an indeterminate
xof degreenas being specified by a list ofn + 1coefficients, where theith coefficient is the coefficient ofxi. Evaluating this polynomial given a value forxis easy; it just involves exponentiation, multiplication, and addition. Polynomial evaluation has a conceptual inverse called polynomial interpolation. In this direction, the input is evaluations atn + 1points in "general position" and the output is then + 1coefficients. For example, a line is a polynomial of degree1and two points are in general position if they are not the same point. This is commonly expressed the phrase "Any two (distinct) points defines a line." Three points are in general position if they are not co-linear, where co-linear means that all three points are on the same line. In general,n + 1points are in general position if they are not all on the same polynomial of degreen.Anyway, here is the point. If a pure function is known to implement some polynomial of degree (at most)
n, then even if the domain is infinite, there existsn + 1inputs such that it is sufficient to test this function for correctness on those inputs.This is why I think the phrase transition in the Devil's advocate testing is critical. There is some objective measure of complexity of the function under test (such as cyclomatic complexity), and we have an intuitive sense that a certain number of tests is sufficient for testing functions with that complexity. If the Devil is allowed to add monomials to the polynomial (or, heaven forbid, modify the implementation so that it is not a polynomial), then any finite number of tests can be circumvented. If instead the Devil is only allowed to modify the coefficients of the polynomial, then we have a winning strategy.
I think it would be exceedingly intersting if you can formally define what you mean here by "objectively". In the case of a polynomial (and speaking slightly roughly), changing the "first" nonzero coefficient to
0decreases the complexity (i.e. the degree of the polynomial) while any other change to that coefficient or any change to any other coefficient maintains the complexity.Tyson, thank you for writing. What I meant by objectively simpler I partially explain in the same paragraph. I consider cyclomatic complexity one of hardly any useful measurements in software development. As I also imply in the article, I consider Robert C. Martin's Transformation Priority Premise to include a good ranking of code constructs, e.g. that using a constant is simpler than using a variable, and so on.
I don't think you need to reach for polynomial interpolation in order to make your point. Just consider a function that returns a constant value, like this one:
You can make a similar argument about this function: You only need a single test value in order to demonstrate that it works as intended. I suppose you could view that as a zero-degree polynomial.
Beyond what you think of as the phase transition I sometimes try to see what happens if I slightly increase the complexity of a function. For the
Foofunction, it could be a change like this:Unless you just happened to pick a number less than
-1000for your test value, your test will not discover such a change.Your argument attempts to guard against that sort of change by assuming that we can somehow 'forbid' a change from a polynomial to something irregular. Real code doesn't work that way. Real code is rarely a continuous function, but rather discrete. That's the reason we have a concept such as edge case, because code branches at discrete values.
A polynomial is a single function, regardless of degree. Implemented in code, it'll have a cyclomatic complexity of 1. That may not even be worth testing, because you'd essentially only be reproducing the implementation code in your test.
The purpose of the Devil's Advocate technique isn't to demonstrate correctness; that's what unit tests are for. The purpose of the Devil's Advocate technique is to critique the tests.
In reality, I never imagine that some malicious developer gains access to the source code. On the other hand, we all make mistakes, and I try to imagine what a likely mistake might look like.