ploeh blog danish software design
A pure Test Spy
Ad-hoc Test Spies can be implemented in Haskell using the Writer monad.
In a previous article on state-based testing in Haskell, I made the following throw-away statement:
"you could write an ad-hoc Mock using, for example, the Writer monad"In that article, I didn't pursue that thought, since the theme was another. Instead, I'll expand on it here.
Test Double continuum #
More than a decade ago, I wrote an MSDN Magazine article called Exploring The Continuum Of Test Doubles. It was in the September 2007 issue, and you can also download the entire issue as a single file and read the article offline, should you want to.
In the article, I made the argument that the classification of Test Doubles presented in the excellent xUnit Test Patterns should be thought of more as a continuum with vague and fuzzy transitions, rather than discrete categories.
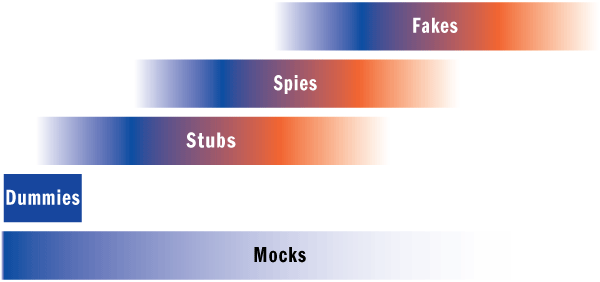
This figure appeared in the original article. Given that the entire MSDN Magazine issue is available for free, and that I'm the original author of the article, I consider it fair use to repeat it here.
The point is that it's not always clear whether a Test Double is, say, a Mock, or a Spy. What I'll show you in this article is closer to a Test Spy than to a Mock, but since the distinction is blurred anyway, I think that I can get away with it.
Test Spy #
xUnit Test Patterns defines a Test Spy as a Test Double that captures "the indirect output calls made to another component by the SUT [System Under Test] for later verification by the test." When, as shown in a previous article, you use Mock<T>.Verify to assert than an interaction took place, you're using the Test Double more as a Spy than a Mock:
repoTD.Verify(r => r.Update(user));
Strictly speaking, a Mock is a Test Double that immediately fails the test if any unexpected interaction takes place. People often call those Strict Mocks, but according to the book, that's a Mock. If the Test Double only records what happens, so that you can later query it to verify whether some interaction took place, it's closer to being a Test Spy.
Whether you call it a Mock or a Spy, you can implement verification similar to the above Verify method in functional programming using the Writer monad.
Writer-based Spy #
I'll show you a single example in Haskell. In a previous article, you saw a simplified function to implement a restaurant reservation feature, repeated here for your convenience:
tryAccept :: Int -> Reservation -> MaybeT ReservationsProgram Int tryAccept capacity reservation = do guard =<< isReservationInFuture reservation reservations <- readReservations $ reservationDate reservation let reservedSeats = sum $ reservationQuantity <$> reservations guard $ reservedSeats + reservationQuantity reservation <= capacity create $ reservation { reservationIsAccepted = True }
This function runs in the MaybeT monad, so the two guard functions could easily prevent if from running 'to completion'. In the happy path, though, execution should reach 'the end' of the function and call the create function.
In order to test this happy path, you'll need to not only run a test-specific interpreter over the ReservationsProgram free monad, you should also verify that reservationIsAccepted is True.
You can do this using the Writer monad to implement a Test Spy:
testProperty "tryAccept, happy path" $ \ (NonNegative i) (fmap getReservation -> reservations) (ArbReservation reservation) expected -> let spy (IsReservationInFuture _ next) = return $ next True spy (ReadReservations _ next) = return $ next reservations spy (Create r next) = tell [r] >> return (next expected) reservedSeats = sum $ reservationQuantity <$> reservations capacity = reservedSeats + reservationQuantity reservation + i (actual, observedReservations) = runWriter $ foldFreeT spy $ runMaybeT $ tryAccept capacity reservation in Just expected == actual && [True] == (reservationIsAccepted <$> observedReservations)
This test is an inlined QuickCheck-based property. The entire source code is available on GitHub.
Notice the spy function. As the name implies, it's the Test Spy for the test. Its full type is:
spy :: Monad m => ReservationsInstruction a -> WriterT [Reservation] m a
This is a function that, for a given ReservationsInstruction value returns a WriterT value where the type of data being written is [Reservation]. The function only writes to the writer context in one of the three cases: the Create case. The Create case carries with it a Reservation value here named r. Before returning the next step in interpreting the free monad, the spy function calls tell, thereby writing a singleton list of [r] to the writer context.
In the Act phase of the test, it calls the tryAccept function and proceeds to interpret the result, which is a MaybeT ReservationsProgram Int value. Calling runMaybeT produces a ReservationsProgram (Maybe Int), which you can then interpret with foldFreeT spy. This returns a Writer [Reservation] (Maybe Int), which you can finally run with runWriter to get a (Maybe Int, [Reservation]) tuple. Thus, actual is a Maybe Int value, and observedReservations is a [Reservation] value - the reservation that was written by spy using tell.
The Assert phase of the test is a Boolean expression that checks that actual is as expected, and that reservationIsAccepted of the observed reservation is True.
It takes a little while to make the pieces of the puzzle fit, but it's basically just standard Haskell library functions clicked together.
Summary #
People sometimes ask me: How do Mocks and Stubs work in functional programming?
In general, my answer is that you don't need Mocks and Stubs because when functions are pure, you don't need to to test interactions. Sooner or later, though, you may run into higher-level interactions, even if they're pure interactions, and you'll likely want to unit test those.
In a previous article you saw how to apply state-based testing in Haskell, using the State monad. In this article you've seen how you can create ad-hoc Mocks or Spies with the Writer monad. No auto-magical test-specific 'isolation frameworks' are required.
An example of state-based testing in C#
An example of avoiding Mocks and Stubs in C# unit testing.
This article is an instalment in an article series about how to move from interaction-based testing to state-based testing. In the previous article, you saw an example of a pragmatic state-based test in F#. You can now take your new-found knowledge and apply it to the original C# example.
In the spirit of xUnit Test Patterns, in this article you'll see how to refactor the tests while keeping the implementation code constant.
The code shown in this article is available on GitHub.
Connect two users #
The previous article provides more details on the System Under Test (SUT), but here it is, repeated, for your convenience:
public class ConnectionsController : ApiController { public ConnectionsController( IUserReader userReader, IUserRepository userRepository) { UserReader = userReader; UserRepository = userRepository; } public IUserReader UserReader { get; } public IUserRepository UserRepository { get; } public IHttpActionResult Post(string userId, string otherUserId) { var userRes = UserReader.Lookup(userId).SelectError( error => error.Accept(UserLookupError.Switch( onInvalidId: "Invalid user ID.", onNotFound: "User not found."))); var otherUserRes = UserReader.Lookup(otherUserId).SelectError( error => error.Accept(UserLookupError.Switch( onInvalidId: "Invalid ID for other user.", onNotFound: "Other user not found."))); var connect = from user in userRes from otherUser in otherUserRes select Connect(user, otherUser); return connect.SelectBoth(Ok, BadRequest).Bifold(); } private User Connect(User user, User otherUser) { user.Connect(otherUser); UserRepository.Update(user); return otherUser; } }
This implementation code is a simplification of the code example that serves as an example running through my two Clean Coders videos, Church Visitor and Preserved in translation.
A Fake database #
As in the previous article, you can define a test-specific Fake database:
public class FakeDB : Collection<User>, IUserReader, IUserRepository { public IResult<User, IUserLookupError> Lookup(string id) { if (!(int.TryParse(id, out int i))) return Result.Error<User, IUserLookupError>(UserLookupError.InvalidId); var user = this.FirstOrDefault(u => u.Id == i); if (user == null) return Result.Error<User, IUserLookupError>(UserLookupError.NotFound); return Result.Success<User, IUserLookupError>(user); } public bool IsDirty { get; set; } public void Update(User user) { IsDirty = true; if (!Contains(user)) Add(user); } }
This is one of the few cases where I find inheritance more convenient than composition. By deriving from Collection<User>, you don't have to explicitly write code to expose a Retrieval Interface. The entirety of a standard collection API is already available via the base class. Had this class been part of a public API, I'd be concerned that inheritance could introduce future breaking changes, but as part of a suite of unit tests, I hope that I've made the right decision.
Although you can derive a Fake database from a base class, you can still implement required interfaces - in this case IUserReader and IUserRepository. The Update method is the easiest one to implement, since it simply sets the IsDirty flag to true and adds the user if it's not already part of the collection.
The IsDirty flag is the only custom Retrieval Interface added to the FakeDB class. As the previous article explains, this flag provides a convenient was to verify whether or not the database has changed.
The Lookup method is a bit more involved, since it has to support all three outcomes implied by the protocol:
- If the
idis invalid, a result to that effect is returned. - If the user isn't found, a result to that effect is returned.
- If the user with the requested
idis found, then that user is returned.
Happy path test case #
This is all you need in terms of Test Doubles. You now have a test-specific IUserReader and IUserRepository implementation that you can pass to the Post method. Notice that a single class implements multiple interfaces. This is often key to be able to implement a Fake object in the first place.
Like in the previous article, you can start by exercising the happy path where a user successfully connects with another user:
[Theory, UserManagementTestConventions] public void UsersSuccessfullyConnect( [Frozen(Matching.ImplementedInterfaces)]FakeDB db, User user, User otherUser, ConnectionsController sut) { db.Add(user); db.Add(otherUser); db.IsDirty = false; var actual = sut.Post(user.Id.ToString(), otherUser.Id.ToString()); var ok = Assert.IsAssignableFrom<OkNegotiatedContentResult<User>>(actual); Assert.Equal(otherUser, ok.Content); Assert.True(db.IsDirty); Assert.Contains(otherUser.Id, user.Connections); }
This, and all other tests in this article use xUnit.net 2.3.1 and AutoFixture 4.1.0.
The test is organised according to my standard heuristic for formatting tests according to the Arrange Act Assert pattern. In the Arrange phase, it adds the two valid User objects to the Fake db and sets the IsDirty flag to false.
Setting the flag is necessary because this is object-oriented code, where objects have mutable state. In the previous articles with examples in F# and Haskell, the User types were immutable. Connecting two users didn't mutate one of the users, but rather returned a new User value, as this F# example demonstrates:
// User -> User -> User let addConnection user otherUser = { user with ConnectedUsers = otherUser :: user.ConnectedUsers }
In the current object-oriented code base, however, connecting one user to another is an instance method on the User class that mutates its state:
public void Connect(User otherUser) { connections.Add(otherUser.Id); }
As a consequence, the Post method could, if someone made a mistake in its implementation, call user.Connect, but forget to invoke UserRepository.Update. Even if that happened, then all the other assertions would pass. This is the reason that you need the Assert.True(db.IsDirty) assertion in the Assert phase of the test.
While we can apply to object-oriented code what we've learned from functional programming, the latter remains simpler.
Error test cases #
While there's one happy path, there's four distinct error paths that you ought to cover. You can use the Fake database for that as well:
[Theory, UserManagementTestConventions] public void UsersFailToConnectWhenUserIdIsInvalid( [Frozen(Matching.ImplementedInterfaces)]FakeDB db, string userId, User otherUser, ConnectionsController sut) { Assert.False(int.TryParse(userId, out var _)); db.Add(otherUser); db.IsDirty = false; var actual = sut.Post(userId, otherUser.Id.ToString()); var err = Assert.IsAssignableFrom<BadRequestErrorMessageResult>(actual); Assert.Equal("Invalid user ID.", err.Message); Assert.False(db.IsDirty); } [Theory, UserManagementTestConventions] public void UsersFailToConnectWhenOtherUserIdIsInvalid( [Frozen(Matching.ImplementedInterfaces)]FakeDB db, User user, string otherUserId, ConnectionsController sut) { Assert.False(int.TryParse(otherUserId, out var _)); db.Add(user); db.IsDirty = false; var actual = sut.Post(user.Id.ToString(), otherUserId); var err = Assert.IsAssignableFrom<BadRequestErrorMessageResult>(actual); Assert.Equal("Invalid ID for other user.", err.Message); Assert.False(db.IsDirty); } [Theory, UserManagementTestConventions] public void UsersDoNotConnectWhenUserDoesNotExist( [Frozen(Matching.ImplementedInterfaces)]FakeDB db, int userId, User otherUser, ConnectionsController sut) { db.Add(otherUser); db.IsDirty = false; var actual = sut.Post(userId.ToString(), otherUser.Id.ToString()); var err = Assert.IsAssignableFrom<BadRequestErrorMessageResult>(actual); Assert.Equal("User not found.", err.Message); Assert.False(db.IsDirty); } [Theory, UserManagementTestConventions] public void UsersDoNotConnectWhenOtherUserDoesNotExist( [Frozen(Matching.ImplementedInterfaces)]FakeDB db, User user, int otherUserId, ConnectionsController sut) { db.Add(user); db.IsDirty = false; var actual = sut.Post(user.Id.ToString(), otherUserId.ToString()); var err = Assert.IsAssignableFrom<BadRequestErrorMessageResult>(actual); Assert.Equal("Other user not found.", err.Message); Assert.False(db.IsDirty); }
There's little to say about these tests that hasn't already been said in at least one of the previous articles. All tests inspect the state of the Fake database after calling the Post method. The exact interactions between Post and db aren't specified. Instead, these tests rely on setting up the initial state, exercising the SUT, and verifying the final state. These are all state-based tests that avoid over-specifying the interactions.
Specifically, none of these tests use Mocks and Stubs. In fact, at this incarnation of the test code, I was able to entirely remove the reference to Moq.
Summary #
The premise of Refactoring is that in order to be able to refactor, the "precondition is [...] solid tests". In reality, many development organisations have the opposite experience. When programmers attempt to make changes to how their code is organised, tests break. In xUnit Test Patterns this problem is called Fragile Tests, and the cause is often Overspecified Software. This means that tests are tightly coupled to implementation details of the SUT.
It's easy to inadvertently fall into this trap when you use Mocks and Stubs, even when you follow the rule of using Mocks for Commands and Stubs for Queries. Refactoring tests towards state-based testing with Fake objects, instead of interaction-based testing, could make test suites more robust to changes.
It's intriguing, though, that state-based testing is simpler in functional programming. In Haskell, you can simply write your tests in the State monad and compare the expected outcome to the actual outcome. Since state in Haskell is immutable, it's trivial to compare the expected with the actual state.
As soon as you introduce mutable state, structural equality is no longer safe, and instead you have to rely on other inspection mechanisms, such as the IsDirty flag seen in this, and the previous, article. This makes the tests slightly more brittle, because it tends to pull towards interaction-based testing.
While you can implement the State monad in both F# and C#, it's probably more pragmatic to express state-based tests using mutable state and the occasional IsDirty flag. As always, there's no panacea.
While this article concludes the series on moving towards state-based testing, I think that an appendix on Test Spies is in order.
Next: A pure Test Spy.
An example of state based-testing in F#
While F# is a functional-first language, it's okay to occasionally be pragmatic and use mutable state, for example to easily write some sustainable state-based tests.
This article is an instalment in an article series about how to move from interaction-based testing to state-based testing. In the previous article, you saw how to write state-based tests in Haskell. In this article, you'll see how to apply what you've learned in F#.
The code shown in this article is available on GitHub.
A function to connect two users #
This article, like the others in this series, implements an operation to connect two users. I explain the example in details in my two Clean Coders videos, Church Visitor and Preserved in translation.
Like in the previous Haskell example, in this article we'll start with the implementation, and then see how to unit test it.
// ('a -> Result<User,UserLookupError>) -> (User -> unit) -> 'a -> 'a -> HttpResponse<User> let post lookupUser updateUser userId otherUserId = let userRes = lookupUser userId |> Result.mapError (function | InvalidId -> "Invalid user ID." | NotFound -> "User not found.") let otherUserRes = lookupUser otherUserId |> Result.mapError (function | InvalidId -> "Invalid ID for other user." | NotFound -> "Other user not found.") let connect = result { let! user = userRes let! otherUser = otherUserRes addConnection user otherUser |> updateUser return otherUser } match connect with Ok u -> OK u | Error msg -> BadRequest msg
While the original C# example used Constructor Injection, the above post function uses partial application for Dependency Injection. The two function arguments lookupUser and updateUser represent interactions with a database. Since functions are polymorphic, however, it's possible to replace them with Test Doubles.
A Fake database #
Like in the Haskell example, you can implement a Fake database in F#. It's also possible to implement the State monad in F#, but there's less need for it. F# is a functional-first language, but you can also write mutable code if need be. You could, then, choose to be pragmatic and base your Fake database on mutable state.
type FakeDB () = let users = Dictionary<int, User> () member val IsDirty = false with get, set member this.AddUser user = this.IsDirty <- true users.Add (user.UserId, user) member this.TryFind i = match users.TryGetValue i with | false, _ -> None | true, u -> Some u member this.LookupUser s = match Int32.TryParse s with | false, _ -> Error InvalidId | true, i -> match users.TryGetValue i with | false, _ -> Error NotFound | true, u -> Ok u member this.UpdateUser u = this.IsDirty <- true users.[u.UserId] <- u
This FakeDB type is a class that wraps a mutable dictionary. While it 'implements' LookupUser and UpdateUser, it also exposes what xUnit Test Patterns calls a Retrieval Interface: an API that tests can use to examine the state of the object.
Immutable values normally have structural equality. This means that two values are considered equal if they contain the same constituent values, and have the same structure. Mutable objects, on the other hand, typically have reference equality. This makes it harder to compare two objects, which is, however, what almost all unit testing is about. You compare expected state with actual state.
In the previous article, the Fake database was simply an immutable dictionary. This meant that tests could easily compare expected and actual values, since they were immutable. When you use a mutable object, like the above dictionary, this is harder. Instead, what I chose to do here was to introduce an IsDirty flag. This enables easy verification of whether or not the database changed.
Happy path test case #
This is all you need in terms of Test Doubles. You now have test-specific LookupUser and UpdateUser methods that you can pass to the post function.
Like in the previous article, you can start by exercising the happy path where a user successfully connects with another user:
[<Fact>] let ``Users successfully connect`` () = Property.check <| property { let! user = Gen.user let! otherUser = Gen.withOtherId user let db = FakeDB () db.AddUser user db.AddUser otherUser let actual = post db.LookupUser db.UpdateUser (string user.UserId) (string otherUser.UserId) test <@ db.TryFind user.UserId |> Option.exists (fun u -> u.ConnectedUsers |> List.contains otherUser) @> test <@ isOK actual @> }
All tests in this article use xUnit.net 2.3.1, Unquote 4.0.0, and Hedgehog 0.7.0.0.
This test first adds two valid users to the Fake database db. It then calls the post function, passing the db.LookupUser and db.UpdateUser methods as arguments. Finally, it verifies that the 'first' user's ConnectedUsers now contains the otherUser. It also verifies that actual represents a 200 OK HTTP response.
Missing user test case #
While there's one happy-path test case, there's four other test cases left. One of these is when the first user doesn't exist:
[<Fact>] let ``Users don't connect when user doesn't exist`` () = Property.check <| property { let! i = Range.linear 1 1_000_000 |> Gen.int let! otherUser = Gen.user let db = FakeDB () db.AddUser otherUser db.IsDirty <- false let uniqueUserId = string (otherUser.UserId + i) let actual = post db.LookupUser db.UpdateUser uniqueUserId (string otherUser.UserId) test <@ not db.IsDirty @> test <@ isBadRequest actual @> }
This test adds one valid user to the Fake database. Once it's done with configuring the database, it sets IsDirty to false. The AddUser method sets IsDirty to true, so it's important to reset the flag before the act phase of the test. You could consider this a bit of a hack, but I think it makes the intent of the test clear. This is, however, a position I'm ready to reassess should the tests evolve to make this design awkward.
As explained in the previous article, this test case requires an ID of a user that doesn't exist. Since this is a property-based test, there's a risk that Hedgehog might generate a number i equal to otherUser.UserId. One way to get around that problem is to add the two numbers together. Since i is generated from the range 1 - 1,000,000, uniqueUserId is guaranteed to be different from otherUser.UserId.
The test verifies that the state of the database didn't change (that IsDirty is still false), and that actual represents a 400 Bad Request HTTP response.
Remaining test cases #
You can write the remaining three test cases in the same vein:
[<Fact>] let ``Users don't connect when other user doesn't exist`` () = Property.check <| property { let! i = Range.linear 1 1_000_000 |> Gen.int let! user = Gen.user let db = FakeDB () db.AddUser user db.IsDirty <- false let uniqueOtherUserId = string (user.UserId + i) let actual = post db.LookupUser db.UpdateUser (string user.UserId) uniqueOtherUserId test <@ not db.IsDirty @> test <@ isBadRequest actual @> } [<Fact>] let ``Users don't connect when user Id is invalid`` () = Property.check <| property { let! s = Gen.alphaNum |> Gen.string (Range.linear 0 100) |> Gen.filter isIdInvalid let! otherUser = Gen.user let db = FakeDB () db.AddUser otherUser db.IsDirty <- false let actual = post db.LookupUser db.UpdateUser s (string otherUser.UserId) test <@ not db.IsDirty @> test <@ isBadRequest actual @> } [<Fact>] let ``Users don't connect when other user Id is invalid`` () = Property.check <| property { let! s = Gen.alphaNum |> Gen.string (Range.linear 0 100) |> Gen.filter isIdInvalid let! user = Gen.user let db = FakeDB () db.AddUser user db.IsDirty <- false let actual = post db.LookupUser db.UpdateUser (string user.UserId) s test <@ not db.IsDirty @> test <@ isBadRequest actual @> }
All tests inspect the state of the Fake database after the calling the post function. The exact interactions between post and db aren't specified. Instead, these tests rely on setting up the initial state, exercising the System Under Test, and verifying the final state. These are all state-based tests that avoid over-specifying the interactions.
Summary #
While the previous Haskell example demonstrated that it's possible to write state-based unit tests in a functional style, when using F#, it sometimes make sense to leverage the object-oriented features already available in the .NET framework, such as mutable dictionaries. It would have been possible to write purely functional state-based tests in F# as well, by porting the Haskell examples, but here, I wanted to demonstrate that this isn't required.
I tend to be of the opinion that it's only possible to be pragmatic if you know how to be dogmatic, but now that we know how to write state-based tests in a strictly functional style, I think it's fine to be pragmatic and use a bit of mutable state in F#. The benefit of this is that it now seems clear how to apply what we've learned to the original C# example.
The programmer as decision maker
As a programmer, your job is to make technical decisions. Make some more.
When I speak at conferences, people often come and talk to me. (I welcome that, BTW.) Among all the conversations I've had over the years, there's a pattern to some of them. The attendee will start by telling me how inspired (s)he is by the talk I just gave, or something I've written. That's gratifying, and a good way to start a conversation, but is often followed up like this:
Attendee: "I just wish that we could do something like that in our organisation..."
Let's just say that here we're talking about test-driven development, or perhaps just unit testing. Nothing too controversial. I'd typically respond,
Me: "Why can't you?"
Attendee: "Our boss won't let us..."
That's unfortunate. If your boss has explicitly forbidden you to write and run unit tests, then there's not much you can do. Let me make this absolutely clear: I'm not going on record saying that you should actively disobey a direct order (unless it's unethical, that is). I do wonder, however:
Why is the boss even involved in that decision?
It seems to me that programmers often defer too much authority to their managers.
A note on culture #
I'd like to preface the rest of this article with my own context. I've spent most of my programming career in Danish organisations. Even when I worked for Microsoft, I worked for Danish subsidiaries, with Danish managers.
The power distance in Denmark is (in)famously short. It's not unheard of for individual contributors to question their superiors' decisions; sometimes to their face, and sometimes even when other people witness this. When done respectfully (which it often is), this can be extremely efficient. Managers are as fallible as the rest of us, and often their subordinates know of details that could impact a decision that a manager is about to make. Immediately discussing such details can help ensure that good decisions are made, and bad decisions are cancelled.
This helps managers make better decisions, so enlightened managers welcome feedback.
In general, Danish employees also tend to have a fair degree of autonomy. What I'll suggest in this article is unlikely to get you fired in Denmark. Please use your own judgement if you consider transplanting the following to your own culture.
Technical decisions #
If your job is programmer, software developer, or similar, the value you add to the team is that you bring technical expertise. Maybe some of your colleagues are programmers as well, but together, you are the people with the technical expertise.
Even if the project manager or other superiors used to program, unless they're also writing code for the current code base, they only have general technical expertise, but not specific expertise related to the code base you're working with. The people with most technical expertise are you and your colleagues.
You are decision makers.
Whenever you interact with your code base, you make technical decisions.
In order to handle incoming HTTP requests to a /reservations resource, you may first decide to create a new file called ReservationsController.cs. You'd most likely also decide to open that file and start adding code to it.
Perhaps you add a method called Post that takes a Reservation argument. Perhaps you decide to inject an IMaîtreD dependency.
At various steps along the way, you may decide to compile the code.
Once you think that you've made enough changes to address your current work item, you may decide to run the program to see if it works. For a web-based piece of software, that typically involves starting up a browser and somehow interacting with the service. If your program is a web site, you may start at the front page, log in, click around, and fill in some forms. If your program is a REST API, you may interact with it via Fiddler or Postman (I prefer curl or Furl, but most people I've met still prefer something they can click on, it seems).
What often happens is that your changes don't work the first time around, so you'll have to troubleshoot. Perhaps you decide to use a debugger.
How many decisions are that?
I just described seven or eight types of the sort of decisions you make as a programmer. You make such decisions all the time. Do you ask your managers permission before you start a debugging session? Before you create a new file? Before you name a variable?
Of course you don't. You're the technical expert. There's no-one better equipped than you or your team members to make those decisions.
Decide to add unit tests #
If you want to add unit tests, why don't you just decide to add them? If you want to apply test-driven development, why don't you just do so?
A unit test is one or more code files. You're already authorised to make decisions about adding files.
You can run a test suite instead of launching the software every time you want to interact with it. It's likely to be faster, even.
Why should you ask permission to do that?
Decide to refactor #
Another complaint I hear is that people aren't allowed to refactor.
Why are you even asking permission to refactor?
Refactoring means reorganising the code without changing the behaviour of the system. Another word for that is editing the code. It's okay. You're already permitted to edit code. It's part of your job description.
I think I know what the underlying problem is, though...
Make technical decisions in the small #
As an individual contributor, you're empowered to make small-scale technical decisions. These are decisions that are unlikely to impact schedules or allocation of programmers, including new hires. Big decisions probably should involve your manager.
I have an inkling of why people feel that they need permission to refactor. It's because the refactoring they have in mind is going to take weeks. Weeks in which nothing else can be done. Weeks where perhaps the code doesn't even compile.
Many years ago (but not as many as I'd like it to be), my colleague and I had what Eric Evans in DDD calls a breakthrough. We wanted to refactor towards deeper insight. What prompted the insight was a new feature that we had to add, and we'd been throwing design ideas back and forth for some time before the new insight arrived.
We could implement the new feature if we changed one of the core abstractions in our domain model, but it required substantial changes to the existing code base. We informed our manager of our new insight and our plan, estimating that it would take less than a week to make the changes and implement the new feature. Our manager agreed with the plan.
Two weeks later our code hadn't been in a compilable state for a week. Our manager pulled me away to tell me, quietly and equitably, that he was not happy with our lack of progress. I could only concur.
After more heroic work, we finally managed to complete the changes and implement the new feature. Nonetheless, blocking all other development for two-three weeks in order to make a change isn't acceptable.
That sort of change is a big decision because it impacts other team members, schedules, and perhaps overall business plans. Don't make those kinds of decisions without consulting with stakeholders.
This still leaves, I believe, lots of room for individual decision-making in the small. What I learned from the experience I just recounted was not to engage in big changes to a code base. Learn how to make multiple incremental changes instead. In case that's completely impossible, add the new model side-by-side with the old model, and incrementally change over. That's what I should have done those many years ago.
Don't be sneaky #
When I give talks about the blessings of functional programming, I sometimes get into another type of discussion.
Attendee: It's so inspiring how beautiful and simple complex domain models become in F#. How can we do the same in C#?
Me: You can't. If you're already using C#, you should strongly consider F# if you wish to do functional programming. Since it's also a .NET language, you can gradually introduce F# code and mix the compiled code with your existing C# code.
Attendee: Yes... [already getting impatient with me] But we can't do that...
Me: Why not?
Attendee: Because our manager will not allow it.
Based on the suggestions I've already made here, you may expect me to say that that's another technical decision that you should make without asking permission. Like the previous example about blocking refactorings, however, this is another large-scale decision.
Your manager may be concerned that it'd be hard to find new employees if the code base is written in some niche language. I tend to disagree with that position, but I do understand why a manager would take that position. While I think it suboptimal to restrict an entire development organisation to a single language (whether it's C#, Java, C++, Ruby, etc.), I'll readily accept that language choice is a strategic decision.
If every programmer got to choose the programming language they prefer the most that day, you'd have code bases written in dozens of different languages. While you can train bright new hires to learn a new language or two, it's unrealistic that a new employee will be able to learn thirty different languages in a short while.
I find it reasonable that a manager has the final word on the choice of language, even when I often disagree with the decisions.
The outcome usually is that people are stuck with C# (or Java, or...). Hence the question: How can we do functional programming in C#?
I'll give the answer that I often give here on the blog: mu (unask the question). You can, in fact, translate functional concepts to C#, but the result is so non-idiomatic that only the syntax remains of C#:
public static IReservationsInstruction<TResult> Select<T, TResult>( this IReservationsInstruction<T> source, Func<T, TResult> selector) { return source.Match<IReservationsInstruction<TResult>>( isReservationInFuture: t => new IsReservationInFuture<TResult>( new Tuple<Reservation, Func<bool, TResult>>( t.Item1, b => selector(t.Item2(b)))), readReservations: t => new ReadReservations<TResult>( new Tuple<DateTimeOffset, Func<IReadOnlyCollection<Reservation>, TResult>>( t.Item1, d => selector(t.Item2(d)))), create: t => new Create<TResult>( new Tuple<Reservation, Func<int, TResult>>( t.Item1, r => selector(t.Item2(r))))); }
Keep in mind the manager's motivation for standardising on C#. It's often related to concerns about being able to hire new employees, or move employees from project to project.
If you write 'functional' C#, you'll end up with code like the above, or the following real-life example:
return await sendRequest( ApiMethodNames.InitRegistration, new GSObject()) .Map(r => ValidateResponse.Validate(r) .MapFailure(_ => ErrorResponse.RegisterErrorResponse())) .Bind(r => r.RetrieveField("regToken")) .BindAsync(token => sendRequest( ApiMethodNames.RegisterAccount, CreateRegisterRequest( mailAddress, password, token)) .Map(ValidateResponse.Validate) .Bind(response => getIdentity(response) .ToResult(ErrorResponse.ExternalServiceResponseInvalid))) .Map(id => GigyaIdentity.CreateNewSiteUser(id.UserId, mailAddress));
(I'm indebted to Rune Ibsen for this example.)
A new hire can have ten years of C# experience and still have no chance in a code base like that. You'll first have to teach him or her functional programming. If you can do that, you might as well also teach a new language, like F#.
It's my experience that learning the syntax of a new language is easy, and usually doesn't take much time. The hard part is learning a new way to think.
Writing 'functional' C# makes it doubly hard on new team members. Not only do they have to learn a new paradigm (functional programming), but they have to learn it in a language unsuited for that paradigm.
That's why I think you should unask the question. If your manager doesn't want to allow F#, then writing 'functional' C# is just being sneaky. That'd be obeying the letter of the law while breaking the spirit of it. That is, in my opinion, immoral. Don't be sneaky.
Summary #
As a professional programmer, your job is to be a technical expert. In normal circumstances (at least the ones I know from my own career), you have agency. In order to get anything done, you make small decisions all the time, such as editing code. That's not only okay, but expected of you.
Some decision, on the other hand, can have substantial ramifications. Choosing to write code in an unsanctioned language tends to fall on the side where a manager should be involved in the decision.
In between is a grey area.
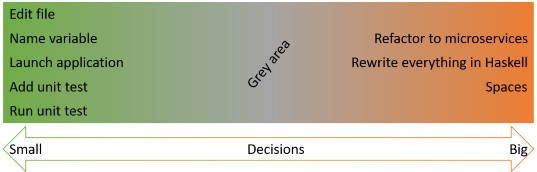
I don't even consider adding unit tests to be in the grey area, but some refactorings may be.
"It's easier to ask forgiveness than it is to get permission."
To navigate grey areas you need a moral compass.
I'll let you be the final judge of what you can get away with, but I consider it both appropriate and ethical to make the decision to add unit tests, and to continually improve code bases. You shouldn't have to ask permission to do that.
Comments
Before all, I'd just like to thank all the content you share, they all make me think in a good way!
Now regarding to this post, while I tend to agree that a developer can take the decision to add (or not) unit tests by himself, there is no great value comming out of it, if that's not an approach of the whole development team, right? I believe we need the entire team on board to maximize the values of unit tests. There are changes we need to consider, from changes in the mindset of how you develop to actually running them on continuour integration pipelines. Doesn't all of that push simple decisions like "add unit test" from green area towards orange area?
Francisco, thank you for writing. If you have a team of developers, then I agree that unit tests are going to be most valuable if the team decides to use them.
This is still something that you ought to be competent to decide as a self-organising team of developers. Do you need to ask a manager's permission?
I'm not trying to pretend that this is easy. I realise that it can be difficult.
I've heard about teams where other developers are hostile to the idea of unit testing. In that situation, I can offer no easy fixes. What a lone developer can try to do in that situation is to add and run unit tests locally, on his or her own machine. This will incur some friction, because other team members will be oblivious to the tests, so they'll change code that will cause those unit tests to break.
This might teach the lone developer to write tests so that they're as robust to trivial changes as possible. That's a valuable skill in any case. There's still going to be some overhead of maintaining the unit tests in a scenario like that, but if that overhead is smaller than the productivity gained, then in might still be worthwhile.
What might then happen could be that other developers who are on the fence see that the lone unit tester is more effective than they are. Perhaps they'll get curious about unit tests after all, once they can see the contours of advantages.
The next scenario, then, is a team with a few developers writing unit tests, and other who don't. At some number, you'll have achieved enough critical mass that, at least, you get to check in the unit tests together with the source code. Soon after, you may be able to institute a policy that while not everyone writes unit tests, it's not okay to break existing tests.
The next thing you can do, then, is to set up a test run as part of continuous integration and declare that a failing test run means that the build broke. You still have team members who don't write tests, but at least you get to do it, and the tests add value to the whole team.
Perhaps the sceptics will slowly start to write unit tests over time. Some die-hards probably never will.
You may be able to progress through such stages without asking a manager, but I do understand that there's much variation in organisation and team dynamics. If you can use any of the above sketches as inspiration, then that's great. If you (or other readers) have other success stories to tell, then please share them.
The point I was trying to make with this article is that programmers have agency. This isn't a licence to do whatever you please. You still have to navigate the dynamics of whatever organisation you're in. You may not, however, need to ask your manager about every little thing that you're competent to decide yourselves.
Thank you A LOT for putting words on all these thought. You'll be my reference whenever I want to introduce unit test.
My usual example is "a surgeon doesn't need to ask to the manager if he can wash his hand. Whashing his hand is part of his job". (Not mine, but I can't remember where it comes from)
An example of state-based testing in Haskell
How do you do state-based testing when state is immutable? You use the State monad.
This article is an instalment in an article series about how to move from interaction-based testing to state-based testing. In the previous article, you saw an example of an interaction-based unit test written in C#. The problem that this article series attempts to address is that interaction-based testing can lead to what xUnit Test Patterns calls Fragile Tests, because the tests get coupled to implementation details, instead of overall behaviour.
My experience is that functional programming is better aligned with unit testing because functional design is intrinsically testable. While I believe that functional programming is no panacea, it still seems to me that we can learn many valuable lessons about programming from it.
People often ask me about F# programming: How do I know that my F# code is functional?
I sometimes wonder that myself, about my own F# code. One can certainly choose to ignore such a question as irrelevant, and I sometimes do, as well. Still, in my experience, asking such questions can create learning opportunities.
The best answer that I've found is: Port the F# code to Haskell.
Haskell enforces referential transparency via its compiler. If Haskell code compiles, it's functional. In this article, then, I take the problem from the previous article and port it to Haskell.
The code shown in this article is available on GitHub.
A function to connect two users #
In the previous article, you saw implementation and test coverage of a piece of software functionality to connect two users with each other. This was a simplification of the example running through my two Clean Coders videos, Church Visitor and Preserved in translation.
In contrast to the previous article, we'll start with the implementation of the System Under Test (SUT).
post :: Monad m => (a -> m (Either UserLookupError User)) -> (User -> m ()) -> a -> a -> m (HttpResponse User) post lookupUser updateUser userId otherUserId = do userRes <- first (\case InvalidId -> "Invalid user ID." NotFound -> "User not found.") <$> lookupUser userId otherUserRes <- first (\case InvalidId -> "Invalid ID for other user." NotFound -> "Other user not found.") <$> lookupUser otherUserId connect <- runExceptT $ do user <- ExceptT $ return userRes otherUser <- ExceptT $ return otherUserRes lift $ updateUser $ addConnection user otherUser return otherUser return $ either BadRequest OK connect
This is as direct a translation of the C# code as makes sense. If I'd only been implementing the desired functionality in Haskell, without having to port existing code, I'd designed the code differently.
This post function uses partial application as an analogy to dependency injection, but in order to enable potentially impure operations to take place, everything must happen inside of some monad. While the production code must ultimately run in the IO monad in order to interact with a database, tests can choose to run in another monad.
In the C# example, two dependencies are injected into the class that defines the Post method. In the above Haskell function, these two dependencies are instead passed as function arguments. Notice that both functions return values in the monad m.
The intent of the lookupUser argument is that it'll query a database with a user ID. It'll return the user if present, but it could also return a UserLookupError, which is a simple sum type:
data UserLookupError = InvalidId | NotFound deriving (Show, Eq)
If both users are found, the function connects the users and calls the updateUser function argument. The intent of this 'dependency' is that it updates the database. This is recognisably a Command, since its return type is m () - unit (()) is equivalent to void.
State-based testing #
How do you unit test such a function? How do you use Mocks and Stubs in Haskell? You don't; you don't have to. While the post method can be impure (when m is IO), it doesn't have to be. Functional design is intrinsically testable, but that proposition depends on purity. Thus, it's worth figuring out how to keep the post function pure in the context of unit testing.
While IO implies impurity, most common monads are pure. Which one should you choose? You could attempt to entirely 'erase' the monadic quality of the post function with the Identity monad, but if you do that, you can't verify whether or not updateUser was invoked.
While you could write an ad-hoc Mock using, for example, the Writer monad, it might be a better choice to investigate if something closer to state-based testing would be possible.
In an object-oriented context, state-based testing implies that you exercise the SUT, which mutates some state, and then you verify that the (mutated) state matches your expectations. You can't do that when you test a pure function, but you can examine the state of the function's return value. The State monad is an obvious choice, then.
A Fake database #
Haskell's State monad is parametrised on the state type as well as the normal 'value type', so in order to be able to test the post function, you'll have to figure out what type of state to use. The interactions implied by the post function's lookupUser and updateUser arguments are those of database interactions. A Fake database seems an obvious choice.
For the purposes of testing the post function, an in-memory database implemented using a Map is appropriate:
type DB = Map Integer User
This is simply a dictionary keyed by Integer values and containing User values. You can implement compatible lookupUser and updateUser functions with State DB as the Monad. The updateUser function is the easiest one to implement:
updateUser :: User -> State DB () updateUser user = modify $ Map.insert (userId user) user
This simply inserts the user into the database, using the userId as the key. The type of the function is compatible with the general requirement of User -> m (), since here, m is State DB.
The lookupUser Fake implementation is a bit more involved:
lookupUser :: String -> State DB (Either UserLookupError User) lookupUser s = do let maybeInt = readMaybe s :: Maybe Integer let eitherInt = maybe (Left InvalidId) Right maybeInt db <- get return $ eitherInt >>= maybe (Left NotFound) Right . flip Map.lookup db
First, consider the type. The function takes a String value as an argument and returns a State DB (Either UserLookupError User). The requirement is a function compatible with the type a -> m (Either UserLookupError User). This works when a is String and m is, again, State DB.
The entire function is written in do notation, where the inferred Monad is, indeed, State DB. The first line attempts to parse the String into an Integer. Since the built-in readMaybe function returns a Maybe Integer, the next line uses the maybe function to handle the two possible cases, converting the Nothing case into the Left InvalidId value, and the Just case into a Right value.
It then uses the State module's get function to access the database db, and finally attempt a lookup against that Map. Again, maybe is used to convert the Maybe value returned by Map.lookup into an Either value.
Happy path test case #
This is all you need in terms of Test Doubles. You now have test-specific lookupUser and updateUser functions that you can pass to the post function.
Like in the previous article, you can start by exercising the happy path where a user successfully connects with another user:
testProperty "Users successfully connect" $ \ user otherUser -> runStateTest $ do put $ Map.fromList [toDBEntry user, toDBEntry otherUser] actual <- post lookupUser updateUser (show $ userId user) (show $ userId otherUser) db <- get return $ isOK actual && any (elem otherUser . connectedUsers) (Map.lookup (userId user) db)
Here I'm inlining test cases as anonymous functions - this time expressing the tests as QuickCheck properties. I'll later return to the runStateTest helper function, but first I want to focus on the test body itself. It's written in do notation, and specifically, it runs in the State DB monad.
user and otherUser are input arguments to the property. These are both User values, since the test also defines Arbitrary instances for that type (not shown in this article; see the source code repository for details).
The first step in the test is to 'save' both users in the Fake database. This is easily done by converting each User value to a database entry:
toDBEntry :: User -> (Integer, User) toDBEntry = userId &&& id
Recall that the Fake database is nothing but an alias over Map Integer User, so the only operation required to turn a User into a database entry is to extract the key.
The next step in the test is to exercise the SUT, passing the test-specific lookupUser and updateUser Test Doubles to the post function, together with the user IDs converted to String values.
In the assert phase of the test, it first extracts the current state of the database, using the State library's built-in get function. It then verifies that actual represents a 200 OK value, and that the user entry in the database now contains otherUser as a connected user.
Missing user test case #
While there's one happy-path test case, there's four other test cases left. One of these is when the first user doesn't exist:
testProperty "Users don't connect when user doesn't exist" $ \ (Positive i) otherUser -> runStateTest $ do let db = Map.fromList [toDBEntry otherUser] put db let uniqueUserId = show $ userId otherUser + i actual <- post lookupUser updateUser uniqueUserId (show $ userId otherUser) assertPostFailure db actual
What ought to trigger this test case is that the 'first' user doesn't exist, even if the otherUser does exist. For this reason, the test inserts the otherUser into the Fake database.
Since the test is a QuickCheck property, i could be any positive Integer value - including the userId of otherUser. In order to properly exercise the test case, however, you'll need to call the post function with a uniqueUserId - thas it: an ID which is guaranteed to not be equal to the userId of otherUser. There's several options for achieving this guarantee (including, as you'll see soon, the ==> operator), but a simple way is to add a non-zero number to the number you need to avoid.
You then exercise the post function and, as a verification, call a reusable assertPostFailure function:
assertPostFailure :: (Eq s, Monad m) => s -> HttpResponse a -> StateT s m Bool assertPostFailure stateBefore resp = do stateAfter <- get let stateDidNotChange = stateBefore == stateAfter return $ stateDidNotChange && isBadRequest resp
This function verifies that the state of the database didn't change, and that the response value represents a 400 Bad Request HTTP response. This verification doesn't actually verify that the error message associated with the BadRequest case is the expected message, like in the previous article. This would, however, involve a fairly trivial change to the code.
Missing other user test case #
Similar to the above test case, users will also fail to connect if the 'other user' doesn't exist. The property is almost identical:
testProperty "Users don't connect when other user doesn't exist" $ \ (Positive i) user -> runStateTest $ do let db = Map.fromList [toDBEntry user] put db let uniqueOtherUserId = show $ userId user + i actual <- post lookupUser updateUser (show $ userId user) uniqueOtherUserId assertPostFailure db actual
Since this test body is so similar to the previous test, I'm not going to give you a detailed walkthrough. I did, however, promise to describe the runStateTest helper function:
runStateTest :: State (Map k a) b -> b runStateTest = flip evalState Map.empty
Since this is a one-liner, you could also write all the tests by simply in-lining that little expression, but I thought that it made the tests more readable to give this function an explicit name.
It takes any State (Map k a) b and runs it with an empty map. Thus, all State-valued functions, like the tests, must explicitly put data into the state. This is also what the tests do.
Notice that all the tests return State values. For example, the assertPostFailure function returns StateT s m Bool, of which State s Bool is an alias. This fits State (Map k a) b when s is Map k a, which again is aliased to DB. Reducing all of this, the tests are simply functions that return Bool.
Invalid user ID test cases #
Finally, you can also cover the two test cases where one of the user IDs is invalid:
testProperty "Users don't connect when user Id is invalid" $ \ s otherUser -> isIdInvalid s ==> runStateTest $ do let db = Map.fromList [toDBEntry otherUser] put db actual <- post lookupUser updateUser s (show $ userId otherUser) assertPostFailure db actual , testProperty "Users don't connect when other user Id is invalid" $ \ s user -> isIdInvalid s ==> runStateTest $ do let db = Map.fromList [toDBEntry user] put db actual <- post lookupUser updateUser (show $ userId user) s assertPostFailure db actual
Both of these properties take a String value s as input. When QuickCheck generates a String, that could be any String value. Both tests require that the value is an invalid user ID. Specifically, it mustn't be possible to parse the string into an Integer. If you don't constrain QuickCheck, it'll generate various strings, including e.g. "8" and other strings that can be parsed as numbers.
In the above "Users don't connect when user doesn't exist" test, you saw how one way to explicitly model constraints on data is to project a seed value in such a way that the constraint always holds. Another way is to use QuickCheck's built-in ==> operator to filter out undesired values. In this example, both tests employ the isIdInvalid function:
isIdInvalid :: String -> Bool isIdInvalid s = let userInt = readMaybe s :: Maybe Integer in isNothing userInt
Using isIdInvalid with the ==> operator guarantees that s is an invalid ID.
Summary #
While state-based testing may, at first, sound incompatible with strictly functional programming, it's not only possible with the State monad, but even, with good language support, easily done.
The tests shown in this article aren't concerned with the interactions between the SUT and its dependencies. Instead, they compare the initial state with the state after exercising the SUT. Comparing values, even complex data structures such as maps, tends to be trivial in functional programming. Immutable values typically have built-in structural equality (in Haskell signified by the automatic Eq type class), which makes comparing them trivial.
Now that we know that state-based testing is possible even with Haskell's enforced purity, it should be clear that we can repeat the feat in F#.
Code quality isn't software quality
A trivial observation made explicit.
You'd think that it's evident that code quality and software quality are two different things. Yet, I often see or hear arguments about one or the other that indicates to me that some people don't make that distinction. I wonder why; I do.
Software quality #
There's a school of thought leaders who advocate that, ultimately, we write code to solve problems, or to improve life, for people. I have nothing against that line of reasoning; it's just not one that I pursue much. Why should I use my energy on this message when someone like Dan North does it so much better than I could?
Dan North is far from the only person making the point that our employers, or clients, or end-users don't care about the code; he is, in my opinion, one of the best communicators in that field. It makes sense that, with that perspective on software development, you'd invent something like behaviour-driven development.
The evaluation criterion used in this discourse is one of utility. Does the software serve a purpose? Does it do it well?
In that light, quality software is software that serves its purpose beyond expectation. It rarely, if ever, crashes. It's easy to use. It's sufficiently responsive. It's pretty. It works both on-line and off-line. Attributes like that are externally observable qualities.
You can write quality software in many different languages, using various styles. When you evaluate the externally observable qualities of software, the code is invisible. It's not part of the evaluation.
It seems to me that some people try to make an erroneous conclusion from this premise. They'd say that since no employer, client, or end user evaluates the software based on the code that produced it, then no one cares about the code.
Code quality #
It's easy to refute that argument. All you have to do is to come up with a counter-example. You just have to find one person who cares about the code. That's easy.
You care about the code.
Perhaps you react negatively to that assertion. Perhaps you say: "No! I'm not one of those effete aesthetes who only program in Plankalkül." Fine. Maybe you're not the type who likes to polish the code; maybe you're the practical, down-to-earth type who just likes to get stuff done, so that your employer/client/end-user is happy.
Even so, I think that you still care about the code. Have you ever looked with bewilderment at a piece of code and thought: "Who the hell wrote this piece of shit!?" How many WTFs/m is your code?
I think every programmer cares about their code bases; if not in an active manner, then at least in a passive way. Bad code can seriously impede progress. I've seen more than one organisation effectively go out of business because of bad legacy code.
Code quality is when you care about the readability and malleability of the code. It's when you care about the code's ability to sustain the business, not only today, but also in the future.
Sustainable code #
I often get the impression that some people look at code quality and software quality as a (false) dichotomy.

Such arguments often seem to imply that you can't have one without sacrificing the other. You must choose.
The reality is, of course, that you can do both.
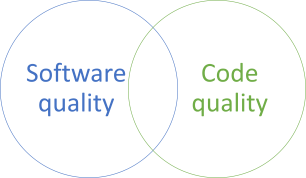
At the intersection between software and code quality the code sustains the business both now, and in the future.
Yes, you should write code such that it produces software that provides value here and now, but you should also do your best to enable it to provide value in the future. This is sustainable code. It's code that can sustain the organisation during its lifetime.
No gold-plating #
To be clear: this is not a call for gold plating or speculative generality. You probably can't predict the future needs of the stake-holders.
Quality code doesn't have to be able to perfectly address all future requirements. In order to be sustainable, though, it should be easy to modify in the future, or perhaps just easy to throw away and rewrite. I think a good start is to write humane code; code that fits in your brain.
At least, do your best to avoid writing legacy code.
Summary #
Software quality and code quality can co-exist. You can write quality code that compiles to quality software, but one doesn't imply the other. These are two independent quality dimensions.
An example of interaction-based testing in C#
An example of using Mocks and Stubs for unit testing in C#.
This article is an instalment in an article series about how to move from interaction-based testing to state-based testing. In this series, you'll be presented with some alternatives to interaction-based testing with Mocks and Stubs. Before we reach the alternatives, however, we need to establish an example of interaction-based testing, so that you have something against which you can compare those alternatives. In this article, I'll present a simple example, in the form of C# code.
The code shown in this article is available on GitHub.
Connect two users #
For the example, I'll use a simplified version of the example that runs through my two Clean Coders videos, Church Visitor and Preserved in translation.
The desired functionality is simple: implement a REST API that enables one user to connect to another user. You could imagine some sort of social media platform, or essentially any sort of online service where users might be interested in connecting with, or following, other users.
In essence, you could imagine that a user interface makes an HTTP POST request against our REST API:
POST /connections/42 HTTP/1.1
Content-Type: application/json
{
"otherUserId": 1337
}
Let's further imagine that we implement the desired functionality with a C# method with this signature:
public IHttpActionResult Post(string userId, string otherUserId)
We'll return to the implementation later, but I want to point out a few things.
First, notice that both userId and otherUserId are string arguments. While the above example encodes both IDs as numbers, essentially, both URLs and JSON are text-based. Following Postel's law, the method should also accept JSON like { "otherUserId": "1337" }. That's the reason the Post method takes string arguments instead of int arguments.
Second, the return type is IHttpActionResult. Don't worry if you don't know that interface. It's just a way to model HTTP responses, such as 200 OK or 400 Bad Request.
Depending on the input values, and the state of the application, several outcomes are possible:
| Other user | ||||
|---|---|---|---|---|
| Found | Not found | Invalid | ||
| User | Found | Other user | "Other user not found." |
"Invalid ID for other user." |
| Not found | "User not found." |
"User not found." |
"User not found." |
|
| Invalid | "Invalid user ID." |
"Invalid user ID." |
"Invalid user ID." |
|
"foo" that doesn't represent a number), then it doesn't matter if the other user exists. Likewise, even if the first user ID is well-formed, it might still be the case that no user with that ID exists in the database.
The assumption here is that the underlying user database uses integers as row IDs.
When both users are found, the other user should be returned in the HTTP response, like this:
HTTP/1.1 200 OK
Content-Type: application/json
{
"id": 1337,
"name": "ploeh",
"connections": [{
"id": 42,
"name": "fnaah"
}, {
"id": 2112,
"name": "ndøh"
}]
}
The intent is that when the first user (e.g. the one with the 42 ID) successfully connects to user 1337, a user interface can show the full details of the other user, including the other user's connections.
Happy path test case #
Since there's five distinct outcomes, you ought to write at least five test cases. You could start with the happy-path case, where both user IDs are well-formed and the users exist.
All tests in this article use xUnit.net 2.3.1, Moq 4.8.1, and AutoFixture 4.1.0.
[Theory, UserManagementTestConventions] public void UsersSuccessfullyConnect( [Frozen]Mock<IUserReader> readerTD, [Frozen]Mock<IUserRepository> repoTD, User user, User otherUser, ConnectionsController sut) { readerTD .Setup(r => r.Lookup(user.Id.ToString())) .Returns(Result.Success<User, IUserLookupError>(user)); readerTD .Setup(r => r.Lookup(otherUser.Id.ToString())) .Returns(Result.Success<User, IUserLookupError>(otherUser)); var actual = sut.Post(user.Id.ToString(), otherUser.Id.ToString()); var ok = Assert.IsAssignableFrom<OkNegotiatedContentResult<User>>( actual); Assert.Equal(otherUser, ok.Content); repoTD.Verify(r => r.Update(user)); Assert.Contains(otherUser.Id, user.Connections); }
To be clear, as far as Overspecified Software goes, this isn't a bad test. It only has two Test Doubles, readerTD and repoTD. My current habit is to name any Test Double with the TD suffix (for Test Double), instead of explicitly naming them readerStub and repoMock. The latter would have been more correct, though, since the Mock<IUserReader> object is consistently used as a Stub, whereas the Mock<IUserRepository> object is used only as a Mock. This is as it should be, because it follows the rule that you should use Mocks for Commands, Stubs for Queries.
IUserRepository.Update is, indeed a Command:
public interface IUserRepository { void Update(User user); }
Since the method returns void, unless it doesn't do anything at all, the only thing it can do is to somehow change the state of the system. The test verifies that IUserRepository.Update was invoked with the appropriate input argument.
This is fine.
I'd like to emphasise that this isn't the biggest problem with this test. A Mock like this verifies that a desired interaction took place. If IUserRepository.Update isn't called in this test case, it would constitute a defect. The software wouldn't have the desired behaviour, so the test ought to fail.
The signature of IUserReader.Lookup, on the other hand, implies that it's a Query:
public interface IUserReader { IResult<User, IUserLookupError> Lookup(string id); }
In C# and most other languages, you can't be sure that implementations of the Lookup method have no side effects. If, however, we assume that the code base in question obeys the Command Query Separation principle, then, by elimination, this must be a Query (since it's not a Command, because the return type isn't void).
For a detailed walkthrough of the IResult<S, E> interface, see my Preserved in translation video. It's just an Either with different terminology, though. Right is equivalent to SuccessResult, and Left corresponds to ErrorResult.
The test configures the IUserReader Stub twice. It's necessary to give the Stub some behaviour, but unfortunately you can't just use Moq's It.IsAny<string>() for configuration, because in order to model the test case, the reader should return two different objects for two different inputs.
This starts to look like Overspecified Software.
Ideally, a Stub should just be present to 'make happy noises' in case the SUT decides to interact with the dependency, but with these two Setup calls, the interaction is overspecified. The test is tightly coupled to how the SUT is implemented. If you change the interaction implemented in the Post method, you could break the test.
In any case, what the test does specify is that when you query the UserReader, it returns a Success object for both user lookups, a 200 OK result is returned, and the Update method was called with user.
Invalid user ID test case #
If the first user ID is invalid (i.e. not an integer) then the return value should represent 400 Bad Request and the message body should indicate as much. This test verifies that this is the case:
[Theory, UserManagementTestConventions] public void UsersFailToConnectWhenUserIdIsInvalid( [Frozen]Mock<IUserReader> readerTD, [Frozen]Mock<IUserRepository> repoTD, string userId, User otherUser, ConnectionsController sut) { Assert.False(int.TryParse(userId, out var _)); readerTD .Setup(r => r.Lookup(userId)) .Returns(Result.Error<User, IUserLookupError>( UserLookupError.InvalidId)); var actual = sut.Post(userId, otherUser.Id.ToString()); var err = Assert.IsAssignableFrom<BadRequestErrorMessageResult>(actual); Assert.Equal("Invalid user ID.", err.Message); repoTD.Verify(r => r.Update(It.IsAny<User>()), Times.Never()); }
This test starts with a Guard Assertion that userId isn't an integer. This is mostly an artefact of using AutoFixture. Had you used specific example values, then this wouldn't have been necessary. On the other hand, had you written the test case as a property-based test, it would have been even more important to explicitly encode such a constraint.
Perhaps a better design would have been to use a domain-specific method to check for the validity of the ID, but there's always room for improvement.
This test is more brittle than it looks. It only defines what should happen when IUserReader.Lookup is called with the invalid userId. What happens if IUserReader.Lookup is called with the Id associated with otherUser?
This currently doesn't matter, so the test passes.
The test relies, however, on an implementation detail. This test implicitly assumes that the implementation short-circuits as soon as it discovers that userId is invalid. What if, however, you'd made some performance measurements, and you'd discovered that in most cases, the software would run faster if you Lookup both users in parallel?
Such an innocuous performance optimisation could break the test, because the behaviour of readerTD is unspecified for all other cases than for userId.
Invalid ID for other user test case #
What happens if the other user ID is invalid? This unit test exercises that test case:
[Theory, UserManagementTestConventions] public void UsersFailToConnectWhenOtherUserIdIsInvalid( [Frozen]Mock<IUserReader> readerTD, [Frozen]Mock<IUserRepository> repoTD, User user, string otherUserId, ConnectionsController sut) { Assert.False(int.TryParse(otherUserId, out var _)); readerTD .Setup(r => r.Lookup(user.Id.ToString())) .Returns(Result.Success<User, IUserLookupError>(user)); readerTD .Setup(r => r.Lookup(otherUserId)) .Returns(Result.Error<User, IUserLookupError>( UserLookupError.InvalidId)); var actual = sut.Post(user.Id.ToString(), otherUserId); var err = Assert.IsAssignableFrom<BadRequestErrorMessageResult>(actual); Assert.Equal("Invalid ID for other user.", err.Message); repoTD.Verify(r => r.Update(It.IsAny<User>()), Times.Never()); }
Notice how the test configures readerTD twice: once for the Id associated with user, and once for otherUserId. Why does this test look different from the previous test?
Why is the first Setup required? Couldn't the arrange phase of the test just look like the following?
Assert.False(int.TryParse(otherUserId, out var _)); readerTD .Setup(r => r.Lookup(otherUserId)) .Returns(Result.Error<User, IUserLookupError>( UserLookupError.InvalidId));
If you wrote the test like that, it would resemble the previous test (UsersFailToConnectWhenUserIdIsInvalid). The problem, though, is that if you remove the Setup for the valid user, the test fails.
This is another example of how the use of interaction-based testing makes the tests brittle. The tests are tightly coupled to the implementation.
Missing users test cases #
I don't want to belabour the point, so here's the two remaining tests:
[Theory, UserManagementTestConventions] public void UsersDoNotConnectWhenUserDoesNotExist( [Frozen]Mock<IUserReader> readerTD, [Frozen]Mock<IUserRepository> repoTD, string userId, User otherUser, ConnectionsController sut) { readerTD .Setup(r => r.Lookup(userId)) .Returns(Result.Error<User, IUserLookupError>( UserLookupError.NotFound)); var actual = sut.Post(userId, otherUser.Id.ToString()); var err = Assert.IsAssignableFrom<BadRequestErrorMessageResult>(actual); Assert.Equal("User not found.", err.Message); repoTD.Verify(r => r.Update(It.IsAny<User>()), Times.Never()); } [Theory, UserManagementTestConventions] public void UsersDoNotConnectWhenOtherUserDoesNotExist( [Frozen]Mock<IUserReader> readerTD, [Frozen]Mock<IUserRepository> repoTD, User user, int otherUserId, ConnectionsController sut) { readerTD .Setup(r => r.Lookup(user.Id.ToString())) .Returns(Result.Success<User, IUserLookupError>(user)); readerTD .Setup(r => r.Lookup(otherUserId.ToString())) .Returns(Result.Error<User, IUserLookupError>( UserLookupError.NotFound)); var actual = sut.Post(user.Id.ToString(), otherUserId.ToString()); var err = Assert.IsAssignableFrom<BadRequestErrorMessageResult>(actual); Assert.Equal("Other user not found.", err.Message); repoTD.Verify(r => r.Update(It.IsAny<User>()), Times.Never()); }
Again, notice the asymmetry of these two tests. The top one passes with only one Setup of readerTD, whereas the bottom test requires two in order to pass.
You can add a second Setup to the top test to make the two tests equivalent, but people often forget to take such precautions. The result is Fragile Tests.
Post implementation #
In the spirit of test-driven development, I've shown you the tests before the implementation.
public class ConnectionsController : ApiController { public ConnectionsController( IUserReader userReader, IUserRepository userRepository) { UserReader = userReader; UserRepository = userRepository; } public IUserReader UserReader { get; } public IUserRepository UserRepository { get; } public IHttpActionResult Post(string userId, string otherUserId) { var userRes = UserReader.Lookup(userId).SelectError( error => error.Accept(UserLookupError.Switch( onInvalidId: "Invalid user ID.", onNotFound: "User not found."))); var otherUserRes = UserReader.Lookup(otherUserId).SelectError( error => error.Accept(UserLookupError.Switch( onInvalidId: "Invalid ID for other user.", onNotFound: "Other user not found."))); var connect = from user in userRes from otherUser in otherUserRes select Connect(user, otherUser); return connect.SelectBoth(Ok, BadRequest).Bifold(); } private User Connect(User user, User otherUser) { user.Connect(otherUser); UserRepository.Update(user); return otherUser; } }
This is a simplified version of the code shown towards the end of my Preserved in translation video, so I'll refer you there for a detailed explanation.
Summary #
The premise of Refactoring is that in order to be able to refactor, the "precondition is [...] solid tests". In reality, many development organisations have the opposite experience. When programmers attempt to make changes to how their code is organised, tests break. In xUnit Test Patterns this problem is called Fragile Tests, and the cause is often Overspecified Software. This means that tests are tightly coupled to implementation details of the System Under Test (SUT).
It's easy to inadvertently fall into this trap when you use Mocks and Stubs, even when you follow the rule of using Mocks for Commands and Stubs for Queries. In my experience, it's often the explicit configuration of Stubs that tend to make tests brittle. A Command represents an intentional side effect, and you want to verify that such a side effect takes place. A Query, on the other hand, has no side effect, so a black-box test shouldn't be concerned with any interactions involving Queries.
Yet, using an 'isolation framework' such as Moq, FakeItEasy, NSubstitute, and so on, will pull you towards overspecifying the interactions the SUT has with its Query dependencies.
How can we improve? One strategy is to move towards a more functional design, which is intrinsically testable. In the next article, you'll see how to rewrite both tests and implementation in Haskell.
Comments
Hi Mark,
I think I came to the same conclusion (maybe not the same solution), meaning you can't write solid tests when mocking all the dependencies interaction : all these dependencies interaction are implementation details (even the database system you chose). For writing solid tests I chose to write my tests like this : start all the services I can in test environment (database, queue ...), mock only things I have no choice (external PSP or Google Captcha), issue command (using MediatR) and check the result with a query. You can find some of my work here . The work is not done on all the tests but this is the way I want to go. Let me know what you think about it.
I could have launched the tests at the Controller level but I chose Command and Query handler.
Can't wait to see your solution
Rémi, thank you for writing. Hosting services as part of a test run can be a valuable addition to an overall testing or release pipeline. It's reminiscent of the approach taken in GOOS. I've also touched on this option in my Pluralsight course Outside-In Test-Driven Development. This is, however, a set of tests I would identify as belonging towards the top of a Test Pyramid. In my experience, such tests tend to run (an order of magnitude) slower than unit tests.
That doesn't preclude their use. Depending on circumstances, I still prefer having tests like that. I think that I've written a few applications where tests like that constituted the main body of unit tests.
I do, however, also find this style of testing too limiting in many situation. I tend to prefer 'real' unit tests, since they tend to be easier to write, and they execute faster.
Apart from performance and maintainability concerns, one problem that I often see with integration tests is that it's practically impossible to cover all edge cases. This tends to lead to either bug-ridden software, or unmaintainable test suites.
Still, I think that, ultimately, having enough experience with different styles of testing enables one to make an informed choice. That's my purpose with these articles: to point out that alternatives exist.
From interaction-based to state-based testing
Indiscriminate use of Mocks and Stubs can lead to brittle test suites. A more functional design can make state-based testing easier, leading to more robust test suites.
The original premise of Refactoring was that in order to refactor, you must have a trustworthy suite of unit tests, so that you can be confident that you didn't break any functionality.
The idea is that you can change how the code is organised, and as long as you don't break any tests, all is good. The experience that most people seem to have, though, is that when they change something in the code, tests break."to refactor, the essential precondition is [...] solid tests"
This is a well-known test smell. In xUnit Test Patterns this is called Fragile Test, and it's often caused by Overspecified Software. Even if you follow the proper practice of using Mocks for Commands, Stubs for Queries, you can still end up with a code base where the tests are highly coupled to implementation details of the software.
The cause is often that when relying on Mocks and Stubs, test verification hinges on how the System Under Test (SUT) interacts with its dependencies. For that reason, we can call such tests interaction-based tests. For more information, watch my Pluralsight course Advanced Unit Testing.
Lessons from functional programming #
Another way to verify the outcome of a test is to inspect the state of the system after exercising the SUT. We can, quite naturally, call this state-based testing. In object-oriented design, this can lead to other problems. Nat Pryce has pointed out that state-based testing breaks encapsulation.
Interestingly, in his article, Nat Pryce concludes:
"I have come to think of object oriented programming as an inversion of functional programming. In a lazy functional language data is pulled through functions that transform the data and combine it into a single result. In an object oriented program, data is pushed out in messages to objects that transform the data and push it out to other objects for further processing."That's an impressively perceptive observation to make in 2004. I wish I was that perspicacious, but I only reached a similar conclusion ten years later.
Functional programming is based on the fundamental principle of referential transparency, which, among other things, means that data must be immutable. Thus, no objects change state. Instead, functions can return data that contains immutable state. In unit tests, you can verify that return values are as expected. Functional design is intrinsically testable; we can consider it a kind of state-based testing, although the states you'd be verifying are immutable return values.
In this article series, you'll see three different styles of testing, from interaction-based testing with Mocks and Stubs in C#, over strictly functional state-based testing in Haskell, to pragmatic state-based testing in F#, finally looping back to C# to apply the lessons from functional programming.
- An example of interaction-based testing in C#
- An example of state-based testing in Haskell
- An example of state based-testing in F#
- An example of state-based testing in C#
- A pure Test Spy
Summary #
Adopting a more functional design, even in a fundamentally object-oriented language like C# can, in my experience, lead to a more sustainable code base. Various maintenance tasks become easier, including unit tests. Functional programming, however, is no panacea. My intent with this article series is only to inspire; to show alternatives to the ways things are normally done. Adopting one of those alternatives could lead to better code, but you must still exercise context-specific judgement.
Asynchronous Injection
How to combine asynchronous programming with Dependency Injection without leaky abstractions.
C# has decent support for asynchronous programming, but it ultimately leads to leaky abstractions. This is often conspicuous when combined with Dependency Injection (DI). This leads to frequently asked questions around the combination of DI and asynchronous programming. This article outlines the problem and suggests an alternative.
The code base supporting this article is available on GitHub.
A synchronous example #
In this article, you'll see various stages of a small sample code base that pretends to implement the server-side behaviour of an on-line restaurant reservation system (my favourite example scenario). In the first stage, the code uses DI, but no asynchronous I/O.
At the boundary of the application, a Post method receives a Reservation object:
public class ReservationsController : ControllerBase { public ReservationsController(IMaîtreD maîtreD) { MaîtreD = maîtreD; } public IMaîtreD MaîtreD { get; } public IActionResult Post(Reservation reservation) { int? id = MaîtreD.TryAccept(reservation); if (id == null) return InternalServerError("Table unavailable"); return Ok(id.Value); } }
The Reservation object is just a simple bundle of properties:
public class Reservation { public DateTimeOffset Date { get; set; } public string Email { get; set; } public string Name { get; set; } public int Quantity { get; set; } public bool IsAccepted { get; set; } }
In a production code base, I'd favour a separation of DTOs and domain objects with proper encapsulation, but in order to keep the code example simple, here the two roles are combined.
The Post method simply delegates most work to an injected IMaîtreD object, and translates the return value to an HTTP response.
The code example is overly simplistic, to the point where you may wonder what is the point of DI, since it seems that the Post method doesn't perform any work itself. A slightly more realistic example includes some input validation and mapping between layers.
The IMaîtreD implementation is this:
public class MaîtreD : IMaîtreD { public MaîtreD(int capacity, IReservationsRepository repository) { Capacity = capacity; Repository = repository; } public int Capacity { get; } public IReservationsRepository Repository { get; } public int? TryAccept(Reservation reservation) { var reservations = Repository.ReadReservations(reservation.Date); int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return null; reservation.IsAccepted = true; return Repository.Create(reservation); } }
The protocol for the TryAccept method is that it returns the reservation ID if it accepts the reservation. If the restaurant has too little remaining Capacity for the requested date, it instead returns null. Regular readers of this blog will know that I'm no fan of null, but this keeps the example realistic. I'm also no fan of state mutation, but the example does that as well, by setting IsAccepted to true.
Introducing asynchrony #
The above example is entirely synchronous, but perhaps you wish to introduce some asynchrony. For example, the IReservationsRepository implies synchrony:
public interface IReservationsRepository { Reservation[] ReadReservations(DateTimeOffset date); int Create(Reservation reservation); }
In reality, though, you know that the implementation of this interface queries and writes to a relational database. Perhaps making this communication asynchronous could improve application performance. It's worth a try, at least.
How do you make something asynchronous in C#? You change the return type of the methods in question. Therefore, you have to change the IReservationsRepository interface:
public interface IReservationsRepository { Task<Reservation[]> ReadReservations(DateTimeOffset date); Task<int> Create(Reservation reservation); }
The Repository methods now return Tasks. This is the first leaky abstraction. From the Dependency Inversion Principle it follows that
The"clients [...] own the abstract interfaces"
MaîtreD class is the client of the IReservationsRepository interface, which should be designed to support the needs of that class. MaîtreD doesn't need IReservationsRepository to be asynchronous.
The change of the interface has nothing to with what MaîtreD needs, but rather with a particular implementation of the IReservationsRepository interface. Because this implementation queries and writes to a relational database, this implementation detail leaks into the interface definition. It is, therefore, a leaky abstraction.
On a more practical level, accommodating the change is easily done. Just add async and await keywords in appropriate places:
public async Task<int?> TryAccept(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return null; reservation.IsAccepted = true; return await Repository.Create(reservation); }
In order to compile, however, you also have to fix the IMaîtreD interface:
public interface IMaîtreD { Task<int?> TryAccept(Reservation reservation); }
This is the second leaky abstraction, and it's worse than the first. Perhaps you could successfully argue that it was conceptually acceptable to model IReservationsRepository as asynchronous. After all, a Repository conceptually represents a data store, and these are generally out-of-process resources that require I/O.
The IMaîtreD interface, on the other hand, is a domain object. It models how business is done, not how data should be accessed. Why should business logic be asynchronous?
It's hardly news that async and await is infectious. Once you introduce Tasks, it's async all the way!
That doesn't mean that asynchrony isn't one big leaky abstraction. It is.
You've probably already realised what this means in the context of the little example. You must also patch the Post method:
public async Task<IActionResult> Post(Reservation reservation) { int? id = await MaîtreD.TryAccept(reservation); if (id == null) return InternalServerError("Table unavailable"); return Ok(id.Value); }
Pragmatically, I'd be ready to accept the argument that this isn't a big deal. After all, you just replace all return values with Tasks, and add async and await keywords where they need to go. This hardly impacts the maintainability of a code base.
In C#, I'd be inclined to just acknowledge that, hey, there's a leaky abstraction. Moving on...
On the other hand, sometimes people imply that it has to be like this. That there is no other way.
Falsifiable claims like that often get my attention. Oh, really?!
Move impure interactions to the boundary of the system #
We can pretend that Task<T> forms a functor. It's also a monad. Monads are those incredibly useful programming abstractions that have been propagating from their origin in statically typed functional programming languages to more mainstream languages like C#.
In functional programming, impure interactions happen at the boundary of the system. Taking inspiration from functional programming, you can move the impure interactions to the boundary of the system.
In the interest of keeping the example simple, I'll only move the impure operations one level out: from MaîtreD to ReservationsController. The approach can be generalised, although you may have to look into how to handle pure interactions.
Where are the impure interactions in MaîtreD? They are in the two interactions with IReservationsRepository. The ReadReservations method is non-deterministic, because the same input value can return different results, depending on the state of the database when you call it. The Create method causes a side effect to happen, because it creates a row in the database. This is one way in which the state of the database could change, which makes ReadReservations non-deterministic. Additionally, Create also violates Command Query Separation (CQS) by returning the ID of the row it creates. This, again, is non-deterministic, because the same input value will produce a new return value every time the method is called. (Incidentally, you should design Create methods so that they don't violate CQS.)
Move reservations to a method argument #
The first refactoring is the easiest. Move the ReadReservations method call to the application boundary. In the above state of the code, the TryAccept method unconditionally calls Repository.ReadReservations to populate the reservations variable. Instead of doing this from within TryAccept, just pass reservations as a method argument:
public async Task<int?> TryAccept( Reservation[] reservations, Reservation reservation) { int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return null; reservation.IsAccepted = true; return await Repository.Create(reservation); }
This no longer compiles until you also change the IMaîtreD interface:
public interface IMaîtreD { Task<int?> TryAccept(Reservation[] reservations, Reservation reservation); }
You probably think that this is a much worse leaky abstraction than returning a Task. I'd be inclined to agree, but trust me: ultimately, this will matter not at all.
When you move an impure operation outwards, it means that when you remove it from one place, you must add it to another. In this case, you'll have to query the Repository from the ReservationsController, which also means that you need to add the Repository as a dependency there:
public class ReservationsController : ControllerBase { public ReservationsController( IMaîtreD maîtreD, IReservationsRepository repository) { MaîtreD = maîtreD; Repository = repository; } public IMaîtreD MaîtreD { get; } public IReservationsRepository Repository { get; } public async Task<IActionResult> Post(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); int? id = await MaîtreD.TryAccept(reservations, reservation); if (id == null) return InternalServerError("Table unavailable"); return Ok(id.Value); } }
This is a refactoring in the true sense of the word. It just reorganises the code without changing the overall behaviour of the system. Now the Post method has to query the Repository before it can delegate the business decision to MaîtreD.
Separate decision from effect #
As far as I can tell, the main reason to use DI is because some impure interactions are conditional. This is also the case for the TryAccept method. Only if there's sufficient remaining capacity does it call Repository.Create. If it detects that there's too little remaining capacity, it immediately returns null and doesn't call Repository.Create.
In object-oriented code, DI is the most common way to decouple decisions from effects. Imperative code reaches a decision and calls a method on an object based on that decision. The effect of calling the method can vary because of polymorphism.
In functional programming, you typically use a functor like Maybe or Either to separate decisions from effects. You can do the same here.
The protocol of the TryAccept method already communicates the decision reached by the method. An int value is the reservation ID; this implies that the reservation was accepted. On the other hand, null indicates that the reservation was declined.
You can use the same sort of protocol, but instead of returning a Nullable<int>, you can return a Maybe<Reservation>:
public async Task<Maybe<Reservation>> TryAccept( Reservation[] reservations, Reservation reservation) { int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return Maybe.Empty<Reservation>(); reservation.IsAccepted = true; return reservation.ToMaybe(); }
This completely decouples the decision from the effect. By returning Maybe<Reservation>, the TryAccept method communicates the decision it made, while leaving further processing entirely up to the caller.
In this case, the caller is the Post method, which can now compose the result of invoking TryAccept with Repository.Create:
public async Task<IActionResult> Post(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); Maybe<Reservation> m = await MaîtreD.TryAccept(reservations, reservation); return await m .Select(async r => await Repository.Create(r)) .Match( nothing: Task.FromResult(InternalServerError("Table unavailable")), just: async id => Ok(await id)); }
Notice that the Post method never attempts to extract 'the value' from m. Instead, it injects the desired behaviour (Repository.Create) into the monad. The result of calling Select with an asynchronous lambda expression like that is a Maybe<Task<int>>, which is a awkward combination. You can fix that later.
The Match method is the catamorphism for Maybe. It looks exactly like the Match method on the Church-encoded Maybe. It handles both the case when m is empty, and the case when m is populated. In both cases, it returns a Task<IActionResult>.
Synchronous domain logic #
At this point, you have a compiler warning in your code:
Warning CS1998 This async method lacks 'await' operators and will run synchronously. Consider using the 'await' operator to await non-blocking API calls, or 'await Task.Run(...)' to do CPU-bound work on a background thread.Indeed, the current incarnation of
TryAccept is synchronous, so remove the async keyword and change the return type:
public Maybe<Reservation> TryAccept( Reservation[] reservations, Reservation reservation) { int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return Maybe.Empty<Reservation>(); reservation.IsAccepted = true; return reservation.ToMaybe(); }
This requires a minimal change to the Post method: it no longer has to await TryAccept:
public async Task<IActionResult> Post(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); Maybe<Reservation> m = MaîtreD.TryAccept(reservations, reservation); return await m .Select(async r => await Repository.Create(r)) .Match( nothing: Task.FromResult(InternalServerError("Table unavailable")), just: async id => Ok(await id)); }
Apart from that, this version of Post is the same as the one above.
Notice that at this point, the domain logic (TryAccept) is no longer asynchronous. The leaky abstraction is gone.
Redundant abstraction #
The overall work is done, but there's some tidying up remaining. If you review the TryAccept method, you'll notice that it no longer uses the injected Repository. You might as well simplify the class by removing the dependency:
public class MaîtreD : IMaîtreD { public MaîtreD(int capacity) { Capacity = capacity; } public int Capacity { get; } public Maybe<Reservation> TryAccept( Reservation[] reservations, Reservation reservation) { int reservedSeats = reservations.Sum(r => r.Quantity); if (Capacity < reservedSeats + reservation.Quantity) return Maybe.Empty<Reservation>(); reservation.IsAccepted = true; return reservation.ToMaybe(); } }
The TryAccept method is now deterministic. The same input will always return the same input. This is not yet a pure function, because it still has a single side effect: it mutates the state of reservation by setting IsAccepted to true. You could, however, without too much trouble refactor Reservation to an immutable Value Object.
This would enable you to write the last part of the TryAccept method like this:
return reservation.Accept().ToMaybe();
In any case, the method is close enough to be pure that it's testable. The interactions of TryAccept and any client code (including unit tests) is completely controllable and observable by the client.
This means that there's no reason to Stub it out. You might as well just use the function directly in the Post method:
public class ReservationsController : ControllerBase { public ReservationsController( int capacity, IReservationsRepository repository) { Capacity = capacity; Repository = repository; } public int Capacity { get; } public IReservationsRepository Repository { get; } public async Task<IActionResult> Post(Reservation reservation) { var reservations = await Repository.ReadReservations(reservation.Date); Maybe<Reservation> m = new MaîtreD(Capacity).TryAccept(reservations, reservation); return await m .Select(async r => await Repository.Create(r)) .Match( nothing: Task.FromResult(InternalServerError("Table unavailable")), just: async id => Ok(await id)); } }
Notice that ReservationsController no longer has an IMaîtreD dependency.
All this time, whenever you make a change to the TryAccept method signature, you'd also have to fix the IMaîtreD interface to make the code compile. If you worried that all of these changes were leaky abstractions, you'll be happy to learn that in the end, it doesn't even matter. No code uses that interface, so you can delete it.
Grooming #
The MaîtreD class looks fine, but the Post method could use some grooming. I'm not going to tire you with all the small refactoring steps. You can follow them in the GitHub repository if you're interested. Eventually, you could arrive at an implementation like this:
public class ReservationsController : ControllerBase { public ReservationsController( int capacity, IReservationsRepository repository) { Capacity = capacity; Repository = repository; maîtreD = new MaîtreD(capacity); } public int Capacity { get; } public IReservationsRepository Repository { get; } private readonly MaîtreD maîtreD; public async Task<IActionResult> Post(Reservation reservation) { return await Repository.ReadReservations(reservation.Date) .Select(rs => maîtreD.TryAccept(rs, reservation)) .SelectMany(m => m.Traverse(Repository.Create)) .Match(InternalServerError("Table unavailable"), Ok); } }
Now the Post method is just a single, composed asynchronous pipeline. Is it a coincidence that this is possible?
This is no coincidence. This top-level method executes in the 'Task monad', and a monad is, by definition, composable. You can chain operations together, and they don't all have to be asynchronous. Specifically, maîtreD.TryAccept is a synchronous piece of business logic. It's unaware that it's being injected into an asynchronous context. This type of design would be completely run of the mill in F# with its asynchronous workflows.
Summary #
Dependency Injection frequently involves I/O-bound operations. Those typically get hidden behind interfaces so that they can be mocked or stubbed. You may want to access those I/O-bound resources asynchronously, but with C#'s support for asynchronous programming, you'll have to make your abstractions asynchronous.
When you make the leaf nodes in your call graph asynchronous, that design change ripples through the entire code base, forcing you to be async all the way. One result of this is that the domain model must also accommodate asynchrony, although this is rarely required by the logic it implements. These concessions to asynchrony are leaky abstractions.
Pragmatically, it's hardly a big problem. You can use the async and await keywords to deal with the asynchrony, and it's unlikely to, in itself, cause a problem with maintenance.
In functional programming, monads can address asynchrony without introducing sweeping leaky abstractions. Instead of making DI asynchronous, you can inject desired behaviour into an asynchronous context.
Behaviour Injection, not Dependency Injection.
Comments
Hi Mark,
aren't you loading more responsibilities on the ReservationsController? Previously, it only had to delegate all the work to MaîtreD and return an appropriate result, now it additionally fetches reservations from the repository. You are also loading the handling of any errors the reservations repository might throw onto the controller, instead of handling them in the MaîtreD class.
You are also hard wiring a dependency on MaîtreD into the ReservationsController; I thought one of the advantages of DI were to avoid newing up dependencies to concrete implementations outside of a centralized "builder class".
Could you elaborate on these points? Thanks!
Ramon, thank you for writing. Am I loading more responsibilities on the Controller? Yes, I am. Too many? I don't think so.
To be fair, however, this example is unrealistically simplified (in order to make it easily understandable). There isn't much going on, overall, so one has to imagine that more things are happening than is actually the case. For instance, at the beginning of the example, so little is going on in the Controller that I think it'd be fair to ask why it's even necessary to distinguish between a Controller and a MaîtreD class.
Usually, I'd say that the responsibility of a Controller object is to facilitate the translation of what goes on at the boundary of the application and what happens in the domain model. Using the terminology of the ports and adapters architecture, you could say that a Controller's responsibility is to serve as an Adapter between the technology-agnostic domain model and the technology-specific SDKs you'll need to bring into play to communicate with the 'real world'. Talking to databases fits that responsibility, I think.
The MaîtreD class didn't handle any database errors before, so I don't agree that I've moved that responsibility.
When it comes to using a MaîtreD object from inside the Controller, I don't agree that I've 'hard-wired' it. It's not a dependency in the Dependency Injection sense; it's an implementation detail. Notice that it's a private class field.
Is it an 'advantage of DI' that you can "avoid newing up dependencies to concrete implementations outside of a centralized "builder class"?" How is that an advantage? Is that a goal?
In future articles, I'll discuss this sort of 'dependency elimination' in more details.
Mark, thanks for replying.
I assumed that some exception handling would be happening in the MaitreD class that would then migrate to the ReservationsController and you left it out for the sake of simplicity. But granted, that can still happen inside the respository class.
Let's imagine that for some reason, you want to write to the filesystem in addition to the database (eg. writing some reservation data like table number that can be printed and given to the customer). Following your reasoning, there would now be a reference to some IReservationPrinter in the Controller. It suddenly has to hold references to all data exchange classes that it was previously unaware of, only caring about the result MaîtreD was returning.
Maybe I didn't express myself properly: I thought Dependency Injection is a technique to resolve all implementation types at a single composition root. Of course this only applies to dependencies in the sense of DI, so where do you draw the line between implementation detail and dependency?
In any case I'm looking forward to reading more articles on this topic!
Ramon, in general when it comes to exception handling, you either handle exceptions at the source (i.e. in the Repository) or at the boundary of the application (which is typically done by frameworks already). I'm no fan of defensive coding.
"It suddenly has to hold references to all data exchange classes that it was previously unaware of"Yes, but now
MaîtreD doesn't have to do that. Is there anything inherently associated with business logic that stipulates that it handles data access?
The following line of argument may be increasingly difficult to relate to as time moves forward, and business becomes increasingly digital, but there once was a time when business logic was paper-based. In paper-based organisations, data would flow through a business in the shape of paper; typically as forms. Data would arrive at the desk of a clerk or domain expert who would add more data or annotations to a form, and put it in his or her out-box for later collection.
My point is that I see nothing inherent in business logic to stipulate that business objects should be responsible for data retrieval or persistence. I recommend Domain Modeling Made Functional if you're interested in a comprehensive treatment of this way of looking at modelling business logic.
"I thought Dependency Injection is a technique to resolve all implementation types at a single composition root."It is, and that still happens here. There are, however, fewer dependencies overall. I would argue that with the final design outlined here, the remaining dependency (
IReservationsRepository) is also, architecturally, the only real dependency of the application. The initial IMaîtreD dependency is, in my opinion, an implementation detail. Exposing it as a dependency makes the code more brittle, and harder to refactor, but that's what I'm going to cover in future articles.
Mark, I have to admit that I'm still not convinced (without having read the book you mentioned):
Expanding on your analogy, a clerk would maybe make a phone call or walk over to another desk if he needs more information regarding his current form (I know I do at my office). A maître d'hôtel would presumably open his book of reservations to check if he still has a table available and would write a new reservation in his book.
The MaîtreD doesn't need to know if the data it needs comes from the file system or a database or a web service (that's the responsibility of the repository class), all it cares about is that it needs some data. Currently, some other part of the system decides what data MaîtreD has to work with.
Again, I didn't have a look at the reading recommendation yet. Maybe I should. ;)
I definitely agree with Mark that the business logic (in the final version of MaîtreD.TryAccept) should be in a function that is pure and synchronous. However, I am also sympathetic to Ramon's argument.
There are two UIs for the application that I am currently building at work. The primary interface is over HTTP and uses web controllers just like in Mark's example. The second interface is a CLI (that is only accessable to administrators with phsyical access to the server). Suppose my application was also an on-line restaurant reservation system and that a reservation could be made with both UIs.
Looking back at the final implementation of ReservationsController.Post, the first three lines are independent of ControllerBase and would also need to be executed when accessing the system though the CLI. My understanding is that Ramon's primary suggestion is to move these three lines into MaîtreD.TryAccept. I am sympathetic to Ramon's argument in that I am in favor of extracting those three lines. However, I don't want them to be colocated with the final implimentatiion of MaîtreD.TryAccept.
In my mind, the single responsibility of ReservationsController.Post is to translate the result of the reseravation request into the expected type of response. That would be just the fourth line in the final implementation of this method. In terms of naming, I like Ramon's suggestion that the first three lines of ReservationsController.Post be moved to MaîtreD.TryAccept. But then I also want to move the final implementation of MaîtreD.TryAccept to a method on a different type. As we all know, naming is an impossible problem, so I don't have a good name for this new third type.
What do you think Ramon? Have I understood your concerns and suggested something that you could get behind?
What about you Mark? You said that there was
so little...going on in the Controller that I think it'd be fair to ask why it's even necessary to distinguish between a Controller and a MaîtreD class.
Would two UIs be sufficient motivation in your eyes to justify distinguishing between a Controller and a MaîtreD class?
Tyson, thank you for joining the discussion. By adding a particular problem (more than one user interface) to be addressed, you make the discussion more specific. I think this helps to clarify some issues.
Ramon wrote:
"I have to admit that I'm still not convinced"That's okay; you don't have to be. I rarely write articles with the explicit intent of telling people that they must do something, or that they should never do something else. While it does happen, this article isn't such an article. If it helps you address a problem, then take what you find useful. If it doesn't, then ignore it.
With Tyson's help, though, we can now discuss something more concrete. I think some of those observations identify a tender spot in my line of argument. In the initial version of ReservationsController, the only responsibility of the Post method was to translate from and to HTTP. That's a distinct separation of responsibility, so clearly preferable.
When I add the Repository dependency, I widen the scope of the ReservationsController's responsibility, which now includes 'all IO'. This does blur the demarcation of responsibility, but often still works out well in practice, I find. Still, it depends on how much other stuff is going on related to IO. If you have too much IO going on, another separation of responsibilities is in order.
I do find, however, that when implementing the same sort of software capability in different user interfaces, I need to specifically design for each user interface paradigm. A web-based user interface is quite different from a command-line interface, which is again different from a native application, or a voice-based interface, and so on. A web-based interface is, for example, stateless, whereas a native smart phone application would often be stateful. You can rarely reuse the 'user interface controller layer' for one type of application in a different type of application.
Even a command-line interface could be stateful by interactively asking a series of questions. That's such a different user interface paradigm that an object designed for one type of interaction is rarely reusable in another context.
What I do find is that fine-grained building blocks still compose. When TryAccept is a pure function, it's always composable. This means that my chance of being able to reuse it becomes much higher than if it's an object injected with various dependencies.
"a clerk would maybe make a phone call or walk over to another desk if he needs more information regarding his current form"Indeed, but how do you model this in software? A program doesn't have the degree of ad-hoc flexibility that people have. It can't just arbitrarily decide to make a phone call if it doesn't have a 'phone' dependency. Even when using Dependency Injection, you'll have to add that dependency to a business object. You'll have to explicitly write code to give it that capability, and even so, an injected dependency doesn't magically imbue a business object with the capability to make 'ad-hoc phone calls'. A dependency comes with specific methods you can call in order to answer specific questions.
Once you're adding code that enables an object to ask specific questions, you might as well just answer those questions up-front and pass the answer as method arguments. That's what this article's refactoring does. It knows that the MaîtreD object is going to ask about the existing reservations for the requested date, so it just passes that information as part of an 'execution context'.
"A maître d'hôtel would presumably open his book of reservations to check if he still has a table available and would write a new reservation in his book"That's a brilliant observation! This just once again demonstrates what Evans wrote in DDD, that insight about the domain arrive piecemeal. A maître d'hôtel clearly doesn't depend on any repository, but rather on the book of reservations. You can add that as a dependency, or pass it as a method argument. I'd lean toward doing the latter, because I'd tend to view a book as a piece of data.
Ultimately, if we are to take the idea of inversion of control seriously, we should, well, invert control. When we inject dependencies, we let the object with those dependencies control its interactions with them. Granted, those interactions are now polymorphic, but control isn't inverted.
If you truly want to invert control, then load data, pass it to functions, and persist the return values. In that way, functions have no control of where data comes from, or what happens to it afterwards. This keeps a software design supple.
Hi Mark, Thanks for your post, I think it's very valuable.
In the past, I had a situation when I was a junior software developer and just started working on a small, internal web application (ASP.NET MVC) to support HR processes in our company. At the time, I was discovering blogs like yours, or fsharpforfunandprofit.com and was especially fond of the sandwich architecture. I was preparing to refactor one of the controllers just like your example in this post (Controller retrieving necessary data from the repository, passing it to the pure business logic, then wrapping the results in a request). Unfortunately, My more experienced colleague said that it's a "fat controller antipattern" and that the controller can have only one line of code - redirecting the request to the proper business logic method. I wanted to explain to him that he is wrong, but couldn't find proper arguments, or examples.
Now I have them. This post is great for this particular purpose.
I guess it comes down to the amount of responsibilities the controller should have.
Marek named the fat controller antipattern. I remember reading about some years ago and it stuck, that's why I usually model my controllers to delegate the request to a worker class, maybe map a return value to a transfer object and wrap it all in some ActionResult. I can relate to the argument that all I/O should happen at the boundaries of the system, though I'm not seeing it on the controller's responsibility list, all the more so when I/O exceeds a simple database call.
If you have too much IO going on, another separation of responsibilities is in order.
I think that is what I was aiming for. The third type that Tyson is looking a name for could then be some kind of thin Data Access Layer, serving as a façade to encapsulate all calls to I/O, that can be injected into the MaîtreD class.
Isn't code flexibility usually modeled using conditionals? Assume we are a very important guest and our maître d'hôtel really wishes to make a reservation for us, but all tables are taken. He could decide to phone all currently known guests to ask for a confirmation, if some guest cannot make it, he could give the table to us.
Using the initial version of TryAccept, it would lead to something like this:
public async Task<int?> TryAccept(Reservation reservation)
{
if(await CheckTableAvailability(reservation))
{
reservation.IsAccepted = true;
return await Repository.Create(reservation);
}
else
{
return null;
}
}
private async Task<bool> CheckTableAvailability(Reservation reservation)
{
var reservations = await Repository.ReadReservations(reservation.Date);
int reservedSeats = reservations.Sum(r => r.Quantity);
if(Capacity < reservedSeats + reservation.Quantity)
{
foreach(var r in reservations)
{
if(!(await Telephone.AskConfirmation(r.Guest.PhoneNumber)))
{
//some guest cannot make it for his reservation
return true;
}
}
//all guests have confirmed their reservation - no table for us
return false;
}
return true;
}
That is assuming that MaîtreD has a dependency on both the Repository and a Telephone. Not the best code I've ever written, but it serves its purpose. If the dependency on Reservation is taken out of the MaîtreD, so could the dependency on Telephone. But then, you are deciding beforehand in the controller that MaîtreD might need to make a telephone call - that's business logic in the controller class and a weaker separation of concerns.
A maître d'hôtel clearly doesn't depend on any repository, but rather on the book of reservations. You can add that as a dependency, or pass it as a method argument. I'd lean toward doing the latter, because I'd tend to view a book as a piece of data.
And this is where I tend to disagree. The book of reservations in my eyes is owned and preciously guarded by the maître d'hôtel. Imagine some lowly garçon scribbling reservations in it. Unbelievable! Joking aside, the reservations in the book are pieces of data, no doubt about that - but I'd see the whole book as a resource owned by le maître and only him being able to request data from it. Of course, this depends on the model of the restaurant that I have in my mind, it might very well be different from yours - we didn't talk about a common model beforehand.
Apparently, I answered my own question when I moved the table availability check into its own private method. This way, a new dependency TableAvailabilityChecker can handle the availability check (complete with reservations book and phone calls), acting as a common data access layer.
I have created a repository, where I tried to follow the steps outlined in this blog post with the new dependency. After all refactorings the controller looks like this:
public class ReservationsController : ControllerBase
{
private readonly MaitreD _maitreD;
public ReservationsController(int capacity, IReservationsRepository repository, ITelephone telephone)
{
_maitreD = new MaitreD(capacity);
Repository = repository;
Telephone = telephone;
}
public IReservationsRepository Repository { get; }
public ITelephone Telephone { get; }
public async Task Post(Reservation reservation)
{
Reservation[] currentReservations = await Repository.ReadReservations(reservation.Date);
var confirmationCalls = currentReservations.Select(cr => Telephone.AskConfirmation(cr.Guest.PhoneNumber));
return _maitreD.CheckTableAvailability(currentReservations, reservation)
.Match(
some: r => new Maybe(r),
none: _maitreD.AskConfirmation(await Task.WhenAll(confirmationCalls), reservation)
)
.Match(
some: r => Ok(Repository.Create(_maitreD.Accept(r))),
none: new ContentResult { Content = "Table unavailable", StatusCode = StatusCodes.Status500InternalServerError } as ActionResult
);
}
}
During the refactorings, I was able to remove the TableAvailabilityChecker again; I'm quite happy that the maître d'hôtel is checking the table availability and asking for the confirmations with the resources that are given to him. I'm not so happy with the Task.WhenAll() part, but I don't know how to make this more readable and at the same time make the calls only if we need them.
All in all, I now think a bit differently about the controller responsibilities: Being at the boundary of the system, it is arguably the best place to make calls to external systems. If and how the information gathered from the outside is used however is still up to the business objects. Thanks, Mark, for the insight!
Thanks for writing this article. Doesn't testability suffer from turning the Maître d into an implementation detail of the ReservationsController? Now, we not only have to test for the controller's specific responsibilities but also for the behaviour that is implemented by the Maître d. Previously we could have provided an appropriate test double when instantiating the controller, knowing that the Maître d is tested and working. The resulting test classes would be more specific and focused. Is this a trade-off you made in favour of bringing the article's point across?
Max, thank you for writing. I don't think that testability suffers; on the contrary, I think that it improves. Once the MaîtreD class becomes deterministic, you no longer have to hide it behind a Test Double in order to be able to control its behaviour. You can control its behaviour simply by making sure that it receives the appropriate input arguments.
The Facade Tests that cover ReservationsController in the repository are, in my opinion, readable and maintainable.
I've started a new article series about this topic, since I knew it'd come up. I hope that these articles will help illustrate my position.
Hi, Mark! Thank you for this blog post.
I really like the way of composing effectful and pure code the post explains. But here are some things I keep wondering about.
1) Is it correct that — given this approach — pure code cannot call back into impure code. When I say call back I mean it in a general way: maybe invoking a lambda passed as an argument to a function, maybe invoking a method on an injected dependency — basically the specific mechanics of calling back are irrelevant in this case.
2) In case point 1) is actually correct, have you ever had in your practice a task where the "ban" on callbacks was too limiting/impractical?
To give a more specific example of scenarios I have in mind, let's get back to MaitreD for a second. Let's imagine the amount of reservations data grew too big to load all at once. As a result MaitreD needs an instance of ReservationRepository so it can first run some business logic and based on the outcome read only a small specific subset of reservations from the repository.
Or let's take a look at another imaginary scenario. Before confirming a reservation MaitreD must make a call to an external payment service to block a certain sum of money on the customer's card.
These are only quick examples off the top of my head. Maybe dealing with them is easy, I would still be really grateful if you could give a couple of scenarios where you found it hard or impractical to do without "callbacks" and if and how you eventually manage to overcome the complications.
Mykola, thank you for writing. Yes, it's correct that a pure function can't call an impure function. This means, among other things, that you can't use Dependency Injection in functional programming.
Is that rule impractical? It depends on the programming language. In Haskell, that rule is enforced by the compiler. You can't break that rule, but the language is also designed in such a way that there's plenty of better ways to do things. In Haskell, that rule isn't impractical.
In a language like F#, that rule is no longer enforced, and there's also fewer built-in alternatives. The general solution to the problem is to use a free monad, but while it's possible to use free monads in F#, it's not as idiomatic, and there's a compelling argument to be made that going with partial application as Dependency Injection is more practical.
It's also possible to employ free monads in C#, but it's really non-idiomatic and hard to understand.
Haskell has some other general-purpose solutions (e.g. the so-called mtl style), but the only type of architecture I'm aware of that translates to F# or C# is free monads.
Does this mean that the ideas of this article is impractical for real software?
I don't think so. Let's consider your examples:
That's a frequently asked question, but in reality, I have a hard time imagining that. How much data is a reservation? It's a date (8 bytes), a quantity (in reality, a single byte is enough to keep track of that), as well as a name and an email address. Let's assume that an email address is, on average, shorter than 30 characters, and a name is shorter than 50 characters. We'll assume that we save both strings in UTF-8. Most characters are probably still just going to be 1 byte, but let's be generous and assume 2 bytes per character. That's 169 bytes per reservation, but let's be even more generous and say 200 bytes per reservation."Let's imagine the amount of reservations data grew too big to load all at once."
What if we load 1,000 reservations? That's 200 kilobytes of memory. 10,000 reservations is 2 megabytes. That's about the size of an average web page. Is that too much data?
We routinely load web pages over the internet, and none but the Australians complain about the size.
My point is that I find it incredulous to claim that it'd be too much data if you need to load a couple of hundred of reservations in one go.
I can definitely imagine scenarios where you'd like to load reservations not only for the date in question, but also for surrounding dates. Even for a medium-sized restaurant, that's unlikely to be more than a few hundred, or perhaps a few thousand of reservations. That's not a lot of data. Most pictures on the WWW are bigger.
Just speculatively load extra data in one go. It's going to make your code much simpler, and is unlikely to affect performance if you're being smart about it. You can even consider to cache that data...
When it comes to your other question, I'll refer to a catch-phrase from the early days of large-scale web commerce (Pat Helland): take the money.
Don't make payment a blocking call. As soon as you have enough information to execute a purchase, kick it off as an asynchronous background job.
If a restaurant has that type of workflow that requires reservation of an amount on a credit card, you turn the business process into an asynchronous workflow. On the UI side, you make sure to reflect the current state of the system so that users don't try to reserve on dates that you already know are sold out. I show such a workflow in my functional architecture with F# Pluralsight course.
When a user makes a reservation, you take the reservation data and put it on a queue, and tell the user that you're working on it.
A background job receives the queued message and decides whether or not to accept the reservation. If it decides to accept it, it creates two other messages: one to reserve the money, and another a timeout.
Another background job receives the message to reserve the money on the credit card and attempts to do that. Once that's over, it reports success or failure by putting another message on a queue.
The reservation system receives the asynchronous message about the credit card and either commits or cancels the reservation. If it never gets such a message, the timeout message will eventually trigger a cancellation.
Each message handler can use the impure-pure-impure sandwich pattern, and in that way keep the business logic pure.
In my experience, you can often address issues like the ones you bring up by selecting an application architecture that best addresses those particular concerns. That'll make the implementation code simpler.
In fact, I'm often struggling to come up with an example scenario where something like a free monad would be necessary, because I always think to myself: Why would I do it that way? I'd just architect my application in this other way, and then the problem will go away by itself.
Hi Mark, I was just wondering - why is the controller asking its clients for a capacity, when it only uses it to imediately create a MaitreD? Should it not ask for the MaitreD in the first place, instead of sneakily conjuring it up in the constructor?
It feels like the controller owns the MaitreD, but the MaitreD represents pure and deterministic behaviour set up by its "capacity" dependency - and the capacity is only injected into the controller. So should it really be private?
Can't we just ask for the MaitreD, leave it public, forget about the "implementation detail" of a capacity, and be done with it?
Thanks!
votroto, thank you for writing. Injecting a concrete dependency is definitely an option. I'm currently working on a larger example code base that also has a MaitreD class, and in that code base I decided to inject that into the Controller instead of its constituent elements.
It's a trade-off; I don't see one option as more correct than the other. In the present article, the MaîtreD class is so simple that it only has a single dependency: capacity. In this case, it's a toss-up. Either you inject capacity, or you inject the entire MaîtreD class. In both cases, you have a single dependency in addition to that IReservationsRepository dependency. In this situation, I chose to follow the principle of least knowledge. By injecting only the capacity, the MaîtreD class is an implementation detail not exposed to the rest of the world.
In the larger example code base that I'm currently working on, the MaitreD class is more complex: it has several configuration values that determine its behaviour. If I wanted to keep the MaitreD class an implementation detail, the Controller constructor would look like this:
public ReservationsController( IReservationsRepository repository, TimeOfDay opensAt, TimeOfDay lastSeating, TimeSpan seatingDuration, IEnumerable<Table> tables) { Repository = repository; MaitreD = new MaitreD(opensAt, lastSeating, seatingDuration, tables); }
I don't think that this addresses any real concerns. If I ever decide to change the MaitreD constructor, I'd have to also change the ReservationsController constructor. Thus, while ReservationsController might not 'formally' depend on MaitreD, it still does so in practice. In that case I chose to inject MaitreD instead:
public ReservationsController( IReservationsRepository repository, MaitreD maitreD) { Repository = repository; MaitreD = maitreD; }
Don't read the above as an argument for one option over the other. I'm only trying to explain the deliberations I go through to arrive at a decision, one way or the other.
How to get the value out of the monad
How do I get the value out of my monad? You don't. You inject the desired behaviour into the monad.
A frequently asked question about monads can be paraphrased as: How do I get the value out of my monad? This seems to particularly come up when the monad in question is Haskell's IO monad, from which you can't extract the value. This is by design, but then beginners are often stumped on how to write the code they have in mind.
You can encounter variations of the question, or at least the underlying conceptual misunderstanding, with other monads. This seems to be particularly prevalent when object-oriented or procedural programmers start working with Maybe or Either. People really want to extract 'the value' from those monads as well, despite the lack of guarantee that there will be a value.
So how do you extract the value from a monad?
The answer isn't use a comonad, although it could be, for a limited set of monads. Rather, the answer is mu.
Unit containers #
Before I attempt to address how to work with monads, I think it's worthwhile to speculate on what misleads people into thinking that it makes sense to even contemplate extracting 'the value' from a monad. After all, you rarely encounter the question: How do I get the value out of my collection?
Various collections form monads, but everyone intuitively understand that there isn't a single value in a collection. Collections could be empty, or contain many elements. Collections could easily be the most ordinary monad. Programmers deal with collections all the time.
Yet, I think that most programmers don't realise that collections form monads. The reason for this could be that mainstream languages rarely makes this relationship explicit. Even C# query syntax, which is nothing but monads in disguise, hides this fact.
What happens, I think, is that when programmers first come across monads, they often encounter one of a few unit containers.
What's a unit container? I admit that the word is one I made up, because I couldn't detect existing terminology on this topic. The idea, though, is that it's a functor guaranteed to contain exactly one value. Since functors are containers, I call such types unit containers. Examples include Identity, Lazy, and asynchronous functors.
You can extract 'the value' from most unit containers (with IO being the notable exception from the rule). Trivially, you can get the item contained in an Identity container:
> Identity<string> x = new Identity<string>("bar"); > x.Item "bar"
Likewise, you can extract the value from lazy and asynchronous values:
> Lazy<int> x = new Lazy<int>(() => 42); > x.Value 42 > Task<int> y = Task.Run(() => 1337); > await y 1337
My theory, then, is that some programmers are introduced to the concept of monads via lazy or asynchronous computations, and that this could establish incorrect mental models.
Semi-containers #
There's another category of monad that we could call semi-containers (again, I'm open to suggestions for a better name). These are data containers that contain either a single value, or no value. In this set of monads, we find Nullable<T>, Maybe, and Either.
Unfortunately, Maybe implementations often come with an API that enables you to ask a Maybe object if it's populated or empty, and a way to extract the value from the Maybe container. This misleads many programmers to write code like this:
Maybe<int> id = // ... if (id.HasItem) return new Customer(id.Item); else throw new DontKnowWhatToDoException();
Granted, in many cases, people do something more reasonable than throwing a useless exception. In a specific context, it may be clear what to do with an empty Maybe object, but there are problems with this Tester-Doer approach:
- It doesn't compose.
- There's no systematic technique to apply. You always need to handle empty objects in a context-specific way.
If you throw an exception when the object is empty, you'll likely have to deal with that exception further up in the call stack.
If you return a magic value (like returning -1 when a natural number is expected), you again force all callers to check for that magic number.
If you set a flag that indicates that an object was empty, again, you put the burden on callers to check for the flag.
This leads to defensive coding, which, at best, makes the code unreadable.
Behaviour Injection #
Interestingly, programmers rarely take a Tester-Doer approach to working with collections. Instead, they rely on APIs for collections and arrays.
In C#, LINQ has been around since 2007, and most programmers love it. It's common knowledge that you can use the Select method to, for example, convert an array of numbers to an array of strings:
> new[] { 42, 1337, 2112, 90125 }.Select(i => i.ToString())
string[4] { "42", "1337", "2112", "90125" }
You can do that with all functors, including Maybe:
Maybe<int> id = // ... Maybe<Customer> c = id.Select(x => new Customer(x));
A previous article offers a slightly more compelling example:
var viewModel = repository.Read(id).Select(r => r.ToViewModel());
Common to all the three above examples is that instead of trying to extract a value from the monad (which makes no sense in the array example), you inject the desired behaviour into the context of the data container. What that eventually brings about depends on the monad in question.
In the array example, the behaviour being injected is that of turning a number into a string. Since this behaviour is injected into a collection, it's applied to every element in the source array.
In the second example, the behaviour being injected is that of turning an integer into a Customer object. Since this behaviour is injected into a Maybe, it's only applied if the source object is populated.
In the third example, the behaviour being injected is that of turning a Reservation domain object into a View Model. Again, this only happens if the original Maybe object is populated.
Composability #
The marvellous quality of a monad is that it's composable. You could, for example, start by attempting to parse a string into a number:
string candidate = // Some string from application boundary Maybe<int> idm = TryParseInt(candidate);
This code could be defined in a part of your code base that deals with user input. Instead of trying to get 'the value' out of idm, you can pass the entire object to other parts of the code. The next step, defined in a different method, in a different class, perhaps even in a different library, then queries a database to read a Reservation object corresponding to that ID - if the ID is there, that is:
Maybe<Reservation> rm = idm.SelectMany(repository.Read);
The Read method on the repository has this signature:
public Maybe<Reservation> Read(int id)
The Read method returns a Maybe<Reservation> object because you could pass any int to the method, but there may not be a row in the database that corresponds to that number. Had you used Select on idm, the return type would have been Maybe<Maybe<Reservation>>. This is a typical example of a nested functor, so instead, you use SelectMany, which flattens the functor. You can do this because Maybe is a monad.
The result at this stage is a Maybe<Reservation> object. If all goes according to plan, it's populated with a Reservation object from the database. Two things could go wrong at this stage, though:
- The
candidatestring didn't represent a number. - The database didn't contain a row for the parsed ID.
idm is empty.
You can now pass rm to another part of the code base, which then performs this step:
Maybe<ReservationViewModel> vm = rm.Select(r => r.ToViewModel());
Functors and monads are composable (i.e. 'chainable'). This is a fundamental trait of functors; they're (endo)morphisms, which, by definition, are composable. In order to leverage that composability, though, you must retain the monad. If you extract 'the value' from the monad, composability is lost.
For that reason, you're not supposed to 'get the value out of the monad'. Instead, you inject the desired behaviour into the monad in question, so that it stays composable. In the above example, repository.Read and r.ToViewModel() are behaviors injected into the Maybe monad.
Summary #
When we learn something new, there's always a phase where we struggle to understand a new concept. Sometimes, we may, inadvertently, erect a tentative, but misleading mental model of a concept. It seems to me that this happens to many people while they're grappling with the concept of functors and monads.
One common mental wrong turn that many people seem to take is to try to 'get the value out of the monad'. This seems to be particularly common with IO in Haskell, where the issue is a frequently asked question.
I've also reviewed enough F# code to have noticed that people often take the imperative, Tester-Doer road to 'a option. That's the reason this article uses a majority of its space on various Maybe examples.
In a future article, I'll show a more complete and compelling example of behaviour injection.
Comments
Hi Mark, was very interested in your post as I do try and use Option Monads in my code, and I think I understand the point you are making about not thinking of an optional value as something that is composable. However, I recently had a couple of situations where I reluctantly had to check the value, would really appreciate any thoughts you may have?
The first example was where I have a UI and the user may specify a Latitude and a Longitude. The user may not yet have specified both values, so each is held as an Option
Having read your article, I realise I could change this to a Select statement on latitude, but that lambda would still need to check longitude.HasValue. Should I combine the two options somehow before doing a single Select?
The second example again relates to a UI where the user can enter values in a grid, or leave a row blank. I would like to calculate the mean, standard deviation and root mean square of the values, and normally all these functions would have the signature: double Mean(ICollection<double> values)
If I keep this then I need a function like
if(latitude.HasValue && longitude.HasValue)
Bearing = CalculateRhumbBearing(latitude.Value, longitude.Value, fixedLatitude, fixedLongitude).ToOptionMonad();
else
Bearing = OptionMonad<double>.None;
foreach(var item in values)
{
if(item.HasValue)
{
yield return item.Value;
}
}
Or some equivalent Where/Select combination. Can you advise me please, how you recommend transforming an IEnumerable<OptionMonad<X>> to an enumerable<X>? Or should I write a signature overload double Mean(ICollection<OptionMonad<double>> possibleValues) and ditto for SD and RMS?
Thanks, Sean
Sean, thank you for writing. The first example you give is quite common, and is easily addressed with using the applicative or monadic capabilities of Maybe. Often, in a language like C#, it's easiest to use monadic bind (in C# called SelectMany):
Bearing = latitude .SelectMany(lat => longitude .Select(lon => CalculateRhumbBearing(lat, lon, fixedLatitude, fixedLongitude)));
If you find code like that disagreeable, you can also write it with query syntax:
Bearing = from lat in latitude from lon in longitude select CalculateRhumbBearing(lat, lon, fixedLatitude, fixedLongitude);
Here, Bearing is a Maybe value. As you can see, in neither of the above alternatives is it necessary to check and extract the values. Bearing will be populated when both latitude and longitude are populated, and empty otherwise.
Regarding the other question, being able to filter out empty values from a collection is a standard operation in both F# and Haskell. In C#, you can write it like this:
public static IEnumerable<T> Choose<T>(this IEnumerable<IMaybe<T>> source) { return source.SelectMany(m => m.Match(new T[0], x => new[] { x })); }
This example is based on the Church-encoded Maybe, which is currently my favourite implementation. I decided to call the method Choose, as this is also the name it has in F#. In Haskell, this function is called catMaybes.
Hi Mark, did you ever think about publishing a Library containing all these types missing in .net Framework like Either? Or can you recommend an existing library?
Achim, thank you for writing. The thought has crossed my mind, but my position on this question seems to be changing.
Had you asked me one or two years ago, I'd have answered that I hadn't seriously considered doing that, and that I saw little reason to do so. There is, as far as I can tell, plenty of such libraries out there, although I can't recommend any in particular. This seems to be something that many people create as part of a learning exercise. It seems to be a rite of passage for many people, similarly to developing a Dependency Injection container, or an ORM.
Besides, a reusable library would mean another dependency that your code would have to take on.
These days, however, I'm beginning to reconsider my position. It seems that no such library is emerging as dominant, and some of the types involved (particularly Maybe) would really be useful.
Ideally, these types ought be in the .NET Base Class Library, but perhaps a second-best alternative would be to put them in a commonly-used shared library.
Hi Mark, thank you for the interesting article series.
Can you maybe provide guidance of how asynchronous operations can become part of a chain of operations? How would the 'functor flattening' be combined with the built Task/Task<T> types? Extending your example, how would you go about if we would like to enrich the reservation retrieved from repository with that day's special, which happens to be async:
Task<ReservationWithMenuSuggestion> EnrichWithSpecialOfTheDayAsync(Reservation reservation)
I tried with your Church encoded Maybe implementation, but I got stuck with the Task<T> wrapping/unwrapping/awaiting.
Ralph, thank you for writing. Please see if my new article Asynchronous Injection answers your question.
Hi Mark, I'm curious what do you think about this approach to monads - Maybe monad through async/await in C#
Dominik, thank you for writing. That's a clever article. As far as I can tell, the approach is similar to Nick Palladinos' Eff library. You can see how he rewrote one of my sample applications using it.
I've no personal experience with this approach, so I could easily be wrong in my assessment. Nick reports that he's had some success getting other people on board with such an approach, because the resulting user code looks like idiomatic C#. That is, I think, one compelling argument.
What I do find less appealing, however, is that, if I understand this correctly, the C# compiler enables you to mix, or interleave, disparate effects. As long as your method returns an awaitable object, you can await true asynchronous tasks, bind Maybe values, and conceivably invoke other effectful operations all in the same method - and you wouldn't be able to tell from the return type what to expect.
In my opinion, one of the most compelling benefits of modelling with universal abstractions is that they provide excellent encapsulation. You can use the type system to communicate the pre- and post-conditions of an operation.
If I see an operation that returns Maybe<User>, I expect that it may or may not return a User object. If I see a return type of Task<User>, I expect that I'm guaranteed to receive a User object, but that this'll happen asynchronously. Only if I see something like Task<Maybe<User>> do I expect the combination of those two effects.
My concern with making Maybe awaitable is that this enables one to return Maybe<User> from a method, but still make the implementation asynchronous (e.g. by querying a database for the user). That effect is now hidden, which in my view break encapsulation because you now have to go and read the implementation code in order to discover that this is taking place.
Mark, thanks for useful respond!
You are absolutely true that awaiting Maybe that have Task have side effects not visible to invoker. I agree that this is the smell I felt but you gave me the source of it.

Comments
If we had checked the FakeDB contains to user (by retrieving, similar as in the F# case), and assert Connections property on the retrieved objects, would we still need the IsDirty flag? I think it would be good to create a couple of cases which demonstrates refactoring, and how overspecified tests break with the interaction based tests, while works nicely here.
ladeak, thank you for writing. The
The Haskell example demonstrates how noIsDirtyflag is essentially a hack to work around the mutable nature of theFakeDB. As the previous article describes:IsDirtyflag is required, because you can simply compare the state before and after the SUT was exercised.You could do something similar in C# or F#, but that would require you to take an immutable snapshot of the Fake database before exercising the SUT, and then compare that snapshot with the state of the Fake database after the SUT was exercised. This is definitely also doable (as the Haskell example demonstrates), but a bit more work, which is the (unprincipled, pragmatic) reason I instead chose to use an
IsDirtyflag.Regarding more examples, I originally wrote another sample code base to support this talk. That sample code base contains examples that demonstrate how overspecified tests break even when you make small internal changes. I haven't yet, however, found a good home for that code base.
First of all, thank you for yet another awesome series.
The fragility of my various employers' unit tests has always bothered me, but I couldn't necessarily offer an alternative that reduced/removed that. After further thought, I initially came up with two objections to this approach (based on actual enterprise experience), but was easily able to dismiss them:
- What if the SUT has a lot of dependencies?
- Then--following best practices--the SUT is doing too much
- What if the dependency has a lot of methods
- Then--following best practices--the dependency is doing too much
The one point I wanted to seek clarification on though was that--as you spell out throughout the series--this "state-based" approach is no panacea and you may still need to do some test refactoring if you change the implementation of the SUT (e.g. if, referencing point #2 above, we break up a large dependency into a more targeted one). You may need to update your "fake" to account for that, but that that effort is much smaller than updating innumerable mock setup/verify calls, is that a correct summation? So I would have a "fake" per unit test fixture (to use nunit terminology) and would only need to update that one fake if/when the SUT for that fixture is refactored in such a way that impacts the fake.After reading this series I was trying to imagine how I could introduce this into my team's codebase where both of the objections I listed above are very real problems (I am new to the team and trying to wrangle with these issues). I imagine a pragmatic first step would be to define multiple fakes for a given large SUT that attempt to group dependency behavior in some logical fashion. Per usual, you've given me a lot to think about and some motivation to clean up some code!
Sven, thank you for writing. I think that your summary of my position is accurate. A Fake affords a 'one-stop' place where you can go and address changes in you SUT APIs. You'll still need to edit test code (your Fake implementation), but in single place.
We can, on the other hand, view multiple
Setup/Verifychanges as a violation of the DRY principle.I don't understand, however, why you want to involve the concept of a Fixture, one way or another. A Fake is Fake, regardless of the Fixture in which it appears.
Mark, you are right and I had intended to remove that reference to fixtures but forgot to. I could easily see fakes living completely outside of any specific fixture.