ploeh blog danish software design
Money monoid
Kent Beck's money TDD example has some interesting properties.
This article is part of a series about monoids. In short, a monoid is an associative binary operation with a neutral element (also known as identity).
In the first half of Test-Driven Development By Example Kent Beck explores how to develop a simple and flexible Money API using test-driven development. Towards the end, he arrives at a design that warrants further investigation.
Kent Beck's API #
The following treatment of Kent Beck's code is based on Yawar Amin's C# reproduction of Kent Beck's original Java code, further forked and manipulated by me.
The goal of Kent Beck's exercise is to develop an object-oriented API able to handle money of multiple currencies, and for example be able to express operations such as 5 USD + 10 CHF. Towards the end of the example, he arrives at an interface that, translated to C#, looks like this:
public interface IExpression { Money Reduce(Bank bank, string to); IExpression Plus(IExpression addend); IExpression Times(int multiplier); }
The Reduce method reduces an IExpression object to a single currency (to), represented as a Money object. This is useful if you have an IExpression object that contains several currencies.
The Plus method adds another IExpression object to the current object, and returns a new IExpression. This could be money in a single currency, but could also represent money held in more than one currency.
The Times method multiplies an IExpression with a multiplier. You'll notice that, throughout this example code base, both multiplier and amounts are modelled as integers. I think that Kent Beck did this as a simplification, but a more realistic example should use decimal values.
The metaphor is that you can model money as one or more expressions. A simple expression would be 5 USD, but you could also have 5 USD + 10 CHF or 5 USD + 10 CHF + 10 USD. While you can reduce some expressions, such as 5 CHF + 7 CHF, you can't reduce an expression like 5 USD + 10 CHF unless you have an exchange rate. Instead of attempting to reduce monetary values, this particular design builds an expression tree until you decide to evaluate it. (Sounds familiar?)
Kent Beck implements IExpression twice:
Moneymodels an amount in a single currency. It contains anAmountand aCurrencyread-only property. It's the quintessential Value Object.Summodels the sum of two otherIExpressionobjects. It contains two otherIExpressionobjects, calledAugendandAddend.
IExpression sum = new Sum(Money.Dollar(5), Money.Franc(10));
where Money.Dollar and Money.Franc are two static factory methods that return Money values.
Associativity #
Did you notice that Plus is a binary operation? Could it be a monoid as well?
In order to be a monoid, it must obey the monoid laws, the first of which is that the operation must be associative. This means that for three IExpression objects, x, y, and z, x.Plus(y).Plus(z) must be equal to x.Plus(y.Plus(z)). How should you interpret equality here? The return value from Plus is another IExpression value, and interfaces don't have custom equality behaviour. Either, it's up to the individual implementations (Money and Sum) to override and implement equality, or you can use test-specific equality.
The xUnit.net assertion library supports test-specific equality via custom comparers (for more details, see my Advanced Unit Testing Pluralsight course). The original Money API does, however, already include a way to compare expressions!
The Reduce method can reduce any IExpression to a single Money object (that is, to a single currency), and since Money is a Value Object, it has structural equality. You can use this to compare the values of IExpression objects. All you need is an exchange rate.
In the book, Kent Beck uses a 2:1 exchange rate between CHF and USD. As I'm writing this, the exchange rate is 0.96 Swiss Franc to a Dollar, but since the example code consistently models money as integers, that rounds to a 1:1 exchange rate. This is, however, a degenerate case, so instead, I'm going to stick to the book's original 2:1 exchange rate.
You can now add an Adapter between Reduce and xUnit.net in the form of an IEqualityComparer<IExpression>:
public class ExpressionEqualityComparer : IEqualityComparer<IExpression> { private readonly Bank bank; public ExpressionEqualityComparer() { bank = new Bank(); bank.AddRate("CHF", "USD", 2); } public bool Equals(IExpression x, IExpression y) { var xm = bank.Reduce(x, "USD"); var ym = bank.Reduce(y, "USD"); return object.Equals(xm, ym); } public int GetHashCode(IExpression obj) { return bank.Reduce(obj, "USD").GetHashCode(); } }
You'll notice that this custom equality comparer uses a Bank object with a 2:1 exchange rate. Bank is another object from the Test-Driven Development example. It doesn't implement any interface itself, but it does appear as an argument in the Reduce method.
In order to make your test code more readable, you can add a static helper class:
public static class Compare { public static ExpressionEqualityComparer UsingBank = new ExpressionEqualityComparer(); }
This enables you to write an assertion for associativity like this:
Assert.Equal( x.Plus(y).Plus(z), x.Plus(y.Plus(z)), Compare.UsingBank);
In my fork of Yawar Amin's code base, I added this assertion to an FsCheck-based automated test, and it holds for all the Sum and Money objects that FsCheck generates.
In its present incarnation, IExpression.Plus is associative, but it's worth noting that this isn't guaranteed to last. An interface like IExpression is an extensibility point, so someone could easily add a third implementation that would violate associativity. We can tentatively conclude that Plus is currently associative, but that the situation is delicate.
Identity #
If you accept that IExpression.Plus is associative, it's a monoid candidate. If an identity element exists, then it's a monoid.
Kent Beck never adds an identity element in his book, but you can add one yourself:
public static class Plus { public readonly static IExpression Identity = new PlusIdentity(); private class PlusIdentity : IExpression { public IExpression Plus(IExpression addend) { return addend; } public Money Reduce(Bank bank, string to) { return new Money(0, to); } public IExpression Times(int multiplier) { return this; } } }
There's only a single identity element, so it makes sense to make it a Singleton. The private PlusIdentity class is a new IExpression implementation that deliberately doesn't do anything.
In Plus, it simply returns the input expression. This is the same behaviour as zero has for integer addition. When adding numbers together, zero is the identity element, and the same is the case here. This is more explicitly visible in the Reduce method, where the identity expression simply reduces to zero in the requested currency. Finally, if you multiply the identity element, you still get the identity element. Here, interestingly,
PlusIdentity behaves similar to the identity element for multiplication (1).
You can now write the following assertions for any IExpression x:
Assert.Equal(x, x.Plus(Plus.Identity), Compare.UsingBank); Assert.Equal(x, Plus.Identity.Plus(x), Compare.UsingBank);
Running this as a property-based test, it holds for all x generated by FsCheck. The same caution that applies to associativity also applies here: IExpression is an extensibility point, so you can't be sure that Plus.Identity will be the identity element for all IExpression implementations someone could create, but for the three implementations that now exist, the monoid laws hold.
IExpression.Plus is a monoid.
Multiplication #
In basic arithmetic, the multiplication operator is called times. When you write 3 * 5, it literally means that you have 3 five times (or do you have 5 three times?). In other words:
3 * 5 = 3 + 3 + 3 + 3 + 3
Does a similar relationship exist for IExpression?
Perhaps, we can take a hint from Haskell, where monoids and semigroups are explicit parts of the core library. You're going to learn about semigroups later, but for now, it's interesting to observe that the Semigroup typeclass defines a function called stimes, which has the type Integral b => b -> a -> a. Basically, what this means that for any integer type (16-bit integer, 32-bit integer, etc.) stimes takes an integer and a value a and 'multiplies' the value. Here, a is a type for which a binary operation exists.
In C# syntax, stimes would look like this as an instance method on a Foo class:
public Foo Times(int multiplier)
I named the method Times instead of STimes, since I strongly suspect that the s in Haskell's stimes stands for Semigroup.
Notice how this is the same type of signature as IExpression.Times.
If it's possible to define a universal implementation of such a function in Haskell, could you do the same in C#? In Money, you can implement Times based on Plus:
public IExpression Times(int multiplier) { return Enumerable .Repeat((IExpression)this, multiplier) .Aggregate((x, y) => x.Plus(y)); }
The static Repeat LINQ method returns this as many times as requested by multiplier. The return value is an IEnumerable<IExpression>, but according to the IExpression interface, Times must return a single IExpression value. You can use the Aggregate LINQ method to repeatedly combine two IExpression values (x and y) to one, using the Plus method.
This implementation is hardly as efficient as the previous, individual implementation, but the point here isn't about efficiency, but about a common, reusable abstraction. The exact same implementation can be used to implement Sum.Times:
public IExpression Times(int multiplier) { return Enumerable .Repeat((IExpression)this, multiplier) .Aggregate((x, y) => x.Plus(y)); }
This is literally the same code as for Money.Times. You can also copy and paste this code to PlusIdentity.Times, but I'm not going to repeat it here, because it's the same code as above.
This means that you can remove the Times method from IExpression:
public interface IExpression { Money Reduce(Bank bank, string to); IExpression Plus(IExpression addend); }
Instead, you can implement it as an extension method:
public static class Expression { public static IExpression Times(this IExpression exp, int multiplier) { return Enumerable .Repeat(exp, multiplier) .Aggregate((x, y) => x.Plus(y)); } }
This works because any IExpression object has a Plus method.
As I've already admitted, this is likely to be less efficient than specialised implementations of Times. In Haskell, this is addressed by making stimes part of the typeclass, so that implementers can implement a more efficient algorithm than the default implementation. In C#, the same effect could be achieved by refactoring IExpression to an abstract base class, with Times as a public virtual (overridable) method.
Haskell sanity check #
Since Haskell has a more formal definition of a monoid, you may want to try to port Kent Beck's API to Haskell, as a proof of concept. In its final modification, my C# fork has three implementations of IExpression:
MoneySumPlusIdentity
data Expression = Money { amount :: Int, currency :: String } | Sum { augend :: Expression, addend :: Expression } | MoneyIdentity deriving (Show)
You can formally make this a Monoid:
instance Monoid Expression where mempty = MoneyIdentity mappend MoneyIdentity y = y mappend x MoneyIdentity = x mappend x y = Sum x y
The C# Plus method is here implemented by the mappend function. The only remaining member of IExpression is Reduce, which you can implement like this:
import Data.Map.Strict (Map, (!)) reduce :: Ord a => Map (String, a) Int -> a -> Expression -> Int reduce bank to (Money amt cur) = amt `div` rate where rate = bank ! (cur, to) reduce bank to (Sum x y) = reduce bank to x + reduce bank to y reduce _ _ MoneyIdentity = 0
Haskell's typeclass mechanism takes care of the rest, so that, for example, you can reproduce one of Kent Beck's original tests like this:
λ> let bank = fromList [(("CHF","USD"),2), (("USD", "USD"),1)]
λ> let sum = stimesMonoid 2 $ MoneyPort.Sum (Money 5 "USD") (Money 10 "CHF")
λ> reduce bank "USD" sum
20
Just like stimes works for any Semigroup, stimesMonoid is defined for any Monoid, and therefore you can also use it with Expression.
With the historical 2:1 exchange rate, 5 Dollars + 10 Swiss Franc, times 2, is equivalent to 20 Dollars.
Summary #
In chapter 17 of his book, Kent Beck describes that he'd been TDD'ing a Money API many times before trying out the expression-based API he ultimately used in the book. In other words, he had much experience, both with this particular problem, and with programming in general. Clearly this is a highly skilled programmer at work.
I find it interesting that he seems to intuitively arrive at a design involving a monoid and an interpreter. If he did this on purpose, he doesn't say so in the book, so I rather speculate that he arrived at the design simply because he recognised its superiority. This is the reason that I find it interesting to identify this, an existing example, as a monoid, because it indicates that there's something supremely comprehensible about monoid-based APIs. It's conceptually 'just like addition'.
In this article, we returned to a decade-old code example in order to identify it as a monoid. In the next article, I'm going to revisit an example code base of mine from 2015.
Next: Convex hull monoid.
Strings, lists, and sequences as a monoid
Strings, lists, and sequences are essentially the same monoid. An introduction for object-oriented programmers.
This article is part of a series about monoids. In short, a monoid is an associative binary operation with a neutral element (also known as identity).
Sequences #
C# models a lazily evaluated sequence of values as IEnumerable<T>. You can combine two sequences by appending one to the other:
xs.Concat(ys);
Here, xs and ys are instances of IEnumerable<T>. The Concat extension method concatenates two sequences together. It has the signature IEnumerable<T> Concat<T>(IEnumerable<T>, IEnumerable<T>), so it's a binary operation. If it's also associative and has identity, then it's a monoid.
Sequences are associative, because the order of evaluation doesn't change the outcome. Associativity is a property of a monoid, so one way to demonstrate this is with property-based testing:
[Property(QuietOnSuccess = true)] public void ConcatIsAssociative(int[] xs, int[] ys, int[] zs) { Assert.Equal( xs.Concat(ys).Concat(zs), xs.Concat(ys.Concat(zs))); }
This automated test uses FsCheck (yes, it also works from C#!) to demonstrate that Concat is associative. For simplicity's sake, the test declares xs, ys, and zs as arrays. This is because FsCheck natively knows how to create arrays, whereas it doesn't have built-in support for IEnumerable<T>. While you can use FsCheck's API to define how IEnumerable<T> objects should be created, I didn't want to add this extra complexity to the example. The associativity property holds for other pure implementations of IEnumerable<T> as well. Try it, if you need to convince yourself.
The Concat operation also has identity. The identity element is the empty sequence, as this FsCheck-based test demonstrates:
[Property(QuietOnSuccess = true)] public void ConcatHasIdentity(int[] xs) { Assert.Equal( Enumerable.Empty<int>().Concat(xs), xs.Concat(Enumerable.Empty<int>())); Assert.Equal( xs, xs.Concat(Enumerable.Empty<int>())); }
Appending an empty sequence before or after another sequence doesn't change the other sequence.
Since Concat is an associative binary operation with identity, it's a monoid.
Linked lists and other collections #
The above FsCheck-based tests demonstrate that Concat is a monoid for arrays. The properties hold for all pure implementations of IEnumerable<T>.
In Haskell, lazily evaluated sequences are modelled as linked lists. These are lazy because all Haskell expressions are lazily evaluated by default. The monoid laws hold for Haskell lists as well:
λ> ([1,2,3] ++ [4,5,6]) ++ [7,8,9] [1,2,3,4,5,6,7,8,9] λ> [1,2,3] ++ ([4,5,6] ++ [7,8,9]) [1,2,3,4,5,6,7,8,9] λ> [] ++ [1,2,3] [1,2,3] λ> [1,2,3] ++ [] [1,2,3]
In Haskell, ++ is the operator that corresponds to Concat in C#, but the operation is normally called append instead of concat.
In F#, linked lists are eagerly evaluated, because all F# expressions are eagerly evaluated by default. Lists are still monoids, though, because the monoid laws still hold:
> ([1; 2; 3] @ [4; 5; 6]) @ [7; 8; 9];; val it : int list = [1; 2; 3; 4; 5; 6; 7; 8; 9] > [1; 2; 3] @ ([4; 5; 6] @ [7; 8; 9]);; val it : int list = [1; 2; 3; 4; 5; 6; 7; 8; 9] > [] @ [1; 2; 3];; val it : int list = [1; 2; 3] > [1; 2; 3] @ [];; val it : int list = [1; 2; 3]
In F#, the list concatenation operator is @, instead of ++, but the behaviour is the same.
Strings #
Have you ever wondered why text values are called strings in most programming languages? After all, for most people, a string is a long flexible structure made from fibres. What does that have to do with text?
In programming, text is often arranged in memory as a consecutive block of characters, one after the other. Thus, you could think of text as characters like pearls on a string. A program often reads such a consecutive block of memory until it reaches a terminator of some kind. Thus, strings of characters have an order to them. They are similar to sequences and lists.
In fact, in Haskell, the type String is nothing but a synonym for [Char] (meaning: a list of Char values). Thus, anything you can do with lists of other values, you can do with String values:
λ> "foo" ++ []
"foo"
λ> [] ++ "foo"
"foo"
λ> ("foo" ++ "bar") ++ "baz"
"foobarbaz"
λ> "foo" ++ ("bar" ++ "baz")
"foobarbaz"
Clearly, ++ over String is a monoid in Haskell.
Likewise, in .NET, System.String implements IEnumerable<char>, so you'd expect it to be a monoid here as well - and it almost is. It's certainly associative:
[Property(QuietOnSuccess = true)] public void PlusIsAssociative(string x, string y, string z) { Assert.Equal( (x + y) + z, x + (y + z)); }
In C#, the + operator is actually defined for string, and as the FsCheck test demonstrates, it's associative. It almost also has identity. What's the equivalent of an empty list for strings? The empty string:
[Property(QuietOnSuccess = true)] public void PlusHasIdentity(NonNull<string> x) { Assert.Equal("" + x.Get, x.Get + ""); Assert.Equal(x.Get, x.Get + ""); }
Here, I had to tell FsCheck to avoid null values, because, as usual, null throws a big wrench into our attempts at being able to reason about the code.
The problem here is that "" + null and null + "" both return "", which is not equal to the input value (null). In other words, "" is not a true identity element for +, because of this single special case. (And by the way, null isn't the identity element either, because null + null returns... ""! Of course it does.) This is, however, an implementation detail. As an exercise, consider writing an (extension) method in C# that makes string a proper monoid, even for null values. If you can do that, you'll have demonstrated that string concatenation is a monoid in .NET, just as it is in Haskell.
Free monoid #
Recall that in the previous article, you learned how both addition and multiplication of numbers form monoids. There's at least one more monoid for numbers, and that's a sequence. If you have a generic sequence (IEnumerable<T>), it can contain anything, including numbers.
Imagine that you have two numbers, 3 and 4, and you want to combine them, but you haven't yet made up your mind about how you want to combine them. In order to postpone the decision, you can put both numbers in a singleton array (that is, an array with a single element, not to be confused with the Singleton design pattern):
var three = new[] { 3 }; var four = new[] { 4 };
Since sequences are monoids, you can combine them:
var combination = three.Concat(four);
This gives you a new sequence that contains both numbers. At this point, you haven't lost any information, so once you've decided how to combine the numbers, you can evaluate the data that you've collected so far. This is called the free monoid.
If you need the sum of the numbers, you can add them together:
var sum = combination.Aggregate(0, (x, y) => x + y);
(Yes, I'm aware that the Sum method exists, but I want you to see the details.) This Aggregate overloads takes a seed value as the first argument, and a function to combine two values as the second.
Here's how to get the product:
var product = combination.Aggregate(1, (x, y) => x * y);
Notice how in both cases, the seed value is the identity for the monoidal operation: 0 for addition, and 1 for multiplication. Likewise, the aggregator function uses the binary operation associated with that particular monoid.
I think it's interesting that this is called the free monoid, similar to free monads. In both cases, you collect data without initially interpreting it, and then later you can submit the collected data to one of several evaluators.
Summary #
Various collection types, like .NET sequences, arrays, or Haskell and F# lists, are monoids over concatenation. In Haskell, strings are lists, so string concatenation is a monoid as well. In .NET, the + operator for strings is a monoid if you pretend that null strings don't exist. Still, all of these are essentially variations of the same monoid.
It makes sense that C# uses + for string concatenation, because, as the previous article described, addition is the most intuitive and 'natural' of all monoids. Because you know first-grade arithmetic, you can immediately grasp the concept of addition as a metaphor. A monoid, however, is more than a metaphor; it's an abstraction that describes well-behaved binary operations, where one of those operations just happen to be addition. It's a generalisation of the concept. It's an abstraction that you already understand.
Next: Money monoid.
Comments
Thanks for this article series! Best regards, Manuel
Manuel, thank you for writing. The confusion is entirely caused by my sloppy writing. A monoid is an associative binary operation with identity. Since the free monoid essentially elevates each number to a singleton list, the binary operation in question is list concatenation.
The Aggregate method is a built-in BCL method that aggregates values. I'll have more to say about that in later articles, but aggregation in itself is not a monoid; it follows from monoids.
I've yet to find a source that explains the etymology of the 'free' terminology, but as far as I can tell, free monoids, as well as free monads, are instances of a particular abstraction that you 'get for free', so to speak. You can always put values into singleton lists, just like you can always create a free monad from any functor. These instances are lossless in the sense that performing operations on them never erase data. For the free monoid, you just keep on concatenating more values to your list of values.
This decouples the collection of data from evaluation. Data collection is lossless. Only when you want to evaluate the result must you decide on a particular type of evaluation. For integers, for example, you could choose between addition and multiplication. Once you perform the evaluation, the result is lossy.
In Haskell, the Data.Monoid module defines an <> infix operator that you can use as the binary operation associated with a particular type. For lists, you can use it like this:
Prelude Data.Monoid Data.Foldable> xs = [3] <> [4] <> [5] Prelude Data.Monoid Data.Foldable> xs [3,4,5]
Notice how the operation isn't lossy. This means you can defer the decision on how to evaluate it until later:
Prelude Data.Monoid Data.Foldable> getSum $ fold $ Sum <$> xs 12 Prelude Data.Monoid Data.Foldable> getProduct $ fold $ Product <$> xs 60
Notice how you can choose to evaluate xs to calculate the sum, or the product.
I think the word free is used in algebraic structures to suggest that all possible interpretations are left open. This is because they are not constrained by additional specific laws which would allow to further evaluate (reduce, simplify) expressions.
For example,
2+0can be simplified to
2due to Monoid laws (identity) while
2+3can be reduced to
5due to specific arithmetic laws.
Freedom from further constraints also mean that we can always devise automatically (hence free
as in free beer
) an instance from a signature.
This construction is called term algebra;
its values are essentially the syntactic structures (AST) of the expressions allowed by the signature
and the sole simplifications permitted are those specified by the general laws.
In the case of a Monoid, thanks to associativity (which is a Monoid law, not specific to any particular instance), if we consider complex expressions like
(1+3)+2we can flatten their AST to a list
[1,3,2]without losing information and still without committing yet to any specific interpretation. And for atomic expressions like
3the single node AST becomes a singleton list.
Monoids
Introduction to monoids for object-oriented programmers.
This article is part of a larger series about monoids, semigroups, and related concepts. In this article, you'll learn what a monoid is, and what distinguishes it from a semigroup.

Monoids form a subset of semigroups. The rules that govern monoids are stricter than those for semigroups, so you'd be forgiven for thinking that it would make sense to start with semigroups, and then build upon that definition to learn about monoids. From a strictly hierarchical perspective, that would make sense, but I think that monoids are more intuitive. When you see the most obvious monoid example, you'll see that they cover operations from everyday life. It's easy to think of examples of monoids, while you have to think harder to find some good semigroup examples. That's the reason I think that you should start with monoids.
Monoid laws #
What do addition (40 + 2) and multiplication (6 * 7) have in common?
They're both
- associative
- binary operations
- with a neutral element.
Binary operation #
Let's start with the most basic property. That an operation is binary means that it works on two values. Perhaps you mostly associate the word binary with binary numbers, such as 101010, but the word originates from Latin and means something like of two. Astronomers talk about binary stars, but the word is dominantly used in computing context: apart from binary numbers, you may also have heard about binary trees. When talking about binary operations, it's implied that both input values are of the same type, and that the return type is the same as the input type. In other words, a C# method like this is a proper binary operation:
public static Foo Op(Foo x, Foo y)
Sometimes, if Op is an instance method on the Foo class, it can also look like this:
public Foo Op (Foo foo)
On the other hand, this isn't a binary operation:
public static Baz Op(Foo f, Bar b)
Although it takes two input arguments, they're of different types, and the return type is a third type.
Since all involved arguments and return values are of the same type, a binary operation exhibits what Eric Evans in Domain-Driven Design calls Closure of Operations.
Associative #
In order to form a monoid, the binary operation must be associative. This simply means that the order of evaluation doesn't matter. For example, for addition, it means that
(2 + 3) + 4 = 2 + (3 + 4) = 2 + 3 + 4 = 9
Likewise, for multiplication
(2 * 3) * 4 = 2 * (3 * 4) = 2 * 3 * 4 = 24
Expressed as the above Op instance method, associativity would require that areEqual is true in the following code:
var areEqual = foo1.Op(foo2).Op(foo3) == foo1.Op(foo2.Op(foo3));
On the left-hand side, foo1.Op(foo2) is evaluated first, and the result then evaluated with foo3. On the right-hand side, foo2.Op(foo3) is evaluated first, and then used as an input argument to foo1.Op. Since the left-hand side and the right-hand side are compared with the == operator, associativity requires that areEqual is true.
In C#, if you have a custom monoid like Foo, you'll have to override Equals and implement the == operator in order to make all of this work.
Neutral element #
The third rule for monoids is that there must exist a neutral value. In the normal jargon, this is called the identity element, and this is what I'm going to be calling it from now on. I only wanted to introduce the concept using a friendlier name.
The identity element is a value that doesn't 'do' anything. For addition, for example, it's zero, because adding zero to a value doesn't change the value:
0 + 42 = 42 + 0 = 42
As an easy exercise, see if you can figure out the identity value for multiplication.
As implied by the above sum, the identity element must act neutrally both when applied to the left-hand side and the right-hand side of another value. For our Foo objects, it could look like this:
var hasIdentity = Foo.Identity.Op(foo) == foo.Op(Foo.Identity) && foo.Op(Foo.Identity) == foo;
Here, Foo.Identity is a static read-only field of the type Foo.
Examples #
There are plenty of examples of monoids. The most obvious examples are addition and multiplication, but there are more. Depending on your perspective, you could even say that there's more than one addition monoid, because there's one for integers, one for real numbers, and so on. The same can be said for multiplication.
There are also two monoids over boolean values called all and any. If you have a binary operation over boolean values called all, how do you think it works? What would be the identity value? What about any?
I'll leave you to ponder (or look up) all and any, and instead, in the next articles, show you some slightly more interesting monoids.
- Angular addition monoid
- Strings, lists, and sequences as a monoid
- Money monoid
- Convex hull monoid
- Tuple monoids
- Function monoids
- Endomorphism monoid
- Maybe monoids
- Lazy monoids
- Monoids accumulate
== operator. On the other hand, there's no Multiply method for TimeSpan, because what does it mean to multiply two durations? What would the dimension be? Time squared?
Summary #
A monoid (not to be confused with a monad) is a set (a type) equipped with a binary operation that satisfies the two monoid laws: that the operation is associative, and that an identity element exists. Addition and multiplication are prime examples, but several others exist.
(By the way, the identity element for multiplication is one (1), the all monoid is boolean and, and the any monoid is boolean or.)
Next: Angular addition monoid
Comments
Great series! I'm a big fan of intuitive abstractions and composition. Can't wait for the remaining parts.
I first heard of the closure property in SICP, where it's mentioned that:
In general, an operation for combining data objects satisfies the closure property if the results of combining things with that operation can themselves be combined using the same operation.Also, a reference to the algebraic origin of this concept is made in the foot note for this sentence:
The use of the word "closure" here comes from abstract algebra, where a set of elements is said to be closed under an operation if applying the operation to elements in the set produces an element that is again an element of the set.
It's interesting to see this concept come up over and over, although it hasn't been widely socialized as a formal construct to software composition.
This looks like it's going to be a fantastic series - I'm really looking forwards to reading the rest!
So, as we are talking about forming a vocabulary and reducing ambiguity, I have a question about the use of the word closure, which I think has more than one common meaning in this context.
In Eric Evans' "Closure of Operations", closure refers to the fact that the operation is "closed" over it's set of possible values - in other words, the set is closed under the operation.
Closure is also used to describe a function with a bound value (as in the poor man's object").
These are two separate concepts as far as I am aware. Also, I suspect that the latter meaning is likely more well known to C# devs reading this series, especially ReSharper users who have come across it's "implicitly captured closure" detection. So, if I am correct, do you think it is worth making this distinction clear to avoid potential confusion?
Sean, thank you for writing. That's a great observation, and one that I frankly admit that I hadn't made myself. In an ideal world, one of those concepts would have a different name, so that we'd be able to distinguish them from each other.
In my experience, I find that the context in which I'm using those words tend to make the usage unambiguous, but I think that you have a good point that some readers may be more familiar with closure as a captured outer value, rather than the concept of an operation where the domain and the codomain is the same. I'll see if I can make this clearer when I revisit Evans' example.
I'm recently learning category theory, and happened to read this blog. Great post! I'll follow up the series.
I find it a little confusing:
(By the way, the identity element for multiplication is one (1), all is boolean and, and any is boolean or.)
Identity element should be the element of the collection rather than operation, right? So, the id for all should be True, and that of any should be False.
Vitrun, thank you for writing. Yes, the identity for any is false, and for all it's true. There are two other monoids over Boolean values. Can you figure out what they are?
I don't understand this:
"Identity element should be the element of the collection rather than operation"Can you elaborate what you mean by that?
A monoid is a sequence (M, e, ⋆), where M is a set, e ∈ M is the identity, and ⋆ is the function/operator.
To be clear. I mean, the identity should be the element of the set, rather than the operator
Are the other two and and or?
I found you good at bridging the gap between programming practice and ivory-tower concepts. How do you do that?
Vitrun, thank you for your kind words. I don't know if I have a particular way of 'bridging the gap'; I try to identify patterns in the problems I run into, and then communicate those patterns in as simple a language as I can, with as helpful examples as I can think of...
the identity should be the element of the setYes.
Regarding monoids over Boolean values, any is another name for Boolean or, and all is another name for Boolean and. That's two monoids (any and all); in addition to those, there are two more monoids over Booleans. I could tell you what they are, but it's a good exercise if you can figure them out by yourself. If not, you can easily Google them.
Hi Mark. Thank you for these articles.
Are the other two boolean monoids not and xor? ... And the identity value for not is the input value. And the identity value for xor is any of the two input values. I did not google for them. I will just wait for your answer so that there will be thrill, and so I remember what the answer is :)
I just realized that not is not a monoid because it does not operate on two values hehe. Sorry about that.
I googled it already :)
I gave answers too soon. I just realized that I was confused about the definition of an identity value.
This is another lesson for me to read a technical writing at least two or three times before thinking that I already understood it.
Jeremiah, thank you for writing, and please accept my apologies that I didn't respond right away. Not only do I write technical content, but I also read a fair bit of it, and my experience is that I often have to work with the topic in question in order to fully grasp it. Reading a text more than once is one way of doing it. When it comes to Boolean monoids, another way is to draw up some truth tables. A third way would be to simply play with Boolean expressions in your programming language of choice. Whatever it takes; if you learned something, then I'm happy.
Thanks for this great series. I know you've specified twice that a monoid is a set equipped with a binary operation, and that's consistent with other sources. However, I'm confused when you say addition and multiplication are monoids. Is it more technically correct to say "the set of integers under addition is a monoid"?
Mark, thank you for writing. It's almost impossible to be explicitly correct all the time when discussing matters like these. It'd tend to make the text verbose, bordering on unreadable. I'm no mathematician, but I think that you're right that it's technically more correct to say that the set of integers under addition forms a monoid, or gives rise to a monoid.
If you were to insist on precision, however, then I believe that your formulation is also incorrect. Mathematically, monoids are triples consisting of 1. a set, 2. a binary, associative operation, and 3. an identity. You didn't mention the identity, which under addition is zero.
I'm not writing this to insist that 'you're wrong, and therefore I'm right'. My language is imprecise, too. I do point this out, however, to highlight just how difficult it is to be absolutely precise when discussing such concepts in prose.
Other aspects to be aware of are these:
- Addition also gives rise to a monoid on the set of rational numbers and real numbers. On complex numbers, too, I think...
- In programming, addition isn't really addition because of overflow/underflow. Exceptions to that rule are unbounded numbers like .NET's BigInteger or Haskell's Integer and Rational. (Interestingly, even in the face of overflow, 'addition' may still form a monoid, but I'll leave that as an exercise.)
- Floating-point arithmetic, as yet another consideration, in general requires some hand-waving. As far as I recall, floating-point addition isn't associative. Is it really addition, then? In practice, however, we still call it addition. Would we say that it forms a monoid?
Being precise in language can be useful when trying to learn an unfamiliar concept, but my experience with writing this series of articles is that I've been unable to keep up the rigour in my prose at all times.
Monoids, semigroups, and friends
Introduction to monoids, semigroups, and similar concepts, for object-oriented programmers.
This article series is part of an even larger series of articles about the relationship between design patterns and category theory.
Functional programming has often been criticised for its abstruse jargon. Terminology like zygohistomorphic prepromorphism doesn't help sell the message, but before we start throwing stones, we should first exit our own glass house. In object-oriented design, we have names like Bridge, Visitor, SOLID, cohesion, and so on. The words sound familiar, but can you actually explain or implement the Visitor design pattern, or characterise cohesion?
That Bridge is a word you know doesn't make object-oriented terminology better. Perhaps it even makes it worse. After all, now the word has become ambiguous: did you mean a physical structure connecting two places, or are you talking about the design pattern? Granted, in practical use, it will often be clear from the context, but it doesn't change that if someone talks about the Bridge pattern, you'll have no idea what it is, unless you've actually learned it. Thus, that the word is familiar doesn't make it better.
More than one object-oriented programmer have extolled the virtues of 'operations whose return type is the same as the type of its argument(s)'. Such vocabulary, however, is inconvenient. Wouldn't it be nice to have a single, well-defined word for this? Perhaps monoid, or semigroup?
Object-oriented hunches #
In Domain-Driven Design, Eric Evans discusses the notion of Closure of Operations, that is, operations "whose return type is the same as the type of its argument(s)." In C#, it could be a method with the signature public Foo Bar(Foo f1, Foo f2). This method takes two Foo objects as input, and returns a new Foo object as output.
As Evans points out, object designs with that quality begins to look like arithmetic. If you have an operation that takes two Foo and returns a Foo, what could it be? Could it be like addition? Multiplication? Another mathematical operation?
Some enterprise developers just 'want to get stuff done', and don't care about mathematics. To them, the value of making code more mathematical is disputable. Still, even if you 'don't like maths', you understand addition, multiplication, and so on. Arithmetic is a powerful metaphor, because all programmers understand it.
In his book Test-Driven Development: By Example, Kent Beck seems to have the same hunch, although I don't think he ever explicitly calls it out.
What Evans describes are monoids, semigroups, and similar concepts from abstract algebra. To be fair, I recently had the opportunity to discuss the matter with him, and he's perfectly aware of those concepts today. Whether he was aware of them when he wrote DDD in 2003 I don't know, but I certainly wasn't; my errand isn't to point fingers, but to point out that clever people have found this design principle valuable in object-oriented design long before they gave it a distinct name.
Relationships #
Monoids and semigroups belong to a larger group of operations called magmas. You'll learn about those later, but we'll start with monoids, move on to semigroups, and then explore other magmas. All monoids are semigroups, while the inverse doesn't hold. In other words, monoids form a subset of semigroups.
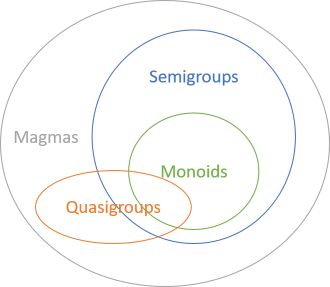
All magmas describe binary operations of the form: an operation takes two Foo values as input and returns a Foo value as output. Both categories are governed by (intuitive) laws. The difference is that the laws governing monoids are stricter than the laws governing semigroups. Don't be put off by the terminology; 'law' may sound like you have to get involved in complicated maths, but these laws are simple and intuitive. You'll learn them as you read on.
Summary #
To the average object-oriented programmer, terms like monoid and semigroup smell of mathematics, academia, and ivory-tower astronaut architects, but they're plain and simple concepts that anyone can understand, if they wish to invest 15 minutes of their time.
Whether or not an object is a magma tells us whether Evans' Closure of Operations is possible. It might teach us other things about our code, as well.
Next: Monoids.
Comments
Hi Mark,
Thank you for taking the time to write such interesting articles. I'm personally fascinated by the relationship between ancient subjects like algebra and modern ones like programming. I can't wait to read more.
That said, I understand the feeling of being put off by some of the terms used in functional programming (I'm looking at you, "zygohistomorphic"). I think the reason for it is that the vast majority of those words come from Greek or Latin, and to many people (me included) Greek is exactly what it sounds like — Greek.
Granted, things aren't much better in the object-oriented programming world, where a Visitor isn't necessarily what you think it is, even if you recognize the word.
However, in my experience, knowing the etymology of a word is the first step in understanding it. I think that including a translation for every new term would make the subjects of these articles feel less alien. It would be a way to "break the ice", so to speak.
One example I came to think of is the word polymorphism — perhaps one of the most "academic-sounding" words thrown around in object-oriented programming conversations. It may feel intimidating at first, but it quickly falls off the ivory tower once you know that it literally means "when things can take many shapes" (from the Greek polys, "many", morphē, "shape" and "ismós", the general concept).
/Enrico
Enrico, thank you for writing. Funny you should write that, because leading with an explanation of monoid is exactly what I do in my new Clean Coders episode Composite as Universal Abstraction. In short, monoid means 'one-like'. In the video, I go into more details on why that's a useful name.
Hey, Mark, what a great start on a very promising series! One more accessibility suggestion along the same lines as Enrico's: You might consider including pronunciation for new terms that aren't obvious.
Eagerly anticipating future installments!
From design patterns to category theory
How do you design good abstractions? By using abstractions that already exist.
When I was a boy, I had a cassette tape player. It came with playback controls like these:

Soon after cassette players had become widely adopted, VCR manufacturers figured out that they could reuse those symbols to make their machines easier to use. Everyone could play a video tape, but 'no one' could 'program' them, because, while playback controls were already universally understood by consumers, each VCR came with its own proprietary interface for 'programming'.
Then came CD players. Same controls.
MP3 players. Same controls.
Streaming audio and video players. Same controls.
If you download an app that plays music, odds are that you'll find it easy to get started playing music. One reason is that all playback apps seem to have the same common set of controls. It's an abstraction that you already know.
Understanding source code #
As I explain in my Humane Code video, you can't program without abstractions. To summarise, in the words of Robert C. Martin
"Abstraction is the elimination of the irrelevant and the amplification of the essential"With such abstractions, source code becomes easier to understand. Like everything else, there's no silver bullet, but good coding abstractions can save you much grief, and make it easier to understand big and complex code bases.
Not only can a good abstraction shield you from having to understand all the details in a big system, but if you're familiar with the abstraction, you may be able to quickly get up to speed.
While the above definition is great for identifying a good abstraction, it doesn't tell you how to create one.
Design patterns #
Design Patterns explains that a design pattern is a general reusable solution to a commonly occurring problem. As I interpret the original intent of the Gang of Four, the book was an attempt to collect and abstract solutions that were repeatedly observed 'in the wild'. The design patterns in the book are descriptive, not prescriptive.
Design patterns are useful in two ways:
- They offer solutions
- They form a vocabulary
I have no problems with ready-made solutions, but I think that the other advantage may be even bigger. When you're looking at unfamiliar source code, you struggle to understand how it's structured, and what it does. If, hypothetically, you discover that pieces of that unfamiliar source code follows a design pattern that you know, then understanding the code becomes much easier.
There are two criteria for this to happen:
- The reader (you) must already know the pattern
- The original author (also you?) must have implemented the pattern without any surprising deviations
Ambiguous specification #
Programming to a well-known abstraction is a force multiplier, but it does require that those two conditions are satisfied: prior knowledge, and correct implementation.
I don't know how to solve the prior knowledge requirement, other than to tell you to study. I do, however, think that it's possible to formalise some of the known design patterns.
Most design patterns are described in some depth. They come with sections on motivation, when to use and not to use, diagrams, and example code. Furthermore, they also come with an overview of variations.
Picture this: as a reader, you've just identified that the code you're looking at is an implementation of a design pattern. Then you realise that it isn't structured like you'd expect, or that its behaviour surprises you. Was the author incompetent, after all?
While you're inclined to believe the worst about your fellow (wo)man, you look up the original pattern, and there it is: the author is using a variation of the pattern.
Design patterns are ambiguous.
Universal abstractions #
Design Patterns was a great effort in 1994, and I've personally benefited from it. The catalogue was an attempt to discover good abstractions.
What's a good abstraction? As already quoted, it's a model that amplifies the essentials, etcetera. I think a good abstraction should also be intuitive.
What's the most intuitive abstractions ever?
Mathematics.
Stay with me, please. If you're a normal reader of my blog, you're most likely an 'industry programmer' or enterprise developer. You're not interested in mathematics. Perhaps mathematics even turns you off, and at the very least, you never had use for mathematics in programming.
You may not find n-dimensional differential topology, or stochastic calculus, intuitive, but that's not the kind of mathematics I have in mind.
Basic arithmetic is intuitive. You know: 1 + 3 = 4, or 3 * 4 = 12. In fact, it's so intuitive that you can't formally prove it -without axioms, that is. These axioms are unprovable; you must take them at face value, but you'll readily do that because they're so intuitive.
Mathematics is a big structure, but it's all based on intuitive axioms. Mathematics is intuitive.
Writers before me have celebrated the power of mathematical abstraction in programming. For instance, in Domain-Driven Design Eric Evans discusses how Closure of Operations leads to object models reminiscent of arithmetic. If you can design Value Objects in such a way that you can somehow 'add' them together, you have an intuitive and powerful abstraction.
Notice that there's more than one way to combine numbers. You can add them together, but you can also multiply them. Could there be a common abstraction for that? What about objects that can somehow be combined, even if they aren't 'number-like'? The generalisation of such operations is a branch of mathematics called category theory, and it has turned out to be productive when applied to functional programming. Haskell is the most prominent example.
By an interesting coincidence, the 'things' in category theory are called objects, and while they aren't objects in the sense that we think of in object-oriented design, there is some equivalence. Category theory concerns itself with how objects map to other objects. A functional programmer would interpret such morphisms as functions, but in a sense, you can also think of them as well-defined behaviour that's associated with data.
The objects of category theory are universal abstractions. Some of them, it turns out, coincide with known design patterns. The difference is, however, that category theory concepts are governed by specific laws. In order to be a functor, for example, an object must obey certain simple and intuitive laws. This makes the category theory concepts more specific, and less ambiguous, than design patterns.
The coming article series is an exploration of this space:
- Monoids, semigroups, and friends
- Functors, applicatives, and friends
- Software design isomorphisms
- Church encoding
- Catamorphisms
- Some design patterns as universal abstractions
Motivation #
The purpose of this article series is two-fold. Depending on your needs and interests, you can use it to
- learn better abstractions
- learn how functional programming is a real alternative to object-oriented programming
The other goal of these articles may be less clear. Object-oriented programming (OOP) is the dominant software design paradigm. It wasn't always so. When OOP was new, many veteran programmers couldn't see how it could be useful. They were schooled in one paradigm, and it was difficult for them to shift to the new paradigm. They were used to do things in one way (typically, procedural), and it wasn't clear how to achieve the same goals with idiomatic object-oriented design.
The same sort of resistance applies to functional programming. Tasks that are easy in OOP seem impossible in functional programming. How do you make a for loop? How do you change state? How do you break out of a routine?
This leads to both frustration, and dismissal of functional programming, which is still seen as either academic, or something only interesting in computation-heavy domains like science or finance.
It's my secondary goal with these articles to show that:
- There are clear equivalences between known design patterns and concepts from category theory
- Thus, functional programming is as universally useful as OOP
- Since equivalences exist, there's a learning path
Work in progress #
I've been thinking about these topics for years. What's a good abstraction? When do abstractions compose?
My first attempt at answering these questions was in 2010, but while I had the experience that certain abstractions composed better than others, I lacked the vocabulary. I've been wanting to write a better treatment of the topic ever since, but I've been constantly learning as I've grappled with the concepts.
I believe that I now have the vocabulary to take a stab at this again. This is hardly the ultimate treatment. A year from now, I hope to have learned even more, and perhaps that'll lead to further insights or refinement. Still, I can't postpone writing this article until I've stopped learning, because at that time I'll either be dead or senile.
I'll write these articles in an authoritative voice, because a text that constantly moderates and qualifies its assertions easily becomes unreadable. Don't consider the tone an indication that I'm certain that I'm right. I've tried to be as rigorous in my arguments as I could, but I don't have a formal education in computer science. I welcome feedback on any article, both if it's to corroborate my findings, or if it's to refute them. If you have any sort of feedback, then please leave a comment.
I consider the publication of these articles as though I submit them to peer review. If you can refute them, they deserve to be refuted. If not, they just may be valuable to other people.
Summary #
Category theory generalises some intuitive relations, such as how numbers combine (e.g. via addition or multiplication). Instead of discussing numbers, however, category theory considers abstract 'objects'. This field of mathematics explore how object relate and compose.
Some category theory concepts can be translated to code. These universal abstractions can form the basis of a powerful and concise software design vocabulary.
The design patterns movement was an early attempt to create such a vocabulary. I think using category theory offers the chance of a better vocabulary, but fortunately, all the work that went into design patterns isn't wasted. It seems to me that some design patterns are essentially ad-hoc, informally specified, specialised instances of basic category theory concepts. There's quite a bit of overlap. This should further strengthen the argument that category theory is valuable in programming, because some of the concepts are equivalent to design patterns that have already proven useful.
Comments
What a perfect introduction !
I heard about category theory more than one year ago. But it was from a PhD who code in 'haskell' and I thought it was too hard for me to understand.
And then, this post.
Thank you a lot! (you aleardy published the follow up ! yeah)
Thanks for writing these articles, it's nice to have some reference material that is approachable for us as dotnet programmers.
One thing I was kind of expecting to find here was something about the two building blocks of combining types: products and coproducts. Is this something you have written about, or are considering writing about? It gets mentioned in the Church encoding series and obviously those about visitors, but not really as a concept on its own.
What triggered me to come here this time, was reading about the much requested Champion "Discriminated Unions". Not only in those comments, but also when looking at other C# code, lots of people seem to not realize how fundamental of a concept sum types are. IF they are, I could be wrong ofcourse.
I liked the way bartosz milewski explained this by visualizing them as graphs. Or how Scott Wlaschin relates it back to other concepts we also take for granted:
- products, *, AND, classes, records, tuples
- coproducts, +, OR, discriminated unions, ...
Anyway, I don't want to ramble on too much. Just curious if it's something you think fits the list of universal abstractions.
Rutger, thank you for writing. I agree that the notion of algebraic data types are, in some sense, quite fundamental. Despite that, I was never planning on covering that topic in this series. The main reason is that I think that other people have already done a great job of it. The first time I encountered the concept was in Tomas Petricek's exemplarily well-written article Power of mathematics Reasoning about functional types, but, as you demonstrate, there are plenty of other good resources. Another favourite of mine is Thinking with Types.
That's not to say that this is the right decision, or that I might not write such an article. When I started this massive article series, I had a general idea about the direction I'd like to go, but I learned a lot along the way that slightly changed the plans. For example, despite the title, there's not that much category theory here. The reason for that is that I found that most of the concepts didn't really require category theory. For example, monoids originate (as far as I can tell) from abstract algebra, and you don't need more than that to explain the concept.
So, to answer your direct question: No, this isn't something that I've given an explicit treatment. On one hand, I think there's already enough good material on the topic that the world doesn't need my contribution. On the other hand, perhaps there's a dearth of treatment that puts this in a C# context.
I'm not adverse to writing such an article, but I have so many other topics I'd also like to cover.
Interception vis-à-vis Pure DI
How do you do AOP with Pure DI?
One of my readers, Nick Ball, asks me this question:
"Just spent the last couple of hours reading chapter 9 of your book about Interceptors. The final few pages show how to use Castle Windsor to make the code DRYer. That's cool, but I'm quite a fan of Pure DI as I tend to think it keeps things simpler. Plus I'm working in a legacy C++ application which limits the tooling available to me.
"So, I was wondering if you had any suggestions on how to DRY up an interceptor in Pure DI? I know in your book you state that this is where DI containers come into their own, but I also know through reading your blog that you prefer going the Pure DI route too. Hence I wondered whether you'd had any further insight since the book publication?"
It's been more than 15 years since I last did C++, so I'm going to give an answer based on C#, and hope it translates.
Position #
I do, indeed, prefer Pure DI, but there may be cases where a DI Container is warranted. Interception, or Aspect-Oriented Programming (AOP), is one such case, but obviously that doesn't help if you can't use a DI Container.
Another option for AOP is some sort of post-processor of your code. As I briefly cover in chapter 9 of my book, in .NET this is typically done by a custom tool using 'IL-weaving'. As I also outline in the book, I'm not a big fan of this approach, but perhaps that could be an option in C++ as well. In any case, I'll proceed under the assumption that you want a strictly code-based solution, involving no custom tools or build steps.
All that said, I doubt that this is as much of a problem than one would think. AOP is typically used for cross-cutting concerns such as logging, caching, instrumentation, authorization, metering, or auditing. As an alternative, you can also use Decorators for such cross-cutting concerns. This seems daunting if you truly need to decorate hundreds, or even thousands, of classes. In such a case, convention-based interception seems like a DRYer option.
You'd think.
In my experience, however, this is rarely the case. Typically, even when applying caching, logging, or authorisation logic, I've only had to create a handful of Decorators. Perhaps it's because I tend to keep my code bases to a manageable size.
If you only need a dozen Decorators, I don't think that the loss of compile-time safety and the added dependency warrants the use of a DI Container. That doesn't mean, however, that I can't aim for as DRY code as possible.
Instrument #
If you don't have a DI Container or an AOP tool, I believe that a Decorator is the best way to address cross-cutting concerns, and I don't think there's any way around adding those Decorator classes. The aim, then, becomes to minimise the effort involved in creating and maintaining such classes.
As an example, I'll revisit an old blog post. In that post, the task was to instrument an OrderProcessor class. The solution shown in that article was to use Castle Windsor to define an IInterceptor.
To recapitulate, the code for the Interceptor looks like this:
public class InstrumentingInterceptor : IInterceptor { private readonly IRegistrar registrar; public InstrumentingInterceptor(IRegistrar registrar) { if (registrar == null) throw new ArgumentNullException(nameof(registrar)); this.registrar = registrar; } public void Intercept(IInvocation invocation) { var correlationId = Guid.NewGuid(); this.registrar.Register(correlationId, string.Format("{0} begins ({1})", invocation.Method.Name, invocation.TargetType.Name)); invocation.Proceed(); this.registrar.Register(correlationId, string.Format("{0} ends ({1})", invocation.Method.Name, invocation.TargetType.Name)); } }
While, in the new scenario, you can't use Castle Windsor, you can still take the code and make a similar class out of it. Call it Instrument, because classes should have noun names, and instrument is a noun (right?).
public class Instrument { private readonly IRegistrar registrar; public Instrument(IRegistrar registrar) { if (registrar == null) throw new ArgumentNullException(nameof(registrar)); this.registrar = registrar; } public T Intercept<T>( string methodName, string typeName, Func<T> proceed) { var correlationId = Guid.NewGuid(); this.registrar.Register( correlationId, string.Format("{0} begins ({1})", methodName, typeName)); var result = proceed(); this.registrar.Register( correlationId, string.Format("{0} ends ({1})", methodName, typeName)); return result; } public void Intercept( string methodName, string typeName, Action proceed) { var correlationId = Guid.NewGuid(); this.registrar.Register( correlationId, string.Format("{0} begins ({1})", methodName, typeName)); proceed(); this.registrar.Register( correlationId, string.Format("{0} ends ({1})", methodName, typeName)); } }
Instead of a single Intercept method, the Instrument class exposes two Intercept overloads; one for methods without a return value, and one for methods that return a value. Instead of an IInvocation argument, the overload for methods without a return value takes an Action delegate, whereas the other overload takes a Func<T>.
Both overload also take methodName and typeName arguments.
Most of the code in the two methods is similar. While you could refactor to a Template Method, I invoke the Rule of three and let the duplication stay for now.
Decorators #
The Instrument class isn't going to magically create Decorators for you, but it reduces the effort of creating one:
public class InstrumentedOrderProcessor2 : IOrderProcessor { private readonly IOrderProcessor orderProcessor; private readonly Instrument instrument; public InstrumentedOrderProcessor2( IOrderProcessor orderProcessor, Instrument instrument) { if (orderProcessor == null) throw new ArgumentNullException(nameof(orderProcessor)); if (instrument == null) throw new ArgumentNullException(nameof(instrument)); this.orderProcessor = orderProcessor; this.instrument = instrument; } public SuccessResult Process(Order order) { return this.instrument.Intercept( nameof(Process), this.orderProcessor.GetType().Name, () => this.orderProcessor.Process(order)); } }
I called this class InstrumentedOrderProcessor2 with the 2 postfix because the previous article already contains a InstrumentedOrderProcessor class, and I wanted to make it clear that this is a new class.
Notice that InstrumentedOrderProcessor2 is a Decorator of IOrderProcessor. It both implements the interface, and takes one as a dependency. It also takes an Instrument object as a Concrete Dependency. This is mostly to enable reuse of a single Instrument object; no polymorphism is implied.
The decorated Process method simply delegates to the instrument's Intercept method, passing as parameters the name of the method, the name of the decorated class, and a lambda expression that closes over the outer order method argument.
For simplicity's sake, the Process method invokes this.orderProcessor.GetType().Name every time it's called, which may not be efficient. Since the orderProcessor class field is readonly, though, you could optimise this by getting the name once and for all in the constructor, and assign the string to a third class field. I didn't want to complicate the example with irrelevant code, though.
Here's another Decorator:
public class InstrumentedOrderShipper : IOrderShipper { private readonly IOrderShipper orderShipper; private readonly Instrument instrument; public InstrumentedOrderShipper( IOrderShipper orderShipper, Instrument instrument) { if (orderShipper == null) throw new ArgumentNullException(nameof(orderShipper)); if (instrument == null) throw new ArgumentNullException(nameof(instrument)); this.orderShipper = orderShipper; this.instrument = instrument; } public void Ship(Order order) { this.instrument.Intercept( nameof(Ship), this.orderShipper.GetType().Name, () => this.orderShipper.Ship(order)); } }
As you can tell, it's similar to InstrumentedOrderProcessor2, but instead of IOrderProcessor it decorates IOrderShipper. The most significant difference is that the Ship method doesn't return any value, so you have to use the Action-based overload of Intercept.
For completeness sake, here's a third interesting example:
public class InstrumentedUserContext : IUserContext { private readonly IUserContext userContext; private readonly Instrument instrument; public InstrumentedUserContext( IUserContext userContext, Instrument instrument) { if (userContext == null) throw new ArgumentNullException(nameof(userContext)); if (instrument == null) throw new ArgumentNullException(nameof(instrument)); this.userContext = userContext; this.instrument = instrument; } public User GetCurrentUser() { return this.instrument.Intercept( nameof(GetCurrentUser), this.userContext.GetType().Name, this.userContext.GetCurrentUser); } public Currency GetSelectedCurrency(User currentUser) { return this.instrument.Intercept( nameof(GetSelectedCurrency), this.userContext.GetType().Name, () => this.userContext.GetSelectedCurrency(currentUser)); } }
This example demonstrates that you can also decorate an interface that defines more than a single method. The IUserContext interface defines both GetCurrentUser and GetSelectedCurrency. The GetCurrentUser method takes no arguments, so instead of a lambda expression, you can pass the delegate using method group syntax.
Composition #
You can add such instrumenting Decorators for all appropriate interfaces. It's trivial (and automatable) work, but it's easy to do. While it seems repetitive, I can't come up with a more DRY way to do it without resorting to some sort of run-time Interception or AOP tool.
There's some repetitive code, but I don't think that the maintenance overhead is particularly great. The Decorators do minimal work, so it's unlikely that there are many defects in that area of your code base. If you need to change the instrumentation implementation in itself, the Instrument class has that (single) responsibility.
Assuming that you've added all desired Decorators, you can use Pure DI to compose an object graph:
var instrument = new Instrument(registrar); var sut = new InstrumentedOrderProcessor2( new OrderProcessor( new InstrumentedOrderValidator( new TrueOrderValidator(), instrument), new InstrumentedOrderShipper( new OrderShipper(), instrument), new InstrumentedOrderCollector( new OrderCollector( new InstrumentedAccountsReceivable( new AccountsReceivable(), instrument), new InstrumentedRateExchange( new RateExchange(), instrument), new InstrumentedUserContext( new UserContext(), instrument)), instrument)), instrument);
This code fragment is from a unit test, which explains why the object is called sut. In case you're wondering, this is also the reason for the existence of the curiously named class TrueOrderValidator. This is a test-specific Stub of IOrderValidator that always returns true.
As you can see, each leaf implementation of an interface is contained within an InstrumentedXyz Decorator, which also takes a shared instrument object.
When I call the sut's Process method with a proper Order object, I get output like this:
4ad34380-6826-440c-8d81-64bbd1f36d39 2017-08-25T17:49:18.43 Process begins (OrderProcessor) c85886a7-1ce8-4096-8a30-5f87bf0014e3 2017-08-25T17:49:18.52 Validate begins (TrueOrderValidator) c85886a7-1ce8-4096-8a30-5f87bf0014e3 2017-08-25T17:49:18.52 Validate ends (TrueOrderValidator) 8f7606b6-f3f7-4231-808d-d5e37f1f2201 2017-08-25T17:49:18.53 Collect begins (OrderCollector) 28250a92-6024-439e-b010-f66c63903673 2017-08-25T17:49:18.55 GetCurrentUser begins (UserContext) 28250a92-6024-439e-b010-f66c63903673 2017-08-25T17:49:18.56 GetCurrentUser ends (UserContext) 294ce552-201f-41d2-b7fc-291e2d3720d6 2017-08-25T17:49:18.56 GetCurrentUser begins (UserContext) 294ce552-201f-41d2-b7fc-291e2d3720d6 2017-08-25T17:49:18.56 GetCurrentUser ends (UserContext) 96ee96f0-4b95-4b17-9993-33fa87972013 2017-08-25T17:49:18.57 GetSelectedCurrency begins (UserContext) 96ee96f0-4b95-4b17-9993-33fa87972013 2017-08-25T17:49:18.58 GetSelectedCurrency ends (UserContext) 3af884e5-8e97-44ea-aa0d-2c9e0418110b 2017-08-25T17:49:18.59 Convert begins (RateExchange) 3af884e5-8e97-44ea-aa0d-2c9e0418110b 2017-08-25T17:49:18.59 Convert ends (RateExchange) b8bd0701-515b-44fe-949f-5f5fb5a4590d 2017-08-25T17:49:18.60 Collect begins (AccountsReceivable) b8bd0701-515b-44fe-949f-5f5fb5a4590d 2017-08-25T17:49:18.60 Collect ends (AccountsReceivable) 8f7606b6-f3f7-4231-808d-d5e37f1f2201 2017-08-25T17:49:18.60 Collect ends (OrderCollector) beadabc4-df17-468f-8553-34ae4e3bdbfc 2017-08-25T17:49:18.60 Ship begins (OrderShipper) beadabc4-df17-468f-8553-34ae4e3bdbfc 2017-08-25T17:49:18.61 Ship ends (OrderShipper) 4ad34380-6826-440c-8d81-64bbd1f36d39 2017-08-25T17:49:18.61 Process ends (OrderProcessor)
This is similar to the output from the previous article.
Summary #
When writing object-oriented code, I still prefer Pure DI over using a DI Container, but if I absolutely needed to decorate many services, I'd seriously consider using a DI Container with run-time Interception capabilities. The need rarely materialises, though.
As an intermediate solution, you can use a delegation-based design like the one shown here. As always, it's all a matter of balancing the constraints and goals of the specific situation.
The Test Data Generator functor
A Test Data Generator modelled as a functor.
In a previous article series, you learned that while it's possible to model Test Data Builders as a functor, it adds little value. You shouldn't, however, dismiss the value of functors. It's an abstraction that applies broadly.
Closely related to Test Data Builders is the concept of a generator of random test data. You could call it a Test Data Generator instead. Such a generator can be modelled as a functor.
A C# Generator #
At its core, the idea behind a Test Data Generator is to create random test data. Still, you'll like to be able control various parts of the process, because you'd often need to pin parts of the generated data to deterministic values, while allowing other parts to vary randomly.
In C#, you can write a generic Generator like this:
public class Generator<T> { private readonly Func<Random, T> generate; public Generator(Func<Random, T> generate) { if (generate == null) throw new ArgumentNullException(nameof(generate)); this.generate = generate; } public Generator<T1> Select<T1>(Func<T, T1> f) { if (f == null) throw new ArgumentNullException(nameof(f)); Func<Random, T1> newGenerator = r => f(this.generate(r)); return new Generator<T1>(newGenerator); } public T Generate(Random random) { if (random == null) throw new ArgumentNullException(nameof(random)); return this.generate(random); } }
The Generate method takes a Random object as input, and produces a value of the generic type T as output. This enables you to deterministically reproduce a particular randomly generated value, if you know the seed of the Random object.
Notice how Generator<T> is a simple Adapter over a (lazily evaluated) function. This function also takes a Random object as input, and produces a T value as output. (For the FP enthusiasts, this is simply the Reader functor in disguise.)
The Select method makes Generator<T> a functor. It takes a map function f as input, and uses it to define a new generate function. The return value is a Generator<T1>.
General-purpose building blocks #
Functors are immanently composable. You can compose complex Test Data Generators from simpler building blocks, like the following.
For instance, you may need a generator of alphanumeric strings. You can write it like this:
private const string alphaNumericCharacters = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"; public static Generator<string> AlphaNumericString = new Generator<string>(r => { var length = r.Next(25); // Arbitrarily chosen max length var chars = new char[length]; for (int i = 0; i < length; i++) { var idx = r.Next(alphaNumericCharacters.Length); chars[i] = alphaNumericCharacters[idx]; } return new string(chars); });
This Generator<string> can generate a random string with alphanumeric characters. It randomly picks a length between 0 and 24, and fills it with randomly selected alphanumeric characters. The maximum length of 24 is arbitrarily chosen. The generated string may be empty.
Notice that the argument passed to the constructor is a function. It's not evaluated at initialisation, but only if Generate is called.
The r argument is the Random object passed to Generate.
Another useful general-purpose building block is a generator that can use a single-object generator to create many objects:
public static Generator<IEnumerable<T>> Many<T>(Generator<T> generator) { return new Generator<IEnumerable<T>>(r => { var length = r.Next(25); // Arbitrarily chosen max length var elements = new List<T>(); for (int i = 0; i < length; i++) elements.Add(generator.Generate(r)); return elements; }); }
This method takes a Generator<T> as input, and uses it to generate zero or more T objects. Again, the maximum length of 24 is arbitrarily chosen. It could have been a method argument, but in order to keep the example simple, I hard-coded it.
Domain-specific generators #
From such general-purpose building blocks, you can define custom generators for your domain model. This enables you to use such generators in your unit tests.
In order to generate post codes, you can combine the AlphaNumericString and the Many generators:
public static Generator<PostCode> PostCode = new Generator<PostCode>(r => { var postCodes = Many(AlphaNumericString).Generate(r); return new PostCode(postCodes.ToArray()); });
The PostCode class is part of your domain model; it takes an array of strings as input to its constructor. The PostCode generator uses the AlphaNumericString generator as input to the Many method. This generates zero or many alphanumeric strings, which you can pass to the PostCode constructor.
This, in turn, gives you all the building blocks you need to generate Address objects:
public static Generator<Address> Address = new Generator<Address>(r => { var street = AlphaNumericString.Generate(r); var city = AlphaNumericString.Generate(r); var postCode = PostCode.Generate(r); return new Address(street, city, postCode); });
This Generator<Address> uses the AlphaNumericString generator to generate street and city strings. It uses the PostCode generator to generate a PostCode object. All these objects are passed to the Address constructor.
Keep in mind that all of this logic is defined in lazily evaluated functions. Only when you invoke the Generate method on a generator does the code execute.
Generating values #
You can now write tests similar to the tests shown in the article series about Test Data Builders. If, for example, you need an address in Paris, you can generate it like this:
var rnd = new Random(); var address = Gen.Address.Select(a => a.WithCity("Paris")).Generate(rnd);
Gen.Address is the Address generator shown above; I put all those generators in a static class called Gen. If you don't modify it, Gen.Address will generate a random Address object, but by using Select, you can pin the city to Paris.
You can also start with one type of generator and use Select to map to another type of generator, like this:
var rnd = new Random(); var address = Gen.PostCode .Select(pc => new Address("Rue Morgue", "Paris", pc)) .Generate(rnd);
You use Gen.PostCode as the initial generator, and then Select a new Address in Rue Morgue, Paris, with a randomly generated post code.
Functor #
Such a Test Data Generator is a functor. One way to see that is to use query syntax instead of the fluent API:
var rnd = new Random(); var address = (from a in Gen.Address select a.WithCity("Paris")).Generate(rnd);
Likewise, you can also translate the Rue Morgue generator to query syntax:
var address = ( from pc in Gen.PostCode select new Address("Rue Morgue", "Paris", pc)).Generate(rnd);
This is, however, awkward, because you have to enclose the query expression in brackets in order to be able to invoke the Generate method. Alternatively, you can separate the query from the generation, like this:
var g = from a in Gen.Address select a.WithCity("Paris"); var rnd = new Random(); var address = g.Generate(rnd);
Or this:
var g = from pc in Gen.PostCode select new Address("Rue Morgue", "Paris", pc); var rnd = new Random(); var address = g.Generate(rnd);
You'd probably still prefer the fluent API over this syntax. The reason I show this alternative is to demonstrate that the functor gives you the ability to separate the definition of data generation from the actual generation. In order to emphasise this point, I defined the g variables before creating the Random object rnd.
Property-based testing #
The above Generator<T> is only a crude example of a Test Data Generator. In order to demonstrate how such a generator is a functor, I left out several useful features. Still, this should have given you a sense for how the Generator<T> class itself, as well as such general-purpose building blocks as Many and AlphaNumericString, could be packaged in a reusable library.
The examples above show how to use a generator to create a single random object. You could, however, easily generate many (say, 100) random objects, and run unit tests for each object created. This is the idea behind property-based testing.
There's more to property-based testing than generation of random values, but the implementations I've seen are all based on Test Data Generators as functors (and monads).
FsCheck #
FsCheck is an open source F# library for property-based testing. It defines a Gen functor (and monad) that you can use to generate Address values, just like the above examples:
let! address = Gen.address |> Gen.map (fun a -> { a with City = "Paris"} )
Here, Gen.address is a Gen<Address> value. By itself, it'll generate random Address values, but by using Gen.map, you can pin the city to Paris.
The map function corresponds to the C# Select method. In functional programming, map is the most common name, although Haskell calls the function fmap; the Select name is, in fact, the odd man out.
Likewise, you can map from one generator type to another:
let! address = Gen.postCode |> Gen.map (fun pc -> { Street = "Rue Morgue"; City = "Paris"; PostCode = pc })
This example uses Gen.postCode as the initial generator. This is, as the name implies, a Gen<PostCode> value. For every random PostCode value generated, map turns it into an address in Rue Morgue, Paris.
There's more going on here than I'd like to cover in this article. The use of let! syntax actually requires Gen<'a> to be a monad (which it is), but that's a topic for another day. Both of these examples are contained in a computation expression, and the implication of that is that the address values represent a multitude of randomly generated Address values.
Hedgehog #
Hedgehog is another open source F# library for property-based testing. With Hedgehog, the Address code examples look like this:
let! address = Gen.address |> Gen.map (fun a -> { a with City = "Paris"} )
And:
let! address = Gen.postCode |> Gen.map (fun pc -> { Street = "Rue Morgue"; City = "Paris"; PostCode = pc })
Did you notice something?
This is literally the same syntax as FsCheck! This isn't because Hedgehog is copying FsCheck, but because both are based on the same underlying abstraction: functor (and monad). There are other parts of the API where Hedgehog differs from FsCheck, but their generators are similar.
This is one of the most important advantages of using well-known abstractions like functors. Once you understand such an abstraction, it's easy to learn a new library. With professional experience with FsCheck, it only took me a few minutes to figure out how to use Hedgehog.
Summary #
Functors are well-defined objects from category theory. It may seem abstract, and far removed from 'real' programming, but it's extraordinarily useful. Many category theory abstractions can be applied to a host of different situations. Once you've learned what a functor is, you'll find it easy to learn to use new libraries that build on that abstraction.
In this article you saw a sketch of how the functor abstraction can be used to model Test Data Generators. Contrary to Test Data Builders, which turned out to be a redundant abstraction, a Test Data Generator is truly useful.
Many years ago, I had the idea to create a Test Data Generator for unit testing purposes. I called it AutoFixture, and although it's had some success, the API isn't as clean as it could be. Back then, I didn't know about functors, so I had to invent an API for AutoFixture. This API is proprietary to AutoFixture, so anyone learning AutoFixture must learn this particular API, and its abstractions. It would have been so much easier for all involved if I had designed AutoFixture as a functor instead.
Comments
I'm curious as to what the "useful features" are that that you left out of the Test Data Generator?
Stuart, thank you for writing. Test Data Generators like the one described here are rich data structures that you can do a lot of interesting things with. As described here, the generator only generates a single value every time you invoke its Generate method. What property-based testing libraries like QuickCheck, FsCheck, and Hedgehog do is that instead of a single random value, they generate many values (the default number seems to be 100).
These property-based testing libraries tend to then 'elevate' their generators into another type of data structure called Arbitraries, and these again into Properties. What typically happens is that they use the Generators to generate values, but for each generated value, they evaluate the associated Property. If all Properties succeed, nothing more happens, but in the case of a test failure, no more values are generated. Instead, the libraries switch to a state where they attempt to shrink the counter-example to a simpler counter-example. It uses a Shrinker associated with the Arbitrary to do this. The end result is that if your test doesn't hold, you'll get an easy-to-understand example of the input that caused the test to fail.
Apart from that, there are many other features of Test Data Generators that I left out. Some of these include ways to combine several Generators to a single Generator. It turns out that Test Data Generators are also Applicative Functors and Monads, and you can use these traits to define powerful combinators. In the future, I'll publish more articles on this topic, but it'll take months, because my article queue has quite a few other articles in front of those.
If you want to explore this topic, I'd recommend playing with FsCheck. While it's written in F#, it also works from C#, and its documentation includes C# examples as well. Hedgehog may also work from C#, but being a newer, more experimental library, its documentation is still sparse.
Hedgehog may also work from C#
That's right. Hedgehog may be used from C# as well.
Test data without Builders
We don't need no steenkin' Test Data Builders!
This is the fifth and final in a series of articles about the relationship between the Test Data Builder design pattern, and the identity functor. In the previous article, you learned why a Builder functor adds little value. In this article, you'll see what to do instead.
From Identity to naked values #
While you can define Test Data Builders with Haskell's Identity functor, it adds little value:
Identity address = fmap (\a -> a { city = "Paris" }) addressBuilder
That's nothing but an overly complicated way to create a data value from another data value. You can simplify the code from the previous article. First, instead of calling them 'Builders', we should be honest and name them as the default values they are:
defaultPostCode :: PostCode defaultPostCode = PostCode [] defaultAddress :: Address defaultAddress = Address { street = "", city = "", postCode = defaultPostCode }
defaultPostCode is nothing but an empty PostCode value, and defaultAddress is an Address value with empty constituent values. Notice that defaultAddress uses defaultPostCode for the postCode value.
If you need a value in Paris, you can simply write it like this:
address = defaultAddress { city = "Paris" }
Likewise, if you need a more specific address, but you don't care about the post code, you can write it like this:
address' = Address { street = "Rue Morgue", city = "Paris", postCode = defaultPostCode }
Notice how much simpler this is. There's no need to call fmap in order to pull the 'underlying value' out of the functor, transform it, and put it back in the functor. Haskell's 'copy and update' syntax gives you this ability for free. It's built into the language.
Building F# values #
Haskell isn't the only language with 'copy and update' syntax. F# has it as well, and in fact, it's from the F# documentation that I've taken the 'copy and update' term.
The code corresponding to the above Haskell code looks like this in F#:
let defaultPostCode = PostCode [] let defaultAddress = { Street = ""; City = ""; PostCode = defaultPostCode } let address = { defaultAddress with City = "Paris" } let address' = { Street = "Rue Morgue"; City = "Paris"; PostCode = defaultPostCode }
The syntax is a little different, but the concepts are the same. F# adds the keyword with to 'copy and update' expressions, which translates easily back to C# fluent interfaces.
Building C# objects #
In a previous article, you saw how to refactor your domain model to a model of Value Objects with fluent interfaces.
In your unit tests, you can define natural default values for testing purposes:
public static class Natural { public static PostCode PostCode = new PostCode(); public static Address Address = new Address("", "", PostCode); public static InvoiceLine InvoiceLine = new InvoiceLine("", PoundsShillingsPence.Zero); public static Recipient Recipient = new Recipient("", Address); public static Invoice Invoice = new Invoice(Recipient, new InvoiceLine[0]); }
This static Natural class is a test-specific container of 'good' default values. Notice how, once more, the Address value uses the PostCode value to fill in the PostCode property of the default Address value.
With these default test values, and the fluent interface of your domain model, you can easily build a test address in Paris:
var address = Natural.Address.WithCity("Paris");
Because Natural.Address is an Address object, you can use its WithCity method to build a test address in Paris, and where all other constituent values remain the default values.
Likewise, you can create an address on Rue Morgue, but with a default post code:
var address = new Address("Rue Morgue", "Paris", Natural.PostCode);
Here, you can simply create a new Address object, but with Natural.PostCode as the post code value.
Conclusion #
Using a fluent domain model obviates the need for Test Data Builders. There's a tendency among functional programmers to overbearingly state that design patterns are nothing but recipes to overcome deficiencies in particular programming languages or paradigms. If you believe such a claim, at least it ought to go both ways, but at the conclusion of this article series, I hope I've been able to demonstrate that this is true for the Test Data Builder pattern. You only need it for 'classic', mutable, object-oriented domain models.
- For mutable object models, use Test Data Builders.
- Consider, however, modelling your domain with Value Objects and 'copy and update' instance methods.
- Even better, consider using a programming language with built-in 'copy and update' expressions.
With[...] methods:
public class Invoice { public Recipient Recipient { get; } public IReadOnlyCollection<InvoiceLine> Lines { get; } public Invoice( Recipient recipient, IReadOnlyCollection<InvoiceLine> lines) { if (recipient == null) throw new ArgumentNullException(nameof(recipient)); if (lines == null) throw new ArgumentNullException(nameof(lines)); this.Recipient = recipient; this.Lines = lines; } public Invoice WithRecipient(Recipient newRecipient) { return new Invoice(newRecipient, this.Lines); } public Invoice WithLines(IReadOnlyCollection<InvoiceLine> newLines) { return new Invoice(this.Recipient, newLines); } public override bool Equals(object obj) { var other = obj as Invoice; if (other == null) return base.Equals(obj); return object.Equals(this.Recipient, other.Recipient) && Enumerable.SequenceEqual( this.Lines.OrderBy(l => l.Name), other.Lines.OrderBy(l => l.Name)); } public override int GetHashCode() { return this.Recipient.GetHashCode() ^ this.Lines.GetHashCode(); } }
That may seem like quite a maintenance burden (and it is), but consider that it has the same degree of complexity and overhead as defining a Test Data Builder for each domain object. At least, by putting this extra code in your domain model, you make all of that API (all the With[...] methods, and the structural equality) available to other production code. In my experience, that's a better return of investment than isolating such useful features only to test code.
Still, once you've tried using a language like F# or Haskell, where 'copy and update' expressions come with the language, you realise how much redundant code you're writing in C# or Java. The Test Data Builder design pattern truly is a recipe that addresses deficiencies in particular languages.
Comments
Leveraging extension methods to implement 'With' API is relatively straightforward and you have both developper friendly API and a great separation of concern namely definition and usage.
If you choose to implement extensions in another assembly you could manage who have access to it: unit test only, another assembly, whole project.
You can split API according to context/user too. It can also be useful to enforce some guidelines.
I have some ugly POC code in my branch Roslyn builder generator - it is only a starting point but I think it has some potential.
Dominik, thank you for writing. I admit that I haven't given this much thought, but it strikes me as one of those 'interesting problems' that programmers are keen to solve. It looks to me like a bit of a red herring, as I tend to be sceptical of schemes to generate code. What problem does it address? That one has to type? That's rarely the bottleneck in software development.
Granted, it gets tedious to manually add all those With[...] methods, but there's a lot of things about C# that's tedious. There's a reason I prefer F# instead.
Thanks for respond - I think that for each comment you now have 1+ blog post to respond ;). Despite the fact that I should consider learning new language like F# to open my mind I will focus on c# aspect.
I understand your consideration about code generation but I thing that when we repeat some actions over and over we automatically think about some automations - this is the source of computers I think. Currently I'm working in project where we use Test Builder Pattern heavily and every time I think about writing another builder my motivation is decreasing because psychologically is not interesting anymore and I would be happy to give that to someone else or machine.
When I started to understand what is Roslyn and what it can do it just open my eyes to new opportunities. Generating some simple but frequently repeating code give me more time on focusing on real domain problems and keep my frustration level on low position :)
Of course this is not BIG problem solver but only new approach for simplification of daily tasks - another advantage is that Roslyn I creating normal c# code file that can be navigated from code, can be seen in debugger (in contrast to IL injectors), so there is no magical black boxes. Disadvantage is that currently generating code is very simple - it involves some external nugets and I feel that writing generator in Roslyn could be simplified;
ps. Commenting via pull request is interesting experience - feels like pro ;)
Dominik, while it isn't based on Roslyn, are you aware of AutoFixture?
Yes, I discovered this tool together with your blog ;) I think it is good enough - Roslyn approach is only alternative not basing on reflection or IL injection.
I will try to use AutoFixture in next project so I will see it will survive my requirements.
If I understand correctly, one of your claims is that a fluent C# syntax for expressing change (i.e. "with" methods for an immutable value object) is equivalent to F#'s copy and update syntax for records in the sense that any code written with one can be written with the other. I agree with that. Then you pointed out some advantages with the F# syntax. Among the advantages of F#'s syntax is that there is less code to write in the first place and less code to maintain.
I see an advantage with C#'s syntax. Suppose the only constructor of the value object is internal but all its properties and "with" methods are public. Then adding a new (public) property and corresponding (public) "with" method is not a breaking change. As far as I know, this is not possible with F#.* Either the record consturctor is public or it is not public. If the record's constructor is public, then the copy and update syntax is also public but adding a proprty to the record is a breaking change. Otherwise, the record's constructor is not public, so the copy and update syntax is not available.
I have an extremely short list of advantages of C# over F#, and this is one of them.
*It is possible to put an access modifier immediately after the equals sign when defining a record. However, the documentation for record syntax is missing this information. When I try to put an access modifier before a field identifier, I get a compiler error that says
FS0575 Accessibility modifiers are not permitted on record fields. Use 'type R = internal ...' or 'type R = private ...' to give an accessibility to the whole representation.
P.S. For those that want to write functionally in C#, I recommend using Langage Ext. in particular, a somewhat recently added feature is auto-generated "with" methods.
Tyson, thank you for writing. Let's get the uncontroversial part of this discussion out of the way first: F# record types compile to IL that's equivalent to what a properly-written C# Value Object compiles to. At the IL level, there's no difference.
At the language level, it's true that F# records is a specialised syntax that enables you to succinctly define static types to model data. It's not a general-purpose syntax, so there's definitely things it doesn't allow you to express. F# has normal class syntax for those needs.
That record types aren't refactoring-safe is a known issue. This is true not only for F# records, but for Haskell data types as well. In Haskell public APIs, you sometimes see that combination that you describe. The type has a private constructor, but the library then provides functions to manipulate it (essentially copy-and-update functions). You sometimes see that in F# as well, but here a class would often have been a better choice. Haskell doesn't have object-oriented classes, so it has to resort to that sort of hack to keep APIs backwards compatible.
When you write a public API in F#, choosing between a record and a class as a data carrier is an important choice. When APIs are published (e.g. on nuget.org), you'll have little success with your library if you regularly introduce breaking changes.
For internal use, the story is different. You can use F# records to express domain models with a few lines of code. If you later find out that you have to change the model, then you do that, and fix the ensuing compilation errors.
Public APIs represent more work, regardless of the language in which they're written. Yes, you need to carefully and deliberately design a public library's API and data structures. I don't think, however, that that should detract us from using productive language features for application-specific use.
Let's get the uncontroversial part of this discussion out of the way first...I am right with you. Your entire comment was uncontroversial to me :)
When you write a public API in F#, choosing between a record and a class as a data carrier is an important choice. ... here a class would often have been a better choice.(I quoted you out of order there. I hope this doesn't misrepresent what you were saying. I don't think it does.) I am really interested to learn more about that.
I found the series that includes this blog post when I searched on Google for "builder pattern F#". This series is primarily about the test data builder design pattern. As I understand it, I would describe this pattern as a special case of the (general case) builder design pattern in which all arguments have reasonable defaults.
Have you ever written a builder that accepted multiple arguments one at a time none of which have reasonable defaults? Have you ever blogged about this (more general) build design pattern?
As a good student of your ;) I wonder if the builder design pattern corresponds to some universal abstraction. Among the fluent interfaces that I am most impressed with are configuration in Entity Framework and Fluent Assertions. Of course I could try to make my own fluent interface by copying them, and that would probably work out reasonably well. At the same time, I would like to learn from you and your frustration (if that description is accurate) that you expressed (at the end of the next and last post in this series) with the API of your AutoFixture project failing to use a potential universal abstraction (namely functors).
Tyson, thank you for bringing the Builder pattern to my attention. I haven't written much about it yet, but I believe that it'd be a perfect fit for my article series on how certain design patterns relate to universal abstractions. When I get some time, I'll have to write one or more articles about that topic.
In short, though, I think that the Builder pattern as described in Design Patterns is isomorphic to the Fluent Builder pattern, as you also imply. It remains for me to more formally argue that case, but in short, the Builder pattern is described as a set of virtual methods that return void. Since all these methods return void, each method could, instead, return the object to which it belongs, and that's what a Fluent Builder does.
Once you return the Builder object, you could, instead of mutating and returning the instance, return a new object. That new object is a near-copy of the previous Builder, with only one change applied to it. Now you have a function that essentially takes a Builder as input, plus some other input, and returns a Builder. That's just a curried endomorphism.
Once again, every time we run into a composable design pattern, it turns out to be a monoid. It shouldn't surprise us much, though, since the original Builder pattern as described in Design Patterns has void methods, and such methods compose.
The most formal treatment I have seen about fluent APIs was in this blog post. The context is that we are trying to create a word in some language specified by a grammar, and the methods in the fluent API correspond to production rules in the grammar. The company behind that blog post seems to able to generate a fluent API (in Java) given as input the produciton rules of a grammar. Their main use case appears to be creating a fluent API for constructing SQL queries against a database (presumably by first converting a database schema into corresponding grammar production rules). The end result reminds me of F#'s SQL type provider.
Tyson, I've now published an article that hopefully answers some of your questions. I must admit that I'm still puzzled by this question:
If I left that unanswered, then at least I hope that I've managed to put enough building blocks into position to be able to address it. Can you elaborate?"Have you ever written a builder that accepted multiple arguments one at a time none of which have reasonable defaults?"
I have now elaborated in this comment. Thanks for waiting :)
Builder as Identity
In which the Builder functor turns out to be nothing but the Identity functor in disguise.
This is the fourth in a series of articles about the relationship between the Test Data Builder design pattern, and the identity functor. In the previous article, you saw how a generic Test Data Builder can be modelled as a functor.
You may, however, be excused if you're slightly underwhelmed. Modelling a Test Data Builder as a functor doesn't seem to add much value.
Haskell's Identity functor #
In the previous article, you saw the Builder functor implemented in various languages, including Haskell:
newtype Builder a = Builder a deriving (Show, Eq) instance Functor Builder where fmap f (Builder a) = Builder $ f a
The fmap implementation is literally a one-liner: pattern match the value a out of the Builder, call f with a, and package the result in a new Builder value.
For many trivial functors, it turns out that the Glasgow Haskell Compiler (GHC) can automatically implement fmap with a language extension:
{-# LANGUAGE DeriveFunctor #-}
module Builder where
newtype Builder a = Builder a deriving (Show, Eq, Functor)
Notice the DeriveFunctor language extension. This enables the compiler to automatically implement fmap by adding Functor to the deriving list.
Perhaps we should take this as a hint. If the compiler can automatically make Builder a Functor, perhaps it doesn't add that much value.
This particular Builder is equivalent to Haskell's built-in Identity functor. Identity is a 'no-op' functor, if you will. While it's a functor, it doesn't 'do' anything. It's similar to the Null Object design pattern, in the sense that the only value it adds is that it enables you to turn any naked value into a functor. This can occasionally be useful if you need to pass a functor to an API.
PostCode and Address builders #
You can rewrite the previous PostCode and Address Test Data Builders as Identity values:
postCodeBuilder :: Identity PostCode postCodeBuilder = Identity $ PostCode [] addressBuilder :: Identity Address addressBuilder = Identity Address { street = "", city = "", postCode = pc } where Identity pc = postCodeBuilder
As in the previous examples, postCodeBuilder is nothing but a 'good' default PostCode value. This time, it's turned into an Identity value, instead of a Builder value. The same is true for addressBuilder - notice that it uses postCodeBuilder for the postCode value.
This enables you to build an address in Paris, like previous examples:
Identity address = fmap (\a -> a { city = "Paris" }) addressBuilder
This builds an address with city bound to "Paris", but with all other values still at their default values:
Address {street = "", city = "Paris", postCode = PostCode []}
You can also build an address from an Identity of a different generic type:
Identity address' = fmap newAddress postCodeBuilder where newAddress pc = Address { street = "Rue Morgue", city = "Paris", postCode = pc }
Notice that this example uses postCodeBuilder as an origin, but creates a new Address value. In this expression, newAddress is a local function that takes a PostCode value as input, and returns an Address value as output.
Summary #
Neither F# nor C# comes with a built-in identity functor, but it'd be as trivial to create them as the code you've already seen. In the previous article, you saw how to define a Builder<'a> type in F#. All you have to do is to change its name to Identity<'a>, and you have the identity functor. You can perform a similar rename for the C# code in the previous articles.
Since the Identity functor doesn't really 'do' anything, there's no reason to use it for building test values. In the next article, you'll see how to discard the functor and in the process make your code simpler.
Next: Test data without Builders.
The Builder functor
The Test Data Builder design pattern as a functor.
This is the third in a series of articles about the relationship between the Test Data Builder design pattern, and the identity functor. The previous article introduced this generic Builder class:
public class Builder<T> { private readonly T item; public Builder(T item) { if (item == null) throw new ArgumentNullException(nameof(item)); this.item = item; } public Builder<T1> Select<T1>(Func<T, T1> f) { var newItem = f(this.item); return new Builder<T1>(newItem); } public T Build() { return this.item; } public override bool Equals(object obj) { var other = obj as Builder<T>; if (other == null) return base.Equals(obj); return object.Equals(this.item, other.item); } public override int GetHashCode() { return this.item.GetHashCode(); } }
The workhorse is the Select method. As I previously promised to explain, there's a reason I chose that particular name.
Query syntax #
C# comes with a small DSL normally known as query syntax. People mostly think of it in relation to ORMs such as Entity Framework, but it's a general-purpose language feature. Still, most developers probably associate it with the IEnumerable<T> interface, but it's more general than that. In fact, any type that comes with a Select method with a compatible signature supports query syntax.
I deliberately designed the Builder's Select method to support query syntax:
Address address = from a in Builder.Address select a.WithCity("Paris");
Builder.Address is a Builder<Address> object that contains a 'good' default Address value. Since Builder<T> has a compatible Select method, you can 'query it'. In this example, you use the WithCity method to explicitly pin the Address object's City property, while all the other Address values remain the default values.
There's an extra bit (pun intended) of compiler magic at work. Did you wonder how a Builder<Address> automatically turns into an Address value? After all, address is of the type Address, not Builder<Address>.
I specifically added an implicit conversion so that I didn't have to surround the query expression with brackets in order to call the Build method:
public static implicit operator T(Builder<T> b) { return b.item; }
This conversion is defined on Builder<T>. It's the reason I explicitly use the type name when I declare the address variable above, instead of using the var keyword. Declaring the type forces the implicit conversion.
You can also use query syntax to map one constructed Builder type into another (and ultimately to the value it contains):
Address address = from pc in Builder.PostCode select new Address("Rue Morgue", "Paris", pc);
This expression starts with a Builder<PostCode> object, transforms it into a Builder<Address> object, and then finally uses the implicit conversion to turn the Builder<Address> into an Address object.
Even a more complex 'query' looks almost palatable:
Invoice invoice = from i in Builder.Invoice select i.WithRecipient( from r in Builder.Recipient select r.WithAddress(Builder.Address.WithNoPostCode()));
Again, the implicit type conversion makes the syntax much cleaner.
Functor #
Isn't it amazing that the C# designers were able to come up with such a generally useful language feature? It certainly is a nice piece of work, but it's based on a an existing body of knowledge.
A type like Builder<T> with a suitable Select method is a functor. This is a term from category theory, but I'll try to avoid turning this article into a category theory lecture. Likewise, I'm not going to talk specifically about monads here, although it's a closely related topic. A functor is a mapping between categories; it maps an object from one category into an object of another category.
Although I've never seen Microsoft explicitly acknowledge the connection to functors and monads, it's clear that it's there. One of the principal designers of LINQ was Erik Meijer, who definitely knows his way around category theory and functional programming. A functor is a simple, but widely applicable abstraction.
In order to be a functor, a type must have an associated mapping. In C#'s query syntax, this is a method named Select, but more often it's called map.
Haskell Builder #
In Haskell, the mapping is called fmap, and you can define the Builder functor like this:
newtype Builder a = Builder a deriving (Show, Eq) instance Functor Builder where fmap f (Builder a) = Builder $ f a
Notice how terse the definition is, compared to the C# version. Despite the difference in size, they accomplish the same goal. The first line of code defines the Builder type, complete with structural equality (Eq) and the ability to convert a Builder value to a string (Show).
This Builder type is explicitly defined as a Functor in the second expression, where the fmap function is implemented. The code is similar to the Select method in the above C# example: f is a function that takes the generic type a (corresponding to T in the C# example) as input, and returns a value of the generic type b (corresponding to T1 in the C# example). The mapping pulls the underlying value out of the input Builder, calls f with that value, and puts the return value into a new Builder.
In Haskell, a functor is part of the language itself, so Builder is explicitly declared to be a Functor instance.
If you define some default Builder values, corresponding to the above Builder.Address, you can use them to build addresses in the same way:
Builder address = fmap (\a -> a { city = "Paris" }) addressBuilder
Here, addressBuilder is a Builder Address value, corresponding to the C# Builder.Address value. \a -> a { city = "Paris" } is a lambda expression that takes an Address value as input, and return a similar value as output, only with city explicitly bound to "Paris".
F# example #
Unlike Haskell, F# doesn't treat functors as an explicit construct, but you can still define a Builder functor:
type Builder<'a> = Builder of 'a module Builder = // ('a -> 'b) -> Builder<'a> -> Builder<'b> let map f (Builder x) = Builder (f x)
You can see how similar this is to the Haskell example. In F#, it's common to define a module with the same name as a generic type. This example defines a generic Builder<'a> type and a supporting Builder module. Normally, a module would contain other functions, in addition to map.
Just like in C# and Haskell, you can build an address in Paris with a predefined Builder value as a start:
let (Builder address) = addressBuilder |> Builder.map (fun a -> { a with City = "Paris" })
Again, addressBuilder is a Builder<Address> that contains a 'default' Address (test) value. You use Builder.map with a lambda expression to map the default value into a new Address value where City is bound to "Paris".
Functor laws #
In order to be a proper functor, an object must obey two simple laws. It's not enough that a mapping function exists, it must also obey the laws. While that sounds uncomfortably like mathematics, the laws are simple and intuitive.
The first law is that when the mapping returns the input, the functor returned is also the input functor. There's only one (generic) function that returns its input unmodified. It's called the identity function (often abbreviated id).
Here's an example test case that illustrates the first functor law for the C# Builder<T>:
[Fact] public void BuilderObeysFirstFunctorLaw() { Func<int, int> id = x => x; var sut = new Builder<int>(42); var actual = sut.Select(id); Assert.Equal(sut, actual); }
The .NET Base Class Library doesn't come with a built-in identity function, so the test case first defines it as id. Normally, the identity function would be defined as a function that takes a value of the generic type T as input, and returns the same value (still of type T) as output. This test is only an example for the type int, so it also defines the identity function as constrained to int.
The test creates a new Builder<int> with the value 42, and calls Select with id. Since the first functor law says that mapping with the identity function must return the input functor, the expected value is the sut variable.
This test is only an example of the first functor law. It doesn't prove that Builder<T> obeys the law for all generic types (T) and for all values. It only proves that it holds for the integer 42. You get the idea, though, I'm sure.
The second functor law says that if you chain two functions to make a third function, and map your functor using that third function, the result should be equal to the result you get if you chain two mappings made out of those two functions. Here's an example:
[Fact] public void BuilderObeysSecondFunctorLaw() { Func<int, string> g = i => i.ToString(); Func<string, string> f = s => new string(s.Reverse().ToArray()); var sut = new Builder<int>(1337); var actual = sut.Select(i => f(g(i))); var expected = sut.Select(g).Select(f); Assert.Equal(expected, actual); }
This test case (which is, again, only an example) first defines two functions, f and g. It then creates a new Builder<int> and calls Select with the combined function f(g). This returns the actual result, which is a Builder<string>.
This result should be equal to first calling Select with g (which returns a Builder<string>), and then calling Select with f (which returns another Builder<string>). These two Builder objects should be equal to each other, which they are.
Both these tests compare an expected Builder to an actual Builder, which is the reason that Builder<T> overrides Equals in order to have structural equality. In Haskell, the above Builder type has structural equality because it uses the default instance of Eq, and in F#, Builder<'a> has structural equality because that's the default equality for the immutable F# data types.
We can't easily talk about the functor laws without being able to talk about functor values being (or not being) equal to each other, so structural equality is an important element in the discussion.
Summary #
You can define a Test Data Builder as a functor by defining a generic Builder type with a Select method. In order to be a proper functor, it must also obey the functor laws, but these laws are quite natural; you almost have to go out of your way in order to violate them.
A functor is a well-known abstraction. Instead of trying to come up with a half-baked, ad-hoc abstraction, modelling an API based on already known and understood abstractions such as functors will make the API easier to learn. Everyone who knows what a functor is, will automatically have a good understanding of the API. Even if you didn't know about functors until now, you only have to learn about them once.
This can often be beneficial, but for Test Data Builders, it turns out to be a red herring. The Builder functor is nothing but the Identity functor in disguise.
Next: Builder as Identity.
Comments
Maybe I am missing something, so could you explain with few words what is the advantage of having this _generic builder_?
I mean, inmutable entities and _with methods_ seems to be enough to easily create test data without builders, for example:
var invoice = DefaultTestObjects.Invoice
.WithRecipient(DefaultTestObjects.Recipient
.WithAddress(DefaultTestObjects.Address
.WithNoPostCode()
.WithCity("Paris"))
.WithDate(new DateTimeOffset(2017, 8, 29)));
Andrés, thank you for writing. I hope that the next two articles in this article series will answer your question. It seems, however, that you've already predicted where this is headed. A fine display of critical thinking!
Just for the DSL and implicit conversion laius it's worth reading.
_Implicit/explicit_ is a must-have to lighten _value object_ usage and contributes to deliver proper API.
Thank you Mark.

Comments
Actually, in a lot of financial systems money is stored in cents, and therefore as integers, because it avoids rounding errors.
Great articles btw! :)
Hrvoje, thank you for writing. Yes, it's a good point that you could model the values as cents and rappen, but I think I recall that Kent Beck's text distinctly discusses dollars and francs. I am, however, currently travelling, without access to the book, so I can't check.
The scenario, as simplistic as it may be, involves currency exchange, and exchange rates tend to involve much smaller fractions. As an example, right now, one currency exchange web site reports that 1 CHF is 1.01950 USD. Clearly, representing the U.S. currency with cents would incur a loss of precision, because that would imply an exchange rate of 102 cents to 100 rappen. I'm sure arbitrage opportunities would be legion if you ever wrote code like that.
If I remember number theory correctly, you can always scale any rational number to an integer. I.e. in this case, you could scale 1.01950 to 101,950. There's little reason to do that, because you have the
All of this, however, is just idle speculation on my point. I admit that I've never had to implement complex financial calculations, so there may be some edge cases of which I'm not aware. For all the run-of-the-mill eCommerce and payment solutions I've implemented over the years,decimalstruct for that purpose:decimalhas always been more than adequate.Although exchange rates are typically represented as decimal fractions, it does not follow that amounts of money should be, even if the amounts were determined by calculations involving that exchange rate.
The oversimplified representation of foreign exchange (FX) in Kent Beck's money examples has always struck me as a particularly weak aspect (and not simply because they are integers; that's the least of the problems). You could argue that the very poor modelling of FX is tolerable because that aspect of the problem domain is not the focus in his example. But I think it's problematic because it can lead you to the wrong conclusion about the design of the central parts of the model. Your conclusion that it might be a good idea not to represent a money amount as an integer is an example - I believe it's the wrong conclusion, and that you've been led to it by the completely wrong-headed way his example represents FX.
The nature of foreign exchange is that it is a transaction with a third party. Some entity (perhaps a bank, or the FX trading desk within an company that may or may not be a financial institution (large multinational firms sometimes have their own FX desks) or maybe a friend who has some of the kind of currency you need in her purse) agrees to give you a specific amount of one currency if you give them a specific amount of some other currency, and there is usually an accompanying agreement on the timescale in which the actual monies are to be transferred. (There will sometimes be more than two currencies involved, either because you're doing something complex, or just because you agree to pay a commission fee in some currency that is different from either the 'to' or 'from' currency.) The amounts of actual money that changes hands will invariably be some integer multiple of the smallest available denomination of the currencies in question.
There may well be a published exchange rate. It might even form part of some contract, although such an advertised rate is very often not binding because markets can move fast, and the exchange rate posted when you started negotiation could change at any moment, and might not be available by the time you attempt to reach an agreement. In cases where a published exchange rate has some reliable meaning, it will necessarily come with a time limit (and unless this time limit is pretty short, the time window itself may come at a price - if someone has agreed to sell you currency for a specific price within some time window, what you have there is in effect either a future or an option, depending on whether you are allowed to decide not to complete the transaction).
One very common case where a 'current' exchange rate does in fact apply is when using a credit or debit card abroad. In this case, somewhere in the terms and conditions that you agreed to at some point in the past, it will say that the bank gets to apply the current rate for some definition of current. (The bank will generally have freedom to define what it means by 'current', which is one of the reasons you tend not to get a very good deal on such transactions.) And there will be rules (often generally accepted conventions, instead of being explicitly set out in the contract) about how the rate is applied. It will necessarily involve some amount of rounding. When you bought something on your credit card in a foreign currency, it will have been for a precise amount in that currency - merchants don't get to charge you Pi dollars for something. And when the bank debits your account, they will also do so by a precise amount - if you've ever used a card in this way you'll know that you didn't end up with some fractional number of cents or pennies or whatever in your account afterwards. So the exchange rate you got in practice will very rarely be exactly the advertised one (unless it's such a large transaction that the amounts involved have more decimal places than the 'current' exchange rate, or, by sheer coincidence, the numbers worked out in such a way that you happened to get the exact exchange rate advertised.).
So although you will often see published exchange rates with multiple decimal places, the actual exchange rate depends entirely on the agreement you strike with whoever it is that is going to give you money in the currency you want in exchange for money in the currency you have. The actual exchanges that result from such agreements do not involve fractional amounts.
Where does this leave Kent's example? Fundamentally, 'reducing' a multi-currency expression to a single-currency result will need to create at least one FX transaction (possibly several). So you'll need some sort of mechanism for agreeing the terms of those transactions with the other party or parties. And realistically you'd want to do something to minimize transaction costs (e.g., if you perform multiple USD to GBP conversions, you'll want to handle that with a single FX transaction), so you'll need some sort of logic for managing that too. It's certainly not going to be as simple as looking up the bank's rate.
Ian, thank you for writing. Much of what you write about foreign exchange matches the little I know. What interested me about Kent Beck's example was that his intuition about good programming lead him to a monoidal design.
It seems to me that your criticism mostly targets how the exchange itself is implemented, i.e. the
Reducemethod, or rather, itsbankargument. In its current form, theBankimplementation is indisputably naive.Would a more sophisticated
Bankimplementation address some of the problems? What if, instead of calling itBank, we called itExchange?Already in its current form, the
Bankimplementation is nothing but a dictionary of exchange rates, defined by afromand atocurrency. It follow that the USD/CHF entry isn't the same as the CHF/USD entry. They don't have to be each others' inverses. Doesn't this, already, enable arbitrage?Another change that we could add to a hypothetical more sophisticated
Exchangeclass would be to subtract a fee from the returned value. Would that address one of the other concerns?Furthermore, we could add a time limit to each dictionary of exchange rates.
It's not my intent to claim that such a model would be sufficient to implement an international bank's foreign exchange business, but that's not the scenario that Kent Beck had in mind. The introduction to Test-Driven Development By Example explicitly explains that the scenario is a bond portfolio management system. Doesn't the overall API he outlines sufficiently address that?
Hi Mark, thanks for the code examples here. I do have a few clarifying questions:
PlusIdentitybehaves similar to the identity element for multiplication (1)". But with multiplication, when you multiply the identity element with another factor, you get the other factor, not the identity element. Am I misreading you here?Money Reduce(Bank bank, string to);, but your Haskell example hasreduce :: Ord a => Map (String, a) Int -> a -> Expression -> Int. The return types here are different, right? C# returns aMoneyobject. Haskell seems to return anIntfrom the code signature and sample output. Was this intentional?I know I'm often focused on little details, I just want to make sure it's not a sign of me misunderstanding the main concept. The rest of the article is very clear :)
Mark, thank you for writing. You're right about the first quote - it does look a little odd. The first sentence, however, looks good enough to me. The
Timesmethod does, indeed, returnthis- itself. The second sentence, on the other hand, looks wrong. I'm not sure what I had in mind when I wrote that four years ago, but now that you ask, it does look incorrect. It still behaves like zero. I think I'm going to strike out that sentence. Thank you for pointing that out.You're also right about the Haskell example. For better parity, I should have wrapped the result of
reducein a newExpressionvalue. This is trivially possible like this:This new 'overload' calls the above
reducefunction and wraps the resultingIntin a newExpressionvalue.After the article was written, a proposal to make Semigroup as a superclass of Monoid came out and eventually made it into GHC 8+. The changes so that the Haskell part of the article compiles (with GHC 8+) are:
{-# LANGUAGE CPP #-} import Data.Semigroup (stimesMonoid) #if !MIN_VERSION_base(4,11,0) import qualified Data.Semigroup as Semigroup #endif instance Monoid Expression where #if !MIN_VERSION_base(4,11,0) mappend = (Semigroup.<>) #endif mempty = MoneyIdentity instance Semigroup Expression where MoneyIdentity <> y = y x <> MoneyIdentity = x x <> y = Sum x y