ploeh blog danish software design
Monad laws
An article for object-oriented programmers.
This article is an instalment in an article series about monads.
Just as functors must obey the functor laws, monads must follow the monad laws. When looked at from the right angle, these are intuitive and reasonable rules: identity and associativity.
That sounds almost like a monoid, but the rules are more relaxed. For monoids, we require a binary operation. That's not the case for functors and monads. Instead of binary operations, for monads we're going to use Kleisli composition.
This article draws heavily on the Haskell wiki on monad laws.
In short, the monad laws comprise three rules:
- Left identity
- Right identity
- Associativity
The article describes each in turn, starting with left identity.
Left identity #
A left identity is an element that, when applied to the left of an operator, doesn't change the other element. When used with the fish operator it looks like this:
id >=> h ≡ h
For monads, id turns out to be return, so more specifically:
return >=> h ≡ h
In C# we can illustrate the law as a parametrised test:
[Theory] [InlineData(-1)] [InlineData(42)] [InlineData(87)] public void LeftIdentityKleisli(int a) { Func<int, Monad<int>> @return = Monad.Return; Func<int, Monad<string>> h = i => Monad.Return(i.ToString()); Func<int, Monad<string>> composed = @return.Compose(h); Assert.Equal(composed(a), h(a)); }
Recall that we can implement the fish operators as Compose overloads. The above test demonstrates the notion that @return composed with h should be indistinguishable from h. Such a test should pass.
Keep in mind, however, that Kleisli composition is derived from the definition of a monad. The direct definition of monads is that they come with a return and bind functions (or, alternatively return and join). If we inline the implementation of Compose, the test instead looks like this:
[Theory] [InlineData(-1)] [InlineData(42)] [InlineData(87)] public void LeftIdentityInlined(int a) { Func<int, Monad<int>> @return = Monad.Return; Func<int, Monad<string>> h = i => Monad.Return(i.ToString()); Func<int, Monad<string>> composed = x => @return(x).SelectMany(h); Assert.Equal(composed(a), h(a)); }
or, more succinctly:
Assert.Equal(@return(a).SelectMany(h), h(a));
This is also the way the left identity law is usually presented in Haskell:
return a >>= h = h a
In Haskell, monadic bind is represented by the >>= operator, while in C# it's the SelectMany method. Thus, the Haskell and the C# representations are equivalent.
Right identity #
Right identity starts out similar to left identity. Using the fish operator, the Haskell wiki describes it as:
f >=> return ≡ f
Translated to a C# test, an example of that law might look like this:
[Theory] [InlineData("foo")] [InlineData("ploeh")] [InlineData("lawful")] public void RightIdentityKleisli(string a) { Func<string, Monad<int>> f = s => Monad.Return(s.Length); Func<int, Monad<int>> @return = Monad.Return; Func<string, Monad<int>> composed = f.Compose(@return); Assert.Equal(composed(a), f(a)); }
Again, if we inline Compose, the test instead looks like this:
[Theory] [InlineData("foo")] [InlineData("ploeh")] [InlineData("lawful")] public void RightIdentityInlined(string a) { Func<string, Monad<int>> f = s => Monad.Return(s.Length); Func<int, Monad<int>> @return = Monad.Return; Func<string, Monad<int>> composed = x => f(x).SelectMany(@return); Assert.Equal(composed(a), f(a)); }
Now explicitly call the f function and assign it to a variable m:
[Theory] [InlineData("foo")] [InlineData("ploeh")] [InlineData("lawful")] public void RightIdentityInlinedIntoAssertion(string a) { Func<string, Monad<int>> f = s => Monad.Return(s.Length); Func<int, Monad<int>> @return = Monad.Return; Monad<int> m = f(a); Assert.Equal(m.SelectMany(@return), m); }
The assertion is now the C# version of the normal Haskell definition of the right identity law:
m >>= return = m
In other words, return is the identity element for monadic composition. It doesn't really 'do' anything in itself.
Associativity #
The third monad law is the associativity law. Keep in mind that an operator like + is associative if it's true that
(x + y) + z = x + (y + z)
Instead of +, the operator in question is the fish operator, and since values are functions, we typically call them f, g, and h rather than x, y, and z:
(f >=> g) >=> h ≡ f >=> (g >=> h)
Translated to a C# test as an example, the law looks like this:
[Theory] [InlineData(0)] [InlineData(1)] [InlineData(2)] public void AssociativityKleisli(double a) { Func<double, Monad<bool>> f = i => Monad.Return(i % 2 == 0); Func<bool, Monad<string>> g = b => Monad.Return(b.ToString()); Func<string, Monad<int>> h = s => Monad.Return(s.Length); Func<double, Monad<int>> left = (f.Compose(g)).Compose(h); Func<double, Monad<int>> right = f.Compose(g.Compose(h)); Assert.Equal(left(a), right(a)); }
The outer brackets around (f.Compose(g)) are actually redundant; we should remove them. Also, inline Compose:
[Theory] [InlineData(0)] [InlineData(1)] [InlineData(2)] public void AssociativityInlined(double a) { Func<double, Monad<bool>> f = i => Monad.Return(i % 2 == 0); Func<bool, Monad<string>> g = b => Monad.Return(b.ToString()); Func<string, Monad<int>> h = s => Monad.Return(s.Length); Func<double, Monad<string>> fg = x => f(x).SelectMany(g); Func<double, Monad<int>> left = x => fg(x).SelectMany(h); Func<bool, Monad<int>> gh = x => g(x).SelectMany(h); Func<double, Monad<int>> right = x => f(x).SelectMany(gh); Assert.Equal(left(a), right(a)); }
If there's a way in C# to inline the local compositions fg and gh directly into left and right, respectively, I don't know how. In any case, the above is just an intermediate step.
For both left and right, notice that the first step involves invoking f with x. If, instead, we call that value m, we can rewrite the test like this:
[Theory] [InlineData(0)] [InlineData(1)] [InlineData(2)] public void AssociativityInlinedIntoAssertion(double a) { Func<double, Monad<bool>> f = i => Monad.Return(i % 2 == 0); Func<bool, Monad<string>> g = b => Monad.Return(b.ToString()); Func<string, Monad<int>> h = s => Monad.Return(s.Length); Monad<bool> m = f(a); Assert.Equal(m.SelectMany(g).SelectMany(h), m.SelectMany(x => g(x).SelectMany(h))); }
The above assertion corresponds to the way the associativity law is usually represented in Haskell:
(m >>= g) >>= h = m >>= (\x -> g x >>= h)
Once more, keep in mind that >>= in Haskell corresponds to SelectMany in C#.
Conclusion #
A proper monad must satisfy the three monad laws: left identity, right identity, and associativity. Together, left identity and right identity are know as simply identity. What's so special about identity and associativity?
As Bartosz Milewski explains, a category must satisfy associativity and identity. When it comes to monads, the category in question is the Kleisli category. Or, as the Haskell wiki puts it:
Monad axioms:
Kleisli composition forms
a category.
Subsequent articles in this article series will now proceed to give examples of concrete monads, and what the laws look like for each of these.
Next: The List monad.
Kleisli composition
A way to compose two monadic functions. An article for object-oriented programmers.
This article is an instalment in an article series about monads.
There's a bit of groundwork which will be useful before we get to the monad laws. There are two ways to present the monad laws. One is quite unintuitive, but uses only the concepts already discussed in the introductory article. The other way to present the laws is much more intuitive, but builds on a derived concept: Kleisli composition.
I find it preferable to take the intuitive route, even if it requires this little detour around the Kleisli category.
Monadic functions #
Imagine some monad - any monad. It could be Maybe (AKA Option), Either (AKA Result), Task, State, etcetera. In Haskell notation we denote it m. (Don't worry if you don't know Haskell. The type notation is fairly intuitive, and I'll explain enough of it along the way.)
You may have a function that takes some input and returns a monadic value. Perhaps it's a parser that takes a string as input and returns a Maybe or Either as output:
String -> Maybe Int
Perhaps it's a database query that takes an ID as input and returns a Task or IO value:
UUID -> IO Reservation
Notice that in Haskell, you write the input to the left of the output. (This is also the case in F#.) Functions looks like arrows that point from the input to the output, which is a common depiction that I've also used before.
If we generalise this notation, we would write a monadic function like this:
a -> m b
a is a generic type that denotes input. It could be String or UUID as shown above, or anything else. Likewise, b is another generic type that could be Int, Reservation, or anything else. And m, as already explained, may be any monad. The corresponding C# method signature would be:
Func<T, Monad<T1>>
In C#, it's idiomatic to name generic type arguments T and T1 rather than a and b, but the idea is the same.
The previous article used Functor<T> as a stand-in for any functor. Likewise, now that you know what a monad is, the type Monad<T> is a similar pretend type. It symbolises 'any monad'.
Kleisli composition #
In Functions as pipes you got a visual illustration of how functions compose. If you have a function that returns a Boolean value, you can use that Boolean value as input to a function that accepts Boolean values as input. Generalised, if one function returns a and another function accepts a as input, you can compose these two functions:
(a -> b) -> (b -> c) -> (a -> c)
A combinator of this type takes two functions as input: a -> b (a function from a to b) and (b -> c), and returns a new function that 'hides' the middle step: a -> c.
If this is possible, it seems intuitive that you can also compose monadic functions:
(>=>) :: Monad m => (a -> m b) -> (b -> m c) -> a -> m c
The >=> operator is known as the fish operator - or more precisely the right fish operator, since there's also a left fish operator <=<.
This is known as Kleisli composition. In C# you could write it like this:
public static Func<T, Monad<T2>> Compose<T, T1, T2>( this Func<T, Monad<T1>> action1, Func<T1, Monad<T2>> action2) { return x => action1(x).SelectMany(action2); }
Notice that Kleisli composition works for any monad. You don't need any new abilities in order to compose a monad in this way. The composition exclusively relies on SelectMany (monadic bind).
Here's a usage example:
Func<string, Monad<int>> f = s => Monad.Return(s.Length); Func<int, Monad<bool>> g = i => Monad.Return(i % 2 == 0); Func<string, Monad<bool>> composed = f.Compose(g);
The Compose method corresponds to the right fish operator, but obviously you could define an overload that flips the arguments. That would correspond to the left fish operator.
Universality #
Kleisli composition seems compelling, but in reality I find that I rarely use it. If it isn't that useful, then why dedicate an entire article to it?
As I wrote in the introduction, it's mostly because it gives us an intuitive way to describe the monad laws.
Kleisli arrows form a category. As such, it's a universal abstraction. I admit that this article series has strayed away from its initial vision of discussing category theory, but I still find it assuring when I encounter some bedrock of theory behind a programming concept.
Conclusion #
Kleisli composition lets you compose two (or more) compatible monadic functions into a single monadic function.
Next: Monad laws.
Monads
A monad is a common abstraction. While typically associated with Haskell, monads also exist in C# and other languages.
This article series is part of a larger series of articles about functors, applicatives, and other mappable containers.
If you understand what a functor is, it should be easy to grasp the idea of a monad. It's a functor you can flatten.
There's a little more to it than that, and you also need to learn what I mean by flatten, but that's the essence of it.
In this article-series-within-an-article series, I'll explain this disproportionally dreaded concept, giving you plenty of examples as well as a more formal definition. Examples will be in both C#, F#, and Haskell, although I plan to emphasise C#. I expect that there's little need of explaining monads to people already familiar with Haskell. I'll show examples as separate articles in this series. These articles are mostly aimed at object-oriented programmers curious about monads.
- Kleisli composition
- Monad laws
- The List monad
- The Maybe monad
- An Either monad
- The Identity monad
- The Lazy monad
- Asynchronous monads
- The State monad
- The Reader monad
- Reactive monad
- The IO monad
- Test Data Generator monad
This list is far from exhaustive; more monads exist.
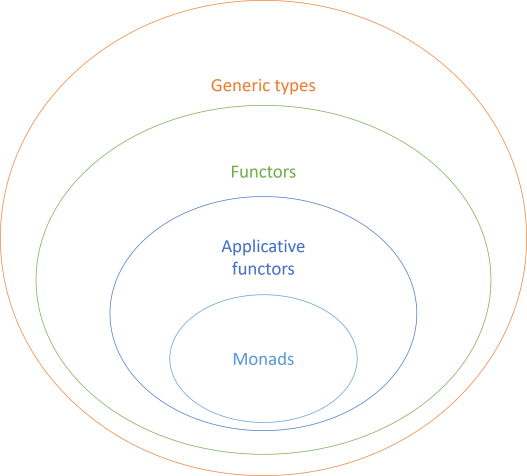
All monads are applicative functors, but not all applicative functors are monads. As the set diagram reiterates, applicative functors are functors, but again: not necessarily the other way around.
Flattening #
A monad is a functor you can flatten. What do I mean by flatten?
As in the article that introduces functors, imagine that you have some Functor<T> container. More concretely, this could be IEnumerable<T>, Maybe<T>, Task<T>, etcetera.
When working with functors, you sometimes run into situations where the containers nest inside each other. Instead of a Functor<decimal>, you may find yourself with a Functor<Functor<decimal>>, or maybe even an object that's thrice or quadruply nested.
If you can flatten such nested functor objects to just Functor<T>, then that functor also forms a monad.
In C#, you need a method with this kind of signature:
public static Functor<T> Flatten<T>(this Functor<Functor<T>> source)
Notice that this method takes a Functor<Functor<T>> as input and returns a Functor<T> as output. I'm not showing the actual implementation, since Functor<T> is really just a 'pretend' functor (and monad). In the example articles that follow, you'll see actual implementation code.
With Flatten you can write code like this:
Functor<decimal> dest = source.Flatten();
Here, source is a Functor<Functor<decimal>>.
This function also exists in Haskell, although there, it's called join:
join :: Monad m => m (m a) -> m a
For any Monad m you can flatten or join a nested monad m (m a) to a 'normal' monad m a.
This is the same function as Flatten, so in C# we could define an alias like this:
public static Functor<T> Join<T>(this Functor<Functor<T>> source) { return source.Flatten(); }
Usually, however, you don't see monads introduced via join or Flatten. It's a shame, really, because it's the most straightforward description.
Bind #
Most languages that come with a notion of monads define them via a function colloquially referred to as monadic bind or just bind. In C# it's called SelectMany, F# computation expressions call it Bind, and Scala calls it flatMap (with a vestige of the concept of flattening). Haskell just defines it as an operator:
(>>=) :: Monad m => m a -> (a -> m b) -> m b
When talking about it, I tend to call the >>= operator bind.
Translated to C# it has this kind of signature:
public static Functor<TResult> SelectMany<T, TResult>( this Functor<T> source, Func<T, Functor<TResult>> selector)
It looks almost like a functor's Select method (AKA map or fmap function). The difference is that this selector returns a functor value (Functor<TResult>) rather than a 'naked' TResult value.
When a Flatten (or Join) method already exists, you can always implement SelectMany like this:
public static Functor<TResult> SelectMany<T, TResult>( this Functor<T> source, Func<T, Functor<TResult>> selector) { Functor<Functor<TResult>> nest = source.Select(selector); return nest.Flatten(); }
I've split the implementation over two lines of code to make it clearer what's going on. That's also the reason I've used an explicit type declaration rather than var.
The Select method exists because the type is already a functor. When you call Select with selector you get a Functor<Functor<TResult>> because selector itself returns a Functor<TResult>. That's a nested functor, which you can Flatten.
You can use SelectMany like this:
Functor<TimeSpan> source = Functor.Return(TimeSpan.FromMinutes(32)); Functor<double> dest = source.SelectMany(x => Functor.Return(x.TotalSeconds + 192));
The lambda expression returns a Functor<double>. Had you called Select with this lambda expression, the result would have been a nested functor. SelectMany, however, flattens while it maps (it flatMaps). (This example is rather inane, since it would be simpler to use Select and omit wrapping the output of the lambda in the functor. The later articles in this series will show some more compelling examples.)
If you already have Flatten (or Join) you can always implement SelectMany like this. Usually, however, languages use monadic bind (e.g. SelectMany) as the foundation. Both C#, Haskell, and F# do that. In that case, it's also possible to go the other way and implement Flatten with SelectMany. You'll see examples of that in the subsequent articles.
Syntactic sugar #
Several languages understand monads well enough to provide some degree of syntactic sugar. While you can always use SelectMany in C# by simply calling the method, there are situations where that becomes awkward. The same is true with bind functions in F# and >>= in Haskell.
In C# you can use query syntax:
Functor<DateTime> fdt = Functor.Return(new DateTime(2001, 8, 3)); Functor<TimeSpan> fts = Functor.Return(TimeSpan.FromDays(4)); Functor<DateTime> dest = from dt in fdt from ts in fts select dt - ts;
In order to support more than a single from expression, however, you must supply a special SelectMany overload, or the code doesn't compile:
public static Functor<TResult> SelectMany<T, U, TResult>( this Functor<T> source, Func<T, Functor<U>> k, Func<T, U, TResult> s) { return source.SelectMany(x => k(x).Select(y => s(x, y))); }
This is an odd quirk of C# that I've yet to encounter in other languages, and I consider it ceremony that I have to perform to satiate the C# compiler. It's not part of the concept of what a monad is. As far as I can tell, you can always implement it like shown here.
Haskell's syntactic sugar is called do notation and works for all monads:
example :: (Monad m, Num a) => m a -> m a -> m a example fdt fts = do dt <- fdt ts <- fts return $ dt - ts
In F#, computation expressions drive syntactic sugar, but still based (among other things) on the concept of a monad:
let example (fdt : Monad<DateTime>) (fts : Monad<TimeSpan>) = monad { let! dt = fdt let! ts = fts return dt - ts }
Here, we again have to pretend that a Monad<'a> type exists, with a companion monad computation expression.
Return #
The ability to flatten nested functors is the essence of what a monad is. There are, however, also some formal requirements. As is the case with functors, there are laws that a monad should obey. I'll dedicate a separate article for those, so we'll skip them for now.
Another requirement is that in addition to SelectMany/bind/flatMap/>>= a monad must also provide a method to 'elevate' a value to the monad. This function is usually called return. It should have a type like this:
public static Functor<T> Return<T>(T x)
You can see it in use in the above code snippet, and with the relevant parts repeated here:
Functor<DateTime> fdt = Functor.Return(new DateTime(2001, 8, 3)); Functor<TimeSpan> fts = Functor.Return(TimeSpan.FromDays(4));
This code example lifts the value DateTime(2001, 8, 3) to a Functor<DateTime> value, and the value TimeSpan.FromDays(4) to a Functor<TimeSpan> value.
Usually, in a language like C# a concrete monad type may either afford a constructor or factory method for this purpose. You'll see examples in the articles that give specific monad examples.
Conclusion #
A monad is a functor you can flatten. That's the simplest way I can put it.
In this article you learned what flattening means. You also learned that a monad must obey some laws and have a return function. The essence, however, is flattening. The laws just ensure that the flattening is well-behaved.
It may not yet be clear to you why some functors would need flattening in the first place, but subsequent articles will show examples.
The word monad has its own mystique in software development culture. If you've ever encountered some abstruse nomenclature about monads, then try to forget about it. The concept is really not hard to grasp, and it usually clicks once you've seen enough examples, and perhaps done some exercises.
Next: Kleisli composition.
Comments
Quoting image in words:
- Every Monad is an applicative functor
- Every applicative functor is a functor
- Every functor is a generic type
As your aricle about Monomorphic functors shows, not every functor is a generic type. However, it is true that every applicative functor is a generic (or polymorphic) functor.
True, the illustration is a simplification.
I guess you might know that already but the reason for the strange SelectMany ceremonial version is compiler performance. The complicated form is needed so that the overload resolution does not take exponential amount of time. See a 2013 article by Eric Lippert covering this.
Petr, thank you for writing. I remember reading about it before, but it's good to have a proper source.
If I understand the article correctly, the problem seems to originate from overload resolution. This would, at least, explain why neither F# nor Haskell needs that extra overload. I wonder if a language like Java would have a similar problem, but I don't think that Java has syntactic sugar for monads.
It still seems a little strange that the C# compiler requires the presence of that overload. Eric Lippert seems to strongly imply that it's always possible to derive that extra overload from any monad's fundamental functions (as is also my conjecture). If this is so, the C# compiler should be able to do that work by itself. Monads that wish to supply a more efficient implement (e.g. IEnumerable<T>) could still do so: The C# compiler could look for the overload and use it if it finds it, and still fall back to the default implementation if none is available.
But I suppose that since the query syntax feature only really exists to support IEnumerable<T> this degree of sophistication wasn't warranted.
Contravariant Dependency Injection
How to use a DI Container in FP... or not.
This article is an instalment in an article series about contravariant functors. It assumes that you've read the introduction, and a few of the examples.
People sometimes ask me how to do Dependency Injection (DI) in Functional Programming (FP). The short answer is that you don't, because dependencies make functions impure. If you're having the discussion on Twitter, you may get some drive-by comments to the effect that DI is just a contravariant functor. (I've seen such interactions take place, but currently can't find the specific examples.)
What might people mean by that?
In this article, I'll explain. You'll also see how this doesn't address the underlying problem that DI makes everything impure. Ultimately, then, it doesn't really matter. It's still not functional.
Partial application as Dependency Injection #
As example code, let's revisit the code from the article Partial application is dependency injection. You may have an impure action like this:
// int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) -> Reservation // -> int option let tryAccept capacity readReservations createReservation reservation = let reservedSeats = readReservations reservation.Date |> List.sumBy (fun x -> x.Quantity) if reservedSeats + reservation.Quantity <= capacity then createReservation { reservation with IsAccepted = true } |> Some else None
The readReservations and createReservation 'functions' will in reality be impure actions that read from and write to a database. Since they are impure, the entire tryAccept action is impure. That's the result from that article.
In this example the 'dependencies' are pushed to the left. This enables you to partially apply the 'function' with the dependencies:
let sut = tryAccept capacity readReservations createReservation
This code example is from a unit test, which is the reason that I've named the partially applied 'function' sut. It has the type Reservation -> int option. Keep in mind that while it looks like a regular function, in practice it'll be an impure action.
You can invoke sut like another other function:
let actual = sut reservation
When you do this, tryAccept will execute, interact with the partially applied dependencies, and return a result.
Partial application is a standard practice in FP, and in itself it's useful. Using it for Dependency Injection, however, doesn't magically make DI functional. DI remains impure, which also means that the entire sut composition is impure.
Moving dependencies to the right #
Pushing dependencies to the left enables partial application. Dependencies are typically more long-lived than run-time values like reservation. Thus, partially applying the dependencies as shown above makes sense. If all dependencies are thread-safe, you can let an action like sut, above, have Singleton lifetime. In other words, just keep a single, stateless Reservation -> int option action around for the lifetime of the application, and pass it Reservation values as they arrive.
Moving dependencies to the right seems, then, counterproductive.
// Reservation -> int -> (DateTimeOffset -> Reservation list) -> (Reservation -> int) // -> int option let tryAccept reservation capacity readReservations createReservation = let reservedSeats = readReservations reservation.Date |> List.sumBy (fun x -> x.Quantity) if reservedSeats + reservation.Quantity <= capacity then createReservation { reservation with IsAccepted = true } |> Some else None
If you move the dependencies to the right, you can no longer partially apply them, so what would be the point of that?
As given above, it seems that you'll have to supply all arguments in one go:
let actual = tryAccept reservation capacity readReservations createReservation
If, on the other hand, you turn all the dependencies into a tuple, some new options arise:
// Reservation -> (int * (DateTimeOffset -> Reservation list) * (Reservation -> int)) // -> int option let tryAccept reservation (capacity, readReservations, createReservation) = let reservedSeats = readReservations reservation.Date |> List.sumBy (fun x -> x.Quantity) if reservedSeats + reservation.Quantity <= capacity then createReservation { reservation with IsAccepted = true } |> Some else None
I decided to count capacity as a dependency, since this is most likely a value that originates from a configuration setting somewhere. Thus, it'd tend to have a singleton lifetime equivalent to readReservations and createReservation.
It still seems that you have to supply all the arguments, though:
let actual = tryAccept reservation (capacity, readReservations, createReservation)
What's the point, then?
Reader #
You can view all functions as values of the Reader profunctor. This, then, is also true for tryAccept. It's an (impure) function that takes a Reservation as input, and returns a Reader value as output. The 'Reader environment' is a tuple of dependencies, and the output is int option.
First, add an explicit Reader module:
// 'a -> ('a -> 'b) -> 'b let run env rdr = rdr env // ('a -> 'b) -> ('c -> 'd) -> ('b -> 'c) -> 'a -> 'd let dimap f g rdr = fun env -> g (rdr (f env)) // ('a -> 'b) -> ('c -> 'a) -> 'c -> 'b let map g = dimap id g // ('a -> 'b) -> ('b -> 'c) -> 'a -> 'c let contraMap f = dimap f id
The run function is mostly there to make the Reader concept more explicit. The dimap implementation is what makes Reader a profunctor. You can use dimap to implement map and contraMap. In the following, we're not going to need map, but I still included it for good measure.
You can partially apply the last version of tryAccept with a reservation:
// sut : (int * (DateTimeOffset -> Reservation list) * (Reservation -> int)) -> int option let sut = tryAccept reservation
You can view the sut value as a Reader. The 'environment' is the tuple of dependencies, and the output is still int option. Since we can view a tuple as a type-safe DI Container, we've now introduced a DI Container to the 'function'. We can say that the action is a Reader of the DI Container.
You can run the action by supplying a container:
let container = (capacity, readReservations, createReservation) let sut = tryAccept reservation let actual = sut |> Reader.run container
This container, however, is specialised to fit tryAccept. What if other actions require other dependencies?
Contravariant mapping #
In a larger system, you're likely to have more than the three dependencies shown above. Other actions require other dependencies, and may not need capacity, readReservations, or createReservation.
To make the point, perhaps the container looks like this:
let container = (capacity, readReservations, createReservation, someOtherService, yetAnotherService)
If you try to run a partially applied Reader like sut with this action, your code doesn't compile. sut needs a triple of a specific type, but container is now a pentuple. Should you change tryAccept so that it takes the bigger pentuple as a parameter?
That would compile, but would be a leaky abstraction. It would also violate the Dependency Inversion Principle and the Interface Segregation Principle because tryAccept would require callers to supply a bigger argument than is needed.
Instead, you can contraMap the pentuple:
let container = (capacity, readReservations, createReservation, someOtherService, yetAnotherService) let sut = tryAccept reservation |> Reader.contraMap (fun (c, rr, cr, _, _) -> (c, rr, cr)) let actual = sut |> Reader.run container
This turns sut into a Reader of the pentuple, instead of a Reader of the triple. You can now run it with the pentuple container. tryAccept remains a Reader of the triple.
Conclusion #
Keep in mind that tryAccept remains impure. While this may look impressively functional, it really isn't. It doesn't address the original problem that composition of impure actions creates larger impure actions that don't fit in your head.
Why, then, make things more complicated than they have to be?
In FP, I'd look long and hard for a better alternative - one that obeys the functional architecture law. If, for various reasons, I was unable to produce a purely functional design, I'd prefer composing impure actions with partial application. It's simpler.
This article isn't an endorsement of using contravariant DI in FP. It's only meant as an explanation of a phrase like DI is just a contravariant functor.
Next: Profunctors.
Type-safe DI Containers are redundant
Just use Pure DI.
This article is part of a series called Type-safe DI composition. In the previous article, you saw how tuples are adequate DI Containers. In case it's not clear from the article that introduces the series, there's really no point to any of this. My motivation for writing the article is that readers sometimes ask me about topics such as DI Containers versus type safety, or DI Containers in functional programming. The goal of these articles is to make it painfully clear why I find such ideas moot.
Tuples as DI Containers #
In the previous article you saw how tuples make adequate DI Containers. Consider, however, this constructor:
private readonly (IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo) container; public CompositionRoot( (IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo) container) { this.container = container; }
One question, though: Why pass a tuple of three objects as a single argument? Wouldn't it be more idiomatic to use a normal argument list?
Argument list #
Just remove the brackets around the tuple argument and dissolve the elements into separate class fields:
private readonly IRestaurantDatabase rdb; private readonly IClock clock; private readonly IReservationsRepository repo; public CompositionRoot(IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo) { this.rdb = rdb; this.clock = clock; this.repo = repo; }
You no longer need to resolve services from a DI Container. You can simply use the class fields directly:
public object Create(ControllerContext context) { if (context is null) throw new ArgumentNullException(nameof(context)); var t = context.ActionDescriptor.ControllerTypeInfo; if (t == typeof(CalendarController)) return new CalendarController(rdb, repo); else if (t == typeof(HomeController)) return new HomeController(rdb); else if (t == typeof(ReservationsController)) return new ReservationsController(clock, rdb, repo); else if (t == typeof(RestaurantsController)) return new RestaurantsController(rdb); else if (t == typeof(ScheduleController)) return new ScheduleController( rdb, repo, AccessControlList.FromUser(context.HttpContext.User)); else throw new ArgumentException( $"Unexpected controller type: {t}.", nameof(context)); }
Instead of container.rdb, container.repo, and container.clock, you can simply access rdb, repo, and clock.
The registration phase (such as it now remains) also becomes simpler:
var rdb = CompositionRoot.CreateRestaurantDatabase(Configuration); var po = CompositionRoot.CreatePostOffice(Configuration, rdb); var clock = CompositionRoot.CreateClock(); var repo = CompositionRoot.CreateRepository(Configuration, po); var compositionRoot = new CompositionRoot(rdb, clock, repo); services.AddSingleton<IControllerActivator>(compositionRoot);
There's no longer any remnant of a DI Container. This is Pure DI.
Conclusion #
Type-safe DI Containers are redundant. The simplest way to compose dependencies in a type-safe fashion is to write normal code, i.e. Pure DI.
What about 'normal' DI Containers, though? These aren't type-safe, but may have their uses. They represent a trade-off. For sufficiently complicated code bases, they may offer some benefits.
I typically don't consider the trade-off worthwhile. The keywords in the above paragraph are 'sufficiently complicated'. Instead of writing complicated code, I favour simplicity: code that fits in my head.
A type-safe DI Container as a tuple
Tuples are DI Containers. With example code in C#.
This article is part of a series called Type-safe DI composition. In the previous article, you saw a C# example of a type-safe DI Container as a functor. In case it's not clear from the article that introduces the series, there's really no point to any of this. My motivation for writing the article is that readers sometimes ask me about topics such as DI Containers versus type safety, or DI Containers in functional programming. The goal of these articles is to make it painfully clear why I find such ideas moot.
The previous article demonstrated how you can view a type-safe DI Container as a functor. The payload is a registry of services. You could introduce a specialised Parameter Object with each service given a name, but really, since a DI container is little more than a dictionary keyed by type, if you give each element of a tuple a unique type, then a tuple of services is all you need.
Identity #
In the previous article, I asked the question: Does Container<T> and its Select method form a lawful functor? In other words, does it obey the functor laws?
In the article, I just left the question dangling, so you might wonder if there's something fishy going on. In a sense, there is.
The Container functor is simply the Identity functor in disguise. Just imagine renaming Container<T> to Identity<T> and this should be clear. Since the Identity functor is lawful, the Container functor is also lawful.
On the other hand, the Identity functor is redundant. It doesn't offer any additional capabilities over its payload. Anything you can do with the Identity functor's payload, you can do directly to the payload. An even stronger statement is that the Identity functor is isomorphic to its underlying payload. This is true also for Container<T>, which is isomorphic to T. This is clear from the definition of the class:
public sealed class Container<T> { public Container(T item) { Item = item; } public T Item { get; } // More members to follow...
You can convert any T to a Container<T> by calling the constructor, and you can convert any Container<T> to a T value by reading the Item property.
Then why have the Container at all?
Tuple as a DI Container #
In the previous article, we left off with a container defined as Container<(IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo)>. It follows that the type of the Container's Item property is (IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo) - a tuple with three elements.
This code example makes use of C# tuple types, which enables you to give each element in the tuple a name. For the tuple in question, the first element is called rdb, the next element clock, and the third repo. This makes the code that accesses these elements more readable, but is structurally unimportant. If you work in a language without this tuple feature, it doesn't change the conclusion in this article series.
Instead of relying on Container<(IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo)>, the CompositionRoot class can rely on the unwrapped tuple:
private readonly (IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo) container; public CompositionRoot( (IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo) container) { this.container = container; }
Its Create method directly accesses the tuple elements to create Controllers:
public object Create(ControllerContext context) { if (context is null) throw new ArgumentNullException(nameof(context)); var t = context.ActionDescriptor.ControllerTypeInfo; if (t == typeof(CalendarController)) return new CalendarController( container.rdb, container.repo); else if (t == typeof(HomeController)) return new HomeController(container.rdb); else if (t == typeof(ReservationsController)) return new ReservationsController( container.clock, container.rdb, container.repo); else if (t == typeof(RestaurantsController)) return new RestaurantsController(container.rdb); else if (t == typeof(ScheduleController)) return new ScheduleController( container.rdb, container.repo, AccessControlList.FromUser(context.HttpContext.User)); else throw new ArgumentException( $"Unexpected controller type: {t}.", nameof(context)); }
Notice that instead of container.Item.rdb, container.Item.repo, and container.Item.clock, there's no redundant Item property. The Create method can directly access container.rdb, container.repo, and container.clock.
Registration #
Not only did it become easier to resolve services from the Container (i.e. the tuple) - registering services is also simpler:
var rdb = CompositionRoot.CreateRestaurantDatabase(Configuration); var po = CompositionRoot.CreatePostOffice(Configuration, rdb); var clock = CompositionRoot.CreateClock(); var repo = CompositionRoot.CreateRepository(Configuration, po); var container = (rdb, clock, repo); var compositionRoot = new CompositionRoot(container); services.AddSingleton<IControllerActivator>(compositionRoot);
Just create the services and put them in a tuple of the desired shape. No query syntax or other compiler tricks are required. Just write normal code.
Conclusion #
The Container<T> class is just the Identity functor in disguise. It's redundant, so you can delete it and instead use a tuple, a record type, or a Parameter Object as your service registry.
Are we done now, or can we simplify things even further? Read on.
Can one flatten a statically typed list?
What would be the type of a heterogeneously nested list?
Once again, I (inadvertently) managed to start a discussion on Twitter about static versus dynamic typing. I've touched on the topic before, but my agenda is not to fan any flames - quite the contrary. I'm trying (nay, struggling) to understand the other side of the debate.
This post isn't really about that, though, but in one of the threads spawned by my original tweet, Tom Johnson wrote:
"One of my favourite examples:
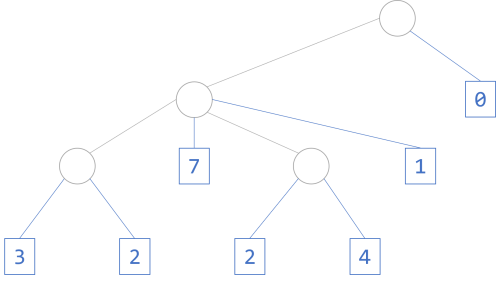
"What's the type of [[[3, 2], 7, [2, 4], 1], 0]?
"What's the type of flatten, which takes that value and yields [3, 2, 7, 2, 4, 1, 0]?"
The type, it turns out, is straightforward.
I'd like to be explicit about my agenda when writing this article. I'm not doing this to prove Tom Johnson wrong. In fact, I get the sense that he already knows the answer. Rather, I found it an interesting little exercise.
Syntax #
First, we need to get one thing out of the way. In many languages, [[[3, 2], 7, [2, 4], 1], 0] isn't valid syntax. Even as a 'normal' list, syntax like [3, 2, 7, 2, 4, 1, 0] wouldn't be valid syntax in some languages.
In Haskell [3, 2, 7, 2, 4, 1, 0] would be valid, but it wouldn't be valid syntax in C#. And while it'd be valid syntax in F#, it wouldn't mean what it means in Haskell. The F# equivalent would be [3; 2; 7; 2; 4; 1; 0].
The point is that that I don't consider myself bound by the specific syntax [[[3, 2], 7, [2, 4], 1], 0]. I'm going to answer the question using Haskell, and in Haskell, that code doesn't parse.
Instead, I'll use a data structure that represents the same data, but in a more verbose manner.
Tree #
In one of the Twitter threads, Alexis King already gave the answer:
"`flatten` is perfectly possible in Haskell, you just have to write a rose tree datatype, not use `[a]`."
The standard Tree a in Data.Tree, however, doesn't seem to quite fit. Instead, we can use a rose tree. As Meertens wrote:
"We consider trees whose internal nodes may fork into an arbitrary (natural) number of sub-trees. (If such a node has zero descendants, we still consider it internal.) Each external node carries a data item. No further information is stored in the tree; in particular, internal nodes are unlabelled."
With unlabelled nodes, we might draw Tom Johnson's 'list' like this:
I'll use the Tree data type introduced in the article Picture archivist in Haskell:
data Tree a b = Node a [Tree a b] | Leaf b deriving (Eq, Show, Read)
If you would, you could define a type alias that has unlabelled internal nodes:
type MeertensTree = Tree ()
I'm not really going to bother doing that, though. I'm just going to create a Tree () b value.
Here we go:
> l = Node () [Node () [Node () [Leaf 3, Leaf 2], Leaf 7, Node () [Leaf 2, Leaf 4], Leaf 1], Leaf 0] > :t l l :: Num b => Tree () b
You could probably come up with a more succinct syntax to create trees like this in code, but I'm assuming that in 'reality', if you have the need to flatten nested lists, it'll be a values that arrive at the boundary of the application...
Flattening #
Can you flatten the 'list' l?
Yes, no problem. The Tree a b data type is an instance of various type classes, among these Foldable:
instance Foldable (Tree a) where foldMap = bifoldMap mempty
You can see the full definition of bifoldMap and its dependencies in the article that introduces the type.
One of the functions available via Foldable is toList, which is just what you need:
> toList l [3,2,7,2,4,1,0]
This is the result required by Tom Johnson.
Summary #
In short, the answer to the question: "What's the type of [[[3, 2], 7, [2, 4], 1], 0]?" is: Num b => Tree () b, an example of which might be Tree () Integer. You could also call it MeertensTree Integer.
Likewise, the type of the requested flatten function is toList :: Foldable t => t a -> [a].
Comments
He appears to be using JavaScript and the solution is trivial in TypeScript, so he must not have looked too hard before claiming that statically typed languages cannot handle this scenario. He also kept moving the goalposts (It needs to use list syntax! It needs to support heterogeneous lists!), but even the most naïve attempt in TypeScript handles those as well.
type Nested<T> = (Nested<T> | T)[];
const flatten = <T>(val: Nested<T>): T[] =>
val.reduce(
(r: T[], v) => [...r, ...(Array.isArray(v) ? flatten(v) : [v])],
[]
);
const nested = [[[3, 2], 7, [2, 4], 1], 0];
const result = flatten(nested);
console.log(result); // [3, 2, 7, 2, 4, 1, 0]
const silly: Nested<number | string | { name: string }> = [
[[3, 2], 1],
"cheese",
{ name: "Fred" },
];
const sillyResult = flatten(silly);
console.log(sillyResult); // [3, 2, 1, "cheese", {"name": "Fred"}]
TypeScript types can also maintain the order of the types of elements in the flattened list. How to flatten a tuple type in TypeScript? gives a solution capable of handling that, though it is certainly more complex than the version above.
A type-safe DI Container as a functor
Decoupling the registry of services from the container. An ongoing C# example.
This article is part of a series called Type-safe DI composition. In the previous article, you saw a C# example of a type-safe, nested DI Container. In case it's not clear from the article that introduces the series, there's really no point to any of this. My motivation for writing the article is that readers sometimes ask me about topics such as DI Containers versus type safety, or DI Containers in functional programming. The goal of these articles is to make it painfully clear why I find such ideas moot.
In the previous article, you saw how you can use container nesting to implement a type-safe container of arbitrary arity. You only need these generic containers:
public sealed class Container public sealed class Container<T1> public sealed class Container<T1, T2>
You can achieve arities higher than two by nesting containers. For example, you can register three services by nesting one container inside another: Container<T1, Container<T2, T3>>. Higher arities require more nesting. See the previous article for an example with five services.
Decoupling the container from the registry #
How did I get the idea of nesting the containers?
It started as I was examining the constructor of the CompositionRoot class:
private readonly Container<IConfiguration, Container<Container<Container<IRestaurantDatabase, IPostOffice>, IClock>, IReservationsRepository>> container; public CompositionRoot(Container<IConfiguration, Container<Container<Container<IRestaurantDatabase, IPostOffice>, IClock>, IReservationsRepository>> container) { this.container = container; }
Those are, indeed, wide lines of code. No 80x24 box here. If you ignore all the container nesting, you can tell that the container contains five services:
IConfigurationIRestaurantDatabaseIPostOfficeIClockIReservationsRepository
CompositionRoot:
IRestaurantDatabaseIClockIReservationsRepository
IConfiguration and IPostOffice services are only present because they were required to create some of the other services. CompositionRoot never directly uses these two services. In other words, there's a leaky abstraction somewhere.
It'd be more in spirit with the Dependency Inversion Principle (DIP) and the Interface Segregation Principle (ISP) if the constructor required only the services it needs.
On the other hand, it's easiest to create the container from its constituent elements if you can pass already-registered services along when registering other services:
var container = Container.Empty .Register(Configuration) .Register(CompositionRoot.CreateRestaurantDatabase) .Register(CompositionRoot.CreatePostOffice) .Register(CompositionRoot.CreateClock()) .Register((conf, cont) => CompositionRoot.CreateRepository(conf, cont.Item1.Item2)); var compositionRoot = new CompositionRoot(container); services.AddSingleton<IControllerActivator>(compositionRoot);
I realised that the container needed a way to remove services from the public API. And it hit me that it'd be easier if I separated the container from its registry of services. If I did that, I could define a single generic Container<T> and even make it a functor. The payload could be a custom Parameter Object, but could also just be a tuple of services.
From Thinking with Types I knew that you can reduce all algebraic data types to canonical representations of Eithers and tuples.
A triple, for example, can be modelled as a Tuple<T1, Tuple<T2, T3>> or Tuple<Tuple<T1, T2>, T3>, a quadruple as e.g. Tuple<Tuple<T1, T2>, Tuple<T3, T4>>, etcetera.
Connecting those dots, I also realised that as an intermediary step I could nest the containers. It's really unnecessary, though, so let's proceed to simplify the code.
A Container functor #
Instead of a Container<T1, T2> in addition to a Container<T1>, you only need the single-arity container:
public sealed class Container<T> { public Container(T item) { Item = item; } public T Item { get; } // More members to follow...
Apart from overriding Equals and GetHashCode, the only member is Select:
public Container<TResult> Select<TResult>(Func<T, TResult> selector) { if (selector is null) throw new ArgumentNullException(nameof(selector)); return new Container<TResult>(selector(Item)); }
This is a straightforward Select implementation, making Container<T> a functor.
Usage #
You can use the Select method to incrementally build the desired container:
var container = Container.Empty.Register(Configuration) .Select(conf => (conf, rdb: CompositionRoot.CreateRestaurantDatabase(conf))) .Select(t => (t.conf, t.rdb, po: CompositionRoot.CreatePostOffice(t.conf, t.rdb))) .Select(t => (t.conf, t.rdb, t.po, clock: CompositionRoot.CreateClock())) .Select(t => (t.conf, t.rdb, t.po, t.clock, repo: CompositionRoot.CreateRepository(t.conf, t.po))); var compositionRoot = new CompositionRoot(container); services.AddSingleton<IControllerActivator>(compositionRoot);
The syntax is awkward, since you need to pass a tuple along to the next step, in which you need to access each of the tuple's elements, only to create a bigger tuple, and so on.
While it does get the job done, we can do better.
Query syntax #
Instead of using method-call syntax to chain all these service registrations together, you can take advantage of C#'s query syntax which lights up for any functor:
var container = from conf in Container.Empty.Register(Configuration) let rdb = CompositionRoot.CreateRestaurantDatabase(conf) let po = CompositionRoot.CreatePostOffice(conf, rdb) let clock = CompositionRoot.CreateClock() let repo = CompositionRoot.CreateRepository(conf, po) select (conf, rdb, po, clock, repo); var compositionRoot = new CompositionRoot(container); services.AddSingleton<IControllerActivator>(compositionRoot);
In both cases, the container object has the type Container<(IConfiguration conf, IRestaurantDatabase rdb, IPostOffice po, IClock clock, IReservationsRepository repo)>, which is still quite the mouthful. Now, however, we can do something about it.
DIP and ISP applied #
The CompositionRoot class only needs three services, so its constructor should ask for those, and no more:
private readonly Container<(IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo)> container; public CompositionRoot( Container<(IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo)> container) { this.container = container; }
With that injected container it can implement Create like this:
public object Create(ControllerContext context) { if (context is null) throw new ArgumentNullException(nameof(context)); var t = context.ActionDescriptor.ControllerTypeInfo; if (t == typeof(CalendarController)) return new CalendarController( container.Item.rdb, container.Item.repo); else if (t == typeof(HomeController)) return new HomeController(container.Item.rdb); else if (t == typeof(ReservationsController)) return new ReservationsController( container.Item.clock, container.Item.rdb, container.Item.repo); else if (t == typeof(RestaurantsController)) return new RestaurantsController(container.Item.rdb); else if (t == typeof(ScheduleController)) return new ScheduleController( container.Item.rdb, container.Item.repo, AccessControlList.FromUser(context.HttpContext.User)); else throw new ArgumentException( $"Unexpected controller type: {t}.", nameof(context)); }
That's more readable, although the intermediary Item object doesn't seem to do much work...
You can create a container with the desired type like this:
Container<(IRestaurantDatabase rdb, IClock clock, IReservationsRepository repo)> container = from conf in Container.Empty.Register(Configuration) let rdb = CompositionRoot.CreateRestaurantDatabase(conf) let po = CompositionRoot.CreatePostOffice(conf, rdb) let clock = CompositionRoot.CreateClock() let repo = CompositionRoot.CreateRepository(conf, po) select (rdb, clock, repo); var compositionRoot = new CompositionRoot(container); services.AddSingleton<IControllerActivator>(compositionRoot);
Notice that the only difference compared to earlier is that the select expression only involves the three required services: rdb, clock, and repo.
Conclusion #
This seems cleaner than before, but perhaps you're left with a nagging doubt: Why is the Container<T> class even required? What value does its Item property provide?
And perhaps another question is also in order: Does the Select method shown even define a lawful functor?
Read on.
A conditional sandwich example
An F# example of reducing a workflow to an impureim sandwich.
The most common reaction to the impureim sandwich architecture (also known as functional core, imperative shell) is one of incredulity. How does this way of organising code generalise to arbitrary complexity?
The short answer is that it doesn't. Given sufficient complexity, you may not be able to 1. gather all data with impure queries, 2. call a pure function, and 3. apply the return value via impure actions. The question is: How much complexity is required before you have to give up on the impureim sandwich?

There's probably a fuzzy transition zone where the sandwich may still apply, but where it begins to be questionable whether it's beneficial. In my experience, this transition seems to lie further to the right than most people think.
Once you have to give up on the impureim sandwich, in functional programming you may resort to using free monads. In object-oriented programming, you may use Dependency Injection. Depending on language and paradigm, still more options may be available.
My experience is mostly with web-based systems, but in that context, I find that a surprisingly large proportion of problems can be rephrased and organised in such a way that the impureim sandwich architecture applies. Actually, I surmise that most problems can be addressed in that way.
I am, however, often looking for good examples. As I wrote in a comment to Dependency rejection:
"I'd welcome a simplified, but still concrete example where the impure/pure/impure sandwich described here isn't going to be possible."
Such examples are, unfortunately, rare. While real production code may seem like an endless supply of examples, production code often contains irrelevant details that obscure the essence of the case. Additionally, production code is often proprietary, so I can't share it.
In 2019 Christer van der Meeren kindly supplied an example problem that I could refactor. Since then, there's been a dearth of more examples. Until now.
I recently ran into another fine example of a decision flow that at first glance seemed a poor fit for the functional core, imperative shell architecture. What follows is, actually, production code, here reproduced with the kind permission of Criipto.
Create a user if it doesn't exist #
As I've previously touched on, I'm helping Criipto integrate with the Fusebit API. This API has a user model where you can create users in the Fusebit services. Once you've created a user, a client can log on as that user and access the resources available to her, him, or it. There's an underlying security model that controls all of that.
Criipto's users may not all be provisioned as users in the Fusebit API. If they need to use the Fusebit system, we'll provision them just in time. On the other hand, there's no reason to create the user if it already exists.
But it gets more complicated than that. To fit our requirements, the user must have an associated issuer. This is another Fusebit resource that we may have to provision if it doesn't already exist.
The desired logic may be easier to follow if visualised as a flowchart.
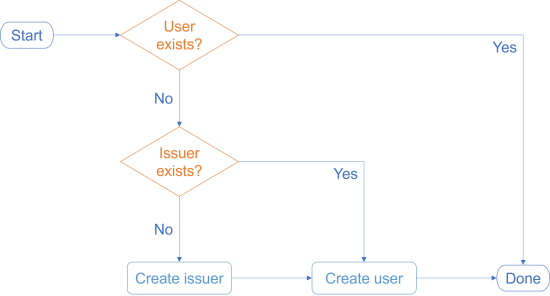
The user must have an issuer, but an appropriate issuer may already exist. If it doesn't, we must create the issuer before we create the user.
At first blush this seems like a workflow that doesn't fit the impureim sandwich architecture. After all, you should only check for the existence of the issuer if you find that the user doesn't exist. There's a decision between the first and second impure query.
Can we resolve this problem and implement the functionality as an impureim sandwich?
Speculative prefetching #
When looking for ways to apply the functional core, imperative shell architecture, it often pays to take a step back and look at a slightly larger picture. Another way to put it is that you should think less procedurally, and more declaratively. A flowchart like the above is essentially procedural. It may prevent you from seeing other opportunities.
One of the reasons I like functional programming is that it forces me to think in a more declarative way. This helps me identify better abstractions than I might otherwise be able to think of.
The above flowchart is representative of the most common counterargument I hear: The impureim sandwich doesn't work if the code has to make a decision about a secondary query based on the result of an initial query. This is also what's at stake here. The result of the user exists query determines whether the program should query about the issuer.
The assumption is that since the user is supposed to have an issuer, if the user exists, the issuer must also exist.
Even so, would it hurt so much to query the Fusebit API up front about the issuer?
Perhaps you react to such a suggestion with distaste. After all, it seems wasteful. Why query a web service if you don't need the result? And what about performance?
Whether or not this is wasteful depends on what kind of waste you measure. If you measure bits transmitted over the network, then yes, you may see this measure increase.
It may not be as bad as you think, though. Perhaps the HTTP GET request you're about to make has a cacheable result. Perhaps the result is already waiting in your proxy server's RAM.
Neither the Fusebit HTTP API's user resources nor its issuer resources, however, come with cache headers, so this last argument doesn't apply here. I still included it above because it's worth taking into account.
Another typical performance consideration is that this kind of potentially redundant traffic will degrade performance. Perhaps. As usual, if that's a concern: measure.
Querying the API whether a user exists is independent of the query to check if an issuer exists. This means that you could perform the two queries in parallel. Depending on the total load on the system, the difference between one HTTP request and two concurrent requests may be negligible. (It could still impact overall system performance if the system is already running close to capacity, so this isn't always a good strategy. Often, however, it's not really an issue.)
A third consideration is the statistical distribution of pathways through the system. If you consider the flowchart above, it indicates a cyclomatic complexity of 3; there are three distinct pathways.
If, however, it turns out that in 95 percent of cases the user doesn't exist, you're going to have to perform the second query (for issuer) anyway, then the difference between prefetching and conditional querying is minimal.
While some would consider this 'cheating', when aiming for the impureim sandwich architecture, these are all relevant questions to ponder. It often turns out that you can fetch all the data before passing them to a pure function. It may entail 'wasting' some electrons on queries that turn out to be unnecessary, but it may still be worth doing.
There's another kind of waste worth considering. This is the waste in developer hours if you write code that's harder to maintain than it has to be. As I recently described in an article titled Favor real dependencies for unit testing, the more you use functional programming, the less test maintenance you'll have.
Keep in mind that the scenario in this article is a server-to-server interaction. How much would a bit of extra bandwidth cost, versus wasted programmer hours?
If you can substantially simplify the code at the cost of a few dollars of hardware or network infrastructure, it's often a good trade-off.
Referential integrity #
The above flowchart implies a more subtle assumption that turns out to not hold in practice. The assumption is that all users in the system have been created the same: that all users are associated with an issuer. Thus, according to this assumption, if the user exists, then so must the issuer.
This turns out to be a false assumption. The Fusebit HTTP API doesn't enforce referential integrity. You can create a user with an issuer that doesn't exist. When creating a user, you supply only the issuer ID (a string), but the API doesn't check that an issuer with that ID exists.
Thus, just because a user exists you can't be sure that its associated issuer exists. To be sure, you'd have to check.
But this means that you'll have to perform two queries after all. The angst from the previous section turns out to be irrelevant. The flowchart is wrong.
Instead, you have two independent, but potentially parallelisable, processes:
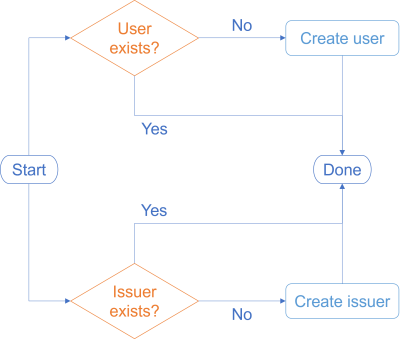
You can't always be that lucky when you consider how to make requirements fit the impureim sandwich mould, but this is beginning to look really promising. Each of these two processes is near-trivial.
Idempotence #
Really, what's actually required is an idempotent create action. As the RESTful Web Services Cookbook describes, all HTTP verbs except POST should be regarded as idempotent in a well-designed API. Alas, creating users and issuers are (naturally) done with POST requests, so these operations aren't naturally idempotent.
In functional programming you often decouple decisions from effects. In order to be able to do that here, I created this discriminated union:
type Idempotent<'a> = UpToDate | Update of 'a
This type is isomorphic to option, but I found it worthwhile to introduce a distinct type for this particular purpose. Usually, if a query returns, say UserData option, you'd interpret the Some case as indicating that the user exists, and the None case as indicating that the user doesn't exist.
Here, I wanted the 'populated' case to indicate that an Update action is required. If I'd used option, then I would have had to map the user-doesn't-exist case to a Some value, and the user-exists case to a None value. I though that this might be confusing to other programmers, since it'd go against the usual idiomatic use of the type.
That's the reason I created a custom type.
The UpToDate case indicates that the value exists and is up to date. The Update case is worded in the imperative to indicate that the value (of type 'a) should be updated.
Establish #
The purpose of this entire exercise is to establish that a user (and issuer) exists. It's okay if the user already exists, but if it doesn't, we should create it.
I mulled over the terminology and liked the verb establish, to the consternation of many Twitter users.
CreateUserIfNotExists is a crude name 🤢
How about EstablishUser instead?
"Establish" can both mean to "set up on a firm or permanent basis" and "show (something) to be true or certain by determining the facts". That seems to say the same in a more succinct way 👌
Just read the comments to see how divisive that little idea is. Still, I decided to define a function called establish to convert a Boolean and an 'a value to an Idempotent<'a> value.
Don't forget the purpose of this entire exercise. The benefit that the impureim sandwich architecture can bring is that it enables you to drain the impure parts of the sandwich of logic. Pure functions are intrinsically testable, so the more you define decisions and algorithms as pure functions, the more testable the code will be.
It's even better when you can make the testable functions generic, because reusable functions has the potential to reduce cognitive load. Once a reader learns and understands an abstraction, it stops being much of a cognitive load.
The functions to create and manipulate Idempotent<'a> values should be covered by automated tests. The behaviour is quite trivial, though, so to increase coverage we can write the tests as properties. The code base in question already uses FsCheck, so I just went with that:
[<Property(QuietOnSuccess = true)>] let ``Idempotent.establish returns UpToDate`` (x : int) = let actual = Idempotent.establish x true UpToDate =! actual [<Property(QuietOnSuccess = true)>] let ``Idempotent.establish returns Update`` (x : string) = let actual = Idempotent.establish x false Update x =! actual
These two properties also use Unquote for assertions. The =! operator means should equal, so you can read an expression like UpToDate =! actual as UpToDate should equal actual.
This describes the entire behaviour of the establish function, which is implemented this way:
// 'a -> bool -> Idempotent<'a> let establish x isUpToDate = if isUpToDate then UpToDate else Update x
About as trivial as it can be. Unsurprising code is good.
Fold #
The establish function affords a way to create Idempotent values. It'll also be useful with a function to get the value out of the container, so to speak. While you can always pattern match on an Idempotent value, that'd introduce decision logic into the code that does that.
The goal is to cover as much decision logic as possible by tests so that we can leave the overall impureim sandwich as an untested declarative composition - a Humble Object, if you will. It'd be appropriate to introduce a reusable function (covered by tests) that can fulfil that role.
We need the so-called case analysis of Idempotent<'a>. In other terminology, this is also known as the catamorphism. Since Idempotent<'a> is isomorphic to option (also known as Maybe), the catamorphism is also isomorphic to the Maybe catamorphism. While we expect no surprises, we can still cover the function with automated tests:
[<Property(QuietOnSuccess = true)>] let ``Idempotent.fold when up-to-date`` (expected : DateTimeOffset) = let actual = Idempotent.fold (fun _ -> DateTimeOffset.MinValue) expected UpToDate expected =! actual [<Property(QuietOnSuccess = true)>] let ``Idempotent.fold when update required`` (x : TimeSpan) = let f (ts : TimeSpan) = ts.TotalHours + float ts.Minutes let actual = Update x |> Idempotent.fold f 1.1 f x =! actual
The most common catamorphisms are idiomatically called fold in F#, so that's what I called it as well.
The first property states that when the Idempotent value is already UpToDate, fold simply returns the 'fallback value' (here called expected) and the function doesn't run.
When the Idempotent is an Update value, the function f runs over the contained value x.
The implementation hardly comes as a surprise:
// ('a -> 'b) -> 'b -> Idempotent<'a> -> 'b let fold f onUpToDate = function | UpToDate -> onUpToDate | Update x -> f x
Both establish and fold are general-purpose functions. I needed one more specialised function before I could compose a workflow to create a Fusebit user if it doesn't exist.
Checking whether an issuer exists #
As I've previously mentioned, I'd already developed a set of modules to interact with the Fusebit API. One of these was a function to read an issuer. This Issuer.get action returns a Task<Result<IssuerData, HttpResponseMessage>>.
The Result value will only be an Ok value if the issuer exists, but we can't conclude that any Error value indicates a missing resource. An Error may also indicate a genuine HTTP error.
A function to translate a Result<IssuerData, HttpResponseMessage> value to a Result<bool, HttpResponseMessage> by examining the HttpResponseMessage is just complex enough (cyclomatic complexity 3) to warrant unit test coverage. Here I just went with some parametrised tests rather than FsCheck properties.
The first test asserts that when the result is Ok it translates to Ok true:
[<Theory>] [<InlineData ("https://example.com", "DN", "https://example.net")>] [<InlineData ("https://example.org/id", "lga", "https://example.gov/jwks")>] [<InlineData ("https://example.com/id", null, "https://example.org/.jwks")>] let ``Issuer exists`` iid dn jwks = let issuer = { Id = Uri iid DisplayName = dn |> Option.ofObj PKA = JwksEndpoint (Uri jwks) } let result = Ok issuer let actual = Fusebit.issuerExists result Ok true =! actual
All tests here are structured according to the AAA formatting heuristic. This particular test may seem so obvious that you may wonder how there's actually any logic to test. Perhaps the next test throws a little more light on that question:
[<Fact>] let ``Issuer doesn't exist`` () = use resp = new HttpResponseMessage (HttpStatusCode.NotFound) let result = Error resp let actual = Fusebit.issuerExists result Ok false =! actual
How do we know that the requested issuer doesn't exist? It's not just any Error result that indicates that, but a particular 404 Not Found result. Notice that this particular Error result translates to an Ok result: Ok false.
All other kinds of Error results, on the other hand, should remain Error values:
[<Theory>] [<InlineData (HttpStatusCode.BadRequest)>] [<InlineData (HttpStatusCode.Unauthorized)>] [<InlineData (HttpStatusCode.Forbidden)>] [<InlineData (HttpStatusCode.InternalServerError)>] let ``Issuer error`` statusCode = use resp = new HttpResponseMessage (statusCode) let expected = Error resp let actual = Fusebit.issuerExists expected expected =! actual
All together, these tests indicate an implementation like this:
// Result<'a, HttpResponseMessage> -> Result<bool, HttpResponseMessage> let issuerExists = function | Ok _ -> Ok true | Error (resp : HttpResponseMessage) -> if resp.StatusCode = HttpStatusCode.NotFound then Ok false else Error resp
Once again, I've managed to write a function more generic than its name implies. This seems to happen to me a lot.
In this context, what matters more is that this is another pure function - which also explains why it was so easy to unit test.
Composition #
It turned out that I'd now managed to extract all complexity to pure, testable functions. What remained was composing them together.
First, a couple of private helper functions:
// Task<Result<'a, 'b>> -> Task<Result<unit, 'b>> let ignoreOk x = TaskResult.map (fun _ -> ()) x // ('a -> Task<Result<'b, 'c>>) -> Idempotent<'a> -> Task<Result<unit, 'c>> let whenMissing f = Idempotent.fold (f >> ignoreOk) (task { return Ok () })
These only exist to make the ensuing composition more readable. Since they both have a cyclomatic complexity of 1, I found that it was okay to skip unit testing.
The same is true for the final composition:
let! comp = taskResult { let (issuer, identity, user) = gatherData dto let! issuerExists = Issuer.get client issuer.Id |> Task.map Fusebit.issuerExists let! userExists = User.find client (IdentityCriterion identity) |> TaskResult.map (not << List.isEmpty) do! Idempotent.establish issuer issuerExists |> whenMissing (Issuer.create client) do! Idempotent.establish user userExists |> whenMissing (User.create client) }
The comp composition starts by gathering data from an incoming dto value. This code snippet is part of a slightly larger Controller Action that I'm not showing here. The rest of the surrounding method is irrelevant to the present example, since it only deals with translation of the input Data Transfer Object and from comp back to an IHttpActionResult object.
After a little pure hors d'œuvre the sandwich arrives with the first impure actions: Retrieving the issuerExists and userExists values from the Fusebit API. After that, the sandwich does fall apart a bit, I admit. Perhaps it's more like a piece of smørrebrød...
I could have written this composition with a more explicit sandwich structure, starting by exclusively calling Issuer.get and User.find. That would have been the first impure layer of the sandwich.
As the pure centre, I could then have composed a pure function from Fusebit.issuerExists, not << List.isEmpty and Idempotent.establish.
Finally, I could have completed the sandwich with the second impure layer that'd call whenMissing.
I admit that I didn't actually structure the code exactly like that. I mixed some of the pure functions (Fusebit.issuerExists and not << List.isEmpty) with the initial queries by adding them as continuations with Task.map and TaskResult.map. Likewise, I decided to immediately pipe the results of Idempotent.establish to whenMissing. My motivation was that this made the code more readable, since I wanted to highlight the symmetry of the two actions. That mattered more to me, as a writer, than highlighting any sandwich structure.
I'm not insisting I was right in making that choice. Perhaps I was; perhaps not. I'm only reporting what motivated me.
Could the code be further improved? I wouldn't be surprised, but at this time I felt that it was good enough to submit to a code review, which it survived.
One possible improvement, however, might be to parallelise the two actions, so that they could execute concurrently. I'm not sure it's worth the (small?) effort, though.
Conclusion #
I'm always keen on examples that challenge the notion of the impureim sandwich architecture. Usually, I find that by taking a slightly more holistic view of what has to happen, I can make most problems fit the pattern.
The most common counterargument is that subsequent impure queries may depend on decisions taken earlier. Thus, the argument goes, you can't gather all impure data up front.
I'm sure that such situations genuinely exist, but I also think that they are rarer than most people think. In most cases I've experienced, even when I initially think that I've encountered such a situation, after a bit of reflection I find that I can structure the code to fit the functional core, imperative shell architecture. Not only that, but the code becomes simpler in the process.
This happened in the example I've covered in this article. Initially, I though that ensuring that a Fusebit user exists would involve a process as illustrated in the first of the above flowcharts. Then, after thinking it over, I realised that defining a simple discriminated union would simplify matters and make the code testable.
I thought it was worthwhile sharing that journey of discovery with others.
Comments
Hello! I have a question about the compatibility of functional design with existing .NET Enterprise codebases, particularly those using Entity Framework Core.
I discovered functional design quite recently, so I'm a novice. Before finding your blog, I watched a podcast by another F# enthusiast, Scott Wlaschin, at NDC London: Moving IO to the edges of your app: Functional Core, Imperative Shell. At the 37:50 timestamp, he mentioned that the impureuim sandwich (or functional core, imperative shell) is a bad match for heavy ORMs like EF Core. I'm not entirely opposed to this idea, but it made me question: are heavy ORMs really incompatible, or are there workarounds? Is it possible to apply these functional approaches, at least partially, to large, existing projects, perhaps even legacy ones?
Thank you for your work!
Thank you for writing. The short answer is no.
But then, if you had asked if it's possible to apply object-oriented design (OOD) to the same projects, the answer would also be no.
Most existing large code bases that I have seen contain procedural spaghetti code. While they don't contain any functional programming (FP) code, neither do they apply OOD.
Questions like yours often carry the implied alternative that while FP doesn't work in the 'real world', object-oriented programming (OOP) does. There's little evidence to that claim. While you can make OOP work in large enterprise projects, it's rare. Most code bases written in C#, Java, C++, etc. are implicitly understood to be object-oriented, but most aren't. They are procedural.
This, however, doesn't address your specific question: Are ORMs incompatible with FP? No, they are compatible with FP to exactly the same degree that they are compatible with OOD: Not very much, but you can make it work if you encapsulate the ORM behind an anti-corruption layer. My article Do ORMs reduce the need for mapping? contains more details.
Nested type-safe DI Containers
How to address the arity problem with type-safe DI Container prototypes.
This article is part of a series called Type-safe DI composition. In the previous article, you saw a C# example of a type-safe DI Container. In case it's not clear from the article that introduces the series, there's really no point to any of this. My motivation for writing the article is that readers sometimes ask me about topics such as DI Containers versus type safety, or DI Containers in functional programming. The goal of these articles is to make it painfully clear why I find such ideas moot.
N+1 arity #
The previous article suggested a series of generic containers in order to support type-safe Dependency Injection (DI) composition. For example, to support five services, you need five generic containers:
public sealed class Container public sealed class Container<T1> public sealed class Container<T1, T2> public sealed class Container<T1, T2, T3> public sealed class Container<T1, T2, T3, T4> public sealed class Container<T1, T2, T3, T4, T5>
As the above listing suggests, there's also an (effectively redundant) empty, non-generic Container class. Thus, in order to support five services, you need 5 + 1 = 6 Container classes. In order to support ten services, you'll need eleven classes, and so on.
While these classes are all boilerplate and completely generic, you may still consider this a design flaw. If so, there's a workaround.
Nested containers #
The key to avoid the n + 1 arity problem is to nest the containers. First, we can delete Container<T1, T2, T3>, Container<T1, T2, T3, T4>, and Container<T1, T2, T3, T4, T5>, while leaving Container and Container<T1> alone.
Container<T1, T2> needs a few changes to its Register methods.
public Container<T1, Container<T2, T3>> Register<T3>(T3 item3) { return new Container<T1, Container<T2, T3>>( Item1, new Container<T2, T3>( Item2, item3)); }
Instead of returning a Container<T1, T2, T3>, this version of Register returns a Container<T1, Container<T2, T3>>. Notice how Item2 is a new container. A Container<T2, T3> is nested inside an outer container whose Item1 remains of the type T1, but whose Item2 is of the type Container<T2, T3>.
The other Register overload follows suit:
public Container<T1, Container<T2, T3>> Register<T3>(Func<T1, T2, T3> create) { if (create is null) throw new ArgumentNullException(nameof(create)); var item3 = create(Item1, Item2); return Register(item3); }
The only change to this method, compared to the previous article, is to the return type.
Usage #
Since the input parameter types didn't change, composition still looks much the same:
var container = Container.Empty .Register(Configuration) .Register(CompositionRoot.CreateRestaurantDatabase) .Register(CompositionRoot.CreatePostOffice) .Register(CompositionRoot.CreateClock()) .Register((conf, cont) => CompositionRoot.CreateRepository(conf, cont.Item1.Item2)); var compositionRoot = new CompositionRoot(container); services.AddSingleton<IControllerActivator>(compositionRoot);
Only the last Register call is different. Instead of a lambda expression taking four arguments ((c, _, po, __)), this one only takes two: (conf, cont). conf is an IConfiguration object, while cont is a nested container of the type Container<Container<IRestaurantDatabase, IPostOffice>, IClock>.
Recall that the CreateRepository method has this signature:
public static IReservationsRepository CreateRepository( IConfiguration configuration, IPostOffice postOffice)
In order to produce the required IPostOffice object, the lambda expression must first read Item1, which has the type Container<IRestaurantDatabase, IPostOffice>. It can then read that container's Item2 to get the IPostOffice.
Not particularly readable, but type-safe.
The entire container object passed into CompositionRoot has the type Container<IConfiguration, Container<Container<Container<IRestaurantDatabase, IPostOffice>, IClock>, IReservationsRepository>>.
Equivalently, the CompositionRoot's Create method has to train-wreck its way to each service:
public object Create(ControllerContext context) { if (context is null) throw new ArgumentNullException(nameof(context)); var t = context.ActionDescriptor.ControllerTypeInfo; if (t == typeof(CalendarController)) return new CalendarController( container.Item2.Item1.Item1.Item1, container.Item2.Item2); else if (t == typeof(HomeController)) return new HomeController(container.Item2.Item1.Item1.Item1); else if (t == typeof(ReservationsController)) return new ReservationsController( container.Item2.Item1.Item2, container.Item2.Item1.Item1.Item1, container.Item2.Item2); else if (t == typeof(RestaurantsController)) return new RestaurantsController(container.Item2.Item1.Item1.Item1); else if (t == typeof(ScheduleController)) return new ScheduleController( container.Item2.Item1.Item1.Item1, container.Item2.Item2, AccessControlList.FromUser(context.HttpContext.User)); else throw new ArgumentException( $"Unexpected controller type: {t}.", nameof(context)); }
Notice how most of the services depend on container.Item2.Item1.Item1.Item1. If you hover over that code in an IDE, you'll see that this is an IRestaurantDatabase service. Again, type-safe, but hardly readable.
Conclusion #
You can address the n + 1 arity problem by nesting generic containers inside each other. How did I think of this solution? And can we simplify things even more?
Read on.

Comments
I am confused by this paragraph. A monoid requries a binary operation (that is also closed), and Kleisli composition is (closed) binary operation.
As you said in the introductory article to this monad series, there are three pieces to a monad: a generic type
M<>, a function with typea -> M<a>(typically called "return"), and a function with signature(a -> M<b>) -> M<a> -> M<b>(sometimes called "bind"). Then(M<>, return, bind)is a monad if those three items satisfy the monad laws.I think the following is true. Let
M<>be a generic type, and letSbe the set of all functions with signaturea -> M<a>. Then(M<>, return, bind)is a monad if only only if(S, >=>, return)is a monoid.Tyson, thank you for writing. To address the elephant in the room first: A monad is a monoid (in the category of endofunctors), but as far as I can tell, you have to look more abstractly at it than allowed by the static type systems we normally employ.
Bartosz Milewski describes a nested functor as the tensor product of two monadic types:
M ⊗ M. The binary operation in question is thenM ⊗ M -> M, or join/flatten (from here on just join). In this very abstract view, monads are monoids. It does require an abstract view of functors as objects in a category. At that level of abstraction, so many details are lost that join looks like a binary operation.So, to be clear, if you want to look at a monad as a monoid, it's not the monadic bind function that's the binary operation; it's join. (That's another reason I prefer explaining monads in terms of join rather than leading with bind.)
When you zoom in on the details, however, join doesn't look like a regular binary operation:
m (m a) -> m a. A binary operation, on the other hand, should look like this:m a -> m a -> m a.The Kleisli composition operator unfortunately doesn't fix this. Let's look at the C# method signature, since it may offer a way out:
Notice that the types don't match:
action1has a type different fromaction2, which is again different from the return type. Thus, it's not a binary operation, because the elements don't belong to the same set.As Bartosz Milewski wrote, though, if we squint a little, we may make it work. C# allows us to 'squint' because of its object hierarchy:
I'm not sure how helpful that is, though, so I didn't want to get into these weeds in the above article itself. It's fine here in the comments, because I expect only very dedicated readers to consult them. This, thus, serves more like a footnote or appendix.
Thanks very much for you reply. It helped me to see where I was wrong.
(S, >=>, return)is not a monoid because>=>is not total overS, which is another condition the binary operation must satisfy, but I overlooked that. Furthremore, I meant to defineSas the set of all functions with signaturea -> M<b>. The same problem still exists though. The second code block in your comment has this same problem. There is not a natural choice for the implementation unless the types of the objects satisfy the constraints implied by the use of type parameters in the first code block in your comment. I will keep thinking about this.In the meantime, keep up the great work. I am loving your monad content.