ploeh blog danish software design
Shift left on x
A difficult task may be easier if done sooner.
You've probably seen a figure like this before:
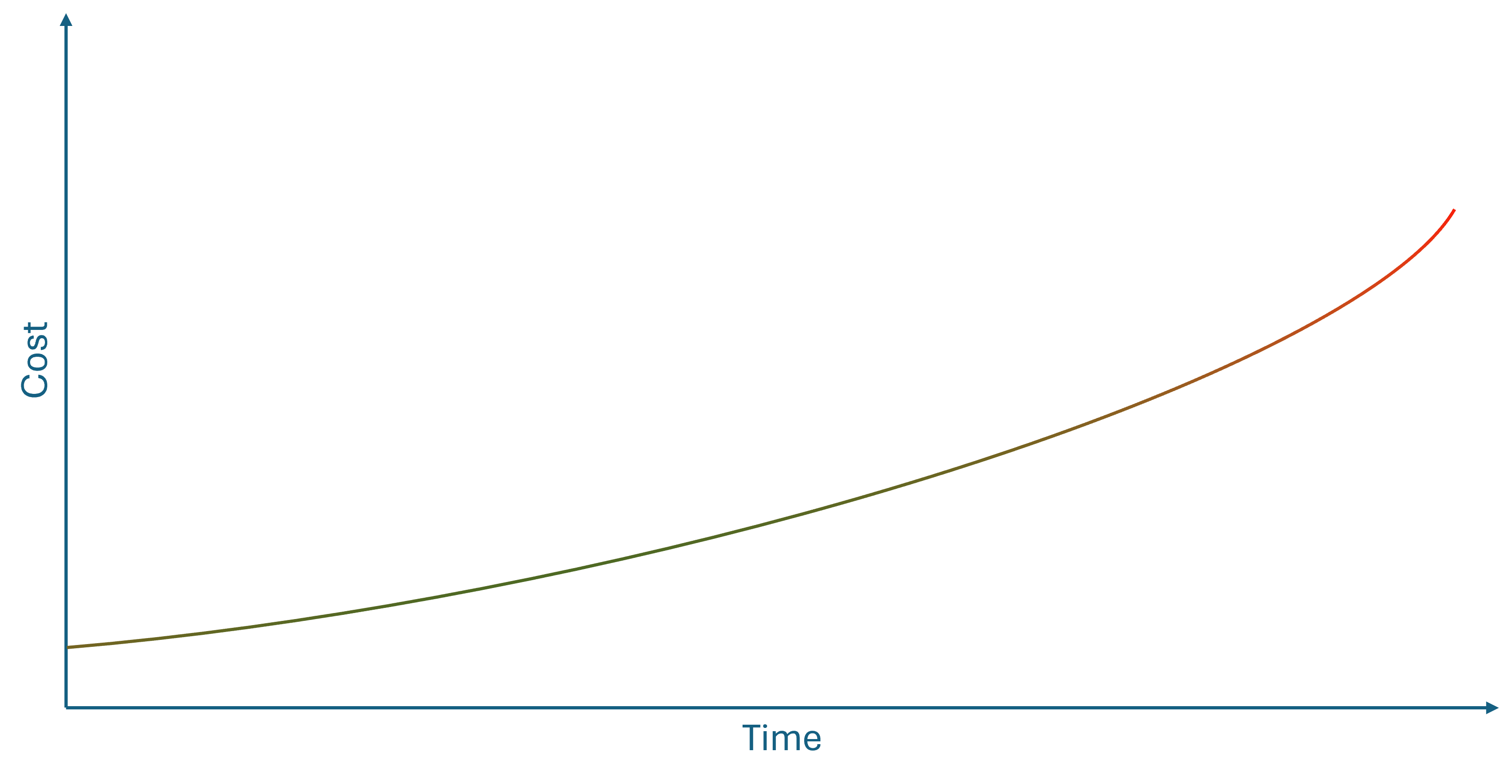
The point is that as time passes, the cost of doing something increases. This is often used to explain why test-driven development (TDD) or other agile methods are cost-effective alternatives to a waterfall process.
Last time I checked, however, there was scant scientific evidence for this curve.
Even so, it feels right. If you discover a bug while you write the code, it's much easier to fix it than if it's discovered weeks later.
Make security easier #
I was recently reminded of the above curve because a customer of mine was struggling with security; mostly authentication and authorization. They asked me if there was a software-engineering practice that could help them get a better handle on security. Since this is a customer who's otherwise quite knowledgeable about agile methods and software engineering, I was a little surprised that they hadn't heard the phrase shift left on security.
The idea fits with the above diagram. 'Shifting left' implies moving to the left on the time axis. In other words, do things sooner. Specifically related to security, the idea is to include security concerns early in every software development process.
There's little new in this. Writing Secure Code from 2004 describes how threat modelling is part of secure coding practices. This is something I've had in the back of my mind since reading the book. I also describe the technique and give an example in Code That Fits in Your Head.
If I know that a system I'm developing requires authentication, some of the first automated acceptance tests I write is one that successfully authenticates against the system, and one or more that fail to do so. Again, the code base that accompanies Code That Fits in Your Head has examples of this.
Since my customer's question reminded me of this practice, I began pondering the idea of 'shifting left'. Since it's both touted as a benefit of TDD and DevSecOps, an obvious pattern suggests itself.
Sufficient requirements #
It's been years since I last drew the above diagram. As I implied, one problem with it is that there seems to be little quantifiable evidence for that relationship. On the other hand, you've surely had the experience that some tasks become harder, the longer you wait. I'll list some example later.
While we may not have solid scientific evidence that a cost curve looks like above, it doesn't have to look like that to make shifting left worthwhile. All it takes, really, is that the relationship is non-decreasing, and increases at least once. It doesn't have to be polynomial or exponential; it may be linear or logarithmic. It may even be a non-decreasing step function, like this:
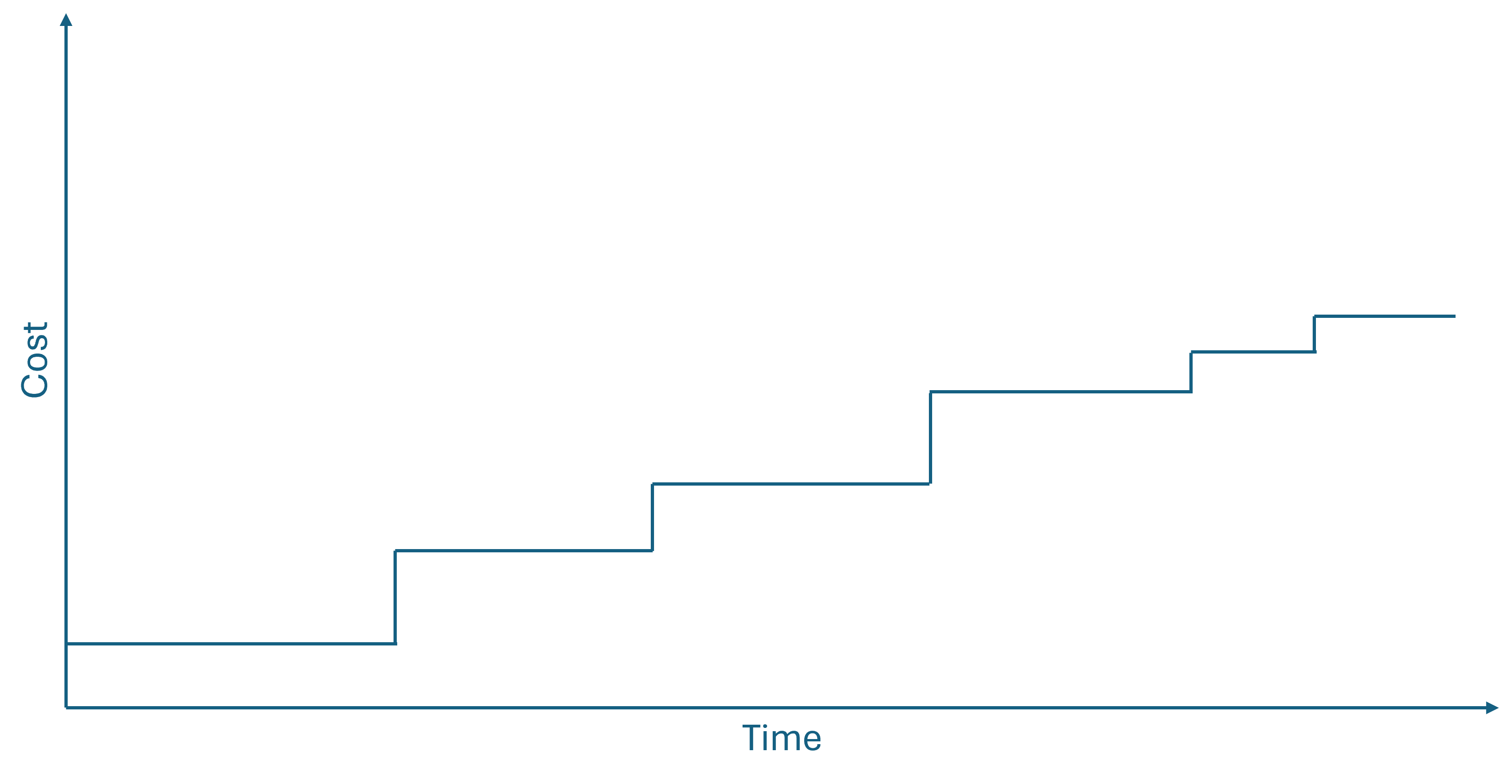
This, as far as I can tell, is a sufficient condition to warrant shifting left on an activity. If you have even anecdotal evidence that it may be more costly to postpone an activity, do it sooner. In practice, I don't think that you need to wait for solid scientific evidence before you do this.
While not quite the same, it's a notion similar to the old agile saw: If it hurts, do it more often. Instead, we may phrase it as: If it gets harder with time, do it sooner.
Examples #
You've already seen two examples: TDD and security. Are there other examples where tackling problems sooner may decrease cost? Certainly.
A few, I cover in Code That Fits in Your Head. The earlier you automate the build process, the easier it is. The earlier you treat all warnings as errors, the easier it is. This seems almost self-explanatory, particularly when it comes to treating warnings as errors. In a brand-new code base, you have no warnings. In that situation, treating warnings as errors is free. When, later, a compiler warning appears, your code doesn't compile, and you're forced to immediately deal with it. At that time, it tends to be much easier to fix the issue, because no other code depends on the code with the warning.
A similar situation applies to an automated build. At the beginning, an automated build is a simple batch file with one command. dotnet test -c Release, stack test, py -m pytest, and so on. Later, when you need to deal with databases, security, third-party components, etc. you enhance the automated build 'just in time'.
Once you have an automated build, deployment is a small step further. In the beginning, deploying an application is typically as easy as copying some program files (compiled code or source files, depending on language) to the machines on which it's going to run. An exception may be if the deployment target is some sort of app store, with a vetting process that prevents you from deploying a walking skeleton. If, on the other hand, your organization controls the deployment target, the sooner you deploy a hello-world application, the easier it is.
Yet another shift-left example is using static code analysis or linting, particularly when combined with treating warnings as errors. Linters are usually free, and as I describe in Code That Fits in Your Head, I've always found it irrational that teams don't use them. Not that I don't understand the mechanism, because if you only turn them on at a time when the code base has already accumulated thousands of linter issues, the sheer volume is overwhelming.
Closely related to this discussion is the lean development notion that bugs are stop-the-line issues. The correct number of known bugs in the code base is zero. The correct number of unhandled exceptions in production is zero. This sounds unattainable to most people, but is possible if you shift left on managing defects.
In short:
- Shift left on security
- Shift left on testing
- Shift left on treating warnings as errors
- Shift left on automated builds
- Shift left on deployment
- Shift left on linting
- Shift left on defect management
This list is hardly exhaustive.
Shift right #
While it increases your productivity to do some things sooner, it's not a universal rule. Some things become easier, the longer you wait. In terms of time-to-cost curves, this happens whenever the curve is decreasing, even if only step-wise.
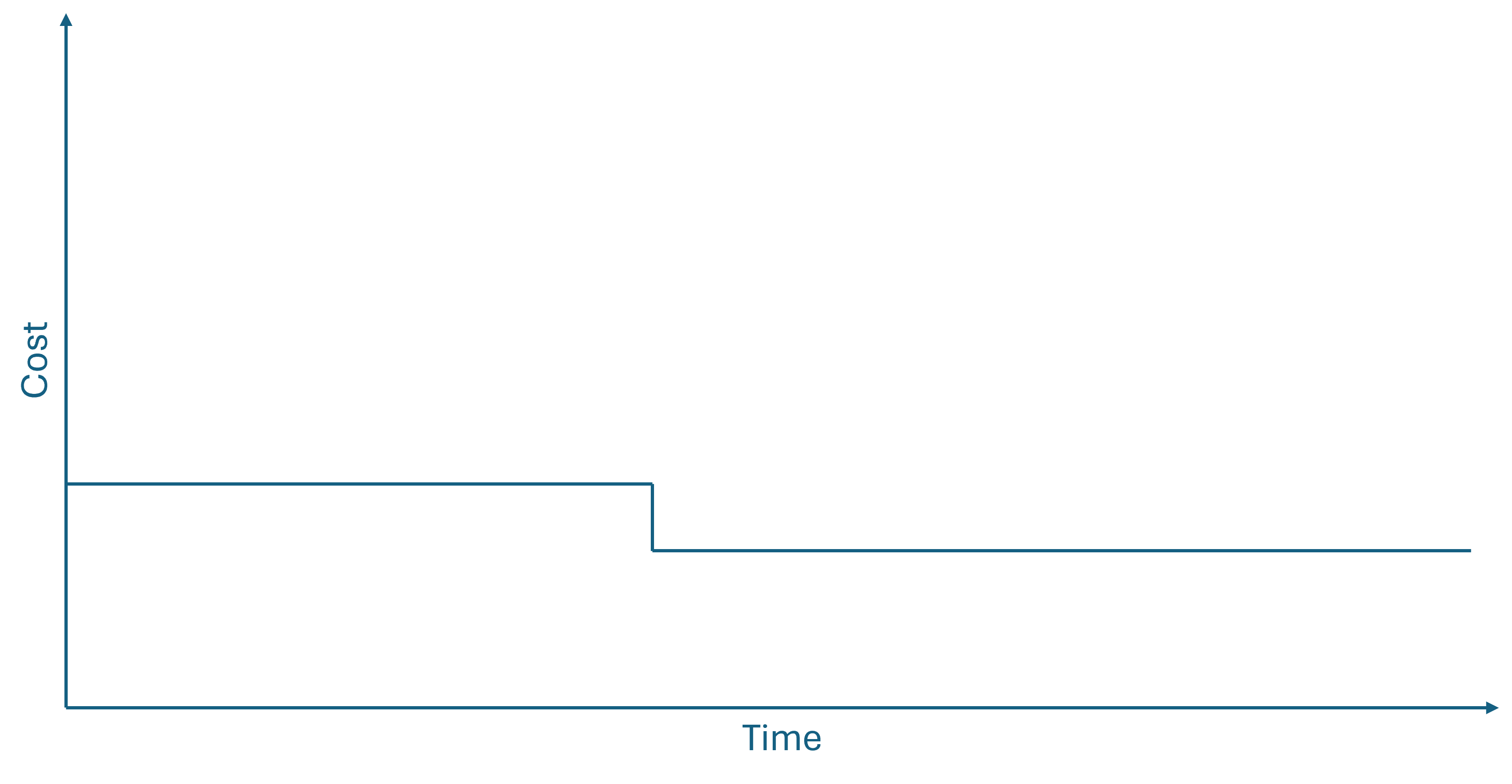
The danger of these figures is that they may give the impression of a deterministic process. That need not be the case, but if you have reason to believe that waiting until later may make solving a problem easier, consider waiting. The notion of waiting until the last responsible moment is central to lean or agile software development.
In a sense, you could view this is 'shifting right' on certain tasks. More than once I've experienced that if you wait long enough with a certain task, it becomes irrelevant. Not just easier to perform, but something that you don't need to do at all. What looked like a requirement early on turned out to be not at all what the customer or user wanted, after all.
When to do what #
How do you distinguish? How do you decide if shifting left or shifting right is more appropriate? In practice, it's rarely difficult. The shift-left list above contains the usual suspects. While the list may not be exhaustive, it's a well-known list of practices that countless teams have found easier to do sooner rather than later.
My own inclination would be to treat most other things as tasks that are better postponed. After all, you can't do everything as the first thing. Naturally, there has to be some sequencing of tasks.
Thinking about such decisions in terms of time-cost curves feels natural to me. I find it an easy framework to consider whether I should shift left or right on some activity.
Conclusion #
Some things are easier if you get started as soon as possible. Candidates include testing, deployment, security, and defect management. This is the case when there's a increasing relationship between time and cost. This relationship need not be a quantified function. Often, you can get by with a sense that 'if I do this now, it's going to be easy; if I wait, it's going to be harder.'
Conversely, some things are better postponed to the last responsible moment. This happens if the relation between time and cost is decreasing.
Perhaps we can simplify this analysis even further. Perhaps you don't even need to think of (step) functions. All you may need is to consider the partial order of tasks in terms of cost. Since I'm a visual thinker, however, increasing and decreasing functions come more naturally to me.
Composing pure Haskell assertions
With HUnit and QuickCheck examples.
A question had been in the back of my mind for a long time, but I always got caught up in something seemingly more important, so I didn't get around to investigate until recently. It's simply this:
How do you compose pure assertions in HUnit or QuickCheck?
Let me explain what I mean, and why this isn't quite as straightforward as it may sound.
Assertions as statements #
What do I mean by composing assertions? Really nothing more than wanting to verify more than a single outcome of a test.
If you're used to writing test assertions in imperative languages like C#, Java, Python, or JavaScript, you think nothing of it. Just write an assertion on one line, and the next assertion on the next line.
If you're writing impure Haskell, you can also do that.
"CLRS example" ~: do p :: IOArray Int Int <- newListArray (1, 10) [1, 5, 8, 9, 10, 17, 17, 20, 24, 30] (r, s) <- cutRod p 10 actualRevenue <- getElems r actualSizes <- getElems s let expectedRevenue = [0, 1, 5, 8, 10, 13, 17, 18, 22, 25, 30] let expectedSizes = [1, 2, 3, 2, 2, 6, 1, 2, 3, 10] expectedRevenue @=? actualRevenue expectedSizes @=? actualSizes
This example is an inlined HUnit test which tests the impure cutRod variation. The two final statements are assertions that use the @=? assertion operator. The value on the left side is the expected value, and to the right goes the actual value. This operator returns a type called Assertion, which turns out to be nothing but an alias for IO ().
In other words, those assertions are impure actions, and they work similarly to assertions in imperative languages. If the actual value passes the assertion, nothing happens and execution moves on to the assertion on the next line. If, on the other hand, the assertion fails, execution short-circuits, and an error is reported.
Imperative languages typically throw exceptions to achieve that behaviour. Even Unquote does this. Exactly how HUnit does it I don't know; I haven't looked under the hood.
You can do the same with Test.QuickCheck.Monadic:
testProperty "cutRod returns correct arrays" $ \ p -> monadicIO $ do let n = length p p' :: IOArray Int Int <- run $ newListArray (1, n) p (r, s) :: (IOArray Int Int, IOArray Int Int) <- run $ cutRod p' n actualRevenue <- run $ getElems r actualSizes <- run $ getElems s assertWith (length actualRevenue == n + 1) "Revenue length is incorrect" assertWith (length actualSizes == n) "Size length is incorrect" assertWith (all (\i -> 0 <= i && i <= n) actualSizes) "Sizes are not all in [1..n]"
Like the previous example, you can repeatedly call assertWith, since this action, too, is a statement that returns no value.
So far, so good.
Composing assertions #
What if, however, you want to write tests as pure functions?
Pure functions are composed from expressions, while statements aren't allowed (or, at least, ineffective, and subject to be optimized away by a compiler). In other words, the above strategy isn't going to work. If you want to write more than one assertion, you need to figure out how they compose.
The naive answer might be to use logical conjunction (AKA Boolean and). Write one assertion as a Boolean expression, another assertion as another Boolean expression, and just compose them using the standard 'and' operator. In Haskell, that would be &&.
This works to a fashion, but has a major drawback. If such a composed assertion fails, it doesn't tell you why. All you know is that the entire Boolean expression evaluated to False.
This is the reason that most testing libraries come with explicit assertion APIs. In HUnit, you may wish to use the ~=? operator, and in QuickCheck the === operator.
The question, however, is how they compose. Ideally, assertions should compose applicatively, but I've never seen that in the wild. If not, look for a monoid, or at least a semigroup.
Let's do that for both HUnit and QuickCheck.
Composing HUnit assertions #
My favourite HUnit assertion is the ~=? operator, which has the (simplified) type a > a -> Test. In other words, an expression like expectedRevenue ~=? actualRevenue has the type Test. The question, then, is: How does Test compose?
Not that well, I'm afraid, but I find the following workable. You can compose one or more Test values with the TestList constructor, but if you're already using the ~: operator, as I usually do (see below), then you just need a Testable instance, and it turns out that a list of Testable values is itself a Testable instance. This means that you can write a pure unit test and compose ~=? like this:
"CLRS example" ~: let p = [0, 1, 5, 8, 9, 10, 17, 17, 20, 24, 30] :: [Int] (r, s) = cutRod p 10 actualRevenue = Map.elems r actualSizes = Map.elems s expectedRevenue = [0, 1, 5, 8, 10, 13, 17, 18, 22, 25, 30] expectedSizes = [1, 2, 3, 2, 2, 6, 1, 2, 3, 10] in [expectedRevenue ~=? actualRevenue, expectedSizes ~=? actualSizes]
This is a refactoring of the above test, now as a pure function, because it tests the pure variation of cutRod. Notice that the two assertions are simply returned as a list.
While this has enough syntactical elegance to satisfy me, it does have the disadvantage that it actually creates two test cases. One that runs with the first assertion, and one that executes with the second:
:CLRS example: : [OK] : [OK]
In most cases this is unlikely to be a problem, but it could be if the test performs a resource-intensive computation. Each assertion you add makes it run one more time.
A test like the one shown here is so 'small' that this is rarely much of an issue. On the other hand, a property-based testing library might stress a System Under Test more, so fortunately, QuickCheck assertions compose better than HUnit assertions.
Composing QuickCheck assertions #
The === operator has the (simplified) type a -> a -> Property. Hoogling for a combinator with the type Property -> Property -> Property doesn't reveal anything useful, but fortunately it turns out that for running QuickCheck properties, all you really need is a Testable instance (not the same Testable as HUnit defines). And lo and behold! The .&&. operator is just what we need. That, or the conjoin function, if you have more than two assertions to combine, as in this example:
testProperty "cutRod returns correct arrays" $ \ p -> do let n = length p let p' = 0 : p -- Ensure the first element is 0 let (r, s) :: (Map Int Int, Map Int Int) = cutRod p' n let actualRevenue = Map.elems r let actualSizes = Map.elems s conjoin [ length actualRevenue === n + 1, length actualSizes === n, counterexample "Sizes are not all in [0..n]" $ all (\i -> 0 <= i && i <= n) actualSizes ]
The .&&. operator is actually a bit more flexible than conjoin, but due to operator precedence and indentation rules, trying to chain those three assertions with .&&. is less elegant than using conjoin. In this case.
Conclusion #
In imperative languages, composing test assertions is as simple as writing one assertion after another. Since assertions are statements, and imperative languages allow you to sequence statements, this is such a trivial way to compose assertions that you've probably never given it much thought.
Pure programs, however, are not composed from statements, but rather from expressions. A pure assertion is an expression that returns a value, so if you want to compose two or more pure assertions, you need to figure out how to compose the values that the assertions return.
Ideally, assertions should compose as applicative functors, but they rarely do. Instead, you'll have to go looking for combinators that enable you to combine two or more of a test library's built-in assertions. In this article, you've seen how to compose assertions in HUnit and QuickCheck.
It's striking so quickly the industry forgets that lines of code isn't a measure of productivity
Code is a liability, not an asset.
It's not a new idea that the more source code you have, the greater the maintenance burden. Dijkstra already touched on this topic in his Turing Award lecture in 1972, and later wrote,
"if we wish to count lines of code, we should not regard them as "lines produced" but as "lines spent""
He went on to note that
"the current conventional wisdom is so foolish as to book that count on the wrong side of the ledger."
The use of the word ledger suggests an accounting perspective that was later also adopted by Tim Ottinger, who observed that Code is a Liability.
The entire premise of my book Code That Fits in Your Head is also that the more code you have, the harder it becomes to evolve and maintain the code base.
Even so, it seems to me that, once more, most of the software industry is equating the ability to spew out as much code as fast as possible with productivity. My guess is that some people are in for a rude awakening in a couple of years.
Greyscale-box test-driven development
Is TDD white-box testing or black-box testing?
Surely you're aware of the terms black-box testing and white-box testing, but have you ever wondered where test-driven development (TDD) fits in that picture?
The short answer is that TDD as a software development practice sits somewhere between the two. It really isn't black and white, and exactly where TDD sits on the spectrum changes with circumstances.

If the above diagram indicates that TDD can't occupy the space of undiluted black- or white-box testing, that's not my intent. In my experience, however, you rarely do neither when you engage with the TDD process. Rather, you find yourself somewhere in-between.
In the following, I'll examine the two extremes in order to explain why TDD rarely leads to either, starting with black-box testing.
Compartmentalization of knowledge #
If you follow the usual red-green-refactor checklist, you write test code and production code in tight loops. You write some test code, some production code, more test code, then more production code, and so on.
If you're working by yourself, at least, that makes it almost impossible to treat the System Under Test (SUT) as a black box. After all, you're also the one who writes the production code.
You can try to 'forget' the production code you just wrote whenever you circle back to writing another test, but in practice, you can't. Even so, it may still be a useful exercise. I call this technique Gollum style (originally introduced in the Pluralsight course Outside-In Test-Driven Development as a variation on the Devil's advocate technique). The idea is to assume two roles, and to explicitly distinguish the goals of the tester from the aims of the implementer.
Still, while this can be an illuminating exercise, I don't pretend that this is truly black-box testing.
Pair programming #
If you pair-program, you have better options. You could have one person write a test, and another person implement the code to pass the test. I could imagine a setup where the tester can't see the production code. Although I've never seen or heard about anyone doing that, this would get close to true black-box TDD.
To demonstrate, imagine a team doing the FizzBuzz kata in this way. The tester writes the first test:
[Fact] public void One() { var actual = FizzBuzzer.Convert(1); Assert.Equal("1", actual); }
Either the implementer is allowed to see the test, or the specification is communicated to him or her in some other way. In any case, the natural response to the first test is an implementation like this:
public static string Convert(int number) { return "1"; }
In TDD, this is expected. This is the simplest implementation that passes all tests. We imagine that the tester already knows this, and therefore adds this test next:
[Fact] public void Two() { var actual = FizzBuzzer.Convert(2); Assert.Equal("2", actual); }
The implementer's response is this:
public static string Convert(int number) { if (number == 1) return "1"; return "2"; }
The tester can't see the implementation, so may believe that the implementation is now 'appropriate'. Even if he or she wants to be 'more sure', a few more test cases (for, say, 4, 7, or 38) could be added; it doesn't make any difference for the following argument.
Next, incrementally, the tester may add a few test cases that cover the "Fizz" behaviour:
[Fact] public void Three() { var actual = FizzBuzzer.Convert(3); Assert.Equal("Fizz", actual); } [Fact] public void Six() { var actual = FizzBuzzer.Convert(6); Assert.Equal("Fizz", actual); }
Similar test cases cover the "Buzz" and "FizzBuzz" behaviours. For this example, I wrote eight test cases in total, but a more sceptical tester might write twelve or even sixteen before feeling confident that the test suite sufficiently describes the desired behaviour of the system. Even so, a sufficiently adversarial implementer might (given eight test cases) deliver this implementation:
public static string Convert(int number) { switch (number) { case 1: return "1"; case 2: return "2"; case 5: case 10: return "Buzz"; case 15: case 30: return "FizzBuzz"; default: return "Fizz"; } }
To be clear, it's not that I expect real-world programmers to be either obtuse or nefarious. In real life, on the other hand, requirements are more complicated, and may be introduced piecemeal in a fashion that may lead to buggy, overly-complicated implementations.
Under-determination #
Remarkably, black-box testing may work better as an ex-post technique, compared to TDD. If we imagine that an implementer has made an effort to correctly implement a system according to specification, a tester may use black-box testing to poke at the SUT, using both randomly selected test cases, and by explicitly exercising the SUT at boundary cases.
Even so, black-box testing in reality tends to run into the problem of under-determination, also known from philosophy of science. As I outlined in Code That Fits in Your Head, software testing has many similarities with empirical science. We use experiments (tests) to corroborate hypotheses that we have about software: Typically either that it doesn't pass tests, or that it does pass all tests, depending on where in the red-green-refactor cycle we are.
Similar to science, we are faced with the basic epistemological problem that we have a finite number of tests, but usually an infinite (or at least extremely big) state space. Thus, as pointed out by the problem of under-determination, more than one 'reality' fits the available observations (i.e. test cases). The above FizzBuzz implementation is an example of this.
As an aside, certain problems actually have images that are sufficiently small that you can cover everything in total. In its most common description, the FizzBuzz kata, too, falls into this category.
"Write a program that prints the numbers from 1 to 100."
This means that you can, in fact, write 100 test cases and thereby specify the problem in its totality. What you still can't do with black-box testing, however, is impose a particular implementation. An adversarial implementer could write the Convert function as one big switch statement. Just like I did with the Tennis kata, another kata with a small state space.
This, however, rarely happens in the real world. Example-driven testing is under-determined. And no, property-based testing doesn't fundamentally change that conclusion. It behoves you to look critically at the actual implementation code, and not rely exclusively on testing.
Working with implementation code #
It's hardly a surprise that TDD isn't black-box testing. Is it white-box testing, then? Since the red-green-refactor cycle dictates a tight loop between test and production code, you always have the implementation code at hand. In that sense, the SUT is a white box.
That said, the common view on white-box testing is that you work with knowledge about the internal implementation of an already-written system, and use that to design test cases. Typically, looking at the code should enable a tester to identify weak spots that warrant testing.
This isn't always the case with TDD. If you follow the red-green-refactor checklist, each cycle should leave you with a SUT that passes all tests in the simplest way that could possibly work. Consider the first incarnation of Convert, above (the one that always returns "1"). It passes all tests, and from a white-box-testing perspective, it has no weak spots. You can't identify a test case that'll make it crash.
If you consider the test suite as an executable specification, that degenerate implementation is correct, since it passes all tests. Of course, according to the kata description, it's wrong. Looking at the SUT code will tell you that in a heartbeat. It should prompt you to add another test case. The question is, though, whether that qualifies as white-box testing, or it's rather reminiscent of the transformation priority premise. Not that that's necessarily a dichotomy.
Overspecified software #
Perhaps a more common problem with white-box testing in relation to TDD is the tendency to take a given implementation for granted. Of course, working according to the red-green-refactor cycle, there's no implementation before the test, but a common technique is to use Mock Objects to let tests specify how the SUT should be implemented. This leads to the familiar problem of Overspecified Software.
Here's an example.
Finding values in an interval #
In the code base that accompanies Code That Fits in Your Head, the code that handles a new restaurant reservation contains this code snippet:
var reservations = await Repository .ReadReservations(restaurant.Id, reservation.At) .ConfigureAwait(false); var now = Clock.GetCurrentDateTime(); if (!restaurant.MaitreD.WillAccept(now, reservations, reservation)) return NoTables500InternalServerError(); await Repository.Create(restaurant.Id, reservation) .ConfigureAwait(false);
The ReadReservations method is of particular interest in this context. It turns out to be a small extension method on a more general interface method:
internal static Task<IReadOnlyCollection<Reservation>> ReadReservations( this IReservationsRepository repository, int restaurantId, DateTime date) { var min = date.Date; var max = min.AddDays(1).AddTicks(-1); return repository.ReadReservations(restaurantId, min, max); }
The IReservationsRepository interface doesn't have a method that allows a client to search for all reservations on a given date. Rather, it defines a more general method that enables clients to search for reservations in a given interval:
Task<IReadOnlyCollection<Reservation>> ReadReservations( int restaurantId, DateTime min, DateTime max);
As the parameter names imply, the method finds and returns all the reservations for a given restaurant between the min and max values. A previous article already covers this method in much detail.
I think I've stated this more than once before: Code is never perfect. Although I made a genuine attempt to write quality code for the book's examples, now that I revisit this API, I realize that there's room for improvement. The most obvious problem with that method definition is that it's not clear whether the range includes, or excludes, the boundary values. Would it improve encapsulation if the method instead took a Range<DateTime> parameter?
At the very least, I could have named the parameters inclusiveMin and inclusiveMax. That's how the system is implemented, and you can see an artefact of that in the above extension method. It searches from midnight of date to the tick just before midnight on the next day.
The SQL implementation reflects that contract, too.
SELECT [PublicId], [At], [Name], [Email], [Quantity] FROM [dbo].[Reservations] WHERE [RestaurantId] = @RestaurantId AND @Min <= [At] AND [At] <= @Max
Here, @RestaurantId, @Min, and @Max are query parameters. Notice that the query uses the <= relation for both @Min and @Max, making both endpoints inclusive.
Interactive white-box testing #
Since I'm aware of the problem of overspecified software, I test-drove the entire code base using state-based testing. Imagine, however, that I'd instead used a dynamic mock library. If so, a test could have looked like this:
[Fact] public async Task PostUsingMoq() { var now = DateTime.Now; var reservation = Some.Reservation.WithDate(now.AddDays(2).At(20, 15)); var repoTD = new Mock<IReservationsRepository>(); repoTD .Setup(r => r.ReadReservations( Some.Restaurant.Id, reservation.At.Date, reservation.At.Date.AddDays(1).AddTicks(-1))) .ReturnsAsync(new Collection<Reservation>()); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Some.Restaurant), repoTD.Object); var ar = await sut.Post(Some.Restaurant.Id, reservation.ToDto()); Assert.IsAssignableFrom<CreatedAtActionResult>(ar); // More assertions could go here. }
This test uses Moq, but the example doesn't hinge on that. I rarely use dynamic mock libraries these days, but when I do, I still prefer Moq.
Notice how the Setup reproduces the implementation of the ReadReservations extension method. The implication is that if you change the implementation code, you break the test.
Even so, we may consider this an example of a test-driven white-box test. While, according to the red-green-refactor cycle, you're supposed to write the test before the implementation, this style of TDD only works if you, the test writer, has an exact plan for how the SUT is going to look.
An innocent refactoring? #
Don't you find that min.AddDays(1).AddTicks(-1) expression a bit odd? Wouldn't the code be cleaner if you could avoid the AddTicks(-1) part?
Well, you can.
A tick is the smallest unit of measurement of DateTime values. Since ticks are discrete, the range defined by the extension method would be equivalent to a right-open interval, where the minimum value is still included, but the maximum is not. If you made that change, the extension method would be simpler:
internal static Task<IReadOnlyCollection<Reservation>> ReadReservations( this IReservationsRepository repository, int restaurantId, DateTime date) { var min = date.Date; var max = min.AddDays(1); return repository.ReadReservations(restaurantId, min, max); }
In order to offset that change, you also change the SQL accordingly:
SELECT [PublicId], [At], [Name], [Email], [Quantity] FROM [dbo].[Reservations] WHERE [RestaurantId] = @RestaurantId AND @Min <= [At] AND [At] < @Max
Notice that the query now compares [At] with @Max using the < relation.
While this is formally a breaking change of the interface, it's entirely internal to the application code base. No external systems or libraries depend on IReservationsRepository. Thus, this change is a true refactoring: It improves the code without changing the observable behaviour of the system.
Even so, this change breaks the PostUsingMoq test.
To make the test pass, you'll need to repeat the change you made to the SUT:
[Fact] public async Task PostUsingMoq() { var now = DateTime.Now; var reservation = Some.Reservation.WithDate(now.AddDays(2).At(20, 15)); var repoTD = new Mock<IReservationsRepository>(); repoTD .Setup(r => r.ReadReservations( Some.Restaurant.Id, reservation.At.Date, reservation.At.Date.AddDays(1))) .ReturnsAsync(new Collection<Reservation>()); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Some.Restaurant), repoTD.Object); var ar = await sut.Post(Some.Restaurant.Id, reservation.ToDto()); Assert.IsAssignableFrom<CreatedAtActionResult>(ar); // More assertions could go here. }
If it's only one test, you can probably live with that, but it's the opposite of a robust test; it's a Fragile Test.
"to refactor, the essential precondition is [...] solid tests"
A common problem with interaction-based testing is that even small refactorings break many tests. We might see that as a symptom of having too much knowledge of implementation details. We might view this as related to white-box testing.
To be clear, the tests in the code base that accompanies Code That Fits in Your Head are all state-based, so contrary to the PostUsingMoq test, all 161 tests easily survive the above refactoring.
Greyscale-box TDD #
It's not too hard to argue that TDD isn't black-box testing, but it's harder to argue that it's not white-box testing. Naturally, as you follow the red-green-refactor cycle, you know all about the implementation. Still, the danger of being too aware of the SUT code is being trapped in an implementation mindset.
While there's nothing wrong with getting the implementation right, many maintainability problems originate in insufficient encapsulation. Deliberately treating the SUT as a grey box helps in discovering a SUT's contract. That's why I recommend techniques like Devil's Advocate. Pretending to view the SUT from the outside can shed valuable light on usability and maintainability issues.
Conclusion #
The notions of white-box and black-box testing have been around for decades. So has TDD. Even so, it's not always clear to practitioners whether TDD is one or the other. The reason is, I believe, that TDD is neither. Good TDD practice sits somewhere between white-box testing and black-box testing.
Exactly where on that greyscale spectrum TDD belongs depends on context. The more important encapsulation is, the closer you should move towards black-box testing. The more important correctness or algorithm performance is, the closer to white-box testing you should move.
You can, however, move position on the spectrum even in the same code base. Perhaps you want to start close to white-box testing as you focus on getting the implementation right. Once the SUT works as intended, you may then decide to shift your focus towards encapsulation, in which case moving closer to black-box testing could prove beneficial.
IO is special
Are IO expressions really referentially transparent programs?
Sometimes, when I discuss functional architecture or the IO container, a reader will argue that Haskell IO really is 'pure', 'referentially transparent', 'functional', or has another similar property.
The argument usually goes like this: An IO value is a composable description of an action, but not in itself an action. Since IO is a Monad instance, it composes via the usual monadic bind combinator >>=, or one of its derivatives.
Another point sometimes made is that you can 'call' an IO-valued action from within a pure function, as demonstrated by this toy example:
greet :: TimeOfDay -> String -> String greet timeOfDay name = let greeting = case () of _ | isMorning timeOfDay -> "Good morning" | isAfternoon timeOfDay -> "Good afternoon" | isEvening timeOfDay -> "Good evening" | otherwise -> "Hello" sideEffect = putStrLn "Side effect!" in if null name then greeting ++ "." else greeting ++ ", " ++ name ++ "."
This is effectively a Haskell port of the example given in Referential transparency of IO. Here, sideEffect is a value of the type IO (), even though greet is a pure function. Such examples are sometimes used to argue that the expression putStrLn "Side effect!" is pure, because it's deterministic and has no side effects.
Rather, sideEffect is a 'program' that describes an action. The program is a referentially transparent value, although actually running it is not.
As I also explained in Referential transparency of IO, the above function application is legal because greet never uses the value 'inside' the IO action. In fact, the compiler may choose to optimize the sideEffect expression away, and I believe that GHC does just that.
I've tried to summarize the most common arguments as succinctly as I can. While I could cite actual online discussions that I've had, I don't wish to single out anyone. I don't want to make this article appear as though it's an attack on anyone in particular. Rather, my position remains that IO is special, and I'll subsequently try to explain the reasoning.
Reductio ad absurdum #
While I could begin my argument stating the general case, backed up by citing some papers, I'm afraid I'll lose most readers in the process. Therefore I'll flip the argument around and start with a counter-example. What would happen if we accept the claim that IO is pure or referentially transparent?
It would follow that all Haskell code should be considered pure. That would include putStrLn "Hello, world." or launchMissiles. That I find that conclusion absurd may just be my subjective opinion, but it also seems to go against the original purpose of using IO to tackle the awkward squad.
Furthermore, and this may be more objective, it seems to allow writing everything in IO, and still call it 'functional'. What do I mean by that?
Functional imperative code #
If we accept that IO is pure, then we may decide to write everything in procedural style. We could, for example, implement rod-cutting by mirroring the imperative pseudocode used to describe the algorithm.
{-# LANGUAGE FlexibleContexts #-}
module RodCutting where
import Control.Monad (forM_, when)
import Data.Array.IO
import Data.IORef (newIORef, writeIORef, readIORef, modifyIORef)
cutRod :: (Ix i, Num i, Enum i, Num e, Bounded e, Ord e)
=> IOArray i e -> i -> IO (IOArray i e, IOArray i i)
cutRod p n = do
r <- newArray_ (0, n)
s <- newArray_ (1, n)
writeArray r 0 0 -- r[0] = 0
forM_ [1..n] $ \j -> do
q <- newIORef minBound -- q = -∞
forM_ [1..j] $ \i -> do
qValue <- readIORef q
p_i <- readArray p i
r_j_i <- readArray r (j - i)
when (qValue < p_i + r_j_i) $ do
writeIORef q (p_i + r_j_i) -- q = p[i] + r[j - i]
writeArray s j i -- s[j] = i
qValue' <- readIORef q
writeArray r j qValue' -- r[j] = q
return (r, s)
Ironically, the cutRod action remains referentially transparent, as is the original pseudocode from CLRS. This is because the algorithm itself is deterministic, and has no (external) side effects. Even so, the Haskell type system can't 'see' that. This implementation is intrinsically IO-valued.
Functional encapsulation #
You may think that this just proves the point that IO is pure, but it doesn't. We've always known that we can lift any pure value into IO using return: return 42 remains referentially transparent, even if it's contained in IO.
The reverse isn't always true. We can't conclude that code is referentially transparent when it's contained in IO. Usually, it isn't.
Be that as it may, why do we even care?
The problem is one of encapsulation. When an action like cutRod, above, returns an IO value, we're facing a dearth of guarantees. As users of the action, we may have many questions, most of which aren't answered by the type:
- Does
cutRodmodify the input arrayp? - Is
cutRoddeterministic? - Does
cutRodlaunch missiles? - Can I memoize the return values of
cutRod? - Does
cutRodsomehow keep a reference to the arrays that it returns? Can I be sure that a background thread, or a subsequent API call, doesn't mutate these arrays? In other words, is there a potential aliasing problem?
At best, such lack of guarantees lead to defensive coding, but usually it leads to bugs.
If, on the other hand, we were to write a version of cutRod that does not involve IO, we'd be able to answer all the above questions. The advantage would be that the function would be safer and easier to consume.
Referential transparency is not the same as purity #
This leads to a point that I failed to understand for years, until Tyson Williams pointed it out to me. Referential transparency is not the same as purity, although the overlap is substantial.
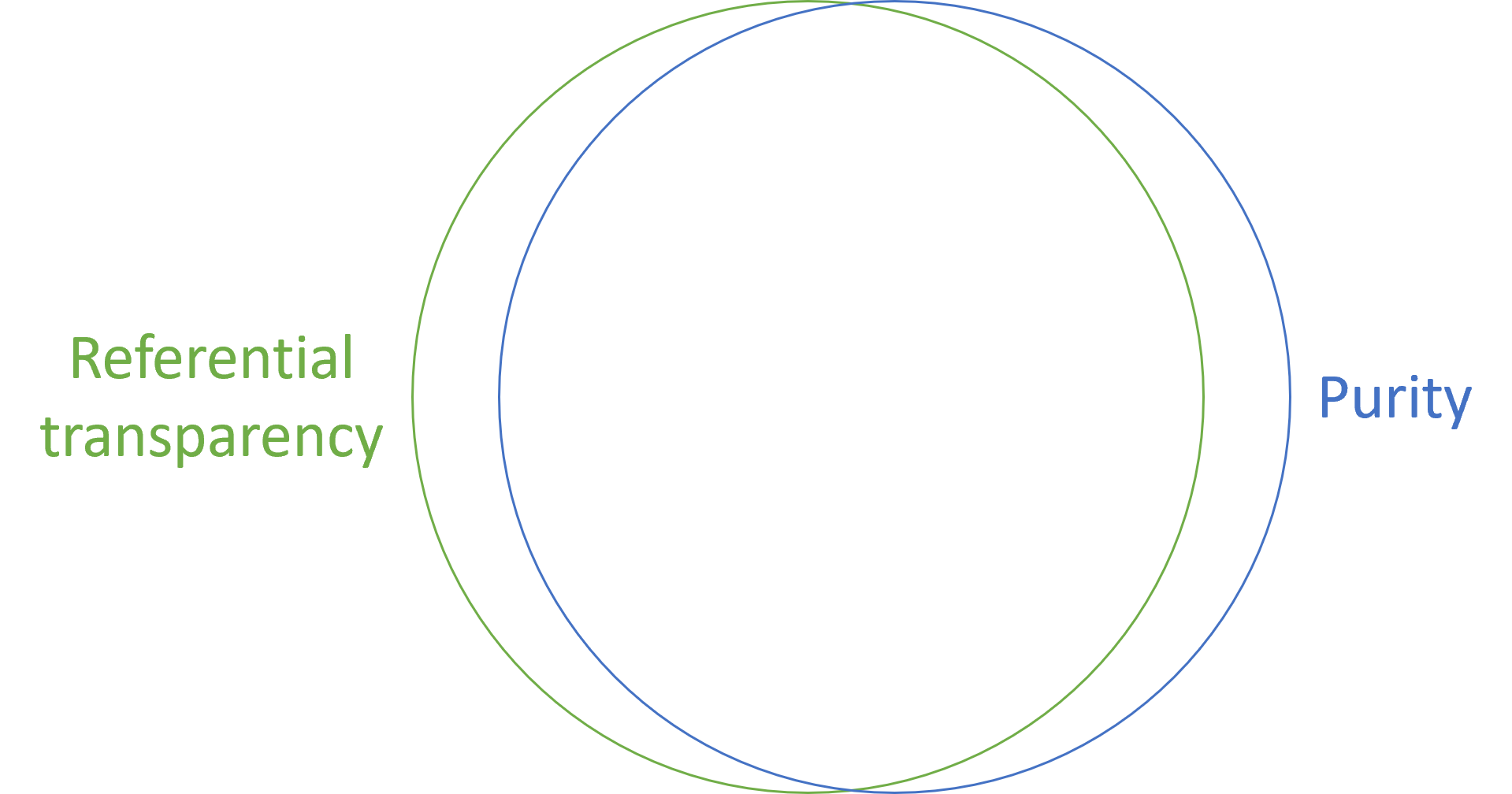
Of course, such a claim requires me to define the terms, but I'll try to keep it light. I'll define referential transparency as the property that allows replacing a function with the value it produces. Practically, it allows memoization. On the other hand, I'll define purity as functions that Haskell can distinguish from impure actions. In practice, this implies the absence of IO.
Usually this amounts to the same thing, but as we've seen above, it's possible to write referentially transparent code that nonetheless is embedded in IO. There are also examples of functions that look pure, although they may not be referentially transparent. Fortunately these are, in my experience, more rare.
That said, this is a digression. My agenda is to argue that IO is special. Yes, it's a Monad instance. Yes, it composes. No, it's not referentially transparent.
Semantics #
From the point of encapsulation, I've previously argued that referential transparency is attractive because it fits in your head. Code that is not referentially transparent usually doesn't.
Why is IO not referentially transparent? To repeat the argument that I sometimes run into, IO values describe programs. Every time your Haskell code runs, the same IO value describes the same program.
This strikes me as about as useful an assertion as insisting that all C code is referentially transparent. After all, a C program also describes the same program even if executed multiple times.
But you don't have to take my word for it. In Tackling the Awkward Squad: monadic input/output, concurrency, exceptions, and foreign-language calls in Haskell Simon Peyton Jones presents the semantics of Haskell.
"Our semantics is stratified in two levels: an inner denotational semantics that describes the behaviour of pure terms, while an outer monadic transition semantics describes the behaviour of
IOcomputations."
Over the next 20 pages, that paper goes into details on how IO is special. The point is that it has different semantics from the rest of Haskell.
Pure rod-cutting #
Before I close, I realize that the above cutRod action may cause distress with some readers. To relieve the tension I'll leave you with a pure implementation.
{-# LANGUAGE TupleSections #-}
module RodCutting (cutRod, solve) where
import Data.Foldable (foldl')
import Data.Map.Strict ((!))
import qualified Data.Map.Strict as Map
seekBetterCut :: (Ord a, Num a)
=> [a] -> Int -> (a, Map.Map Int a, Map.Map Int Int) -> Int
-> (a, Map.Map Int a, Map.Map Int Int)
seekBetterCut p j (q, r, s) i =
let price = p !! i
remainingRevenue = r ! (j - i)
(q', s') =
if q < price + remainingRevenue then
(price + remainingRevenue, Map.insert j i s)
else (q, s)
r' = Map.insert j q' r
in (q', r', s')
findBestCut :: (Bounded a, Ord a, Num a)
=> [a] -> (Map.Map Int a, Map.Map Int Int) -> Int
-> (Map.Map Int a, Map.Map Int Int)
findBestCut p (r, s) j =
let q = minBound -- q = -∞
(_, r', s') = foldl' (seekBetterCut p j) (q, r, s) [1..j]
in (r', s')
cutRod :: (Bounded a, Ord a, Num a)
=> [a] -> Int -> (Map.Map Int a, Map.Map Int Int)
cutRod p n = do
let r = Map.fromAscList $ map (, 0) [0..n] -- r[0:n] initialized to 0
let s = Map.fromAscList $ map (, 0) [1..n] -- s[1:n] initialized to 0
foldl' (findBestCut p) (r, s) [1..n]
solve :: (Bounded a, Ord a, Num a) => [a] -> Int -> [Int]
solve p n =
let (_, s) = cutRod p n
loop l n' =
if n' > 0 then
let cut = s ! n'
in loop (cut : l) (n' - cut)
else l
l' = loop [] n
in reverse l'
This is a fairly direct translation of the imperative algorithm. It's possible that you could come up with something more elegant. At least, I think that I did so in F#.
Regardless of the level of elegance of the implementation, this version of cutRod advertises its properties via its type. A client developer can now trivially answer the above questions, just by looking at the type: No, the function doesn't mutate the input list p. Yes, the function is deterministic. No, it doesn't launch missiles. Yes, you can memoize it. No, there's no aliasing problem.
Conclusion #
From time to time, I run into the claim that Haskell IO, being monadic and composable, is referentially transparent, and that it's only during execution that this property is lost.
I argue that such claims are of little practical interest. There are other parts of Haskell that remain referentially transparent, even during execution. Thus, IO is still special.
From a practical perspective, the reason I care about referential transparency is because the more you have of it, the simpler your code is; the better it fits in your head. The kind of referential transparency that some people argue that IO has does not have the property of making code simpler. In reality, IO code has the same inherent properties as code written in C, Python, Java, Fortran, etc.
Song recommendations with C# free monads
Just because it's possible. Don't do this at work.
This is the last article in a series named Alternative ways to design with functional programming. In it, you've seen various suggestions on how to model a non-trivial problem with various kinds of functional-programming patterns. The previous two articles showed how to use free monads to model the problem in Haskell and F#. In this article, I'll repeat the exercise in C#. It's not going to be pretty, but it's possible.
What is the point of this exercise? Mostly to supply parity in demo code. If you're more familiar with C# than F# or Haskell, this may give you a better sense of what a free monad is, and how it works. That's all. I don't consider the following practical code, and I don't endorse it.
The code shown here is based on the free branch of the DotNet Git repository available with this article series.
Functor #
A free monad enables you to define a monad from any functor. In this context, you start with the functor that models an instruction set for a domain-specific language (DSL). The goal is to replace the SongService interface with this instruction set.
As a reminder, this is the interface:
public interface SongService { Task<IReadOnlyCollection<User>> GetTopListenersAsync(int songId); Task<IReadOnlyCollection<Scrobble>> GetTopScrobblesAsync(string userName); }
I'll remind the reader that the code is my attempt to reconstruct the sample code shown in Pure-Impure Segregation Principle. I don't know if SongService is a base class or an interface. Based on the lack of the idiomatic C# I prefix for interfaces, one may suppose that it was really intended to be a base class, but since I find interfaces easier to handle than base classes, here we are.
In any case, the goal is to replace it with an instruction set, starting with a sum type. Since C# comes with no native support for sum types, we'll need to model it with either Church encoding or a Visitor. I've been over the Visitor territory enough times already, so here I'll go with the Church option, since it's a tad simpler.
I start by creating a new class called SongInstruction<T> with this method:
public TResult Match<TResult>( Func<(int, Func<IReadOnlyCollection<User>, T>), TResult> getTopListeners, Func<(string, Func<IReadOnlyCollection<Scrobble>, T>), TResult> getTopScrobbles) { return imp.Match(getTopListeners, getTopScrobbles); }
If you squint sufficiently hard, you may be able to see how the getTopListeners parameter corresponds to the interface's GetTopListenersAsync method, and likewise for the other parameter.
I'm not going to give you a very detailed walkthrough, as I've already done that earlier in a different context. Likewise, I'll skip some of the implementation details. All the code is available in the Git repository.
To be a functor, the class needs a Select method.
public SongInstruction<TResult> Select<TResult>(Func<T, TResult> selector) { return Match( t => SongInstruction.GetTopListeners( t.Item1, // songId users => selector(t.Item2(users))), t => SongInstruction.GetTopScrobbles( t.Item1, // userName songs => selector(t.Item2(songs)))); }
The name t is, in both cases, short for tuple. It's possible that more recent versions of C# finally allow pattern matching of tuples in lambda expressions, but the version this code is based on doesn't. In both cases Item2 is the 'continuation' function.
Monad #
The next step is to wrap the functor in a data structure that enables you to sequence the above instructions. That has to be another sum type, this time called SongProgram<T>, characterized by this Match method:
public TResult Match<TResult>( Func<SongInstruction<SongProgram<T>>, TResult> free, Func<T, TResult> pure) { return imp.Match(free, pure); }
A SelectMany method is required to make this type a proper monad:
public SongProgram<TResult> SelectMany<TResult>( Func<T, SongProgram<TResult>> selector) { return Match( i => SongProgram.Free(i.Select(p => p.SelectMany(selector))), selector); }
The code is already verbose enough as it is, so I've used i for instruction and p for program.
Lifted helpers #
Although not strictly required, I often find it useful to add a helper method for each case of the instruction type:
public static SongProgram<IReadOnlyCollection<User>> GetTopListeners(int songId) { return Free(SongInstruction.GetTopListeners(songId, Pure)); } public static SongProgram<IReadOnlyCollection<Scrobble>> GetTopScrobbles(string userName) { return Free(SongInstruction.GetTopScrobbles(userName, Pure)); }
This just makes the user code look a bit cleaner.
Song recommendations as a DSL #
Using the composition from Song recommendations from C# combinators as a starting point, it doesn't take that many changes to turn it into a SongProgram-valued function.
public static SongProgram<IReadOnlyList<Song>> GetRecommendations(string userName) { // 1. Get user's own top scrobbles // 2. Get other users who listened to the same songs // 3. Get top scrobbles of those users // 4. Aggregate the songs into recommendations return SongProgram.GetTopScrobbles(userName) .SelectMany(scrobbles => UserTopScrobbles(scrobbles) .Traverse(scrobble => SongProgram .GetTopListeners(scrobble.Song.Id) .Select(TopListeners) .SelectMany(users => users .Traverse(user => SongProgram .GetTopScrobbles(user.UserName) .Select(TopScrobbles)) .Select(Songs))) .Select(TakeTopRecommendations)); }
Notice how much it resembles the original GetRecommendationsAsync method on the RecommendationsProvider class. Instead of songService.GetTopScrobblesAsync it just has SongProgram.GetTopScrobbles, and instead of songService.GetTopListenersAsync it has SongProgram.GetTopListeners.
To support this composition, however, a traversal is required.
Traverse #
The traversal needs a Select function on SongProgram, so we'll start with that.
public SongProgram<TResult> Select<TResult>(Func<T, TResult> selector) { return SelectMany(x => SongProgram.Pure(selector(x))); }
This is the standard implementation of a functor from a monad.
It turns out that it's also useful to define a function to concatenate two sequence-valued programs.
private static SongProgram<IEnumerable<T>> Concat<T>( this SongProgram<IEnumerable<T>> xs, SongProgram<IEnumerable<T>> ys) { return xs.SelectMany(x => ys.Select(y => x.Concat(y))); }
This could, perhaps, be a public function, but in this situation, I only need it to implement Traverse, so I kept it private. The Traverse function, on the other hand, is public.
public static SongProgram<IEnumerable<TResult>> Traverse<T, TResult>( this IEnumerable<T> source, Func<T, SongProgram<TResult>> selector) { return source.Aggregate( Pure(Enumerable.Empty<TResult>()), (acc, x) => acc.Concat(selector(x).Select(xr => new[] {xr}.AsEnumerable()))); }
Given a sequence of values, Traverse applies selector to each, and collects all resulting programs into a single sequence-valued program. You see it in use in the above GetRecommendations composition.
Interpreter #
That last missing piece is an interpreter that can evaluate a program. Since I already have a class called FakeSongService, adding an Interpret method was the easiest implementation strategy.
public T Interpret<T>(SongProgram<T> program) { return program.Match( i => i.Match( t => Interpret(t.Item2(GetTopListernes(t.Item1))), t => Interpret(t.Item2(GetTopScrobbles(t.Item1)))), x => x); }
Here, GetTopListernes and GetTopScrobbles are two private helper functions:
private IReadOnlyCollection<User> GetTopListernes(int songId) { var listeners = from kvp in users where kvp.Value.ContainsKey(songId) select new User(kvp.Key, kvp.Value.Values.Sum()); return listeners.ToList(); } private IReadOnlyCollection<Scrobble> GetTopScrobbles(string userName) { var scrobbles = users .GetOrAdd(userName, new ConcurrentDictionary<int, int>()) .Select(kvp => new Scrobble(songs[kvp.Key], kvp.Value)); return scrobbles.ToList(); }
The implementation closely mirrors the original Fake interface implementation, where users and songs are class fields on FakeSongService. This class was first shown in Characterising song recommendations.
It's now possible to rewrite all the tests.
Refactoring the tests #
Since the original GetRecommendationsAsync method was task-based, all tests had to run in task workflows. This is no longer necessary, as this simplified FsCheck property demonstrates:
[<Property>] let ``One user, some songs`` () = gen { let! user = Gen.userName let! songs = Gen.arrayOf Gen.song let! scrobbleCounts = Gen.choose (1, 100) |> Gen.arrayOfLength songs.Length return (user, Array.zip songs scrobbleCounts) } |> Arb.fromGen |> Prop.forAll <| fun (user, scrobbles) -> let srvc = FakeSongService () scrobbles |> Array.iter (fun (s, c) -> srvc.Scrobble (user, s, c)) let actual = RecommendationsProvider.GetRecommendations user |> srvc.Interpret Assert.Empty actual
Originally, this test had to be defined in terms of the task computation expression, but now it's a pure function. In the act phase the test calls RecommendationsProvider.GetRecommendations user and pipes the returned program to srvc.Interpret. The result, actual, is a plain IReadOnlyCollection<Song> value.
Similarly, I was able to migrate all the example-based tests over, too.
[<Fact>] let ``One verified recommendation`` () = let srvc = FakeSongService () srvc.Scrobble ("cat", Song (1, false, 6uy), 10) srvc.Scrobble ("ana", Song (1, false, 5uy), 10) srvc.Scrobble ("ana", Song (2, true, 5uy), 9_9990) let actual = RecommendationsProvider.GetRecommendations "cat" |> srvc.Interpret Assert.Equal<Song> ([ Song (2, true, 5uy) ], actual)
Once all tests were migrated over to the new GetRecommendations function, I deleted the old RecommendationsProvider class as well as the SongService interface, since none of them were required any longer.
Conclusion #
The lack of proper syntactic sugar, similar to do notation in Haskell, or computation expressions in F#, means that free monads aren't a useful design option in C#. Still, perhaps the last three articles help a reader or two understanding what a free monad is.
Song recommendations with F# free monads
With an extensive computation expression.
This article is part of a series called Alternative ways to design with functional programming. As the title suggests, it examines alternative functional-programming architectures. It does so by looking at the same overall example problem: Calculating song recommendations from a large data set of 'scrobbles'; records of playback data for many users. In the previous article, you saw how to implement the desired functionality using a free monad in Haskell. In this article, you'll see how to use a free monad in F#.
If you are following along in the accompanying Git repository, the code shown here is from the fsharp-free branch. The starting point is fsharp-port.
Functor #
A free monad enables you to define a monad from any functor. In this context, you start with the functor that models an instruction set for a domain-specific language (DSL). The goal is to replace the SongService interface with this instruction set.
As a reminder, this is the interface:
type SongService = abstract GetTopListenersAsync : songId : int -> Task<IReadOnlyCollection<User>> abstract GetTopScrobblesAsync : userName : string -> Task<IReadOnlyCollection<Scrobble>>
I'm following the F# free monad recipe, which, I'm happy to report, turned out to be easy to do.
First, the sum type:
type SongInstruction<'a> = | GetTopListeners of songId : int * (IReadOnlyCollection<User> -> 'a) | GetTopScrobbles of userName : string * (IReadOnlyCollection<Scrobble> -> 'a)
If you check with the F# free monad recipe and compare the SongService interface methods with the SongInstruction cases, you should be able to spot the similarity, and how to get from interface to discriminated union.
As shown in the previous article, in Haskell you can declaratively state that a type should be a Functor instance. In F# you have to implement it yourself.
module SongInstruction = let map f = function | GetTopListeners ( songId, next) -> GetTopListeners ( songId, next >> f) | GetTopScrobbles (userName, next) -> GetTopScrobbles (userName, next >> f)
Here I've put it in its own little module, in order to make it clear which kind of data the map function handles.
Monad #
The next step is to wrap the functor in a data structure that enables you to sequence the above instructions.
type SongProgram<'a> = | Free of SongInstruction<SongProgram<'a>> | Pure of 'a
A bind function is required to make this type a proper monad:
module SongProgram = let rec bind f = function | Free inst -> inst |> SongInstruction.map (bind f) |> Free | Pure inst -> f inst
Again, I'm slavishly following the F# free monad recipe; please refer to it for more details.
Computation expression #
Technically, that's all it takes to make it possible to write programs in the little DSL. Doing it exclusively with the above bind function would, however, but quite cumbersome, so you'll also appreciate some syntactic sugar in the form of a computation expression.
As you will see shortly, I needed to (temporarily) support some imperative language constructs, so I had to make it more involved than usually required.
type SongProgramBuilder () = member _.Bind (x, f) = SongProgram.bind f x member _.Return x = Pure x member _.ReturnFrom x = x member _.Zero () = Pure () member _.Delay f = f member _.Run f = f () member this.While (guard, body) = if not (guard ()) then this.Zero () else this.Bind (body (), fun () -> this.While (guard, body)) member this.TryWith (body, handler) = try this.ReturnFrom (body ()) with e -> handler e member this.TryFinally (body, compensation) = try this.ReturnFrom (body ()) finally compensation () member this.Using (disposable : #System.IDisposable, body) = let body' = fun () -> body disposable this.TryFinally (body', fun () -> match disposable with | null -> () | disp -> disp.Dispose ()) member this.For (sequence : seq<_>, body) = this.Using (sequence.GetEnumerator (), fun enum -> this.While (enum.MoveNext, this.Delay (fun () -> body enum.Current))) member _.Combine (x, y) = x |> SongProgram.bind (fun () -> y ())
I had to do quite a bit of yak shaving before I got the For method right. Not surprisingly, Scott Wlaschin's series on computation expressions proved invaluable.
As you always do with computation expressions, you leave a builder object somewhere the rest of your code can see it:
let songProgram = SongProgramBuilder ()
You'll soon see an example of using a songProgram computation expression.
Lifted helpers #
Although not strictly required, I often find it useful to add a helper function for each case of the instruction type:
let getTopListeners songId = Free (GetTopListeners (songId, Pure)) let getTopScrobbles userName = Free (GetTopScrobbles (userName, Pure))
This just makes the user code look a bit cleaner.
Imperative-looking program #
With all that machinery in place, you can now write a referentially transparent function that implements the same algorithm as the original class method.
let getRecommendations userName = songProgram { // 1. Get user's own top scrobbles // 2. Get other users who listened to the same songs // 3. Get top scrobbles of those users // 4. Aggregate the songs into recommendations let! scrobbles = getTopScrobbles userName let scrobblesSnapshot = scrobbles |> Seq.sortByDescending (fun s -> s.ScrobbleCount) |> Seq.truncate 100 |> Seq.toList let recommendationCandidates = ResizeArray () for scrobble in scrobblesSnapshot do let! otherListeners = getTopListeners scrobble.Song.Id let otherListenersSnapshot = otherListeners |> Seq.filter (fun u -> u.TotalScrobbleCount >= 10_000) |> Seq.sortByDescending (fun u -> u.TotalScrobbleCount) |> Seq.truncate 20 |> Seq.toList for otherListener in otherListenersSnapshot do // Impure let! otherScrobbles = getTopScrobbles otherListener.UserName // Pure let otherScrobblesSnapshot = otherScrobbles |> Seq.filter (fun s -> s.Song.IsVerifiedArtist) |> Seq.sortByDescending (fun s -> s.Song.Rating) |> Seq.truncate 10 |> Seq.toList otherScrobblesSnapshot |> List.map (fun s -> s.Song) |> recommendationCandidates.AddRange let recommendations = recommendationCandidates |> Seq.sortByDescending (fun s -> s.Rating) |> Seq.truncate 200 |> Seq.toList :> IReadOnlyCollection<_> return recommendations }
Notice how much it resembles the original GetRecommendationsAsync method on the RecommendationsProvider class. Instead of songService.GetTopScrobblesAsync it just has getTopScrobbles, and instead of songService.GetTopListenersAsync it has getTopListeners. The whole computation is wrapped in songProgram, and the return type is SongProgram<IReadOnlyCollection<Song>>.
Perhaps you're wondering how the local state mutation (of recommendationCandidates) squares with my claim that this function is referentially transparent, but consider what referential transparency means. It means that you could replace a particular function call (say, getRecommendations "cat") with the value it returns. And you can. That the function used local mutation to arrive at that return value is of no concern to the caller.
Even so, later in this article, we'll refactor the code to something that looks more like a pure function. For now, however, we'll first see how to evaluate programs like the one returned by getRecommendations.
Interpreter #
Again, I follow the F# free monad recipe. Since I already have a class called FakeSongService, adding an Interpret method was the easiest implementation strategy. A private recursive function takes care of the implementation:
let rec interpret = function | Pure x -> x | Free (GetTopListeners (songId, next)) -> users |> Seq.filter (fun kvp -> kvp.Value.ContainsKey songId) |> Seq.map (fun kvp -> user kvp.Key (Seq.sum kvp.Value.Values)) |> Seq.toList |> next |> interpret | Free (GetTopScrobbles (userName, next)) -> users.GetOrAdd(userName, ConcurrentDictionary<_, _> ()) |> Seq.map (fun kvp -> scrobble songs[kvp.Key] kvp.Value) |> Seq.toList |> next |> interpret
The implementation closely mirrors the original Fake interface implementation, where users and songs are class fields on FakeSongService. This class was first shown in Characterising song recommendations.
Since I added the interpret function in the class, we need a method that enables client code to call it:
member _.Interpret program = interpret program
It's now possible to rewrite all the tests.
Refactoring the tests #
Since the original GetRecommendationsAsync method was task-based, all tests had to run in task workflows. This is no longer necessary, as this simplified FsCheck property demonstrates:
[<Property>] let ``One user, some songs`` () = gen { let! user = Gen.userName let! songs = Gen.arrayOf Gen.song let! scrobbleCounts = Gen.choose (1, 100) |> Gen.arrayOfLength songs.Length return (user, Array.zip songs scrobbleCounts) } |> Arb.fromGen |> Prop.forAll <| fun (user, scrobbles) -> let srvc = FakeSongService () scrobbles |> Array.iter (fun (s, c) -> srvc.Scrobble (user, s, c)) let actual = getRecommendations user |> srvc.Interpret Assert.Empty actual
Originally, this test had to be defined in terms of the task computation expression, but now it's a pure function. In the act phase the test calls getRecommendations user and pipes the returned program to srvc.Interpret. The result, actual, is a plain IReadOnlyCollection<Song> value.
Similarly, I was able to migrate all the example-based tests over, too.
[<Fact>] let ``One verified recommendation`` () = let srvc = FakeSongService () srvc.Scrobble ("cat", song 1 false 6uy, 10) srvc.Scrobble ("ana", song 1 false 5uy, 10) srvc.Scrobble ("ana", song 2 true 5uy, 9_9990) let actual = getRecommendations "cat" |> srvc.Interpret Assert.Equal<Song> ([ song 2 true 5uy ], actual)
Once all tests were migrated over to the new getRecommendations function, I deleted the old RecommendationsProvider class as well as the SongService interface, since none of them were required any longer. Notice how I managed to move in smaller steps than in the previous article. As described in Code That Fits in Your Head, I used the Strangler pattern to move incrementally. I should also have done that with the Haskell code base, but fortunately I didn't run into trouble.
With all the tests migrated to pure functions, it's time to go back to getRecommendations to give it some refactoring love.
Traverse #
The local mutation in the above incarnation of getRecommendations is located within a doubly-nested loop. You typically need a traversal if you want to refactor such loops to expressions.
The traversal needs a map function, so we'll start with that.
let map f = bind (f >> Pure)
This function is included in the SongProgram module shown above. That's the reason it can call bind without a prefix. The same is true for the traverse function.
let traverse f xs = let concat xs ys = xs |> bind (fun x -> ys |> map (Seq.append x)) Seq.fold (fun acc x -> concat acc (f x |> map Seq.singleton)) (Pure (Seq.empty)) xs
The local concat function concatenates two SongProgram values that contain sequences to a single SongProgram value containing the concatenated sequence. The traversal uses this helper function to fold over the xs.
Refactored program #
You can now go through all the usual motions of replacing the nested loops and the local mutation with traversal, extracting helper functions and so on. If you're interested in the small steps I took, you may consult the Git repository. Here, I only present the getRecommendations function in the state I decided to leave it.
let getRecommendations userName = songProgram { // 1. Get user's own top scrobbles // 2. Get other users who listened to the same songs // 3. Get top scrobbles of those users // 4. Aggregate the songs into recommendations let! scrobbles = getTopScrobbles userName let! otherlListeners = getUsersOwnTopScrobbles scrobbles |> SongProgram.traverse (fun s -> getTopListeners s.Song.Id) let! otherScrobbles = otherlListeners |> Seq.collect getOtherUsersWhoListenedToTheSameSongs |> SongProgram.traverse (fun u -> getTopScrobbles u.UserName) return otherScrobbles |> Seq.collect getTopScrobblesOfUsers |> aggregateTheSongsIntoRecommendations }
Notice the two applications of traverse, which replace the twice-nested loop.
The type of getRecommendations is unchanged, and all tests still pass.
Conclusion #
As expected, it required more boilerplate code to refactor the GetRecommendationsAsync method to a design based on a free monad, than the corresponding refactoring did in Haskell. Even so, following the F# free monad recipe made it was smooth sailing. I did, however, hit a snag, mostly of my own manufacture, when implementing support for for loops in the computation expression builder, but that problem turned out to be unrelated to the free monad.
Again, you may wonder what the point is. First, I'll refer you to the decision flowchart in the F# free monad recipe, as well as remind you that these articles are all intended to be descriptive rather than prescriptive. They only present what is possible. It's up to you to decide which option to choose.
Second, a SongProgram<'a> may look similar to an interface, but consider how much more restricted it is. A method that uses dependency injection is inherently impure; in such a method, everything may happen, including every kind of bug.
The F# type system does not check whether or not unconstrained side effects or non-determinism takes place, but still, a type like SongProgram<'a> strongly suggests that only SongProgram-related actions take place.
I think that free monads still have a place in F#, although mostly as a niche use case. In C#, on the other hand, free monads aren't useful because the language lacks features to make this kind of programming workable. Still, for demonstration purposes only, it can be done.
Song recommendations with Haskell free monads
A surprisingly easy refactoring.
This article is part of a larger series titled Alternative ways to design with functional programming. In short, it uses Haskell, F#, and C# to present various internal architectures to deal with an example problem. Please refer to the table of contents included with the first article to get a sense of what has already been covered.
In this article, you'll see how a free monad may be used to address the problem that when data size is sufficiently large, you may need to load it piecemeal, based on the results of previous steps in an algorithm. In short, the problem being addressed is to calculate a list of song recommendations based on so-called 'scrobble' data from a multitude of other users' music playback history.
If you want to follow along with the Git repository, the code presented here is from the Haskell repository's free branch.
Starting point #
Instead of starting from scratch from the code base presented in Porting song recommendations to Haskell, I'll start at what was an interim refactoring step in Song recommendations from Haskell combinators:
getRecommendations :: SongService a => a -> String -> IO [Song] getRecommendations srvc un = do -- 1. Get user's own top scrobbles -- 2. Get other users who listened to the same songs -- 3. Get top scrobbles of those users -- 4. Aggregate the songs into recommendations -- Impure scrobbles <- getTopScrobbles srvc un -- Pure let scrobblesSnapshot = take 100 $ sortOn (Down . scrobbleCount) scrobbles -- Impure recommendations <- join <$> traverse (\scrobble -> fmap join $ traverse (\otherListener -> fmap scrobbledSong . take 10 . sortOn (Down . songRating . scrobbledSong) . filter (songHasVerifiedArtist . scrobbledSong) <$> getTopScrobbles srvc (userName otherListener)) . take 20 <$> sortOn (Down . userScrobbleCount) . filter ((10_000 <=) . userScrobbleCount) =<< getTopListeners srvc (songId $ scrobbledSong scrobble)) scrobblesSnapshot -- Pure return $ take 200 $ sortOn (Down . songRating) recommendations
The reason I wanted to start here is that with the IORef out of the way, the only IO-bound code remaining involves the SongService methods.
The plan is to replace the SongService type class with a free monad. Once that's done, there's no more IO left; it will have been replaced by the free monad. That's why it's easiest to first get rid of everything else involving IO. If I didn't, the refactoring wouldn't be as easy. As Kent Beck wrote,
"for each desired change, make the change easy (warning: this may be hard), then make the easy change"
Starting from the above incarnation of the code makes the change easy.
Functor #
As a reminder, this type class is the one I'm getting rid of:
class SongService a where getTopListeners :: a -> Int -> IO [User] getTopScrobbles :: a -> String -> IO [Scrobble]
Converting such an 'interface' to a sum type of instructions is such a well-defined process that I think it could be automated (if it were worth the effort). You take each method of the type class and make it a case in the sum type.
data SongInstruction a = GetTopListeners Int ([User] -> a) | GetTopScrobbles String ([Scrobble] -> a) deriving (Functor)
I usually think of such a type as representing possible instructions in a little domain-specific language (DSL). In this case, the DSL allows only two instructions: GetTopListeners and GetTopScrobbles.
If you've never seen a free monad before, you may be wondering: What's the a? It's what we may call the carrier type. If you haven't worked with, say, F-Algebras, this takes some time getting used to, but the carrier type represents a 'potential'. As presented here, it may be anything, but when you want to evaluate or 'run' the program, the a turns out to be the return type of the evaluation.
Since SongInstruction is a Functor, it's possible to map a to b, or one concrete type to another, so that the a type parameter can take on more than one concrete type during a small 'program' written in the DSL.
In any case, at this point, SongInstruction a is only a Functor, and not yet a Monad.
Free monad #
You may, if you want to, introduce a type alias that makes SongInstruction a (or, rather, its Free wrapper) a Monad.
type SongProgram = Free SongInstruction
The Free wrapper comes from Control.Monad.Free.
In the rest of the code listings in this article, I make no use of this type alias, so I only present it here because it's the type the compiler will infer when running the test. In other words, while never explicitly stated, this is going to be the de-facto free monad in this article.
From action to function #
Changing the getRecommendations action to a function that returns (effectively) Free (SongInstruction [Song]) turned out to be easier than I had expected.
Since I've decided to omit type declarations whenever possible, refactoring is easier because the type inferencing system can allow changes to function and action types to ripple through to the ultimate callers. (To be clear, however, I here show some of the code with type annotations. I've only added those in the process of writing this article, as an aid to you, the reader. You will not find those type annotations in the Git repository.)
First, I added a few helper methods to create 'program instructions':
getTopListeners sid = liftF $ GetTopListeners sid id getTopScrobbles un = liftF $ GetTopScrobbles un id
The liftF function wraps a Functor (here, SongInstruction) in a free monad. This makes it easer to write programs in that DSL.
The only changes now required to getRecommendations is to remove srvc in four places:
getRecommendations :: MonadFree SongInstruction m => String -> m [Song] getRecommendations un = do -- 1. Get user's own top scrobbles -- 2. Get other users who listened to the same songs -- 3. Get top scrobbles of those users -- 4. Aggregate the songs into recommendations -- Impure scrobbles <- getTopScrobbles un -- Pure let scrobblesSnapshot = take 100 $ sortOn (Down . scrobbleCount) scrobbles -- Impure recommendations <- join <$> traverse (\scrobble -> fmap join $ traverse (\otherListener -> fmap scrobbledSong . take 10 . sortOn (Down . songRating . scrobbledSong) . filter (songHasVerifiedArtist . scrobbledSong) <$> getTopScrobbles (userName otherListener)) . take 20 <$> sortOn (Down . userScrobbleCount) . filter ((10_000 <=) . userScrobbleCount) =<< getTopListeners (songId $ scrobbledSong scrobble)) scrobblesSnapshot -- Pure return $ take 200 $ sortOn (Down . songRating) recommendations
It's almost the same code as before. The only difference is that srvc is not longer a parameter to either getRecommendations, getTopListeners, or getTopScrobbles.
Again, I'll point out that I've only added the type annotation for the benefit of you, the reader. We see now, however, that the return type is m [Song], where m is any MonadFree SongInstruction.
Interpreter #
As described in Porting song recommendations to Haskell I use a FakeSongService as a Test Double. SongService is now gone, but I can repurpose the instance implementation as an interpreter of SongInstruction programs.
interpret :: FakeSongService -> Free SongInstruction a -> a interpret (FakeSongService ss us) = iter eval where eval (GetTopListeners sid next) = next $ uncurry User <$> Map.toList (sum <$> Map.filter (Map.member sid) us) eval (GetTopScrobbles un next) = next $ fmap (\(sid, c) -> Scrobble (ss ! sid) c) $ Map.toList $ Map.findWithDefault Map.empty un us
Compare that code to the previous SongService instance shown in Porting song recommendations to Haskell. The functions are nearly identical, only return is replaced by next, and a few other, minute changes.
Test changes #
The hardest part of this refactoring was to adjust the tests. As I've described in Code That Fits in Your Head, I don't like when I have to change the System Under Test and the test code in the same commit, but in this case I lacked the skill to do it more incrementally.
The issue is that since SongService methods were IO-bound, the tests ran in IO. Particularly for the QuickCheck properties, I had to remove the ioProperty and monadicIO combinators. This also meant adjusting some of the assertions. The "One user, some songs" test now looks like this:
testProperty "One user, some songs" $ \ (ValidUserName user) (fmap getSong -> songs) -> do scrobbleCounts <- vectorOf (length songs) $ choose (1, 100) let scrobbles = zip songs scrobbleCounts let srvc = foldr (uncurry (scrobble user)) emptyService scrobbles let actual = interpret srvc $ getRecommendations user return $ counterexample "Should be empty" (null actual)
Notice the interpreter in action, to the left of the application of getRecommendations. Since interpret reduces any Free SongInstruction a to a, it evaluates Free SongInstruction [Song] to [Song]; that's the type of actual.
The change represents a net benefit in my view. All tests are now pure, instead of running in IO. This makes them simpler.
Final refactoring #
The above version of the code was only a good starting point for making the changeover to a free monad. Extracting the usual helper functions, you can arrive at this variation of the getRecommendations function:
getRecommendations un = do -- 1. Get user's own top scrobbles -- 2. Get other users who listened to the same songs -- 3. Get top scrobbles of those users -- 4. Aggregate the songs into recommendations userTops <- getTopScrobbles un <&> getUsersOwnTopScrobbles otherListeners <- traverse (getTopListeners . (songId . scrobbledSong)) userTops <&> getOtherUsersWhoListenedToTheSameSongs . join songs <- traverse (getTopScrobbles . userName) otherListeners <&> getTopScrobblesOfOtherUsers . join return $ aggregateTheSongsIntoRecommendations songs
Again, it looks a lot like one of the variations shown in Porting song recommendations to Haskell, just without the srvc parameter.
Conclusion #
Refactoring from a type class, which in other languages could be an interface, is so easy that you may rightfully ask what the point is. To me, the most important benefit is that you restrict your options. As I discussed in a podcast episode some years ago, constraints liberate. Here, we move from allowing anything (IO) to only allowing a limited set of instructions.
You could argue that a 'real' interpreter (rather than a test-specific interpreter) might run in IO, such as the interpreter shown here. Still, I would argue that most interpreters are smaller, and more stable, than the programs you may write with free monads. Thus, the amount of code you have to review that's allowed to do anything is smaller than it otherwise would have been.
In any case, refactoring to a free monad wasn't too difficult in Haskell. How easy is it in F#?
Song recommendations with free monads
A Golden Hammer.
This article is part of a larger article series about alternative ways to design with functional programming, particularly when faced with massive data loads. In previous articles in the series, you've seen various alternatives that may or may not enable you to solve the example problem using functional programming. Each of the previous alternatives, applying the Recawr Sandwich pattern, employing functional combinators, or using pipes and filters, came with some trade-offs. Either there were limits to the practicality of the architecture, or it wasn't really functional after all.
In this, and the following three articles, we finally reach for a universal solution: Free monads.
By universal I mean: It's always possible to do this (if your language supports it). It doesn't follow that it's always a good idea.
So there are trade-offs here, too.
As is usually the case, although sometimes I forget to write it, this and the following articles are descriptive, not prescriptive. In no way do I insist that things must be done this way. I only present examples as options.
The last resort #
If using a free monad is a universal possibility, then why is that not the default option? Why have I waited this long in the article series before covering it?
For more than a single reason.
It's an 'advanced' technique, and I predict that to many programmers, it looks like black magic. If you're working with a team unready for free monads, foisting it upon them are unlikely to lead to anything good.
The following story may illustrate the problem. It's not about free monads, but rather about Dependency Injection (DI) Containers. A specific one, actually. I was consulting with a team, working as a temporary lead developer for about half a year. I made a number of technical decisions, some of them good and others not so much. Among the latter was the decision to use the Castle Windsor DI Container.
Not that Castle Windsor was a bad library. After having done the research and written a book, I considered it the best DI Container available.
The problem, rather, was that the rest of the team considered it 'automagical'. Not that they weren't sophisticated programmers, but they had no interest learning the Castle Windsor API. They didn't consider it part of their core work, and they didn't think it provided enough benefit compared to the maintenance burden it imposed.
They humoured me as long as I stayed on, but also explicitly told me that they'd rip it out as soon as I was gone. In the meantime, I became the Castle Windsor bottleneck. Everything related to that piece of technology had to go through me, since I was the only person who understood how it worked.
A few years later, I returned to that team and that code base on a new project, and they'd kept their word. They'd removed Castle Windsor in favour of Pure DI, bless them.
This experience was crucial in making me realize that, despite their intellectual attraction, DI Containers are rarely the correct choice.
Free monads look to me as though they belong to the same category. While I don't have a similar story to tell, I'm wary of recommending them unless other options are played out. I'll refer you to the decision flowchart in the article F# free monad recipe.
Language support #
Another concern about free monads is whether your language of choice supports them. They fit perfectly in Haskell, which is also the reason I start this sub-series of articles with a Haskell example.
- Song recommendations with Haskell free monads
- Song recommendations with F# free monads
- Song recommendations with C# free monads
In F# you'll have to do some more legwork, but once you've added the required infrastructure, the 'user code' based on free monads is perfectly fine.
C#, on the other hand, doesn't have all the language features that will make free monads a good experience. I wouldn't suggest using a free monad in C#. I include the article with the C# free monad for demonstration purposes only.
These articles will not introduce free monads to novice readers. For a gentler introduction, see the article series Pure interactions.
Conclusion #
When all else fails, and you just must write pure functions, reach for free monads. They are not for everyone, or every language, but they do offer a functional solution to problems with large data sets or rich interaction with users or the environment.
Testing races with a synchronizing Decorator
Synchronized database reads for testing purposes.
In a previous article, you saw how to use a slow Decorator to test for race conditions. Towards the end, I discussed how that solution is only near-deterministic. In this article, I discuss a technique which is, I think, properly deterministic, but unfortunately less elegant.
In short, it works by letting a Decorator synchronize reads.
The problem #
In the previous article, I used words to describe the problem, but really, I should be showing, not telling. Here's a variation on the previous test that exemplifies the problem.
[Fact] public async Task NoOverbookingRace() { var date = DateTime.Now.Date.AddDays(1).AddHours(18.5); using var service = new RestaurantService(); using var slowService = from repo in service select new SlowReservationsRepository(TimeSpan.FromMilliseconds(100), repo); var task1 = slowService.PostReservation(new ReservationDtoBuilder() .WithDate(date) .WithQuantity(10) .Build()); await Task.Delay(TimeSpan.FromSeconds(1)); var task2 = slowService.PostReservation(new ReservationDtoBuilder() .WithDate(date) .WithQuantity(10) .Build()); var actual = await Task.WhenAll(task1, task2); Assert.Single( actual, msg => msg.StatusCode == HttpStatusCode.InternalServerError); var ok = Assert.Single(actual, msg => msg.IsSuccessStatusCode); // Check that the reservation was actually created: var resp = await service.GetReservation(ok.Headers.Location); resp.EnsureSuccessStatusCode(); var reservation = await resp.ParseJsonContent<ReservationDto>(); Assert.Equal(10, reservation.Quantity); }
Apart from a single new line of code, this is is identical to the test shown in the previous article. The added line is the Task.Delay between task1 and task2.
What's the point of adding this delay there? Only to demonstrate a problem. That's one of the situations I described in the previous article: Even though the test starts both tasks without awaiting them, they aren't guaranteed to run in parallel. Both start as soon as they're created, so task2 is going to be ever so slightly behind task1. What happens if there's a delay between the creation of these two tasks?
Here I've explicitly introduced such a delay for demonstration purposes, but such a delay could happen on a real system for a number of reasons, including garbage collection, thread starvation, the OS running a higher-priority task, etc.
Why might that pause matter?
Because it may produce false negatives. Imagine a situation where there's no transaction control; where there's no TransactionScope around the database interactions. If the pause is long enough, the tasks effectively run in sequence (instead of in parallel), in which case the system correctly rejects the second attempt.
This is even when using the SlowReservationsRepository Decorator.
How long does the pause need to be before this happens?
As described in the previous article, with a configured delay of 100 ms for the SlowReservationsRepository, creating a new reservation is delayed by 300 ms. This bears out. Experimenting on my own machine, if I change that explicit, artificial delay to 300 ms, and remove the transaction control, the test sometimes fails, and sometimes passes. With the above one-second delay, the test always passes, even when transaction control is missing.
You could decide that a 300 ms pause at just the worst possible time is so unlikely that you're willing to simply accept those odds. I would probably be, too. Still, what to test, and what not to test is a function of context. You may find yourself in a context where that's not good enough. What other options are there?
Synchronizing Decorator #
What you really need to reproduce the race condition is to synchronize the database reads. If you could make sure that the Repository only returns data when enough reads have been performed, you can deterministically reproduce the problem.
Again, start with a Decorator. This time, build into it a way to synchronize reads.
internal sealed class SynchronizedReaderRepository : IReservationsRepository { private readonly CountdownEvent countdownEvent = new CountdownEvent(2); public SynchronizedReaderRepository(IReservationsRepository inner) { Inner = inner; } public IReservationsRepository Inner { get; }
Here I've used a CountdownEvent object to ensure that reads only progress when the countdown reaches zero. It's possible that more appropriate threading APIs exist, but this serves well as a proof of concept.
The method you need to synchronize is ReadReservations, so you can leave all the other methods to delegate to Inner. Only ReadReservations is special.
public async Task<IReadOnlyCollection<Reservation>> ReadReservations( int restaurantId, DateTime min, DateTime max) { var result = await Inner .ReadReservations(restaurantId, min, max); countdownEvent.Signal(); countdownEvent.Wait(); return result; }
This implementation also starts by delegating to Inner, but before it returns the result, it signals the countdownEvent and blocks the thread by waiting on the countdownEvent. Only when both threads have signalled it does the counter reach zero, and the methods may proceed.
If we assume that, while the test is running, no other calls to ReadReservations is made, this guarantees that both threads receive the same answer. This will make both competing threads come to the answer that they can accept the reservation. If no transaction control is in place, the system will overbook the requested time slot.
Testing with the synchronizing Repository #
The test that uses SynchronizedReaderRepository is almost identical to the previous test.
[Fact] public async Task NoOverbookingRace() { var date = DateTime.Now.Date.AddDays(1).AddHours(18.5); using var service = new RestaurantService(); using var syncedService = service.Select(repo => new SynchronizedReaderRepository(repo)); var task1 = syncedService.PostReservation(new ReservationDtoBuilder() .WithDate(date) .WithQuantity(10) .Build()); var task2 = syncedService.PostReservation(new ReservationDtoBuilder() .WithDate(date) .WithQuantity(10) .Build()); var actual = await Task.WhenAll(task1, task2); Assert.Single( actual, msg => msg.StatusCode == HttpStatusCode.InternalServerError); var ok = Assert.Single(actual, msg => msg.IsSuccessStatusCode); // Check that the reservation was actually created: var resp = await service.GetReservation(ok.Headers.Location); resp.EnsureSuccessStatusCode(); var reservation = await resp.ParseJsonContent<ReservationDto>(); Assert.Equal(10, reservation.Quantity); }
Contrary to using the slow Repository, this test doesn't allow false negatives. If transaction control is missing from the System Under Test (SUT), this test fails. And it passes when transaction control is in place.
Disadvantages #
That sounds great, so why not just do this, instead of using a delaying Decorator? Because, as usual, there are trade-offs involved. This kind of solution comes with some disadvantages that are worth taking into account.
In short, this could make the test more fragile. As shown above, SynchronizedReaderRepository makes a specific assumption. It assumes that it needs to synchronize exactly two parallel readers. One problem with this is that this may be coupled to exactly one test. If you had other tests, you'd need to write a new Decorator, or generalize this one in some way.
Another problem is that this makes the test sensitive to changes in the SUT. What if a code change introduces a new call to ReadReservations? If so, the countdownEvent may unblock the threads too soon. One such change may be that the SUT decides to also query for surrounding times slots. You might be able to make SynchronizedReaderRepository robust against such changes by keeping a dictionary of synchronization objects (such as the above CountdownEvent) per argument set, but that clearly complicates the implementation.
And even so, it doesn't protect against identical 'double reads', even though these may be less likely to happen.
This Decorator is also vulnerable to caching. If you have a read-through cache that wraps around SynchronizedReaderRepository, only the first query may get to it, which would then cause it to block forever. Perhaps, again, you could fix this with the Wait overload that takes a timeout value.
That said, if you cache reads, the pessimistic locking that TransactionScope uses isn't going to work. You could, perhaps, address that concern with optimistic concurrency, but that comes with its own problems.
Conclusion #
You can address race conditions in various ways, but synchronization has been around for a long time. Not only can you use synchronization primitives and APIs to make your code thread-safe, you can also use them to deterministically reproduce race conditions, or to test that such a bug is no longer present in the system.
I don't want to claim that this is universally possible, but if you run into such problems, it's at least worth considering if you could take advantage of synchronization to reproduce a problem.
Of course, the implication is that you understand what the problem is. This is often the hardest part of dealing with race conditions, and the ideas described in this article don't help with that.

Comments
A more general solution would be to use the parallel random testing described in the talk by John Hughes here.
Thank you for writing. I tried watching the talk, but I don't get how to translate that idea to this example. Additionally, I currently don't have the bandwidth to read a 12-page paper. Would it be possible to sketch out how the concept translates to testing a race condition like the one shown here?
You can think of it as a normal property-based test (in fact CsCheck builds on the existing random testing functions) with a generated initial state set of operations plus a small set of operations to be run in parallel (some PostReservation calls). The property to test is that this parallel run is linearizable which means we can find at least one sequential order of the parallel operations that gives the same result (reservation.Quantity) as the parallel run. This does require some housekeeping to get all the possible permutations correct as you know some ran on the same thread in a certain order which reduces the number to test. We get all the goodies of shrinking here (CsCheck has an advantage as shrinking is random) which is why John was able to help solve very hard concurrency issues for companies.
Thank you for the example code. Obviously, you've made some assumptions about how this particular code base works, but often the devil is in the details, so when I finally had a bit of time on my hands, I decided to try out the feature on the real code base. After a bit of back and forth, I wrote this test:
An important part of the Restaurant REST API design is that clients receive correct responses when things go wrong. That's the motivation for including a
ConcurrentBagas part of the state, recording whether the response indicates success or failure.To my disappointment, even when the race bug is absent (i.e. when transaction control is present in the service), this test fails. Here's a typical output from a failing test:
Message: CsCheck.CsCheckException : Set seed: "0005Pq8wWlm1" or -e CsCheck_Seed=0005Pq8wWlm1 to reproduce (0 shrinks, 72 skipped, 100 total). Initial state: (Ploeh.Samples.Restaurants.RestApi.SqlIntegrationTests.RestaurantService, {}) Sequential Operations: [] Parallel Operations: [Op0 4, Op0 1, Op0 4] On Threads: [0, 1, 0] Final state: (Ploeh.Samples.Restaurants.RestApi.SqlIntegrationTests.RestaurantService, {False, True, True}) Linearized: [Op0 4, Op0 1, Op0 4] -> (Ploeh.Samples.Restaurants.RestApi.SqlIntegrationTests.RestaurantService, {False, False, False}) : [Op0 1, Op0 4, Op0 4] -> (Ploeh.Samples.Restaurants.RestApi.SqlIntegrationTests.RestaurantService, {False, False, False}) : [Op0 4, Op0 4, Op0 1] -> (Ploeh.Samples.Restaurants.RestApi.SqlIntegrationTests.RestaurantService, {False, False, False})At first this is surprising, and upon further reflection, it may not be that surprising. Still, there are things that I don't understand.
Here's what's initially surprising: Implicit in this test is that the restaurant seats a maximum of 10 people a day. Thus, with 4, 1, and 4 seats being requested, it surprised me that any of these reservations were being declined. Still, all the linearized models have
{False, False, False}; in other words, no reservations were accepted.Then I remembered that this test is actually running on a real SQL Server database, and since I'm assuming that CsCheck has been running quite a few scenarios already, it actually makes sense that that particular day is already completely sold out. Does 72 skipped indicate that there were 72 prior runs before this one? Or does it mean that CsCheck found a counterexample after 28 tries, and then decided to skip the remaining 72 runs?
In any case, even if it only did 27 prior runs, it seems likely that the date is already completely sold out. It then puzzles me that the final state is
{False, True, True}. I honestly can't think of a good explanation of that, but perhaps you can?In any case, I still think that I understand why this can't work as written above. The problem with filling up all reservations for a given date is the reason why I originally performed every attempt to provoke the race on a unique date. Is there a way to do that with CsCheck and
SampleParallel?Alternatively, one would need a way to tear down the persistent fixture (i.e. the database) after each run. I can't identify an API that enables me to do that, but perhaps I'm missing something. Is that option somehow available?