ploeh blog danish software design
A first crack at the Args kata
Test-driven development in C#.
A customer hired me to swing by to demonstrate test-driven development and tactical Git. To make things interesting, we agreed that they'd give me a kata at the beginning of the session. I didn't know which problem they'd give me, so I thought it'd be a good idea to come prepared. I decided to seek out katas that I hadn't done before.
The demonstration session was supposed to be two hours in front of a participating audience. In order to make my preparation aligned to that situation, I decided to impose a two-hour time limit to see how far I could get. At the same time, I'd also keep an eye on didactics, so preferably proceeding in an order that would be explainable to an audience.
Some katas are more complicated than others, so I'm under no illusion that I can complete any, to me unknown, kata in under two hours. My success criterion for the time limit is that I'd like to reach a point that would satisfy an audience. Even if, after two hours, I don't reach a complete solution, I should leave a creative and intelligent audience with a good idea of how to proceed.
The first kata I decided to try was the Args kata. In this article, I'll describe some of the most interesting things that happened along the way. If you want all the details, the code is available on GitHub.
Boolean parser #
In short, the goal of the Args kata is to develop an API for parsing command-line arguments.
When you encounter a new problem, it's common to have a few false starts until you develop a promising plan. This happened to me as well, but after a few attempts that I quickly stashed, I realised that this is really a validation problem - as in parse, don't validate.
The first thing I did after that realisation was to copy verbatim the Validated code from An applicative reservation validation example in C#. I consider it fair game to reuse general-purpose code like this for a kata.
With that basic building block available, I decided to start with a parser that would handle Boolean flags. My reasoning was that this might be the simplest parser, since it doesn't have many failure modes. If the flag is present, the value should be interpreted to be true; otherwise, false.
Over a series of iterations, I developed this parametrised xUnit.net test:
[Theory] [InlineData('l', "-l", true)] [InlineData('l', " -l ", true)] [InlineData('l', "-l -p 8080 -d /usr/logs", true)] [InlineData('l', "-p 8080 -l -d /usr/logs", true)] [InlineData('l', "-p 8080 -d /usr/logs", false)] [InlineData('l', "-l true", true)] [InlineData('l', "-l false", false)] [InlineData('l', "nonsense", false)] [InlineData('f', "-f", true)] [InlineData('f', "foo", false)] [InlineData('f', "", false)] public void TryParseSuccess(char flagName, string candidate, bool expected) { var sut = new BoolParser(flagName); var actual = sut.TryParse(candidate); Assert.Equal(Validated.Succeed<string, bool>(expected), actual); }
To be clear, this test started as a [Fact] (single, non-parametrised test) that I subsequently converted to a parametrised test, and then added more and more test cases to.
The final implementation of BoolParser looks like this:
public sealed class BoolParser : IParser<bool> { private readonly char flagName; public BoolParser(char flagName) { this.flagName = flagName; } public Validated<string, bool> TryParse(string candidate) { var idx = candidate.IndexOf($"-{flagName}"); if (idx < 0) return Validated.Succeed<string, bool>(false); var nextFlagIdx = candidate[(idx + 2)..].IndexOf('-'); var bFlag = nextFlagIdx < 0 ? candidate[(idx + 2)..] : candidate.Substring(idx + 2, nextFlagIdx); if (bool.TryParse(bFlag, out var b)) return Validated.Succeed<string, bool>(b); return Validated.Succeed<string, bool>(true); } }
This may not be the most elegant solution, but it passes all tests. Since I was under time pressure, I didn't want to spend too much time polishing the implementation details. As longs as I'm comfortable with the API design and the test cases, I can always refactor later. (I usually say that later is never, which also turned out to be true this time. On the other hand, it's not that the implementation code is awful in any way. It has a cyclomatic complexity of 4 and fits within a 80 x 20 box. It could be much worse.)
The IParser interface came afterwards. It wasn't driven by the above test, but by later developments.
Rough proof of concept #
Once I had a passable implementation of BoolParser, I developed a similar IntParser to a degree where it supported a happy path. With two parsers, I had enough building blocks to demonstrate how to combine them. At that point, I also had some 40 minutes left, so it was time to produce something that might look useful.
At first, I wanted to demonstrate that it's possible to combine the two parsers, so I wrote this test:
[Fact] public void ParseBoolAndIntProofOfConceptRaw() { var args = "-l -p 8080"; var l = new BoolParser('l').TryParse(args).SelectFailure(s => new[] { s }); var p = new IntParser('p').TryParse(args).SelectFailure(s => new[] { s }); Func<bool, int, (bool, int)> createTuple = (b, i) => (b, i); static string[] combineErrors(string[] s1, string[] s2) => s1.Concat(s2).ToArray(); var actual = createTuple.Apply(l, combineErrors).Apply(p, combineErrors); Assert.Equal(Validated.Succeed<string[], (bool, int)>((true, 8080)), actual); }
That's really not pretty, and I wouldn't expect an unsuspecting audience to understand what's going on. It doesn't help that C# is inadequate for applicative functors. While it's possible to implement applicative validation, the C# API is awkward. (There are ways to make it better than what's on display here, but keep in mind that I came into this exercise unprepared, and had to grab what was closest at hand.)
The main point of the above test was only to demonstrate that it's possible to combine two parsers into one. That took me roughly 15 minutes.
Armed with that knowledge, I then proceeded to define this base class:
public abstract class ArgsParser<T1, T2, T> { private readonly IParser<T1> parser1; private readonly IParser<T2> parser2; public ArgsParser(IParser<T1> parser1, IParser<T2> parser2) { this.parser1 = parser1; this.parser2 = parser2; } public Validated<string[], T> TryParse(string candidate) { var l = parser1.TryParse(candidate).SelectFailure(s => new[] { s }); var p = parser2.TryParse(candidate).SelectFailure(s => new[] { s }); Func<T1, T2, T> create = Create; return create.Apply(l, CombineErrors).Apply(p, CombineErrors); } protected abstract T Create(T1 x1, T2 x2); private static string[] CombineErrors(string[] s1, string[] s2) { return s1.Concat(s2).ToArray(); } }
While I'm not a fan of inheritance, this seemed the fasted way to expand on the proof of concept. The class encapsulates the ugly details of the ParseBoolAndIntProofOfConceptRaw test, while leaving just enough room for a derived class:
internal sealed class ProofOfConceptParser : ArgsParser<bool, int, (bool, int)> { public ProofOfConceptParser() : base(new BoolParser('l'), new IntParser('p')) { } protected override (bool, int) Create(bool x1, int x2) { return (x1, x2); } }
This class only defines which parsers to use and how to translate successful results to a single object. Here, because this is still a proof of concept, the resulting object is just a tuple.
The corresponding test looks like this:
[Fact] public void ParseBoolAndIntProofOfConcept() { var sut = new ProofOfConceptParser(); var actual = sut.TryParse("-l -p 8080"); Assert.Equal(Validated.Succeed<string[], (bool, int)>((true, 8080)), actual); }
At this point, I hit the two-hour mark, but I think I managed to produce enough code to convince a hypothetical audience that a complete solution is within grasp.
What remained was to
- add proper error handling to
IntParser - add a corresponding
StringParser - improve the
ArgsParserAPI - add better demo examples of the improved
ArgsParserAPI
While I could leave this as an exercise to the reader, I couldn't just leave the code like that.
Finishing the kata #
For my own satisfaction, I decided to complete the kata, which I did in another hour.
Although I had started with an abstract base class, I know how to refactor it to a sealed class with an injected Strategy. I did that for the existing class, and also added one that supports three parsers instead of two:
public sealed class ArgsParser<T1, T2, T3, T> { private readonly IParser<T1> parser1; private readonly IParser<T2> parser2; private readonly IParser<T3> parser3; private readonly Func<T1, T2, T3, T> create; public ArgsParser( IParser<T1> parser1, IParser<T2> parser2, IParser<T3> parser3, Func<T1, T2, T3, T> create) { this.parser1 = parser1; this.parser2 = parser2; this.parser3 = parser3; this.create = create; } public Validated<string[], T> TryParse(string candidate) { var x1 = parser1.TryParse(candidate).SelectFailure(s => new[] { s }); var x2 = parser2.TryParse(candidate).SelectFailure(s => new[] { s }); var x3 = parser3.TryParse(candidate).SelectFailure(s => new[] { s }); return create .Apply(x1, CombineErrors) .Apply(x2, CombineErrors) .Apply(x3, CombineErrors); } private static string[] CombineErrors(string[] s1, string[] s2) { return s1.Concat(s2).ToArray(); } }
Granted, that's a bit of boilerplate, but if you imagine this as supplied by a reusable library, you only have to write this once.
I was now ready to parse the kata's central example, "-l -p 8080 -d /usr/logs", to a strongly typed value:
private sealed record TestConfig(bool DoLog, int Port, string Directory); [Theory] [InlineData("-l -p 8080 -d /usr/logs")] [InlineData("-p 8080 -l -d /usr/logs")] [InlineData("-d /usr/logs -l -p 8080")] [InlineData(" -d /usr/logs -l -p 8080 ")] public void ParseConfig(string args) { var sut = new ArgsParser<bool, int, string, TestConfig>( new BoolParser('l'), new IntParser('p'), new StringParser('d'), (b, i, s) => new TestConfig(b, i, s)); var actual = sut.TryParse(args); Assert.Equal( Validated.Succeed<string[], TestConfig>( new TestConfig(true, 8080, "/usr/logs")), actual); }
This test parses some variations of the example input into an immutable record.
What happens if the input is malformed? Here's an example of that:
[Fact] public void FailToParseConfig() { var sut = new ArgsParser<bool, int, string, TestConfig>( new BoolParser('l'), new IntParser('p'), new StringParser('d'), (b, i, s) => new TestConfig(b, i, s)); var actual = sut.TryParse("-p aityaity"); Assert.True(actual.Match( onFailure: ss => ss.Contains("Expected integer for flag '-p', but got \"aityaity\"."), onSuccess: _ => false)); Assert.True(actual.Match( onFailure: ss => ss.Contains("Missing value for flag '-d'."), onSuccess: _ => false)); }
Of particular interest is that, as promised by applicative validation, parsing failures don't short-circuit. The input value "-p aityaity" has two problems, and both are reported by TryParse.
At this point I was happy that I had sufficiently demonstrated the viability of the design. I decided to call it a day.
Conclusion #
As I did the Args kata, I found it interesting enough to warrant an article. Once I realised that I could use applicative parsing as the basis for the API, the rest followed.
There's room for improvement, but while doing katas is valuable, there are marginal returns in perfecting the code. Get the main functionality working, learn from it, and move on to another exercise.
Compile-time type-checked truth tables
With simple and easy-to-understand examples in F# and Haskell.
Eve Ragins recently published an article called Why you should use truth tables in your job. It's a good article. You should read it.
In it, she outlines how creating a Truth Table can help you smoke out edge cases or unclear requirements.
I agree, and it also beautifully explains why I find algebraic data types so useful.
With languages like F# or Haskell, this kind of modelling is part of the language, and you even get statically-typed compile-time checking that tells you whether you've handled all combinations.
Eve Ragins points out that there are other, socio-technical benefits from drawing up a truth table that you can, perhaps, print out, or otherwise share with non-technical stakeholders. Thus, the following is in no way meant as a full replacement, but rather as examples of how certain languages have affordances that enable you to think like this while programming.
F# #
I'm not going to go through Eve Ragins' blow-by-blow walkthrough, explaining how you construct a truth table. Rather, I'm just briefly going to show how simple it is to do the same in F#.
Most of the inputs in her example are Boolean values, which already exist in the language, but we need a type for the item status:
type ItemStatus = NotAvailable | Available | InUse
As is typical in F#, a type declaration is just a one-liner.
Now for something a little more interesting. In Eve Ragins' final table, there's a footnote that says that the dash/minus symbol indicates that the value is irrelevant. If you look a little closer, it turns out that the should_field_be_editable value is irrelevant whenever the should_field_show value is FALSE.
So instead of a bool * bool tuple, you really have a three-state type like this:
type FieldState = Hidden | ReadOnly | ReadWrite
It would probably have taken a few iterations to learn this if you'd jumped straight into pattern matching in F#, but since F# requires you to define types and functions before you can use them, I list the type now.
That's all you need to produce a truth table in F#:
let decide requiresApproval canUserApprove itemStatus = match requiresApproval, canUserApprove, itemStatus with | true, true, NotAvailable -> Hidden | false, true, NotAvailable -> Hidden | true, false, NotAvailable -> Hidden | false, false, NotAvailable -> Hidden | true, true, Available -> ReadWrite | false, true, Available -> Hidden | true, false, Available -> ReadOnly | false, false, Available -> Hidden | true, true, InUse -> ReadOnly | false, true, InUse -> Hidden | true, false, InUse -> ReadOnly | false, false, InUse -> Hidden
I've called the function decide because it wasn't clear to me what else to call it.
What's so nice about F# pattern matching is that the compiler can tell if you've missed a combination. If you forget a combination, you get a helpful Incomplete pattern match compiler warning that points out the combination that you missed.
And as I argue in my book Code That Fits in Your Head, you should turn warnings into errors. This would also be helpful in a case like this, since you'd be prevented from forgetting an edge case.
Haskell #
You can do the same exercise in Haskell, and the result is strikingly similar:
data ItemStatus = NotAvailable | Available | InUse deriving (Eq, Show) data FieldState = Hidden | ReadOnly | ReadWrite deriving (Eq, Show) decide :: Bool -> Bool -> ItemStatus -> FieldState decide True True NotAvailable = Hidden decide False True NotAvailable = Hidden decide True False NotAvailable = Hidden decide False False NotAvailable = Hidden decide True True Available = ReadWrite decide False True Available = Hidden decide True False Available = ReadOnly decide False False Available = Hidden decide True True InUse = ReadOnly decide False True InUse = Hidden decide True False InUse = ReadOnly decide False False InUse = Hidden
Just like in F#, if you forget a combination, the compiler will tell you:
LibrarySystem.hs:8:1: warning: [-Wincomplete-patterns] Pattern match(es) are non-exhaustive In an equation for `decide': Patterns of type `Bool', `Bool', `ItemStatus' not matched: False False NotAvailable | 8 | decide True True NotAvailable = Hidden | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^...
To be clear, that combination is not missing from the above code example. This compiler warning was one I subsequently caused by commenting out a line.
It's also possible to turn warnings into errors in Haskell.
Conclusion #
I love languages with algebraic data types because they don't just enable modelling like this, they encourage it. This makes it much easier to write code that handles various special cases that I'd easily overlook in other languages. In languages like F# and Haskell, the compiler will tell you if you forgot to deal with a combination.
Replacing Mock and Stub with a Fake
A simple C# example.
A reader recently wrote me about my 2013 article Mocks for Commands, Stubs for Queries, commenting that the 'final' code looks suspect. Since it looks like the following, that's hardly an overstatement.
public User GetUser(int userId) { var u = this.userRepository.Read(userId); if (u.Id == 0) this.userRepository.Create(1234); return u; }
Can you spot what's wrong?
Missing test cases #
You might point out that this example seems to violate Command Query Separation, and probably other design principles as well. I agree that the example is a bit odd, but that's not what I have in mind.
The problem with the above example is that while it correctly calls the Read method with the userId parameter, it calls Create with the hardcoded constant 1234. It really ought to call Create with userId.
Does this mean that the technique that I described in 2013 is wrong? I don't think so. Rather, I left the code in a rather unhelpful state. What I had in mind with that article was the technique I called data flow verification. As soon as I had delivered that message, I was, according to my own goals, done. I wrapped up the article, leaving the code as shown above.
As the reader remarked, it's noteworthy that an article about better unit testing leaves the System Under Test (SUT) in an obviously defect state.
The short response is that at least one test case is missing. Since this was only demo code to show an example, the entire test suite is this:
public class SomeControllerTests { [Theory] [InlineData(1234)] [InlineData(9876)] public void GetUserReturnsCorrectValue(int userId) { var expected = new User(); var td = new Mock<IUserRepository>(); td.Setup(r => r.Read(userId)).Returns(expected); var sut = new SomeController(td.Object); var actual = sut.GetUser(userId); Assert.Equal(expected, actual); } [Fact] public void UserIsSavedIfItDoesNotExist() { var td = new Mock<IUserRepository>(); td.Setup(r => r.Read(1234)).Returns(new User { Id = 0 }); var sut = new SomeController(td.Object); sut.GetUser(1234); td.Verify(r => r.Create(1234)); } }
There are three test cases: Two for the parametrised GetUserReturnsCorrectValue method and one test case for the UserIsSavedIfItDoesNotExist test. Since the latter only verifies the hardcoded value 1234 the Devil's advocate can get by with using that hardcoded value as well.
Adding a test case #
The solution to that problem is simple enough. Add another test case by converting UserIsSavedIfItDoesNotExist to a parametrised test:
[Theory] [InlineData(1234)] [InlineData(9876)] public void UserIsSavedIfItDoesNotExist(int userId) { var td = new Mock<IUserRepository>(); td.Setup(r => r.Read(userId)).Returns(new User { Id = 0 }); var sut = new SomeController(td.Object); sut.GetUser(userId); td.Verify(r => r.Create(userId)); }
There's no reason to edit the other test method; this should be enough to elicit a change to the SUT:
public User GetUser(int userId) { var u = this.userRepository.Read(userId); if (u.Id == 0) this.userRepository.Create(userId); return u; }
When you use Mocks (or, rather, Spies) and Stubs the Data Flow Verification technique is useful.
On the other hand, I no longer use Spies or Stubs since they tend to break encapsulation.
Fake #
These days, I tend to only model real application dependencies as Test Doubles, and when I do, I use Fakes.

While the article series From interaction-based to state-based testing goes into more details, I think that this small example is a good opportunity to demonstrate the technique.
The IUserRepository interface is defined like this:
public interface IUserRepository { User Read(int userId); void Create(int userId); }
A typical Fake is an in-memory collection:
public sealed class FakeUserRepository : Collection<User>, IUserRepository { public void Create(int userId) { Add(new User { Id = userId }); } public User Read(int userId) { var user = this.SingleOrDefault(u => u.Id == userId); if (user == null) return new User { Id = 0 }; return user; } }
In my experience, they're typically easy to implement by inheriting from a collection base class. Such an object exhibits typical traits of a Fake object: It fulfils the implied contract, but it lacks some of the 'ilities'.
The contract of a Repository is typically that if you add an Entity, you'd expect to be able to retrieve it later. If the Repository offers a Delete method (this one doesn't), you'd expect the deleted Entity to be gone, so that you can't retrieve it. And so on. The FakeUserRepository class fulfils such a contract.
On the other hand, you'd also expect a proper Repository implementation to support more than that:
- You'd expect a proper implementation to persist data so that you can reboot or change computers without losing data.
- You'd expect a proper implementation to correctly handle multiple threads.
- You may expect a proper implementation to support ACID transactions.
The FakeUserRepository does none of that, but in the context of a unit test, it doesn't matter. The data exists as long as the object exists, and that's until it goes out of scope. As long as a test needs the Repository, it remains in scope, and the data is there.
Likewise, each test runs in a single thread. Even when tests run in parallel, each test has its own Fake object, so there's no shared state. Therefore, even though FakeUserRepository isn't thread-safe, it doesn't have to be.
Testing with the Fake #
You can now rewrite the tests to use FakeUserRepository:
[Theory] [InlineData(1234)] [InlineData(9876)] public void GetUserReturnsCorrectValue(int userId) { var expected = new User { Id = userId }; var db = new FakeUserRepository { expected }; var sut = new SomeController(db); var actual = sut.GetUser(userId); Assert.Equal(expected, actual); } [Theory] [InlineData(1234)] [InlineData(9876)] public void UserIsSavedIfItDoesNotExist(int userId) { var db = new FakeUserRepository(); var sut = new SomeController(db); sut.GetUser(userId); Assert.Single(db, u => u.Id == userId); }
Instead of asking a Spy whether or not a particular method was called (which is an implementation detail), the UserIsSavedIfItDoesNotExist test verifies the posterior state of the database.
Conclusion #
In my experience, using Fakes simplifies unit tests. While you may have to edit the Fake implementation from time to time, you edit that code in a single place. The alternative is to edit all affected tests, every time you change something about a dependency. This is also known as Shotgun Surgery and considered an antipattern.
The code base that accompanies my book Code That Fits in Your Head has more realistic examples of this technique, and much else.
NonEmpty catamorphism
The universal API for generic non-empty collections, with examples in C# and Haskell.
This article is part of an article series about catamorphisms. A catamorphism is a universal abstraction that describes how to digest a data structure into a potentially more compact value.
I was recently doing some work that required a data structure like a collection, but with the additional constraint that it should be guaranteed to have at least one element. I've known about Haskell's NonEmpty type, and how to port it to C# for years. This time I needed to implement it in a third language, and since I had a little extra time available, I thought it'd be interesting to pursue a conjecture of mine: It seems as though you can implement most (all?) of a generic data structure's API based on its catamorphism.
While I could make a guess as to how a catamorphism might look for a non-empty collection, I wasn't sure. A quick web search revealed nothing conclusive, so I decided to deduce it from first principles. As this article series demonstrates, you can derive the catamorphism from a type's isomorphic F-algebra.
The beginning of this article presents the catamorphism in C#, with an example. The rest of the article describes how to deduce the catamorphism. This part of the article presents my work in Haskell. Readers not comfortable with Haskell can just read the first part, and consider the rest of the article as an optional appendix.
C# catamorphism #
This article will use a custom C# class called NonEmptyCollection<T>, which is near-identical to the NotEmptyCollection<T> originally introduced in the article Semigroups accumulate.
I don't know why I originally chose to name the class NotEmptyCollection instead of NonEmptyCollection, but it's annoyed me ever since. I've finally decided to rectify that mistake, so from now on, the name is NonEmptyCollection.
The catamorphism for NonEmptyCollection is this instance method:
public TResult Aggregate<TResult>(Func<T, IReadOnlyCollection<T>, TResult> algebra) { return algebra(Head, Tail); }
Because the NonEmptyCollection class is really just a glorified tuple, the algebra is any function which produces a single value from the two constituent values.
It's easy to fall into the trap of thinking of the catamorphism as 'reducing' the data structure to a more compact form. While this is a common kind of operation, loss of data is not inevitable. You can, for example, return a new collection, essentially doing nothing:
var nec = new NonEmptyCollection<int>(42, 1337, 2112, 666); var same = nec.Aggregate((x, xs) => new NonEmptyCollection<int>(x, xs.ToArray()));
This Aggregate method enables you to safely find a maximum value:
var nec = new NonEmptyCollection<int>(42, 1337, 2112, 666); var max = nec.Aggregate((x, xs) => xs.Aggregate(x, Math.Max));
or to safely calculate an average:
var nec = new NonEmptyCollection<int>(42, 1337, 2112, 666); var average = nec.Aggregate((x, xs) => xs.Aggregate(x, (a, b) => a + b) / (xs.Count + 1.0));
Both of these two last examples use the built-in Aggregate function to accumulate the xs. It uses the overload that takes a seed, for which it supplies x. This means that there's guaranteed to be at least that one value.
The catamorphism given here is not unique. You can create a trivial variation by swapping the two function arguments, so that x comes after xs.
NonEmpty F-algebra #
As in the previous article, I'll use Fix and cata as explained in Bartosz Milewski's excellent article on F-algebras.
As always, start with the underlying endofunctor:
data NonEmptyF a c = NonEmptyF { head :: a, tail :: ListFix a } deriving (Eq, Show, Read) instance Functor (NonEmptyF a) where fmap _ (NonEmptyF x xs) = NonEmptyF x xs
Instead of using Haskell's standard list ([]) for the tail, I've used ListFix from the article on list catamorphism. This should, hopefully, demonstrate how you can build on already established definitions derived from first principles.
Since a non-empty collection is really just a glorified tuple of head and tail, there's no recursion, and thus, the carrier type c is not used. You could argue that going through all of these motions is overkill, but it still provides some insights. This is similar to the Boolean catamorphism and Maybe catamorphism.
The fmap function ignores the mapping argument (often called f), since the Functor instance maps NonEmptyF a c to NonEmptyF a c1, but the c or c1 type is not used.
As was the case when deducing the recent catamorphisms, Haskell isn't too happy about defining instances for a type like Fix (NonEmptyF a). To address that problem, you can introduce a newtype wrapper:
newtype NonEmptyFix a = NonEmptyFix { unNonEmptyFix :: Fix (NonEmptyF a) } deriving (Eq, Show, Read)
You can define Functor, Applicative, Monad, etc. instances for this type without resorting to any funky GHC extensions. Keep in mind that, ultimately, the purpose of all this code is just to figure out what the catamorphism looks like. This code isn't intended for actual use.
A helper function makes it easier to define NonEmptyFix values:
createNonEmptyF :: a -> ListFix a -> NonEmptyFix a createNonEmptyF x xs = NonEmptyFix $ Fix $ NonEmptyF x xs
Here's how to use it:
ghci> createNonEmptyF 42 $ consF 1337 $ consF 2112 nilF
NonEmptyFix {
unNonEmptyFix = Fix (NonEmptyF 42 (ListFix (Fix (ConsF 1337 (Fix (ConsF 2112 (Fix NilF)))))))}
While this is quite verbose, keep in mind that the code shown here isn't meant to be used in practice. The goal is only to deduce catamorphisms from more basic universal abstractions, and you now have all you need to do that.
Haskell catamorphism #
At this point, you have two out of three elements of an F-Algebra. You have an endofunctor (NonEmptyF a), and an object c, but you still need to find a morphism NonEmptyF a c -> c. Notice that the algebra you have to find is the function that reduces the functor to its carrier type c, not the 'data type' a. This takes some time to get used to, but that's how catamorphisms work. This doesn't mean, however, that you get to ignore a, as you'll see.
As in the previous articles, start by writing a function that will become the catamorphism, based on cata:
nonEmptyF = cata alg . unNonEmptyFix where alg (NonEmptyF x xs) = undefined
While this compiles, with its undefined implementation of alg, it obviously doesn't do anything useful. I find, however, that it helps me think. How can you return a value of the type c from alg? You could pass a function argument to the nonEmptyF function and use it with x and xs:
nonEmptyF :: (a -> ListFix a -> c) -> NonEmptyFix a -> c nonEmptyF f = cata alg . unNonEmptyFix where alg (NonEmptyF x xs) = f x xs
This works. Since cata has the type Functor f => (f a -> a) -> Fix f -> a, that means that alg has the type f a -> a. In the case of NonEmptyF, the compiler infers that the alg function has the type NonEmptyF a c -> c1, which fits the bill, since c may be the same type as c1.
This, then, is the catamorphism for a non-empty collection. This one is just a single function. It's still not the only possible catamorphism, since you could trivially flip the arguments to f.
I've chosen this representation because the arguments x and xs are defined in the same order as the order of head before tail. Notice how this is the same order as the above C# Aggregate method.
Basis #
You can implement most other useful functionality with nonEmptyF. Here's the Semigroup instance and a useful helper function:
toListFix :: NonEmptyFix a -> ListFix a toListFix = nonEmptyF consF instance Semigroup (NonEmptyFix a) where xs <> ys = nonEmptyF (\x xs' -> createNonEmptyF x $ xs' <> toListFix ys) xs
The implementation uses nonEmptyF to operate on xs. Inside the lambda expression, it converts ys to a list, and uses the ListFix Semigroup instance to concatenate xs with it.
Here's the Functor instance:
instance Functor NonEmptyFix where fmap f = nonEmptyF (\x xs -> createNonEmptyF (f x) $ fmap f xs)
Like the Semigroup instance, this fmap implementation uses fmap on xs, which is the ListFix Functor instance.
The Applicative instance is much harder to write from scratch (or, at least, I couldn't come up with a simpler way):
instance Applicative NonEmptyFix where pure x = createNonEmptyF x nilF liftA2 f xs ys = nonEmptyF (\x xs' -> nonEmptyF (\y ys' -> createNonEmptyF (f x y) (liftA2 f (consF x nilF) ys' <> liftA2 f xs' (consF y ys'))) ys) xs
While that looks complicated, it's not that bad. It uses nonEmptyF to 'loop' over the xs, and then a nested call to nonEmptyF to 'loop' over the ys. The inner lambda expression uses f x y to calculate the head, but it also needs to calculate all other combinations of values in xs and ys.
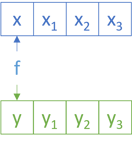
First, it keeps x fixed and 'loops' through all the remaining ys'; that's the liftA2 f (consF x nilF) ys' part:
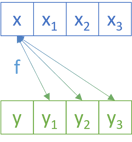
Then it 'loops' over all the remaining xs' and all the ys; that is, liftA2 f xs' (consF y ys').
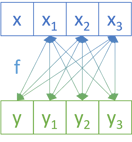
The two liftA2 functions apply to the ListFix Applicative instance.
You'll be happy to see, I think, that the Monad instance is simpler:
instance Monad NonEmptyFix where xs >>= f = nonEmptyF (\x xs' -> nonEmptyF (\y ys -> createNonEmptyF y $ ys <> (xs' >>= toListFix . f)) (f x)) xs
And fortunately, Foldable and Traversable are even simpler:
instance Foldable NonEmptyFix where foldr f seed = nonEmptyF (\x xs -> f x $ foldr f seed xs) instance Traversable NonEmptyFix where traverse f = nonEmptyF (\x xs -> liftA2 createNonEmptyF (f x) (traverse f xs))
Finally, you can implement conversions to and from the NonEmpty type from Data.List.NonEmpty:
toNonEmpty :: NonEmptyFix a -> NonEmpty a toNonEmpty = nonEmptyF (\x xs -> x :| toList xs) fromNonEmpty :: NonEmpty a -> NonEmptyFix a fromNonEmpty (x :| xs) = createNonEmptyF x $ fromList xs
This demonstrates that NonEmptyFix is isomorphic to NonEmpty.
Conclusion #
The catamorphism for a non-empty collection is a single function that produces a single value from the head and the tail of the collection. While it's possible to implement a 'standard fold' (foldr in Haskell), the non-empty catamorphism doesn't require a seed to get started. The data structure guarantees that there's always at least one value available, and this value can then be use to 'kick off' a fold.
In C# one can define the catamorphism as the above Aggregate method. You could then define all other instance functions based on Aggregate.
Next: Either catamorphism.
Test-driving the pyramid's top
Some thoughts on TDD related to integration and systems testing.
My recent article Works on most machines elicited some responses. Upon reflection, it seems that most of the responses relate to the top of the Test Pyramid.
While I don't have an one-shot solution that addresses all concerns, I hope that nonetheless I can suggest some ideas and hopefully inspire a reader or two. That's all. I intend nothing of the following to be prescriptive. I describe my own professional experience: What has worked for me. Perhaps it could also work for you. Use the ideas if they inspire you. Ignore them if you find them impractical.
The Test Pyramid #
The Test Pyramid is often depicted like this:
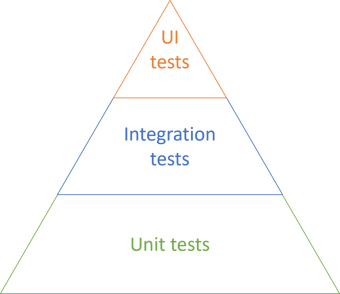
This seems to indicate that while the majority of tests should be unit tests, you should also have a substantial number of integration tests, and quite a few UI tests.
Perhaps the following is obvious, but the Test Pyramid is an idea; it's a way to communicate a concept in a compelling way. What one should take away from it, I think, is only this: The number of tests in each category should form a total order, where the unit test category is the maximum. In other words, you should have more unit tests than you have tests in the next category, and so on.
No-one says that you can only have three levels, or that they have to have the same height. Finally, the above figure isn't even a pyramid, but rather a triangle.
I sometimes think of the Test Pyramid like this:
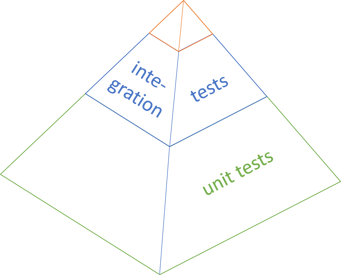
To be honest, it's not so much whether or not the pyramid is shown in perspective, but rather that the unit test base is significantly more voluminous than the other levels, and that the top is quite small.
Levels #
In order to keep the above discussion as recognisable as possible, I've used the labels unit tests, integration tests, and UI tests. It's easy to get caught up in a discussion about how these terms are defined. Exactly what is a unit test? How does it differ from an integration test?
There's no universally accepted definition of a unit test, so it tends to be counter-productive to spend too much time debating the finer points of what to call the tests in each layer.
Instead, I find the following criteria useful:
- In-process tests
- Tests that involve more than one process
- Tests that can only be performed in production
I'll describe each in a little more detail. Along the way, I'll address some of the reactions to Works on most machines.
In-process tests #
The in-process category corresponds roughly to the Test Pyramid's unit test level. It includes 'traditional' unit tests such as tests of stand-alone functions or methods on objects, but also Facade Tests. The latter may involve multiple modules or objects, perhaps even from multiple libraries. Many people may call them integration tests because they integrate more than one module.
As long as an automated test runs in a single process, in memory, it tends to be fast and leave no persistent state behind. This is almost exclusively the kind of test I tend to test-drive. I often follow an outside-in TDD process, an example of which is shown in my book Code That Fits in Your Head.
Consider an example from the source code that accompanies the book:
[Fact] public async Task ReserveTableAtTheVaticanCellar() { using var api = new SelfHostedApi(); var client = api.CreateClient(); var timeOfDayLaterThanLastSeatingAtTheOtherRestaurants = TimeSpan.FromHours(21.5); var at = DateTime.Today.AddDays(433).Add( timeOfDayLaterThanLastSeatingAtTheOtherRestaurants); var dto = Some.Reservation.WithDate(at).ToDto(); var response = await client.PostReservation("The Vatican Cellar", dto); response.EnsureSuccessStatusCode(); }
I think of a test like this as an automated acceptance test. It uses an internal test-specific domain-specific language (test utilities) to exercise the REST service's API. It uses ASP.NET self-hosting to run both the service and the HTTP client in the same process.
Even though this may, at first glance, look like an integration test, it's an artefact of test-driven development. Since it does cut across both HTTP layer and domain model, some readers may think of it as an integration test. It uses a stateful in-memory data store, so it doesn't involve more than a single process.
Tests that span processes #
There are aspects of software that you can't easily drive with tests. I'll return to some really gnarly examples in the third category, but in between, we find concerns that are hard, but still possible to test. The reason that they are hard is often because they involve more than one process.
The most common example is data access. Many software systems save or retrieve data. With test-driven development, you're supposed to let the tests inform your API design decisions in such a way that everything that involves difficult, error-prone code is factored out of the data access layer, and into another part of the code that can be tested in process. This development technique ought to drain the hard-to-test components of logic, leaving behind a Humble Object.
One reaction to Works on most machines concerns exactly that idea:
"As a developer, you need to test HumbleObject's behavior."
It's almost tautologically part of the definition of a Humble Object that you're not supposed to test it. Still, realistically, ladeak has a point.
When I wrote the example code to Code That Fits in Your Head, I applied the Humble Object pattern to the data access component. For a good while, I had a SqlReservationsRepository class that was so simple, so drained of logic, that it couldn't possibly fail.
Until, of course, the inevitable happened: There was a bug in the SqlReservationsRepository code. Not to make a long story out of it, but even with a really low cyclomatic complexity, I'd accidentally swapped two database columns when reading from a table.
Whenever possible, when I discover a bug, I first write an automated test that exposes that bug, and only then do I fix the problem. This is congruent with my lean bias. If a defect can occur once, it can occur again in the future, so it's better to have a regression test.
The problem with this bug is that it was in a Humble Object. So, ladeak is right. Sooner or later, you'll have to test the Humble Object, too.
That's when I had to bite the bullet and add a test library that tests against the database.
One such test looks like this:
[Theory] [InlineData(Grandfather.Id, "2022-06-29 12:00", "e@example.gov", "Enigma", 1)] [InlineData(Grandfather.Id, "2022-07-27 11:40", "c@example.com", "Carlie", 2)] [InlineData(2, "2021-09-03 14:32", "bon@example.edu", "Jovi", 4)] public async Task CreateAndReadRoundTrip( int restaurantId, string at, string email, string name, int quantity) { var expected = new Reservation( Guid.NewGuid(), DateTime.Parse(at, CultureInfo.InvariantCulture), new Email(email), new Name(name), quantity); var connectionString = ConnectionStrings.Reservations; var sut = new SqlReservationsRepository(connectionString); await sut.Create(restaurantId, expected); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual); }
The entire test runs in a special context where a database is automatically created before the test runs, and torn down once the test has completed.
"When building such behavior, you can test against a shared instance of the service in your dev team or run that service on your dev machine in a container."
Yes, those are two options. A third, in the spirit of GOOS, is to strongly favour technologies that support automation. Believe it or not, you can automate SQL Server. You don't need a Docker container for it. That's what I did in the above test.
I can see how a Docker container with an external dependency can be useful too, so I'm not trying to dismiss that technology. The point is, however, that simpler alternatives may exist. I, and others, did test-driven development for more than a decade before Docker existed.
Tests that can only be performed in production #
The last category of tests are those that you can only perform on a production system. What might be examples of that?
I've run into a few over the years. One such test is what I call a Smoke Test: Metaphorically speaking, turn it on and see if it develops smoke. These kinds of tests are good at catching configuration errors. Does the web server have the right connection string to the database? A test can verify whether that's the case, but it makes no sense to run such a test on a development machine, or against a test system, or a staging environment. You want to verify that the production system is correctly configured. Only a test against the production system can do that.
For every configuration value, you may want to consider a Smoke Test.
There are other kinds of tests you can only perform in production. Sometimes, it's not technical concerns, but rather legal or financial constraints, that dictate circumstances.
A few years ago I worked with a software organisation that, among other things, integrated with the Danish personal identification number system (CPR). Things may have changed since, but back then, an organisation had to have a legal agreement with CPR before being granted access to its integration services. It's an old system (originally from 1968) with a proprietary data integration protocol.
We test-drove a parser of the data format, but that still left behind a Humble Object that would actually perform the data transfers. How do we test that Humble Object?
Back then, at least, there was no test system for the CPR service, and it was illegal to query the live system unless you had a business reason. And software testing did not constitute a legal reason.
The only legal option was to make the Humble Object as simple and foolproof as possible, and then observe how it worked in actual production situations. Containers wouldn't help in such a situation.
It's possible to write automated tests against production systems, but unless you're careful, they're difficult to write and maintain. At least, go easy on the assertions, since you can't assume much about the run-time data and behaviour of a live system. Smoke tests are mostly just 'pings', so can be written to be fairly maintenance-free, but you shouldn't need many of them.
Other kinds of tests against production are likely to be fragile, so it pays to minimise their number. That's the top of the pyramid.
User interfaces #
I no longer develop user interfaces, so take the following with a pinch of salt.
The 'original' Test Pyramid that I've depicted above has UI tests at the pyramid's top. That doesn't necessarily match the categories I've outlined here; don't assume parity.
A UI test may or may not involve more than one process, but they are often difficult to maintain for other reasons. Perhaps this is where the pyramid metaphor starts to break down. All models are wrong, but some are useful.
Back when I still programmed user interfaces, I'd usually test-drive them via a subcutaneous API, and rely on some variation of MVC to keep the rendered controls in sync. Still, once in a while, you need to verify that the user interface looks as it's supposed to. Often, the best tool for that job is the good old Mark I Eyeball.
This still means that you need to run the application from time to time.
"Docker is also very useful for enabling others to run your software on their machines. Recently, we've been exploring some apps that consisted of ~4 services (web servers) and a database. All of them written in different technologies (PHP, Java, C#). You don't have to setup environment variables. You don't need to have relevant SDKs to build projects etc. Just run docker command, and spin them instantly on your PC."
That sounds like a reasonable use case. I've never found myself in such circumstances, but I can imagine the utility that containers offer in a situation like that. Here's how I envision the scenario:
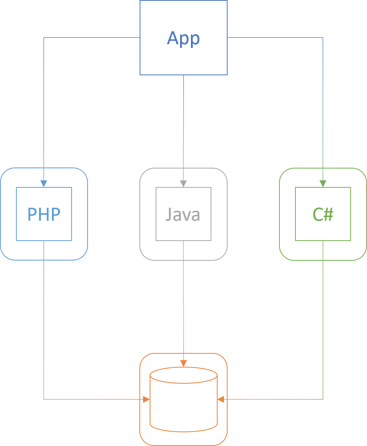
The boxes with rounded corners symbolise containers.
Again, my original goal with the previous article wasn't to convince you that container technologies are unequivocally bad. Rather, it was to suggest that test-driven development (TDD) solves many of the problems that people seem to think can only be solved with containers. Since TDD has many other beneficial side effects, it's worth considering instead of mindlessly reaching for containers, which may represent only a local maximum.
How could TDD address qfilip's concern?
When I test-drive software, I favour real dependencies, and I favour Fake objects over Mocks and Stubs. Were I to return to user-interface programming today, I'd define its external dependencies as one or more interfaces, and implement a Fake Object for each.
Not only will this enable me to simulate the external dependencies with the Fakes. If I implement the Fakes as part of the production code, I'd even be able to spin up the system, using the Fakes instead of the real system.

A Fake is an implementation that 'almost works'. A common example is an in-memory collection instead of a database. It's neither persistent nor thread-safe, but it's internally consistent. What you add, you can retrieve, until you delete it again. For the purposes of starting the app in order to verify that the user interface looks correct, that should be good enough.
Another related example is NServiceBus, which comes with a file transport that is clearly labeled as not for production use. While it's called the Learning Transport, it's also useful for exploratory testing on a development machine. While this example clearly makes use of an external resource (the file system), it illustrates how a Fake implementation can alleviate the need for a container.
Uses for containers #
Ultimately, it's still useful to be able to stand up an entire system, as qfilip suggests, and if containers is a good way to do that, it doesn't bother me. At the risk of sounding like a broken record, I never intended to say that containers are useless.
When I worked as a Software Development Engineer in Microsoft, I had two computers: A laptop and a rather beefy tower PC. I've always done all programming on laptops, so I repurposed the tower as a virtual server with all my system's components on separate virtual machines (VM). The database in one VM, the application server in another, and so on. I no longer remember what all the components were, but I seem to recall that I had four VMs running on that one box.
While I didn't use it much, I found it valuable to occasionally verify that all components could talk to each other on a realistic network topology. This was in 2008, and Docker wasn't around then, but I could imagine it would have made that task easier.
I don't dispute that Docker and Kubernetes are useful, but the job of a software architect is to carefully identify the technologies on which a system should be based. The more technology dependencies you take on, the more rigid the design.
After a few decades of programming, my experience is that as a programmer and architect, I can find better alternatives than depending on container technologies. If testers and IT operators find containers useful to do their jobs, then that's fine by me. Since my code works on most machines, it works in containers, too.
Truly Humble Objects #
One last response, and I'll wrap this up.
"As a developer, you need to test HumbleObject's behavior. What if a DatabaseConnection or a TCP conn to a message queue is down?"
How should such situations be handled? There may always be special cases, but in general, I can think of two reactions:
- Log the error
- Retry the operation
Assuming that the Humble Object is a polymorphic type (i.e. inherits a base class or implements an interface), you should be able to extract each of these behaviours to general-purpose components.
In order to log errors, you can either use a Decorator or a global exception handler. Most frameworks provide a way to catch (otherwise) unhandled exceptions, exactly for this purpose, so you don't have to add such functionality to a Humble Object.
Retry logic can also be delegated to a third-party component. For .NET I'd start looking at Polly, but I'd be surprised if other platforms don't have similar libraries that implement the stability patterns from Release It.
Something more specialised, like a fail-over mechanism, sounds like a good reason to wheel out the Chain of Responsibility pattern.
All of these can be tested independently of any Humble Object.
Conclusion #
In a recent article I reflected on my experience with TDD and speculated that a side effect of that process is code flexible enough to work on most machines. Thus, I've never encountered the need for a containers.
Readers responded with comments that struck me as mostly related to the upper levels of the Test Pyramid. In this article, I've attempted to address some of those concerns. I still get by without containers.
Is software getting worse?
A rant, with some examples.
I've been a software user for thirty years.
My first PC was DOS-based. In my first job, I used OS/2, in the next, Windows 3.11, NT, and later incarnations of Windows.
I wrote my first web sites in Arachnophilia, and my first professional software in Visual Basic, Visual C++, and Visual InterDev.
I used Terminate with my first modem. If I recall correctly, it had a built-in email downloader and offline reader. Later, I switched to Outlook for email. I've used Netscape Navigator, Internet Explorer, Firefox, and Chrome to surf the web.
I've written theses, articles, reports, etc. in Word Perfect for DOS and MS Word for Windows. I wrote my new book Code That Fits In your Head in TexStudio. Yes, it was written entirely in LaTeX.
Updates #
For the first fifteen years, new software version were rare. You'd get a version of AutoCAD, Windows, or Visual C++, and you'd use it for years. After a few years, a new version would come out, and that would be a big deal.
Interim service releases were rare, too, since there was no network-based delivery mechanism. Software came on floppy disks, and later on CDs.
Even if a bug fix was easy to make, it was difficult for a software vendor to distribute it, so most software releases were well-tested. Granted, software had bugs back then, and some of them you learned to work around.
When a new version came out, the same forces were at work. The new version had to be as solid and stable as the previous one. Again, I grant that once in a while, even in those days, this wasn't always the case. Usually, a bad release spelled the demise of a company, because release times were so long that competitors could take advantage of a bad software release.
Usually, however, software updates were improvements, and you looked forward to them.
Decay #
I no longer look forward to updates. These days, software is delivered over the internet, and some applications update automatically.
From a security perspective it can be a good idea to stay up-to-date, and for years, I diligently did that. Lately, however, I've become more conservative. Particularly when it comes to Windows, I ignore all suggestions to update it until it literally forces the update on me.
Just like even-numbered Star Trek movies don't suck the same pattern seems to be true for Windows: Windows XP was good, Windows 7 was good, and Windows 10 wasn't bad either. I kept putting off Windows 11 for as long as possible, but now I use it, and I can't say that I'm surprised that I don't like it.
This article, however, isn't a rant about Windows in particular. This seems to be a general trend, and it's been noticeable for years.
Examples #
I think that the first time I noticed a particular application degrading was Vivino. It started out as a local company here in Copenhagen, and I was a fairly early adopter. Initially, it was great: If you like wine, but don't know that much about it, you could photograph a bottle's label, and it'd automatically recognise the wine and register it in your 'wine library'. I found it useful that I could look up my notes about a wine I'd had a year ago to remind me what I thought of it. As time went on, however, I started to notice errors in my wine library. It might be double entries, or wines that were silently changed to another vintage, etc. Eventually it got so bad that I lost trust in the application and uninstalled it.
Another example is Sublime Text, which I used for writing articles for this blog. I even bought a licence for it. Version 3 was great, but version 4 was weird from the outset. One thing was that they changed how they indicated which parts of a file I'd edited after opening it, and I never understood the idea behind the visuals. Worse was that auto-closing of HTML stopped working. Since I'm that weird dude who writes raw HTML, such a feature is quite important to me. If I write an HTML tag, I expect the editor to automatically add the closing tag, and place my cursor between the two. Sublime Text stopped doing that consistently, and eventually it became annoying enough that I though: Why bother? Now I write in Visual Studio Code.
Microsoft is almost a chapter in itself, but to be fair, I don't consider Microsoft products worse than others. There's just so much of it, and since I've always been working in the Microsoft tech stack, I use a lot of it. Thus, selection bias clearly is at work here. Still, while I don't think Microsoft is worse than the competition, it seems to be part of the trend.
For years, my login screen was stuck on the same mountain lake, even though I tried every remedy suggested on the internet. Eventually, however, a new version of Windows fixed the issue. So, granted, sometimes new versions improve things.
Now, however, I have another problem with Windows Spotlight. It shows nice pictures, and there used to be an option to see where the picture was taken. Since I repaved my machine, this option is gone. Again, I've scoured the internet for resolutions to this problem, but neither rebooting, regedit changes, etc. has so far solved the problem.
That sounds like small problems, so let's consider something more serious. Half a year ago, Outlook used to be able to detect whether I was writing an email in English or Danish. It could even handle the hybrid scenario where parts of an email was in English, and parts in Danish. Since I repaved my machine, this feature no longer works. Outlook doesn't recognise Danish when I write it. One thing are the red squiggly lines under most words, but that's not even the worst. The worst part of this is that even though I'm writing in Danish, outlook thinks I'm writing in English, so it silently auto-corrects Danish words to whatever looks adjacent in English.
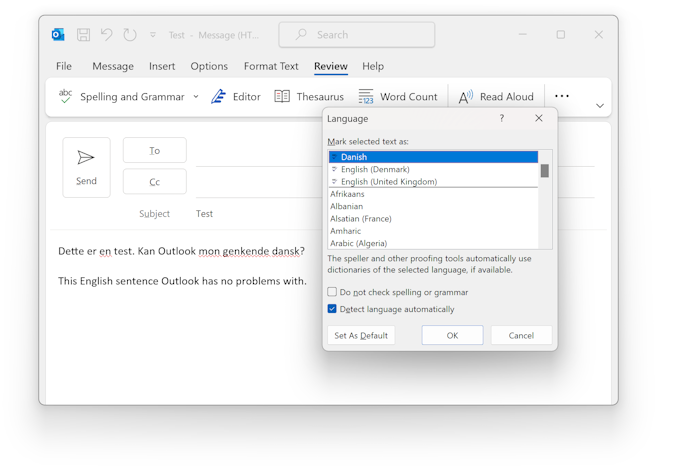
This became so annoying that I contacted Microsoft support about it, but while they had me try a number of things, nothing worked. They eventually had to give up and suggested that I reinstalled my machine - which, at that point, I'd done two weeks before.
This used to work, but now it doesn't.
It's not all bad #
I could go on with other examples, but I think that this suffices. After all, I don't think it makes for a compelling read.
Of course, not everything is bad. While it looks as though I'm particularly harping on Microsoft, I rarely detect problems with Visual Studio or Code, and I usually install updates as soon as they are available. The same is true for much other software I use. Paint.NET is awesome, MusicBee is solid, and even the Sonos Windows app, while horrific, is at least consistently so.
Conclusion #
It seems to me that some software is actually getting worse, and that this is a more recent trend.
The point isn't that some software is bad. This has always been the case. What seems new to me is that software that used to be good deteriorates. While this wasn't entirely unheard of in the nineties (I'm looking at you, WordPerfect), this is becoming much more noticeable.
Perhaps it's just frequency illusion, or perhaps it's because I use software much more than I did in the nineties. Still, I can't shake the feeling that some software is deteriorating.
Why does this happen? I don't know, but my own bias suggests that it's because there's less focus on regression testing. Many of the problems I see look like regression bugs to me. A good engineering team could have caught them with automated regression tests, but these days, it seems as though many teams rely on releasing often and then letting users do the testing.
The problem with that approach, however, is that if you don't have good automated tests, fixing one regression may resurrect another.
Comments
I don't think your perception that software is getting worse is wrong, Mark. I've been an Evernote user since 2011. And, for a good portion of those years, I've been a paid customer.
I'm certainly not alone in my perception that the application is becoming worse with each new release, to the point of, at times, becoming unusable. Syncing problems with the mobile version, weird changes in the UI that don't accomplish anything, general sluggishness, and, above all, not listening to the users regarding long-needed features.
Works on most machines
TDD encourages deployment flexibility. Functional programming also helps.
Recently several of the podcasts I subscribe to have had episodes about various container technologies, of which Kubernetes dominates. I tune out of such content, since it has nothing to do with me.
I've never found containerisation relevant. I remember being fascinated when I first heard of Docker, and for a while, I awaited a reason to use it. It never materialised.
I'd test-drive whatever system I was working on, and deploy it to production. Usually, it'd just work.
Since my process already produced good results, why make it more complicated?
Occasionally, I would become briefly aware of the lack of containers in my life, but then I'd forget about it again. Until now, I haven't thought much about it, and it's probably only the random coincidence of a few podcast episodes back-to-back that made me think more about it.
Be liberal with what system you run on #
When I was a beginner programmer a few years ago, things were different. I'd write code that worked on my machine, but not always on the test server.
As I gained experience, this tended to happen less often. This doubtlessly have multiple causes, and increased experience is likely one of them, but I also think that my interest in loose coupling and test-driven development plays a role.
Increasingly I developed an ethos of writing software that would work on most machines, instead of only my own. It seems reminiscent of Postel's law: Be liberal with what system you run on.
Test-driven development helps in that regard, because you write code that must be able to execute in at least two contexts: The test context, and the actual system context. These two contexts both exist on your machine.
A colleague once taught me: The most difficult generalisation step is going from one to two. Once you've generalised to two cases, it's much easier to generalise to three, four, or n cases.
It seems to me that such from-one-to-two-cases generalisation is an inadvertent by-product of test-driven development. Once your code already matches two different contexts, making it even more flexible isn't that much extra work. It's not even speculative generality because you also need to make it work on the production system and (one hopes) on a build server or continuous delivery pipeline. That's 3-4 contexts. Odds are that software that runs successfully in four separate contexts runs successfully on many more systems.
General-purpose modules #
In A Philosophy of Software Design John Ousterhout argues that one should aim for designing general-purpose objects or modules, rather than specialised APIs. He calls them deep modules and their counterparts shallow modules. On the surface, this seems to go against the grain of YAGNI, but the way I understand the book, the point is rather that general-purpose solutions also solve special cases, and, when done right, the code doesn't have to be more complicated than the one that handles the special case.
As I write in my review of the book, I think that there's a connection with test-driven development. General-purpose code is code that works in more than one situation, including automated testing environments. This is almost tautological. If it doesn't work in an automated test, an argument could be made that it's insufficiently general.
Likewise, general-purpose software should be able to work when deployed to more than one machine. It should even work on machines where other versions of that software already exist.
When you have general-purpose software, though, do you really need containers?
Isolation #
While I've routinely made use of test-driven development since 2003, I started my shift towards functional programming around ten years later. I think that this has amplified my code's flexibility.
As Jessica Kerr pointed out years ago, a corollary of referential transparency is that pure functions are isolated from their environment. Only input arguments affect the output of a pure function.
Ultimately, you may need to query the environment about various things, but in functional programming, querying the environment is impure, so you push it to the boundary of the system. Functional programming encourages you to explicitly consider and separate impure actions from pure functions. This implies that the environment-specific code is small, cohesive, and easy to review.
Conclusion #
For a while, when Docker was new, I expected it to be a technology that I'd eventually pick up and make part of my tool belt. As the years went by, that never happened. As a programmer, I've never had the need.
I think that a major contributor to that is that since I mostly develop software with test-driven development, the resulting software is already robust or flexible enough to run in multiple environments. Adding functional programming to the mix helps to achieve isolation from the run-time environment.
All of this seems to collaborate to enable code to work not just on my machine, but on most machines. Including containers.
Perhaps there are other reasons to use containers and Kubernetes. In a devops context, I could imagine that it makes deployment and operations easier. I don't know much about that, but I also don't mind. If someone wants to take the code I've written and run it in a container, that's fine. It's going to run there too.
Comments
Commenting for the first time. I hope I made these changes in proper manner. Anyway...
Kubernetes usually also means the usage of cloud infrastructure, and as such, it can be automated (and change-tracked) in various interesting ways. Is it worth it? Well, that depends as always... Docker isn't the only container technology supported by k8s, but since it's the most popular one... they go hand in hand.
Docker is also very useful for enabling others to run your software on their machines. Recently, we've been exploring some apps that consisted of ~4 services (web servers) and a database. All of them written in different technologies (PHP, Java, C#). You don't have to setup environment variables. You don't need to have relevant SDKs to build projects etc. Just run docker command, and spin them instantly on your PC.
So there's that...
Unrelated to the topic above, I'd like to ask you, if you could write an article on the specific subject. Or, if the answer is short, comment me back. As an F# enthusiast, I find yours and Scott's blog very valuable. One thing I've failed to find here is why you don't like ORMs. I think the words were they solve a problem that we shouldn't have in the first place. Since F# doesn't play too well with Entity Framework, and I pretty much can't live without it... I'm curious if I'm missing something. A different approach, way of thinking. I can work with raw SQL ofcourse... but the mapping... oh the mapping...
I'm contemplating turning my response into a new article, but it may take some time before I get to it. I'll post here once I have a more thorough response.
qfilip, thank you for writing. I've now published the article that, among many other things, respond to your comment about containers.
I'll get back to your question about ORMs as soon as possible.
I'm still considering how to best address the question about ORMs, but in the meanwhile, I'd like to point interested readers to Ted Neward's famous article The Vietnam of Computer Science.
Finally, I'm happy to announce that I've written an article trying to explain my position: Do ORMs reduce the need for mapping?.
AI for doc comments
A solution in search of a problem?
I was recently listening to a podcast episode where the guest (among other things) enthused about how advances in large language models mean that you can now get these systems to write XML doc comments.
You know, these things:
/// <summary> /// Scorbles a dybliad. /// </summary> /// <param name="dybliad">The dybliad to scorble.</param> /// <param name="flag"> /// A flag that controls wether scorbling is done pre- or postvotraid. /// </param> /// <returns>The scorbled dybliad.</returns> public string Scorble(string dybliad, bool flag)
And it struck me how that's not the first time I've encountered that notion. Finally, you no longer need to write those tedious documentation comments in your code. Instead, you can get Github Copilot or ChatGPT to write them for you.
When was the last time you wrote such comments?
I'm sure that there are readers who wrote some just yesterday, but generally, I rarely encounter them in the wild.
As a rule, I only write them when my modelling skills fail me so badly that I need to apologise in code. Whenever I run into such a situation, I may as well take advantage of the format already in place for such things, but it's not taking up a big chunk of my time.
It's been a decade since I ran into a code base where doc comments were mandatory. When I had to write comments, I'd use GhostDoc, which used heuristics to produce 'documentation' on par with modern AI tools.
Whether you use GhostDoc, Github Copilot, or write the comments yourself, most of them tend to be equally inane and vacuous. Good design only amplifies this quality. The better names you use, and the more you leverage the type system to make illegal states unrepresentable, the less you need the kind of documentation furnished by doc comments.
I find it striking that more than one person wax poetic about AI's ability to produce doc comments.
Is that, ultimately, the only thing we'll entrust to large language models?
I know that that they can do more than that, but are we going to let them? Or is automatic doc comments a solution in search of a problem?
Validating or verifying emails
On separating preconditions from business rules.
My recent article Validation and business rules elicited this question:
"Regarding validation should be pure function, lets have user registration as an example, is checking the email address uniqueness a validation or a business rule? It may not be pure since the check involves persistence mechanism."
This is a great opportunity to examine some heuristics in greater detail. As always, this mostly presents how I think about problems like this, and so doesn't represent any rigid universal truth.
The specific question is easily answered, but when the topic is email addresses and validation, I foresee several follow-up questions that I also find interesting.
Uniqueness constraint #
A new user signs up for a system, and as part of the registration process, you want to verify that the email address is unique. Is that validation or a business rule?
Again, I'm going to put the cart before the horse and first use the definition to answer the question.
Validation is a pure function that decides whether data is acceptable.
Can you implement the uniqueness constraint with a pure function? Not easily. What most systems would do, I'm assuming, is to keep track of users in some sort of data store. This means that in order to check whether or not a email address is unique, you'd have to query that database.
Querying a database is non-deterministic because you could be making multiple subsequent queries with the same input, yet receive differing responses. In this particular example, imagine that you ask the database whether ann.siebel@example.com is already registered, and the answer is no, that address is new to us.
Database queries are snapshots in time. All that answer tells you is that at the time of the query, the address would be unique in your database. While that answer travels over the network back to your code, a concurrent process might add that very address to the database. Thus, the next time you ask the same question: Is ann.siebel@example.com already registered? the answer would be: Yes, we already know of that address.
Verifying that the address is unique (most likely) involves an impure action, and so according to the above definition isn't a validation step. By the law of the the excluded middle, then, it must be a business rule.
Using a different rule of thumb, Robert C. Martin arrives at the same conclusion:
"Uniqueness is semantic not syntactic, so I vote that uniqueness is a business rule not a validation rule."
This highlights a point about this kind of analysis. Using functional purity is a heuristic shortcut to sorting verification problems. Those that are deterministic and have no side effects are validation problems, and those that are either non-deterministic or have side effects are not.
Being able to sort problems in this way is useful because it enables you to choose the right tool for the job, and to avoid the wrong tool. In this case, trying to address the uniqueness constraint with validation is likely to cause trouble.
Why is that? Because of what I already described. A database query is a snapshot in time. If you make a decision based on that snapshot, it may be the wrong decision once you reach a conclusion. Granted, when discussing user registration, the risk of several processes concurrently trying to register the same email address probably isn't that big, but in other domains, contention may be a substantial problem.
Being able to identify a uniqueness constraint as something that isn't validation enables you to avoid that kind of attempted solution. Instead, you may contemplate other designs. If you keep users in a relational database, the easiest solution is to put a uniqueness constraint on the Email column and let the database deal with the problem. Just be prepared to handle the exception that the INSERT statement may generate.
If you have another kind of data store, there are other ways to model the constraint. You can even do so using lock-free architectures, but that's out of scope for this article.
Validation checks preconditions #
Encapsulation is an important part of object-oriented programming (and functional programming as well). As I've often outlined, I base my understanding of encapsulation on Object-Oriented Software Construction. I consider contract (preconditions, invariants, and postconditions) essential to encapsulation.
I'll borrow a figure from my article Can types replace validation?:

The role of validation is to answer the question: Does the data make sense?
This question, and its answer, is typically context-dependent. What 'makes sense' means may differ. This is even true for email addresses.
When I wrote the example code for my book Code That Fits in Your Head, I had to contemplate how to model email addresses. Here's an excerpt from the book:
Email addresses are notoriously difficult to validate, and even if you had a full implementation of the SMTP specification, what good would it do you?
Users can easily give you a bogus email address that fits the spec. The only way to really validate an email address is to send a message to it and see if that provokes a response (such as the user clicking on a validation link). That would be a long-running asynchronous process, so even if you'd want to do that, you can't do it as a blocking method call.
The bottom line is that it makes little sense to validate the email address, apart from checking that it isn't null. For that reason, I'm not going to validate it more than I've already done.
In this example, I decided that the only precondition I would need to demand was that the email address isn't null. This was motivated by the operations I needed to perform with the email address - or rather, in this case, the operations I didn't need to perform. The only thing I needed to do with the address was to save it in a database and send emails:
public async Task EmailReservationCreated(int restaurantId, Reservation reservation) { if (reservation is null) throw new ArgumentNullException(nameof(reservation)); var r = await RestaurantDatabase.GetRestaurant(restaurantId).ConfigureAwait(false); var subject = $"Your reservation for {r?.Name}."; var body = CreateBodyForCreated(reservation); var email = reservation.Email.ToString(); await Send(subject, body, email).ConfigureAwait(false); }
This code example suggests why I made it a precondition that Email mustn't be null. Had null be allowed, I would have had to resort to defensive coding, which is exactly what encapsulation makes redundant.
Validation is a process that determines whether data is useful in a particular context. In this particular case, all it takes is to check the Email property on the DTO. The sample code that comes with Code That Fits in Your Head shows the basics, while An applicative reservation validation example in C# contains a more advanced solution.
Preconditions are context-dependent #
I would assume that a normal user registration process has little need to validate an ostensible email address. A system may want to verify the address, but that's a completely different problem. It usually involves sending an email to the address in question and have some asynchronous process register if the user verifies that email. For an article related to this problem, see Refactoring registration flow to functional architecture.
Perhaps you've been reading this with mounting frustration: How about validating the address according to the SMTP spec?
Indeed, that sounds like something one should do, but turns out to be rarely necessary. As already outlined, users can easily supply a bogus address like foo@bar.com. It's valid according to the spec, and so what? How does that information help you?
In most contexts I've found myself, validating according to the SMTP specification is a distraction. One might, however, imagine scenarios where it might be required. If, for example, you need to sort addresses according to user name or host name, or perform some filtering on those parts, etc. it might be warranted to actually require that the address is valid.
This would imply a validation step that attempts to parse the address. Once again, parsing here implies translating less-structured data (a string) to more-structured data. On .NET, I'd consider using the MailAddress class which already comes with built-in parser functions.
The point being that your needs determine your preconditions, which again determine what validation should do. The preconditions are context-dependent, and so is validation.
Conclusion #
Email addresses offer a welcome opportunity to discuss the difference between validation and verification in a way that is specific, but still, I hope, easy to extrapolate from.
Validation is a translation from one (less-structured) data format to another. Typically, the more-structured data format is an object, a record, or a hash map (depending on language). Thus, validation is determined by two forces: What the input data looks like, and what the desired object requires; that is, its preconditions.
Validation is always a translation with the potential for error. Some input, being less-structured, can't be represented by the more-structured format. In addition to parsing, a validation function must also be able to fail in a composable matter. That is, fortunately, a solved problem.
Validation and business rules
A definition of validation as distinguished from business rules.
This article suggests a definition of validation in software development. A definition, not the definition. It presents how I currently distinguish between validation and business rules. I find the distinction useful, although perhaps it's a case of reversed causality. The following definition of validation is useful because, if defined like that, it's a solved problem.
My definition is this:
Validation is a pure function that decides whether data is acceptable.
I've used the word acceptable because it suggests a link to Postel's law. When validating, you may want to allow for some flexibility in input, even if, strictly speaking, it's not entirely on spec.
That's not, however, the key ingredient in my definition. The key is that validation should be a pure function.
While this may sound like an arbitrary requirement, there's a method to my madness.
Business rules #
Before I explain the benefits of the above definition, I think it'll be useful to outline typical problems that developers face. My thesis in Code That Fits in Your Head is that understanding limits of human cognition is a major factor in making a code base sustainable. This again explains why encapsulation is such an important idea. You want to confine knowledge in small containers that fit in your head. Information shouldn't leak out of these containers, because that would require you to keep track of too much stuff when you try to understand other code.
When discussing encapsulation, I emphasise contract over information hiding. A contract, in the spirit of Object-Oriented Software Construction, is a set of preconditions, invariants, and postconditions. Preconditions are particularly relevant to the topic of validation, but I've often experienced that some developers struggle to identify where validation ends and business rules begin.
Consider an online restaurant reservation system as an example. We'd like to implement a feature that enables users to make reservations. In order to meet that end, we decide to introduce a Reservation class. What are the preconditions for creating a valid instance of such a class?
When I go through such an exercise, people quickly identify requirement such as these:
- The reservation should have a date and time.
- The reservation should contain the number of guests.
- The reservation should contain the name or email (or other data) about the person making the reservation.
A common suggestion is that the restaurant should also be able to accommodate the reservation; that is, it shouldn't be fully booked, it should have an available table at the desired time of an appropriate size, etc.
That, however, isn't a precondition for creating a valid Reservation object. That's a business rule.
Preconditions are self-contained #
How do you distinguish between a precondition and a business rule? And what does that have to do with input validation?
Notice that in the above examples, the three preconditions I've listed are self-contained. They are statements about the object or value's constituent parts. On the other hand, the requirement that the restaurant should be able to accommodate the reservation deals with a wider context: The table layout of the restaurant, prior reservations, opening and closing times, and other business rules as well.
Validation is, as Alexis King points out, a parsing problem. You receive less-structured data (CSV, JSON, XML, etc.) and attempt to project it to a more-structured format (C# objects, F# records, Clojure maps, etc.). This succeeds when the input satisfies the preconditions, and fails otherwise.
Why can't we add more preconditions than required? Consider Postel's law. An operation (and that includes object constructors) should be liberal in what it accepts. While you have to draw the line somewhere (you can't really work with a reservation if the date is missing), an object shouldn't require more than it needs.
In general we observe that the fewer pre-conditions, the easier it is to create an object (or equivalent functional data structure). As a counter-example, this explains why Active Record is antithetical to unit testing. One precondition is that there's a database available, and while not impossible to automate in tests, it's quite the hassle. It's easier to work with POJOs in tests. And unit tests, being the first clients of an API, tell you how easy it is to use that API.
Contracts with third parties #
If validation is fundamentally parsing, it seems reasonable that operations should be pure functions. After all, a parser operates on unchanging (less-structured) data. A programming-language parser takes contents of text files as input. There's little need for more input than that, and the output is expected to be deterministic. Not surprisingly, Haskell is well-suited for writing parsers.
You don't, however, have to buy the argument that validation is essentially parsing, so consider another perspective.
Validation is a data transformation step you perform to deal with input. Data comes from a source external to your system. It can be a user filling in a form, another program making an HTTP request, or a batch job that receives files over FTP.
Even if you don't have a formal agreement with any third party, Hyrum's law implies that a contract does exist. It behoves you to pay attention to that, and make it as explicit as possible.
Such a contract should be stable. Third parties should be able to rely on deterministic behaviour. If they supply data one day, and you accept it, you can't reject the same data the next days on grounds that it was malformed. At best, you may be contravariant in input as time passes; in other words, you may accept things tomorrow that you didn't accept today, but you may not reject tomorrow what you accepted today.
Likewise, you can't have validation rules that erratically accept data one minute, reject the same data the next minute, only to accept it later. This implies that validation must, at least, be deterministic: The same input should always produce the same output.
That's half of the way to referential transparency. Do you need side effects in your validation logic? Hardly, so you might as well implement it as pure functions.
Putting the cart before the horse #
You may still think that my definition smells of a solution in search of a problem. Yes, pure functions are convenient, but does it naturally follow that validation should be implemented as pure functions? Isn't this a case of poor retconning?
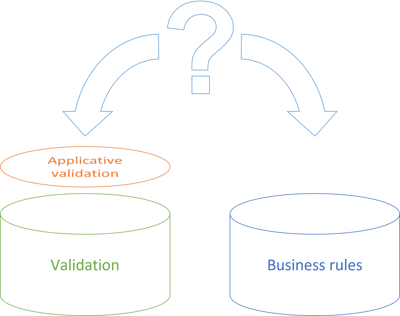
When faced with the question: What is validation, and what are business rules? it's almost as though I've conveniently sized the Validation sorting bucket so that it perfectly aligns with applicative validation. Then, the Business rules bucket fits whatever is left. (In the figure, the two buckets are of equal size, which hardly reflects reality. I estimate that the Business rules bucket is much larger, but had I tried to illustrate that, too, in the figure, it would have looked akilter.)
This is suspiciously convenient, but consider this: My experience is that this perspective on validation works well. To a great degree, this is because I consider validation a solved problem. It's productive to be able to take a chunk of a larger problem and put it aside: We know how to deal with this. There are no risks there.
Definitions do, I believe, rarely spring fully formed from some Platonic ideal. Rather, people observe what works and eventually extract a condensed description and call it a definition. That's what I've attempted to do here.
Business rules change #
Let's return to the perspective of validation as a technical contract between your system and a third party. While that contract should be as stable as possible, business rules change.
Consider the online restaurant reservation example. Imagine that you're the third-party programmer, and that you've developed a client that can make reservations on behalf of users. When a user wants to make a reservation, there's always a risk that it's not possible. Your client should be able to handle that scenario.
Now the restaurant becomes so popular that it decides to change a rule. Earlier, you could make reservations for one, three, or five people, even though the restaurant only has tables for two, four, or six people. Based on its new-found popularity, the restaurant decides that it only accepts reservations for entire tables. Unless it's on the same day and they still have a free table.
This changes the behaviour of the system, but not the contract. A reservation for three is still valid, but will be declined because of the new rule.
"Things that change at the same rate belong together. Things that change at different rates belong apart."
Business rules change at different rates than preconditions, so it makes sense to decouple those concerns.
Conclusion #
Since validation is a solved problem, it's useful to be able to identify what is validation, and what is something else. As long as an 'input rule' is self-contained (or parametrisable), deterministic, and has no side-effects, you can model it with applicative validation.
Equally useful is it to be able to spot when applicative validation isn't a good fit. While I'm sure that someone has published a ValidationT monad transformer for Haskell, I'm not sure I would recommend going that route. In other words, if some business operation involves impure actions, it's not going to fit the mold of applicative validation.
This doesn't mean that you can't implement business rules with pure functions. You can, but in my experience, abstractions other than applicative validation are more useful in those cases.

Comments
Hi Mark,
Firstly, thank you for another insightful article.
I'm curious about using Fakes and testing exceptions. In scenarios where dynamic mocks (like Moq) are employed, we can mock a method to throw an exception, allowing us to test the expected behavior of the System Under Test (SUT). In your example, if we were using Moq, we could create a test to mock the UserRepository's Read method to throw a specific exception (e.g., SqlException). This way, we could ensure that the controller responds appropriately, perhaps with an internal server response. However, I'm unsure about how to achieve a similar test using Fakes. Is this type of test suitable for Fakes, or do such tests not align with the intended use of Fakes? Personally, I avoid using try-catch blocks in repositories or controllers and prefer handling exceptions in middleware (e.g., ErrorHandler). In such cases, I write separate unit tests for the middleware. Could this be a more fitting approach? Your guidance would be much appreciated.
(And yes, I remember your advice about framing questions —it's in your 'Code that Fits in Your Head' book! :D )
Thanks
Thank you for writing. That's a question that warrants an article or two. I've now published an article titled Error categories and category errors. It's not a direct answer to your question, but I found it useful to first outline my thinking on errors in general.
I'll post an update here when I also have an answer to your specific question.
AmirB, once again, thank you for writing. I've now published an article titled Testing exceptions that attempt to answer your question.