ploeh blog danish software design
Polymorphic Builder
Keeping illegal states unrepresentable with the Builder pattern.
As a reaction to my article on Builder isomorphisms Tyson Williams asked:
I'm happy to receive that question, because I struggled to find a compelling example of a Builder where polymorphism seems warranted. Here, it does."If a
GETorDELETErequest had a body or if aPOSTrequest did not have a body, then I would suspect that such behavior was a bug."For the sake of a question that I would like to ask, let's suppose that a body must be added if and only if the method is
POST. Under this assumption,HttpRequestMessageBuildercan create invalid messages. For example, it can create aGETrequest with a body, and it can create aPOSTrequest without a body. Under this assumption, how would you modify your design so that only valid messages can be created?"
Valid combinations #
Before showing code, I think a few comments are in order. As far as I'm aware, the HTTP specification doesn't prohibit weird combinations like a GET request with a body. Still, such a combination is so odd that it seems fair to design an API to prevent this.
On the other hand I think that a POST request without a body should still be allowed. It's not too common, but there are edge cases where this combination is valid. If you want to cause a side effect to happen, a GET is inappropriate, but sometimes all you want do to is to produce an effect. In the Restful Web Services Cookbook Subbu Allamaraju gives this example of a fire-and-forget bulk task:
POST /address-correction?before=2010-01-01 HTTP/1.1
As he puts it, "in essence, the client is "flipping a switch" to start the work."
I'll design the following API to allow this combination, also because it showcases how that sort of flexibility can still be included. On the other hand, I'll prohibit the combination of a request body in a GET request, as Tyson Williams suggested.
Expanded API #
I'll expand on the HttpRequestMessageBuilder example shown in the previous article. As outlined in another article, apart from the Build method the Builder really only has two capabilities:
- Change the HTTP method
- Add (or update) a JSON body
- Add or change the
Acceptheader - Add or change a
Bearertoken
HttpRequestMessageBuilder class now looks like this:
public class HttpRequestMessageBuilder { private readonly Uri url; private readonly object? jsonBody; private readonly string? acceptHeader; private readonly string? bearerToken; public HttpRequestMessageBuilder(string url) : this(new Uri(url)) { } public HttpRequestMessageBuilder(Uri url) : this(url, HttpMethod.Get, null, null, null) { } private HttpRequestMessageBuilder( Uri url, HttpMethod method, object? jsonBody, string? acceptHeader, string? bearerToken) { this.url = url; Method = method; this.jsonBody = jsonBody; this.acceptHeader = acceptHeader; this.bearerToken = bearerToken; } public HttpMethod Method { get; } public HttpRequestMessageBuilder WithMethod(HttpMethod newMethod) { return new HttpRequestMessageBuilder( url, newMethod, jsonBody, acceptHeader, bearerToken); } public HttpRequestMessageBuilder AddJsonBody(object jsonBody) { return new HttpRequestMessageBuilder( url, Method, jsonBody, acceptHeader, bearerToken); } public HttpRequestMessageBuilder WithAcceptHeader(string newAcceptHeader) { return new HttpRequestMessageBuilder( url, Method, jsonBody, newAcceptHeader, bearerToken); } public HttpRequestMessageBuilder WithBearerToken(string newBearerToken) { return new HttpRequestMessageBuilder( url, Method, jsonBody, acceptHeader, newBearerToken); } public HttpRequestMessage Build() { var message = new HttpRequestMessage(Method, url); BuildBody(message); AddAcceptHeader(message); AddBearerToken(message); return message; } private void BuildBody(HttpRequestMessage message) { if (jsonBody is null) return; string json = JsonConvert.SerializeObject(jsonBody); message.Content = new StringContent(json); message.Content.Headers.ContentType.MediaType = "application/json"; } private void AddAcceptHeader(HttpRequestMessage message) { if (acceptHeader is null) return; message.Headers.Accept.ParseAdd(acceptHeader); } private void AddBearerToken(HttpRequestMessage message) { if (bearerToken is null) return; message.Headers.Authorization = new AuthenticationHeaderValue("Bearer", bearerToken); } }
Notice that I've added the methods WithAcceptHeader and WithBearerToken, with supporting implementation. So far, those are the only changes.
It enables you to build HTTP request messages like this:
HttpRequestMessage msg = new HttpRequestMessageBuilder(url) .WithBearerToken("cGxvZWg=") .Build();
Or this:
HttpRequestMessage msg = new HttpRequestMessageBuilder(url) .WithMethod(HttpMethod.Post) .AddJsonBody(new { id = Guid.NewGuid(), date = "2021-02-09 19:15:00", name = "Hervor", email = "hervor@example.com", quantity = 2 }) .WithAcceptHeader("application/vnd.foo.bar+json") .WithBearerToken("cGxvZWg=") .Build();
It still doesn't address Tyson Williams' requirement, because you can build an HTTP request like this:
HttpRequestMessage msg = new HttpRequestMessageBuilder(url) .AddJsonBody(new { id = Guid.NewGuid(), date = "2020-03-22 19:30:00", name = "Ælfgifu", email = "ælfgifu@example.net", quantity = 1 }) .Build();
Recall that the default HTTP method is GET. Since the above code doesn't specify a method, it creates a GET request with a message body. That's what shouldn't be possible. Let's make illegal states unrepresentable.
Builder interface #
Making illegal states unrepresentable is a catch phrase coined by Yaron Minsky to describe advantages of statically typed functional programming. Unintentionally, it also describes a fundamental tenet of object-oriented programming. In Object-Oriented Software Construction Bertrand Meyer describes object-oriented programming as the discipline of guaranteeing that an object can never be in an invalid state.
In the present example, we can't allow an arbitrary HTTP Builder object to afford an operation to add a body, because that Builder object might produce a GET request. On the other hand, there are operations that are always legal: adding an Accept header or a Bearer token. Because these operations are always legal, they constitute a shared API. Extract those to an interface:
public interface IHttpRequestMessageBuilder { IHttpRequestMessageBuilder WithAcceptHeader(string newAcceptHeader); IHttpRequestMessageBuilder WithBearerToken(string newBearerToken); HttpRequestMessage Build(); }
Notice that both the With[...] methods return the new interface. Any IHttpRequestMessageBuilder must implement the interface, but is free to support other operations not part of the interface.
HTTP GET Builder #
You can now implement the interface to build HTTP GET requests:
public class HttpGetMessageBuilder : IHttpRequestMessageBuilder { private readonly Uri url; private readonly string? acceptHeader; private readonly string? bearerToken; public HttpGetMessageBuilder(string url) : this(new Uri(url)) { } public HttpGetMessageBuilder(Uri url) : this(url, null, null) { } private HttpGetMessageBuilder( Uri url, string? acceptHeader, string? bearerToken) { this.url = url; this.acceptHeader = acceptHeader; this.bearerToken = bearerToken; } public IHttpRequestMessageBuilder WithAcceptHeader(string newAcceptHeader) { return new HttpGetMessageBuilder(url, newAcceptHeader, bearerToken); } public IHttpRequestMessageBuilder WithBearerToken(string newBearerToken) { return new HttpGetMessageBuilder(url, acceptHeader, newBearerToken); } public HttpRequestMessage Build() { var message = new HttpRequestMessage(HttpMethod.Get, url); AddAcceptHeader(message); AddBearerToken(message); return message; } private void AddAcceptHeader(HttpRequestMessage message) { if (acceptHeader is null) return; message.Headers.Accept.ParseAdd(acceptHeader); } private void AddBearerToken(HttpRequestMessage message) { if (bearerToken is null) return; message.Headers.Authorization = new AuthenticationHeaderValue("Bearer", bearerToken); } }
Notice that the Build method hard-codes HttpMethod.Get. When you're using an HttpGetMessageBuilder object, you can't modify the HTTP method. You also can't add a request body, because there's no API that affords that operation.
What you can do, for example, is to create an HTTP request with an Accept header:
HttpRequestMessage msg = new HttpGetMessageBuilder(url) .WithAcceptHeader("application/vnd.foo.bar+json") .Build();
This creates a request with an Accept header, but no Bearer token.
HTTP POST Builder #
As a peer to HttpGetMessageBuilder you can implement the IHttpRequestMessageBuilder interface to support POST requests:
public class HttpPostMessageBuilder : IHttpRequestMessageBuilder { private readonly Uri url; private readonly object? jsonBody; private readonly string? acceptHeader; private readonly string? bearerToken; public HttpPostMessageBuilder(string url) : this(new Uri(url)) { } public HttpPostMessageBuilder(Uri url) : this(url, null, null, null) { } public HttpPostMessageBuilder(string url, object jsonBody) : this(new Uri(url), jsonBody) { } public HttpPostMessageBuilder(Uri url, object jsonBody) : this(url, jsonBody, null, null) { } private HttpPostMessageBuilder( Uri url, object? jsonBody, string? acceptHeader, string? bearerToken) { this.url = url; this.jsonBody = jsonBody; this.acceptHeader = acceptHeader; this.bearerToken = bearerToken; } public IHttpRequestMessageBuilder WithAcceptHeader(string newAcceptHeader) { return new HttpPostMessageBuilder( url, jsonBody, newAcceptHeader, bearerToken); } public IHttpRequestMessageBuilder WithBearerToken(string newBearerToken) { return new HttpPostMessageBuilder( url, jsonBody, acceptHeader, newBearerToken); } public HttpRequestMessage Build() { var message = new HttpRequestMessage(HttpMethod.Post, url); BuildBody(message); AddAcceptHeader(message); AddBearerToken(message); return message; } private void BuildBody(HttpRequestMessage message) { if (jsonBody is null) return; string json = JsonConvert.SerializeObject(jsonBody); message.Content = new StringContent(json); message.Content.Headers.ContentType.MediaType = "application/json"; } private void AddAcceptHeader(HttpRequestMessage message) { if (acceptHeader is null) return; message.Headers.Accept.ParseAdd(acceptHeader); } private void AddBearerToken(HttpRequestMessage message) { if (bearerToken is null) return; message.Headers.Authorization = new AuthenticationHeaderValue("Bearer", bearerToken); } }
This class affords various constructor overloads. Two of them don't take a JSON body, and two of them do. This supports both the case where you do want to supply a request body, and the edge case where you don't.
I didn't add an explicit WithJsonBody method to the class, so you can't change your mind once you've created an instance of HttpPostMessageBuilder. The only reason I didn't, though, was to save some space. You can add such a method if you'd like to. As long as it's not part of the interface, but only part of the concrete HttpPostMessageBuilder class, illegal states are still unrepresentable. You can represent a POST request with or without a body, but you can't represent a GET request with a body.
You can now build requests like this:
HttpRequestMessage msg = new HttpPostMessageBuilder( url, new { id = Guid.NewGuid(), date = "2021-02-09 19:15:00", name = "Hervor", email = "hervor@example.com", quantity = 2 }) .WithAcceptHeader("application/vnd.foo.bar+json") .WithBearerToken("cGxvZWg=") .Build();
This builds a POST request with both a JSON body, an Accept header, and a Bearer token.
Is polymorphism required? #
In my previous Builder article, I struggled to produce a compelling example of a polymorphic Builder. It seems that I've now mended the situation. Or have I?
Is the IHttpRequestMessageBuilder interface really required?
Perhaps. It depends on your usage scenarios. I can actually delete the interface, and none of the usage examples I've shown here need change.
On the other hand, had I written helper methods against the interface, obviously I couldn't just delete it.
The bottom line is that polymorphism can be helpful, but it still strikes me as being non-essential to the Builder pattern.
Conclusion #
In this article, I've shown how to guarantee that Builders never get into invalid states (according to the rules we've arbitrarily established). I used the common trick of using constructors for object initialisation. If a constructor completes without throwing an exception, we should expect the object to be in a valid state. The price I've paid for this design is some code duplication.
You may have noticed that there's duplicated code between HttpGetMessageBuilder and HttpPostMessageBuilder. There are ways to address that concern, but I'll leave that as an exercise.
For the sake of brevity, I've only shown examples written as Immutable Fluent Builders. You can refactor all the examples to mutable Fluent Builders or to the original Gang-of-Four Builder pattern. This, too, will remain an exercise for the interested reader.
Impureim sandwich
Pronounced 'impurium sandwich'.
Since January 2017 I've been singing the praise of the impure/pure/impure sandwich, but I've never published an article that defines the term. I intend this article to remedy the situation.
Functional architecture #
In a functional architecture, pure functions can't call impure actions. On the other hand, as Simon Peyton Jones observed in a lecture, observing the result of pure computation is a side-effect. In practical terms, executing a pure function is also impure, because it happens non-deterministically. Thus, even for a piece of software written in a functional style, the entry point must be impure.
While pure functions can't call impure actions, there's no rule to prevent the obverse. Impure actions can call pure functions.
Therefore, the best we can ever hope to achieve is an impure entry point that calls pure code and impurely reports the result from the pure function.

The flow of code here goes from top to bottom:
- Gather data from impure sources.
- Call a pure function with that data.
- Change state (including user interface) based on return value from pure function.
Metaphor #
The reason I call this a sandwich is that I think that it looks like a sandwich, albeit, perhaps, a rather tall one. According to the myth of the sandwich, the 4th Earl of Sandwich was a notorious gambler. While playing cards, he'd order two slices of bread with meat in between. This enabled him to keep playing without greasing the cards. His compatriots would order the same as Sandwich, or simply a Sandwich, and the name stuck.
I like the sandwich as a metaphor. The bread is an affordance, in the spirit of Donald A. Norman. It enables you to handle the meat without getting your fingers greased. In the same way, I think, impure actions enable you to handle a pure function. They let you invoke and observe the result of it.
Examples #
One of the cleanest examples of an impureim sandwich remains my original article:
tryAcceptComposition :: Reservation -> IO (Maybe Int) tryAcceptComposition reservation = runMaybeT $ liftIO (DB.readReservations connectionString $ date reservation) >>= MaybeT . return . flip (tryAccept 10) reservation >>= liftIO . DB.createReservation connectionString
I've here repeated the code, but coloured the background of the impure, pure, and impure parts of the sandwich.
I've shown plenty of other examples of this sandwich architecture, recently, for example, while refactoring a registration flow in F#:
let sut pid r = async { let! validityOfProof = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid let decision = completeRegistrationWorkflow r validityOfProof return! decision |> AsyncResult.traverseBoth db.CompleteRegistration twoFA.CreateProof |> AsyncResult.cata (fun () -> RegistrationCompleted) ProofRequired }
This last example looks as though the bottom part of the sandwich is larger then the rest of the composition. This can sometimes happen (and, in fact, last line of code is also pure). On the other hand, the pure part in the middle will typically look like just a single line of code, even when the invoked function performs work of significant complexity.
The sandwich is a pattern independent of language. You can also apply it in C#:
public async Task<IActionResult> Post(Reservation reservation) { return await Repository.ReadReservations(reservation.Date) .Select(rs => maîtreD.TryAccept(rs, reservation)) .SelectMany(m => m.Traverse(Repository.Create)) .Match(InternalServerError("Table unavailable"), Ok); }
Like in the previous F# example, the final Match is most likely pure. In practice, you may not know, because a method like InternalServerError or Ok is an inherited base class method. Regardless, I don't think that it's architecturally important, because what's going on there is rather trivial.
Naming #
Since the metaphor occurred to me, I've been looking for a better name. The term impure/pure/impure sandwich seems too inconvenient, but nevertheless, people seem to have picked it up.
I want a more distinct name, but have had trouble coming up with one. I've been toying with various abbreviations of impure and pure, but have finally settled on impureim sandwich. It's a contraction of impure/pure/impure.
Why this particular contraction?
I've played with lots of alternatives:
- impureim: impure/pure/impure
- ipi: impure/pure/impure
- impi: impure/pure/impure
- impim: impure/pure/impure
I like impureim because the only anagram that I'm aware of is imperium. I therefore suggest that you pronounce it impurium sandwich. That'll work as a neologic shibboleth.
Summary #
Functional architecture prohibits pure functions from invoking impure actions. On the other hand, a pure function is useless if you can't observe its result. A functional architecture, thus, must have an impure entry point that invokes a pure function and uses another impure action to act on the result.
I suggest that we call such an impure/pure/impure interaction an impureim sandwich, and that we pronounce it an impurium sandwich.
P.S. 2025-01-18:
See also the following, subsequently-published articles that expand on the notion:
In them you can find more examples, and answers to some frequently asked questions.
Comments
I find this example slightly simplistic. What happens when the logic has to do cascade reads/validations as it is typically done? Then you get impureimpureim...? Or do you fetch all data upfront even though it might be...irrelevant? For example, you want to send a comment to a blog post, but that post has forbidden new comments? Wouldn't you want to validate first and then fetch blog post if necessary?
Toni, thank you for writing. As I write in another article,
On the other hand, I never claimed that you can always do this. The impureim sandwich is a design pattern. It gives a name to a general, reusable solution to a commonly occurring problem within a given context."It's my experience that it's conspicuously often possible to implement an impure/pure/impure sandwich."
In cases where you can't apply the impureim sandwich pattern, other patterns are available.
I like this idea and it gives a word to they pattern I have been trying to use but I do have some questions. In the C# example you have a field `maîtreD`. I am assuming that the value comes from dependency injection. Is that the case? And if so can it really be called a pure function? Is that tested in isolation and the test for the function in the example you test that the results from ReadReservations are passed to `maîtreD.TryAccept`? Or is there something else I am missing?
Flechto, thank you for writing. You don't have to assume anything about the code. If you following links in the article, you should be able to find the source code.
Conceptually, yes, the maîtreD class field is initialised via Constructor Injection. What makes you think that that makes it impure?
Discerning and maintaining purity
Functional programming depends on referential transparency, but identifying and keeping functions pure requires deliberate attention.
Referential transparency is the essence of functional programming. Most other traits that people associate with functional programming emerge from it: immutability, recursion, higher-order functions, functors and monads, etcetera.
To summarise, a pure function has to obey two rules:
- The same input always produces the same output.
- Calling it causes no side effects.
Lack of abstraction #
Mainstream programming languages don't distinguish between pure functions and impure actions. I'll use C# for examples, but you can draw the same conclusions for Java, C, C++, Visual Basic .NET and so on - even for F# and Clojure.
Consider this line of code:
string validationMsg = Validator.Validate(dto);
Is Validate a pure function?
You might want to look at the method signature before you answer:
public static string Validate(ReservationDto dto)
This is, unfortunately, not helpful. Will Validate always return the same string for the same dto? Can we guarantee that there's no side effects?
You can't answer these questions only by examining the method signature. You'll have to go and read the code.
This breaks encapsulation. It ruins abstraction. It makes code harder to maintain.
I can't stress this enough. This is what I've attempted to describe in my Humane Code video. We waste significant time reading existing code. Mostly because it's difficult to understand. It doesn't fit in our brains.
Agile Principles, Patterns, and Practices defines an abstraction as
This fits with the definition of encapsulation from Object-Oriented Software Construction. You should be able to interact with an object without knowledge of its implementation details."the amplification of the essential and the elimination of the irrelevant"
When you have to read the code of a method, it indicates a lack of abstraction and encapsulation. Unfortunately, that's the state of affairs when it comes to referential transparency in mainstream programming languages.
Manual analysis #
If you read the source code of the Validate method, however, it's easy to figure out whether it's pure:
public static string Validate(ReservationDto dto) { if (!DateTime.TryParse(dto.Date, out var _)) return $"Invalid date: {dto.Date}."; return ""; }
Is the method deterministic? It seems like it. In fact, in order to answer that question, you need to know if DateTime.TryParse is deterministic. Assume that it is. Apart from the TryParse call, you can easily reason about the rest of this method. There's no randomness or other sources of non-deterministic behaviour in the method, so it seems reasonable to conclude that it's deterministic.
Does the method produce side effects? Again, you have to know about the behaviour of DateTime.TryParse, but I think it's safe to conclude that there's no side effects.
In other words, Validate is a pure function.
Testability #
Pure functions are intrinsically testable because they depend exclusively on their input.
[Fact] public void ValidDate() { var dto = new ReservationDto { Date = "2021-12-21 19:00", Quantity = 2 }; var actual = Validator.Validate(dto); Assert.Empty(actual); }
This unit test creates a reservation Data Transfer Object (DTO) with a valid date string and a positive quantity. There's no error message to produce for a valid DTO. The test asserts that the error message is empty. It passes.
You can with similar ease write a test that verifies what happens if you supply an invalid Date string.
Maintaining purity #
The problem with manual analysis of purity is that any conclusion you reach only lasts until someone edits the code. Every time the code changes, you must re-evaluate.
Imagine that you need to add a new validation rule. The system shouldn't accept reservations in the past, so you edit the Validate method:
public static string Validate(ReservationDto dto) { if (!DateTime.TryParse(dto.Date, out var date)) return $"Invalid date: {dto.Date}."; if (date < DateTime.Now) return $"Invalid date: {dto.Date}."; return ""; }
Is the method still pure? No, it's not. It's now non-deterministic. One way to observe this is to let time pass. Assume that you wrote the above unit test well before December 21, 2021. That test still passes when you make the change, but months go by. One day (on December 21, 2021 at 19:00) the test starts failing. No code changed, but now you have a failing test.
I've made sure that the examples in this article are simple, so that they're easy to follow. This could mislead you to think that the shift from referential transparency to impurity isn't such a big deal. After all, the test is easy to read, and it's clear why it starts failing.
Imagine, however, that the code is as complex as the code base you work with professionally. A subtle change to a method deep in the bowels of a system can have profound impact on the entire architecture. You thought that you had a functional architecture, but you probably don't.
Notice that no types changed. The method signature remains the same. It's surprisingly difficult to maintain purity in a code base, even if you explicitly set out to do so. There's no poka-yoke here; constant vigilance is required.
Automation attempts #
When I explain these issues, people typically suggest some sort of annotation mechanism. Couldn't we use attributes to identify pure functions? Perhaps like this:
[Pure] public static string Validate(ReservationDto dto)
This doesn't solve the problem, though, because this still still compiles:
[Pure] public static string Validate(ReservationDto dto) { if (!DateTime.TryParse(dto.Date, out var date)) return $"Invalid date: {dto.Date}."; if (date < DateTime.Now) return $"Invalid date: {dto.Date}."; return ""; }
That's an impure action annotated with the [Pure] attribute. It still compiles and passes all tests (if you run them before December 21, 2021). The annotation is a lie.
As I've already implied, you also have the compound problem that you need to know the purity (or lack thereof) of all APIs from the base library or third-party libraries. Can you be sure that no pure function becomes impure when you update a library from version 2.3.1 to 2.3.2?
I'm not aware of any robust automated way to verify referential transparency in mainstream programming languages.
Language support #
While no mainstream languages distinguish between pure functions and impure actions, there are languages that do. The most famous of these is Haskell, but other examples include PureScript and Idris.
I find Haskell useful for exactly that reason. The compiler enforces the functional interaction law. You can't call impure actions from pure functions. Thus, you wouldn't be able to make a change to a function like Validate without changing its type. That would break most consuming code, which is a good thing.
You could write an equivalent to the original, pure version of Validate in Haskell like this:
validateReservation :: ReservationDTO -> Either String ReservationDTO validateReservation r@(ReservationDTO _ d _ _ _) = case readMaybe d of Nothing -> Left $ "Invalid date: " ++ d ++ "." Just (_ :: LocalTime) -> Right r
This is a pure function, because all Haskell functions are pure by default.
You can change it to also check for reservations in the past, but only if you also change the type:
validateReservation :: ReservationDTO -> IO (Either String ReservationDTO) validateReservation r@(ReservationDTO _ d _ _ _) = case readMaybe d of Nothing -> return $ Left $ "Invalid date: " ++ d ++ "." Just date -> do utcNow <- getCurrentTime tz <- getCurrentTimeZone let now = utcToLocalTime tz utcNow if date < now then return $ Left $ "Invalid date: " ++ d ++ "." else return $ Right r
Notice that I had to change the return type from Either String ReservationDTO to IO (Either String ReservationDTO). The presence of IO marks the 'function' as impure. If I hadn't changed the type, the code simply wouldn't have compiled, because getCurrentTime and getCurrentTimeZone are impure actions. These types ripple through entire code bases, enforcing the functional interaction law at every level of the code base.
Pure date validation #
How would you validate, then, that a reservation is in the future? In Haskell, like this:
validateReservation :: LocalTime -> ReservationDTO -> Either String ReservationDTO validateReservation now r@(ReservationDTO _ d _ _ _) = case readMaybe d of Nothing -> Left $ "Invalid date: " ++ d ++ "." Just date -> if date < now then Left $ "Invalid date: " ++ d ++ "." else Right r
This function remains pure, although it still changes type. It now takes an additional now argument that represents the current time. You can retrieve the current time as an impure action before you call validateReservation. Impure actions can always call pure functions. This enables you to keep your complex domain model pure, which makes it simpler, and easier to test.
Translated to C#, that corresponds to this version of Validate:
public static string Validate(DateTime now, ReservationDto dto) { if (!DateTime.TryParse(dto.Date, out var date)) return $"Invalid date: {dto.Date}."; if (date < now) return $"Invalid date: {dto.Date}."; return ""; }
This version takes an additional now input parameter, but remains deterministic and free of side effects. Since it's pure, it's trivial to unit test.
[Theory] [InlineData("2010-01-01 00:01", "2011-09-11 18:30", 3)] [InlineData("2019-11-26 13:59", "2019-11-26 19:00", 2)] [InlineData("2030-10-02 23:33", "2030-10-03 00:00", 2)] public void ValidDate(string now, string reservationDate, int quantity) { var dto = new ReservationDto { Date = reservationDate, Quantity = quantity }; var actual = Validator.Validate(DateTime.Parse(now), dto); Assert.Empty(actual); }
Notice that while the now parameter plays the role of the current time, the fact that it's just a value makes it trivial to run simulations of what would have happened if you ran this function in 2010, or what will happen when you run it in 2030. A test is really just a simulation by another name.
Summary #
Most programming languages don't explicitly distinguish between pure and impure code. This doesn't make it impossible to do functional programming, but it makes it arduous. Since the language doesn't help you, you must constantly review changes to the code and its dependencies to evaluate whether code that's supposed to be pure remains pure.
Tests can help, particularly if you employ property-based testing, but vigilance is still required.
While Haskell isn't a mainstream programming language, I find that it helps me flush out my wrong assumptions about functional programming. I write many prototypes and proofs of concept in Haskell for that reason.
Once you get the hang of it, it becomes easier to spot sources of impurity in other languages as well.
- Anything with the
voidreturn type must be assumed to induce side effects. - Everything that involves random numbers is non-deterministic.
- Everything that relies on the system clock is non-deterministic.
- Generating a GUID is non-deterministic.
- Everything that involves input/output is non-deterministic. That includes the file system and everything that involves network communication. In C# this implies that all asynchronous APIs should be considered highly suspect.
Comments
You might be interested in taking a look at PurityAnalyzer; An open source roslyn-based analyzer for C# that I started developing to help maintain pure C# code.
Unfortunately, it is still not production-ready yet and I didn't have time to work on it in the last year. I was hoping contributors would help.
Yacoub, thank you for writing. I wasn't aware of PurityAnalyzer. Do I understand it correctly that it's based mostly on a table of methods known (or assumed) to be pure? It also seems to look for certain attributes, under the assumption that if a [Pure] attribute is present, then one can trust it. Did I understand it correctly?
The fundamental problems with such an approach aside, I can't think of a better solution for the current .NET platform. If you want contributors, though, you should edit the repository's readme-file so that it explains how the tool works, and how contributors could get involved.
Here are the answers to your questions:
1.it's based mostly on a table of methods known (or assumed) to be pure?
This is true for compiled methods, e.g., methods in the .NET frameworks. There are lists maintained for .NET methods that are pure. The lists of course are still incomplete.
For methods in the source code, the analyzer checks if they call impure methods, but it also checks other things like whether they access mutable state. The list of other things is not trivial. If you are interested in the details, see this article. It shows some of the details.
2. It also seems to look for certain attributes, under the assumption that if a [Pure] attribute is present, then one can trust it. Did I understand it correctly?
I don't use the [Pure] attribute because I think that the definition of pure used by Microsoft with this attribute is different than what I consider to be pure. I used a special [IsPure] attribute. There are also other attributes like [IsPureExceptLocally], [IsPureExceptReadLocally], [ReturnsNewObject], etc. The article I mentioned above explains some differences between these.
I agree with you that I should work on readme file to explain details and ask for contributors.
I love this post and enthusiastically agree with all the points you made.
Is the method deterministic? It seems like it. In fact, in order to answer that question, you need to know if DateTime.TryParse is deterministic. Assume that it is.
For what its worth, that overload of DateTime.TryParse is impure because it depends on DateTimeFormatInfo.CurrentInfo, which depends on System.Threading.Thread.CurrentThread.CurrentCulture, which is mutable.
There are lists maintained for .NET methods that are pure.
Yacoub, could you share some links to such lists?
Tyson, I actually knew that, but in order to keep the example simple and compelling, I chose to omit that fact. That's why I phrased the sentence "Assume that it is" (my emphasis) 😉
Tyson, I meant lists maintained as part of the PurityAnalyzer project. You can find them here.
The [Haskell] compiler enforces the functional interaction law. You can't call impure actions from pure functions.
And in contrast, the C# compiler does not enfore the functional interaction law, right?
For exampe, suppose Foo and Bar are pure functions such that Foo calls Bar and the code compiles. Then only change the implementation of Bar in such a way that it is now impure and the code still compiles, which is possible. So Foo is now also impure as well, but its implementation didn't change. Therefore, the C# compiler does not enfore the functional interaction law.
Is this consistent with what you mean by the functional interaction law?
Tyson, thank you for writing. The C# compiler doesn't help protect your intent, if your intent is to apply a functional architecture.
In your example, Foo starts out pure, but becomes impure. That's a result of the law. The law itself isn't broken, but the relationships change. That's often not what you want, so you can say that the compiler doesn't help you maintain a functional architecture.
A compiler like Haskell protects the intent of the law. If foo (Haskell functions must start with a lower-case letter) and bar both start out pure, foo can call bar. When bar later becomes impure, its type changes and foo can no longer invoke it.
I can try to express the main assertion of the functional interaction law like this: a pure function can't call an impure action. This has different implications in different compiler contexts. In Haskell, functions can be statically declared to be either pure or impure. This means that the Haskell compiler can prevent pure functions from calling impure actions. In C#, there's no such distinction at the type level. The implication is therefore different: that if Foo calls Bar and Bar is impure, then Foo must also be impure. This follows by elimination, because a pure function can't call an impure action. Therefore, since Foo can call Bar, and Bar is impure, then Foo must also be impure.
The causation is reversed, so to speak.
Does that answer your question?
Yes, that was a good answer. Thank you.
...a pure function can't call an impure action.
We definitely want this to be true, but let's try to make sure it is. What do you think about the C# function void Foo() => DateTime.Now;? It has lots of good propertie: it alreays returns the same value (something isomorphic to Unit), and it does not mutate anything. However, it calls the impure property DateTime.Now. I think a reasonable person could argue that this function is pure. My guess is that you would say that it is impure. Am I right? I am willing to accept that.
...a pure function has to obey two rules:
- The same input always produces the same output.
- Calling it causes no side effects.
Is it possible for a function to violate the first rule but not violate the second rule?
Tyson, I'm going to assume that you mean something like void Foo() { var _ = DateTime.Now; }, since the code you ask about doesn't compile 😉
That function is, indeed pure, because it has no observable side effects, and it always returns unit. Purity is mostly a question of what we can observe if we consider the function a black box.
Obviously, based on that criterion, we can refactor the function to void Foo() { } and we wouldn't be able to tell the difference. This version of Foo is clearly pure, although degenerate.
Is it possible for a function to violate the first rule but not violate the second rule?Yes, the following method is non-deterministic, but has no side effects:
DateTime Foo() => DateTime.Now; The input is always unit, but the return value can change.
I think I need to practice test driven comment writing ;) Thanks for seeing through my syntax errors again.
Oh, you think that that function is pure. Interesting. It follows then that the functional interaction law (pure functions cannot call impure actions) does not follow from the definition of a pure function. It is possible, in theory and in practice, for a pure function to call an impure action. Instead, the functional interaction law is "just" a goal to aspire to when designing a programming language. Haskell achieved that goal while C# and F# did not. Do you agree with this? (This is really what I was driving towards in this comment above, but I was trying to approach this "blasphemous" claim slowly.)
Just as you helped me distinguish between function purity and totality in this comment, I think it would be helpful for us to consider separately the two defining properties of a pure function. The first property is "the same input always produces the same output". Let's call this weak determinism. Determinism is could be defined as "the same input always produces the same sequence of states", which includes the state of the output, so determinism is indeed stronger than weak determinism. The second property is "causes no side effect". It seems to me that there is either a lack of consensus or a lack of clarity about what constitutes a side effect. One definition I like is mutation of state outside of the current stack frame.
One reason the functional interaction law is false in general is because the corresponding interaction law for weak determinism also false in general. The function I gave above (that called DateTime.Now and then returned unit) is a trivial example of that. A nontrivial example is quicksort.
At this point, I wanted to claim that the side effect interaction law is true in general, but it is not. This law says that a function that is side-effect free cannot call a function that causes a side effect. A counterexample is void Foo() { int i = 0; Bar(ref i); } with void Bar(ref int i) => i++;. That is, Bar mutates state outside of its stack frame, namely in the stack frame of Foo, so it is not side-effect free, but Foo is. (And I promise that I tested that code for compiler errors.)
I need to think more about that. Is there a better definition of side effect, one for which the side effect interaction law is true?
I just realized something that I think is interesting. Purely functional programming languages enforce a property of functions stronger than purity. With respect to the first defining property of a pure function (aka weak determinism), purely functional programming languages enforce the stronger notion of determinism. Otherwise, the compiler would need to realize that functions like quicksort should be allowed (because it is weakly deterministic). This reminds me of the debate between static and dynamic programming languages. In the process of forbidding certain unsafe code, static languages end up forbidding some safe code as well.
Tyson, I disagree with your basic premise:
"It follows then that the functional interaction law (pure functions cannot call impure actions) does not follow from the definition of a pure function."I don't think that this follows.
The key is that your example is degenerate. The Foo function is only pure because DateTime.Now isn't used. The actual, underlying property that we're aiming for is referential transparency. Can you replace Foo with its value? Yes, you can.
Perhaps you think this is a hand-wavy attempt to dodge a bullet, but I don't think that it is. You can write the equivalent function in Haskell like this:
foo :: () -> () foo () = let _ = getCurrentTime in ()
I don't recall if you're familiar with Haskell, but for the benefit of any reader who comes by and wishes to follow this discussion, here are the important points:
- The function calls
getCurrentTime, which is an impure action. Its type isIO UTCTime. TheIOcontainer marks the action as impure. - The underscore is a wildcard that tells Haskell to discard the value.
- The type of
foois() -> (). It takes unit as input and returns unit. There's noIOcontainer involved, so the function is pure.
IO UTCTime is an opaque container of UTCTime values. A pure caller can see the container, but not its contents. A common interpretation of this is that IO represents the superposition of all possible values, just like Schrödinger's box. Also, since Haskell is a lazily evaluated language, actions are only evaluated when their values are needed for something. Since the value of getCurrentTime is discarded, the impure action never runs (the box is never opened). This may be clearer with this example:
bar :: () -> () bar () = let _ = putStrLn "Bar!" in ()
Like foo, bar calls an impure action: putStrLn, which corresponds to Console.WriteLine. Having the type String -> IO () it's impure. It works like this:
> putStrLn "Example" Example
None the less, because bar discards the IO () return value after it calls putStrLn, it never evaluates:
> bar () ()
Perhaps a subtle rephrasing of the functional interaction law would be more precise. Perhaps it should say that a pure function can't evaluate an impure action.
Bringing this back to C#, we have to keep in mind that C# doesn't enforce the functional interaction law in any way. Thus, the law works ex-post, instead of in Haskell, where it works ex-ante. Is the Foo C# code pure? Yes, it is, because it's referentially transparent.
Regarding the purity of QuickSort, you may find this discussion interesting.
...Haskell is a strictly functional language. Every expression is referentially transparent. ... Is the Foo C# code pure? Yes, it is, because it's referentially transparent.
So every function in Haskell is referentially transparent, and if a funciton in C# is referentially transparent, then it is pure. Is C# necessary there? Does referential transparency impliy purity regardless of langauge? Do you consider purity and referential transparency to be concepts that imply each other regulardless of language? I think a function is referential transparency if and only if it is pure, and I think this is independent of the langauge.
If C# is not necessary, then it follows that every function in Haskell is pure. This seems like a contradiction with this statement.
The function callsgetCurrentTime, which is an impure action. Its [return] type isIO UTCTime. TheIOcontainer marks the action as impure.
You cited Bartosz Milewski there. He also says that every function in Haskell is pure. He calls Haskell functions returning IO a pure action. I agree with Milewski; I think every function in Haskell is pure.
Perhaps a subtle rephrasing of the functional interaction law would be more precise. Perhaps it should say that a pure function can't evaluate an impure action.
How does this rephrasing help? In the exmaple from my previous comment, bar is impure while foo is pure even though foo evaluates bar, which can be verified by putting a breakpoint in bar when evaluating foo or by observing that i has value 1 when foo returns. If Haskell contained impure functions, then replacing "calls" with "evalutes" helps because everything is lazy in Haskell, but I don't see how it helps in an eager langauge like C#.
Regarding the purity of QuickSort, you may find this discussion interesting.
Oh, sorry. I now see that my reference to quicksort was unclear. I meant the randomized version of quicksort for the pivot is selected uniformily at random from all elements being sorted. That refrasing of the functional interaction law doesn't address the issue I am trying to point out with quicksort. To elborate, consider this randomized version of quicksort that has no side effects. I think this function is pure even though it uses randomness, which is necessarily obtained from an impure function.
Tyson, my apologies that I've been so dense. I think that I'm beginning to understand where you're going with this. Calling out randomised pivot selection in quicksort helped, I think.
I would consider a quicksort function referentially transparent, even if it were to choose the pivot at random. Even if it does that, you can replace a given function call with its output. The only difference you might observe across multiple function calls would be varying execution time, due to lucky versus unlucky random pivot selection. Execution time is, however, not a property that impacts whether or not we consider a function pure.
Safe Haskell can't do that, though, so you're correct when you say:
"In the process of forbidding certain unsafe code, static languages end up forbidding some safe code as well."(Actually, you can implement quicksort like that in Haskell as well. In order to not muddy the waters, I've so far ignored that the language has an escape hatch for (among other purposes) this sort of scenario:
unsafePerformIO. In Safe Haskell, however, you can't use it, and I've never myself had to use it.)
I'm going to skip the discussion about whether or not all of Haskell is pure, because I think it's a red herring. We can discuss it later, if you're interested.
I think that you're right, though, that the functional interaction law has to come with a disclaimer. I'm not sure exactly how to formulate it, but I need to take a detour around side effects, and then perhaps you can help me with that.
Functional programmers know that every execution has side effects. In the extreme, running any calculation on a computer produces heat. There could be other side effects as well, such as CPU registers changing values, data moving in and out of processor caches, and so on. The question is: when do side effects become significant?
We don't consider the generation of heat a significant side effect. What about a debug trace? If it doesn't affect the state of the system, does it count? If not, then how about logging or auditing?
We usually draw the line somewhere and say that anything on one side counts, and things on the other side don't. The bottom line is, though, that we consider some side effects insignificant.
I think that you have now demonstrated that there's symmetry. Not only are there insignificant side effects, but insignificant randomness also exists. The randomness involved in choosing a pivot in quicksort has no significant impact on the output.
Was that what you meant by weak determinism?
Builder as a monoid
Builder, particularly Fluent Builder, is one of the more useful design patterns. Here's why.
This article is part of a series of articles about design patterns and their universal abstraction counterparts.
The Builder design pattern is an occasionally useful pattern, but mostly in its Fluent Builder variation. I've already described that Builder, Fluent Builder, and Immutable Fluent Builder are isomorphic. The Immutable Fluent Builder variation is a set of pure functions, so among the three variations, it best fits the set of universal abstractions that I've so far discussed in this article series.
Design Patterns describes 23 patterns. Some of these are more useful than others. I first read the book in 2003, and while I initially used many of the patterns, after some years I settled into a routine where I'd reach for the same handful of patterns and ignore the rest.
What makes some design patterns more universally useful than others? There's probably components of both subjectivity and chance, but I also believe that there's some correlation to universal abstractions. I consider abstractions universal when they are derived from universal truths (i.e. mathematics) instead of language features or 'just' experience. That's what the overall article series is about. In this article, you'll learn how the Builder pattern is an instance of a universal abstraction. Hopefully, this goes a long way towards explaining why it seems to be so universally useful.
Builder API, isolated #
I'll start with the HttpRequestMessageBuilder from the article about Builder isomorphisms, particularly its Immutable Fluent Builder incarnation. Start by isolating those methods that manipulate the Builder. These are the functions that had void return types in the original Builder incarnation. Imagine, for example, that you extract an interface of only those methods. What would such an interface look like?
public interface IHttpRequestMessageBuilder { HttpRequestMessageBuilder AddJsonBody(object jsonBody); HttpRequestMessageBuilder WithMethod(HttpMethod newMethod); }
Keep in mind that on all instance methods, the instance itself can be viewed as 'argument 0'. In that light, each of these methods take two arguments: a Builder and the formal argument (jsonBody and newMethod, respectively). Each method returns a Builder. I've already described how this is equivalent to an endomorphism. An endomorphism is a function that returns the same type of output as its input, and it forms a monoid.
This can be difficult to see, so I'll make it explicit. The code that follows only exists to illustrate the point. In no way do I endorse that you write code in this way.
Explicit endomorphism #
You can define a formal interface for an endomorphism:
public interface IEndomorphism<T> { T Run(T x); }
Notice that it's completely generic. The Run method takes a value of the generic type T and returns a value of the type T. The identity of the monoid, you may recall, is the eponymously named identity function which returns its input without modification. You can also define the monoidal combination of two endomorphisms:
public class AppendEndomorphism<T> : IEndomorphism<T> { private readonly IEndomorphism<T> morphism1; private readonly IEndomorphism<T> morphism2; public AppendEndomorphism(IEndomorphism<T> morphism1, IEndomorphism<T> morphism2) { this.morphism1 = morphism1; this.morphism2 = morphism2; } public T Run(T x) { return morphism2.Run(morphism1.Run(x)); } }
This implementation of IEndomorphism<T> composes two other IEndomorphism<T> objects. When its Run method is called, it first calls Run on morphism1 and then uses the return value of that method call (still a T object) as input for Run on morphism2.
If you need to combine more than two endomorphisms then that's also possible, because monoids accumulate.
Explicit endomorphism to change HTTP method #
You can adapt the WithMethod method to the IEndomorphism<HttpRequestMessageBuilder> interface:
public class ChangeMethodEndomorphism : IEndomorphism<HttpRequestMessageBuilder> { private readonly HttpMethod newMethod; public ChangeMethodEndomorphism(HttpMethod newMethod) { this.newMethod = newMethod; } public HttpRequestMessageBuilder Run(HttpRequestMessageBuilder x) { if (x is null) throw new ArgumentNullException(nameof(x)); return x.WithMethod(newMethod); } }
In itself, this is simple code, but it does turn things on their head. The newMethod argument is now a class field (and constructor argument), while the HttpRequestMessageBuilder has been turned into a method argument. Keep in mind that I'm not doing this because I endorse this style of API design; I do it to demonstrate how the Immutable Fluent Builder pattern is an endomorphism.
Since ChangeMethodEndomorphism is an Adapter between IEndomorphism<HttpRequestMessageBuilder> and the WithMethod method, I hope that this is becoming apparent. I'll show one more Adapter.
Explicit endomorphism to add a JSON body #
In the example code, there's one more method that modifies an HttpRequestMessageBuilder object, and that's the AddJsonBody method. You can also create an Adapter over that method:
public class AddJsonBodyEndomorphism : IEndomorphism<HttpRequestMessageBuilder> { private readonly object jsonBody; public AddJsonBodyEndomorphism(object jsonBody) { this.jsonBody = jsonBody; } public HttpRequestMessageBuilder Run(HttpRequestMessageBuilder x) { if (x is null) throw new ArgumentNullException(nameof(x)); return x.AddJsonBody(jsonBody); } }
While the AddJsonBody method itself is more complicated than WithMethod, the Adapter is strikingly similar.
Running an explicit endomorphism #
You can use the IEndomorphism<T> API to compose a pipeline of operations that will, for example, make an HttpRequestMessageBuilder build an HTTP POST request with a JSON body:
IEndomorphism<HttpRequestMessageBuilder> morphism = new AppendEndomorphism<HttpRequestMessageBuilder>( new ChangeMethodEndomorphism(HttpMethod.Post), new AddJsonBodyEndomorphism(new { id = Guid.NewGuid(), date = "2020-03-22 19:30:00", name = "Ælfgifu", email = "ælfgifu@example.net", quantity = 1 }));
You can then Run the endomorphism over a new HttpRequestMessageBuilder object to produce an HTTP request:
HttpRequestMessage msg = morphism.Run(new HttpRequestMessageBuilder(url)).Build();
The msg object represents an HTTP POST request with the supplied JSON body.
Once again, I stress that the purpose of this little exercise is only to demonstrate how an Immutable Fluent Builder is an endomorphism, which is a monoid.
Test Data Builder endomorphism #
You can give Test Data Builders the same treatment, again only to demonstrate that the reason they compose so well is because they're monoids. I'll use an immutable variation of the AddressBuilder from this article.
For example, to modify a city, you can introduce an endomorphism like this:
public class CityEndomorphism : IEndomorphism<AddressBuilder> { private readonly string city; public CityEndomorphism(string city) { this.city = city; } public AddressBuilder Run(AddressBuilder x) { return x.WithCity(city); } }
You can use it to create an address in Paris like this:
IEndomorphism<AddressBuilder> morphism = new CityEndomorphism("Paris"); Address address = morphism.Run(new AddressBuilder()).Build();
The address is fully populated with Street, PostCode, and so on, but apart from City, you know none of the values.
Sweet spot #
Let's return to the question from the introduction to the article. What makes some design patterns useful? I don't think that there's a single answer to that question, but I find it intriguing that so many of the useful patterns turn out to be equivalent to universal abstractions. The Builder pattern is a monoid. From a programming perspective, the most useful characteristic of semigroups and monoids is that they enable you to treat many objects as one object. Monoids compose.
Of the three Builder variations, the Immutable Fluent Builder is the most useful. It's also the variation that most clearly corresponds to the endomorphism monoid. Viewing it as an endomorphism reveals its strengths. When or where is a Builder most useful?
Don't be mislead by Design Patterns, which states the intent of the Builder pattern like this:
This may still be the case, but I don't find that this is the primary advantage offered by the pattern. We've learned much about the utility of each design pattern since 1994, so I don't blame the Gang of Four for not seeing this. I do think, however, that it's important to emphasise that the benefit you can derive from a pattern may differ from the original motivation."Separate the construction of a complex object from its representation so that the same construction process can create different representations."
An endomorphism represents a modification of a value. You need a value to get started, and you get a modified value (of the same type) as output.

Sometimes, all you need is the initial object.

And sometimes, you need to compose several changes.

To me, this makes the sweet spot for the pattern clear. Use an (Immutable) Fluent Builder when you have a basic object that's useful in itself, but where you want to give client code the option to make changes to the defaults.
Sometimes, the initial object has self-contained default values. Test Data Builders are good examples of that:
public AddressBuilder() { this.street = ""; this.city = ""; this.postCode = new PostCodeBuilder().Build(); }
The AddressBuilder constructor fully initialises the object. You can use its WithNoPostcode, WithStreet, etcetera methods to make changes to it, but you can also use it as is.
In other cases, client code must initialise the object to be built. The HttpRequestMessageBuilder is an example of that:
public HttpRequestMessageBuilder(string url) : this(new Uri(url)) { } public HttpRequestMessageBuilder(Uri url) : this(url, HttpMethod.Get, null) { } private HttpRequestMessageBuilder(Uri url, HttpMethod method, object? jsonBody) { this.url = url; Method = method; this.jsonBody = jsonBody; }
While there's more than one constructor overload, client code must supply a url in one form or other. That's the precondition of this class. Given a valid url, though, an HttpRequestMessageBuilder object can be useful without further modification, but you can also modify it by calling its methods.
You often see the Builder pattern used for configuration APIs. The ASP.NET Core IApplicationBuilder is a prominent example of the Fluent Builder pattern. The NServiceBus endpoint configuration API, on the other hand, is based on the classic Builder pattern. It makes sense to use an endomorphic design for framework configuration. Framework designers want to make it as easy to get started with their framework as possible. For this reason, it's important to provide a useful default configuration, so that you can get started with as little ceremony as possible. On the other hand, a framework must be flexible. You need a way to tweak the configuration to support your particular needs. The Builder pattern supports both scenarios.
Other examples include Test Data Builders, as well as specialised Builders such as UriBuilder and SqlConnectionStringBuilder.
It's also worth noting that F# copy-and-update expressions are endomorphisms. That's the reason that when you have immutable records, you need no Test Data Builders.
Summary #
The Builder pattern comes in (at least) three variations: the Gang-of-Four Builder pattern, Fluent Builder, and Immutable Fluent Builder. All are isomorphic to each other, and are equivalent to the endomorphism monoid.
Viewing Builders as endomorphisms may mostly be an academic exercise, but I think it highlights the sweet spot for the pattern. It's particularly useful when you wish to expose an API that offers simple defaults, while at the same time enabling client code to make changes to those defaults. When those changes involve several steps (as e.g. AddJsonBody) you can view each modifier method as a Facade.
Next: Visitor as a sum type.
Builder isomorphisms
The Builder pattern is equivalent to the Fluent Builder pattern.
This article is part of a series of articles about software design isomorphisms. An isomorphism is when a bi-directional lossless translation exists between two representations. Such translations exist between the Builder pattern and two variations of the Fluent Builder pattern. Since the names sound similar, this is hardly surprising.
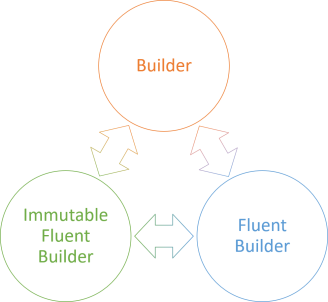
Given an implementation that uses one of those three patterns, you can translate your design into one of the other options. This doesn't imply that each is of equal value. When it comes to composability, both versions of Fluent Builder are superior to the classic Builder pattern.
A critique of the Maze Builder example #
In these articles, I usually first introduce the form presented in Design Patterns. The code example given by the Gang of Four is, however, problematic. I'll start by pointing out the problems and then proceed to present a simpler, more useful example.
The book presents an example centred on a MazeBuilder abstract class. The original example is in C++, but I here present my C# interpretation:
public abstract class MazeBuilder { public virtual void BuildMaze() { } public virtual void BuildRoom(int room) { } public virtual void BuildDoor(int roomFrom, int roomTo) { } public virtual Maze GetMaze() { return null; } }
As the book states, "the maze-building operations of MazeBuilder do nothing by default. They're not declared pure virtual to let derived classes override only those methods in which they're interested." This means that you could technically write a derived class that overrides only BuildRoom. That's unlikely to be useful, since GetMaze still returns null.
Moreover, the presence of the BuildMaze method indicates sequential coupling. A client (a Director, in the pattern language of Design Patterns) is supposed to first call BuildMaze before calling any of the other methods. What happens if a client forgets to call BuildMaze? What happens if client code calls the method after some of the other methods. What happens if it calls it multiple times?
Another issue with the sample code is that it's unclear how it accomplishes its stated goal of separating "the construction of a complex object from its representation." The StandardMazeBuilder presented seems tightly coupled to the Maze class to a degree where it's hard to see how to untangle the two. The book fails to make a compelling example by instead presenting a CountingMazeBuilder that never implements GetMaze. It never constructs the desired complex object.
Don't interpret this critique as a sweeping dismissal of the pattern, or the book in general. As this article series implies, I've invested significant energy in it. I consider the book seminal, but we've learned much since its publication in 1994. A common experience is that not all of the patterns in the book are equally useful, and of those that are, some are useful for different reasons than the book gives. The Builder pattern is an example of that.
The Builder pattern isn't useful only because it enables you to "separate the construction of a complex object from its representation." It's useful because it enables you to present an API that comes with good default behaviour, but which can be tweaked into multiple configurations. The pattern is useful even without polymorphism.
HTTP request Builder #
The HttpRequestMessage class is a versatile API with good default behaviour, but it can be a bit awkward if you want to make an HTTP request with a body and particular headers. You can often get around the problem by using methods like PostAsync on HttpClient, but sometimes you need to drop down to SendAsync. When that happens, you need to build your own HttpRequestMessage objects. A Builder can encapsulate some of that work.
public class HttpRequestMessageBuilder { private readonly Uri url; private object? jsonBody; public HttpRequestMessageBuilder(string url) : this(new Uri(url)) { } public HttpRequestMessageBuilder(Uri url) { this.url = url; Method = HttpMethod.Get; } public HttpMethod Method { get; set; } public void AddJsonBody(object jsonBody) { this.jsonBody = jsonBody; } public HttpRequestMessage Build() { var message = new HttpRequestMessage(Method, url); BuildBody(message); return message; } private void BuildBody(HttpRequestMessage message) { if (jsonBody is null) return; string json = JsonConvert.SerializeObject(jsonBody); message.Content = new StringContent(json); message.Content.Headers.ContentType.MediaType = "application/json"; } }
Compared to Design Patterns' example, HttpRequestMessageBuilder isn't polymorphic. It doesn't inherit from a base class or implement an interface. As I pointed out in my critique of the MazeBuilder example, polymorphism doesn't seem to be the crux of the matter. You could easily introduce a base class or interface that defines the Method, AddJsonBody, and Build members, but what would be the point? Just like the MazeBuilder example fails to present a compelling second implementation, I can't think of another useful implementation of a hypothetical IHttpRequestMessageBuilder interface.
Notice that I dropped the Build prefix from most of the Builder's members. Instead, I reserved the word Build for the method that actually creates the desired object. This is consistent with most modern Builder examples I've encountered.
The HttpRequestMessageBuilder comes with a reasonable set of default behaviours. If you just want to make a GET request, you can easily do that:
var builder = new HttpRequestMessageBuilder(url); HttpRequestMessage msg = builder.Build(); HttpClient client = GetClient(); var response = await client.SendAsync(msg);
Since you only call the builder's Build method, but never any of the other members, you get the default behaviour. A GET request with no body.
Notice that the HttpRequestMessageBuilder protects its invariants. It follows the maxim that you should never be able to put an object into an invalid state. Contrary to Design Patterns' StandardMazeBuilder, it uses its constructors to enforce an invariant. Regardless of what sort of HttpRequestMessage you want to build, it must have a URL. Both constructor overloads require all clients to supply one. (In order to keep the code example as simple as possible, I've omitted all sorts of precondition checks, like checking that url isn't null, that it's a valid URL, and so on.)
If you need to make a POST request with a JSON body, you can change the defaults:
var builder = new HttpRequestMessageBuilder(url); builder.Method = HttpMethod.Post; builder.AddJsonBody(new { id = Guid.NewGuid(), date = "2020-03-22 19:30:00", name = "Ælfgifu", email = "ælfgifu@example.net", quantity = 1 }); HttpRequestMessage msg = builder.Build(); HttpClient client = GetClient(); var response = await client.SendAsync(msg);
Other combinations of Method and AddJsonBody are also possible. You could, for example, make a DELETE request without a body by only changing the Method.
This incarnation of HttpRequestMessageBuilder is cumbersome to use. You must first create a builder object and then mutate it. Once you've invoked its Build method, you rarely need the object any longer, but the builder variable is still in scope. You can address those usage issues by refactoring a Builder to a Fluent Builder.
HTTP request Fluent Builder #
In the Gang of Four Builder pattern, no methods return anything, except the method that creates the object you're building (GetMaze in the MazeBuilder example, Build in the HttpRequestMessageBuilder example). It's always possible to refactor such a Builder so that the void methods return something. They can always return the object itself:
public HttpMethod Method { get; private set; } public HttpRequestMessageBuilder WithMethod(HttpMethod newMethod) { Method = newMethod; return this; } public HttpRequestMessageBuilder AddJsonBody(object jsonBody) { this.jsonBody = jsonBody; return this; }
Changing AddJsonBody is as easy as changing its return type and returning this. Refactoring the Method property is a bit more involved. It's a language feature of C# (and a few other languages) that classes can have properties, so this concern isn't general. In languages without properties, things are simpler. In C#, however, I chose to make the property setter private and instead add a method that returns HttpRequestMessageBuilder. Perhaps it's a little confusing that the name of the method includes the word method, but keep in mind that the method in question is an HTTP method.
You can now create a GET request with a one-liner:
HttpRequestMessage msg = new HttpRequestMessageBuilder(url).Build();
You don't have to declare any builder variable to mutate. Even when you need to change the defaults, you can just start with a builder and keep on chaining method calls:
HttpRequestMessage msg = new HttpRequestMessageBuilder(url) .WithMethod(HttpMethod.Post) .AddJsonBody(new { id = Guid.NewGuid(), date = "2020-03-22 19:30:00", name = "Ælfgifu", email = "ælfgifu@example.net", quantity = 1 }) .Build();
This creates a POST request with a JSON message body.
We can call this pattern Fluent Builder because this version of the Builder pattern has a Fluent Interface.
This usually works well enough in practice, but is vulnerable to aliasing. What happens if you reuse an HttpRequestMessageBuilder object?
var builder = new HttpRequestMessageBuilder(url); var deleteMsg = builder.WithMethod(HttpMethod.Delete).Build(); var getMsg = builder.Build();
As the variable names imply, the programmer responsible for these three lines of code incorrectly believed that without the call to WithMethod, the builder will use its default behaviour when Build is called. The previous line of code, however, mutated the builder object. Its Method property remains HttpMethod.Delete until another line of code changes it!
HTTP request Immutable Fluent Builder #
You can disarm the aliasing booby trap by making the Fluent Builder immutable. A good first step in that refactoring is making sure that all class fields are readonly:
private readonly Uri url; private readonly object? jsonBody;
The url field was already marked readonly, so the change only applies to the jsonBody field. In addition to the class fields, don't forget any automatic properties:
public HttpMethod Method { get; }
The HttpMethod property previously had a private setter, but this is now gone. It's also strictly read only.
Now that all data is read only, the only way you can 'change' values is via a constructor. Add a constructor overload that receives all data and chain the other constructors into it:
public HttpRequestMessageBuilder(string url) : this(new Uri(url)) { } public HttpRequestMessageBuilder(Uri url) : this(url, HttpMethod.Get, null) { } private HttpRequestMessageBuilder(Uri url, HttpMethod method, object? jsonBody) { this.url = url; Method = method; this.jsonBody = jsonBody; }
I'm usually not keen on allowing null arguments, but I made the all-encompassing constructor private. In that way, at least no client code gets the wrong idea.
The optional modification methods can now only do one thing: return a new object:
public HttpRequestMessageBuilder WithMethod(HttpMethod newMethod) { return new HttpRequestMessageBuilder(url, newMethod, jsonBody); } public HttpRequestMessageBuilder AddJsonBody(object jsonBody) { return new HttpRequestMessageBuilder(url, Method, jsonBody); }
The client code looks the same as before, but now you no longer have an aliasing problem:
var builder = new HttpRequestMessageBuilder(url); var deleteMsg = builder.WithMethod(HttpMethod.Delete).Build(); var getMsg = builder.Build();
Now deleteMsg represents a Delete request, and getMsg truly represents a GET request.
Since this variation of the Fluent Builder pattern is immutable, it's natural to call it an Immutable Fluent Builder.
You've now seen how to refactor from Builder via Fluent Builder to Immutable Fluent Builder. If these three pattern variations are truly isomorphic, it should also be possible to move in the other direction. I'll leave it as an exercise for the reader to do this with the HTTP request Builder example. Instead, I will briefly discuss another example that starts at the Fluent Builder pattern.
Test Data Fluent Builder #
A prominent example of the Fluent Builder pattern would be the set of all Test Data Builders. I'm going to use the example I've already covered. You can visit the previous article for all details, but in summary, you can, for example, write code like this:
Address address = new AddressBuilder().WithCity("Paris").Build();
This creates an Address object with the City property set to "Paris". The Address class comes with other properties. You can trust that the AddressBuilder gave them values, but you don't know what they are. You can use this pattern in unit tests when you need an Address in Paris, but you don't care about any of the other data.
In my previous article, I implemented AddressBuilder as a Fluent Builder. I did that in order to stay as true to Nat Pryce's original example as possible. Whenever I use the Test Data Builder pattern in earnest, however, I use the immutable variation so that I avoid the aliasing issue.
Test Data Builder as a Gang-of-Four Builder #
You can easily refactor a typical Test Data Builder like AddressBuilder to a shape more reminiscent of the Builder pattern presented in Design Patterns. Apart from the Build method that produces the object being built, change all other methods to void methods:
public class AddressBuilder { private string street; private string city; private PostCode postCode; public AddressBuilder() { this.street = ""; this.city = ""; this.postCode = new PostCodeBuilder().Build(); } public void WithStreet(string newStreet) { this.street = newStreet; } public void WithCity(string newCity) { this.city = newCity; } public void WithPostCode(PostCode newPostCode) { this.postCode = newPostCode; } public void WithNoPostcode() { this.postCode = new PostCode(); } public Address Build() { return new Address(this.street, this.city, this.postCode); } }
You can still build a test address in Paris, but it's now more inconvenient.
var addressBuilder = new AddressBuilder(); addressBuilder.WithCity("Paris"); Address address = addressBuilder.Build();
You can still use multiple Test Data Builders to build more complex test data, but the classic Builder pattern doesn't compose well.
var invoiceBuilder = new InvoiceBuilder(); var recipientBuilder = new RecipientBuilder(); var addressBuilder = new AddressBuilder(); addressBuilder.WithNoPostcode(); recipientBuilder.WithAddress(addressBuilder.Build()); invoiceBuilder.WithRecipient(recipientBuilder.Build()); Invoice invoice = invoiceBuilder.Build();
These seven lines of code creates an Invoice object with a address without a post code. Compare that with the Fluent Builder example in the previous article. This is a clear example that while the variations are isomorphic, they aren't equally useful. The classic Builder pattern isn't as practical as one of the Fluent variations.
You might protest that this variation of AddressBuilder, InvoiceBuilder, etcetera isn't equivalent to the Builder pattern. After all, the Builder shown in Design Patterns is polymorphic. That's really not an issue, though. Just extract an interface from the concrete builder:
public interface IAddressBuilder { Address Build(); void WithCity(string newCity); void WithNoPostcode(); void WithPostCode(PostCode newPostCode); void WithStreet(string newStreet); }
Make the concrete class implement the interface:
public class AddressBuilder : IAddressBuilder
You could argue that this adds no value. You'd be right. This goes contrary to the Reused Abstractions Principle. I think that the same criticism applies to Design Patterns' original description of the pattern, as I've already pointed out. The utility in the pattern comes from how it gives client code good defaults that it can then tweak as necessary.
Summary #
The Builder pattern was originally described in Design Patterns. Later, smart people like Nat Pryce figured out that by letting each mutating operation return the (mutated) Builder, such a Fluent API offered superior composability. A further improvement to the Fluent Builder pattern makes the Builder immutable in order to avoid aliasing issues.
All three variations are isomorphic. Work that one of these variations afford is also afforded by the other variations.
On the other hand, the variations aren't equally useful. Fluent APIs offer superior composability.
Next: Church encoding.
Comments
You can now[, with the fluent builder implementation,] create a
GETrequest with a one-liner:
HttpRequestMessage msg = new HttpRequestMessageBuilder(url).Build();
It is also possible to write that one-liner with the original (non-fluent) builder implementation. Did you mean to show how it is possible with the fluent builder implementation to create a DELETE request with a one-liner? You have such an example two code blocks later.
Tyson, you are, of course, right. The default behaviour could also have been a one-liner with the non-fluent design. Every other configuration, however, can't be a one-liner with the Gang-of-Four pattern, while it can in the Fluent guise.
Among the example uses of your HttpRequestMessageBuilder, I see three HTTP verbs used: GET, DELETE, and POST. Furthermore, a body is added if and only if the method is POST. This matches my expectations gained from my limited experience doing web programming. If a GET or DELETE request had a body or if a POST request did not have a body, then I would suspect that such behavior was a bug.
For the sake of a question that I would like to ask, let's suppose that a body must be added if and only if the method is POST. Under this assumption, HttpRequestMessageBuilder can create invalid messages. For example, it can create a GET request with a body, and it can create a POST request without a body. Under this assumption, how would you modify your design so that only valid messages can be created?
Tyson, thank you for another inspiring question! It gives me a good motivation to write about polymorphic Builders. I'll try to address this question in a future article.
Tyson, I've now attempted to answer your question in a new article.
Non-exceptional averages
How do you code without exceptions? Here's one example.
Encouraging object-oriented programmers to avoid throwing exceptions is as fun as telling them to renounce null references. To be fair, exception-throwing is such an ingrained feature of C#, Java, C++, etcetera that it can be hard to see how to do without it.
To be clear, I don't insist that you pretend that exceptions don't exist in languages that have them. I'm also not advocating that you catch all exceptions in order to resurface them as railway-oriented programming. On the other hand, I do endorse the generally good advice that you shouldn't use exceptions for control flow.
What can you do instead? Despite all the warnings against railway-oriented programming, Either is still a good choice for a certain kind of control flow. Exceptions are for exceptional situations, such as network partitions, running out of memory, disk failures, and so on. Many run-time errors are both foreseeable and preventable. Prefer code that prevents errors.
There's a few ways you can do that. One of them is to protect invariants by enforcing pre-conditions. If you have a static type system, you can use the type system to prevent errors.
Average duration #
How would you calculate the average of a set of durations? You might, for example, need to calculate average duration of message handling for a polling consumer. C# offers many built-in overloads of the Average extension method, but none that calculates the average of TimeSpan values.
How would you write that method yourself?
It's not a trick question.
Based on my experience coaching development teams, this is a representative example:
public static TimeSpan Average(this IEnumerable<TimeSpan> timeSpans) { var sum = TimeSpan.Zero; var count = 0; foreach (var ts in timeSpans) { sum += ts; count++; } return sum / count; }
This gets the job done in most situations, but it has two error modes. It doesn't work if timeSpans is empty, and it doesn't work if it's infinite.
When the input collection is empty, you'll be trying to divide by zero, which isn't allowed. How do you deal with that? Most programmers I've met just shrug and say: don't call the method with an empty collection. Apparently, it's your responsibility as the caller. You have to memorise that this particular Average method has that particular precondition.
I don't think that's a professional position. This puts the burden on client developers. In a world like that, you have to learn by rote the preconditions of thousands of APIs.
What can you do? You could add a Guard Clause to the method.
Guard Clause #
Adding a Guard Clause doesn't really make the method much easier to reason about for client developers, but at least it protects an invariant.
public static TimeSpan Average(this IEnumerable<TimeSpan> timeSpans) { if (!timeSpans.Any()) throw new ArgumentOutOfRangeException( nameof(timeSpans), "Can't calculate the average of an empty collection."); var sum = TimeSpan.Zero; var count = 0; foreach (var ts in timeSpans) { sum += ts; count++; } return sum / count; }
Don't get me wrong. I often write code like this because it makes it easier for me as a library developer to reason about the rest of the method body. On the other hand, it basically just replaces one run-time exception with another. Before I added the Guard Clause, calling Average with an empty collection would cause it to throw an OverflowException; now it throws an ArgumentOutOfRangeException.
From client developers' perspective, this is only a marginal improvement. You're still getting no help from the type system, but at least the run-time error is a bit more informative. Sometimes, that's the best you can do.
Finite collections #
The Average method has two preconditions, but we've only addressed one. The other precondition is that the input timeSpans must be finite. Unfortunately, this compiles:
static IEnumerable<T> InfinitelyRepeat<T>(T x) { while (true) yield return x; } var ts = new TimeSpan(1, 2, 3, 4); var tss = InfinitelyRepeat(ts); var avg = tss.Average();
Since tss infinitely repeats ts, the Average method call (theoretically) loops forever; in fact it quickly overflows because it keeps adding TimeSpan values together.
Infinite collections aren't allowed. Can you make that precondition explicit?
I don't know of a way to test that timeSpans is finite at run time, but I can change the input type:
public static TimeSpan Average(this IReadOnlyCollection<TimeSpan> timeSpans) { if (!timeSpans.Any()) throw new ArgumentOutOfRangeException( nameof(timeSpans), "Can't calculate the average of an empty collection."); var sum = TimeSpan.Zero; foreach (var ts in timeSpans) sum += ts; return sum / timeSpans.Count; }
Instead of accepting any IEnumerable<TimeSpan> as an input argument, I've now constrained timeSpans to an IReadOnlyCollection<TimeSpan>. This interface has been in .NET since .NET 4.5 (I think), but it lives a quiet existence. Few people know of it.
It's just IEnumerable<T> with an extra constraint:
public interface IReadOnlyCollection<T> : IEnumerable<T> { int Count { get; } }
The Count property strongly implies that the IEnumerable<T> is finite. Also, that the value is an int implies that the maximum size of the collection is 2,147,483,647. That's probably going to be enough for most day-to-day use.
You can no longer pass an infinite stream of values to the Average method. It's simply not going to compile. That both communicates and protects the invariant that infinite collections aren't allowed. It also makes the implementation code simpler, since the method doesn't have to count the elements. That information is already available from timeSpans.Count.
If a type can address one invariant, can it also protect the other?
Non-empty collection #
You can change the input type again. Here I've used this NotEmptyCollection<T> implementation:
public static TimeSpan Average(this NotEmptyCollection<TimeSpan> timeSpans) { var sum = timeSpans.Head; foreach (var ts in timeSpans.Tail) sum += ts; return sum / timeSpans.Count; }
Now client code can no longer call the Average method with an empty collection. That's also not going to compile.
You've replaced a run-time check with a compile-time check. It's now clear to client developers who want to call the method that they must supply a NotEmptyCollection<TimeSpan>, instead of just any IReadOnlyCollection<TimeSpan>.
You can also simplify the implementation code:
public static TimeSpan Average(this NotEmptyCollection<TimeSpan> timeSpans) { var sum = timeSpans.Aggregate((x, y) => x + y); return sum / timeSpans.Count; }
How do we know that NotEmptyCollection<T> contains at least one element? The constructor enforces that constraint:
public NotEmptyCollection(T head, params T[] tail) { if (head == null) throw new ArgumentNullException(nameof(head)); this.Head = head; this.Tail = tail; }
But wait, there's a Guard Clause and a throw there! Have we even accomplished anything, or did we just move the throw around?
Parse, don't validate #
A Guard Clause is a kind of validation. It validates that input fulfils preconditions. The problem with validation is that you have to repeat it in various different places. Every time you receive some data as an input argument, it may or may not have been validated. A receiving method can't tell. There's no flag on a string, or a number, or a collection, which is set when data has been validated.
Every method that receives such an input will have to perform validation, just to be sure that the preconditions hold. This leads to validation code being duplicated over a code base. When you duplicate code, you later update it in most of the places it appears, but forget to update it in a few places. Even if you're meticulous, a colleague may not know about the proper way of validating a piece of data. This leads to bugs.
As Alexis King explains in her Parse, don’t validate article, 'parsing' is the process of validating input of weaker type into a value of a stronger type. The stronger type indicates that validation has happened. It's like a Boolean flag that indicates that, yes, the data contained in the type has been through validation, and found to hold.
This is also the case of NotEmptyCollection<T>. If you have an object of that type, you know that it has already been validated. You know that the collection isn't empty. Even if you think that it looks like we've just replaced one exception with another, that's not the point. The point is that we've replaced scattered and unsystematic validation code with a single verification step.
You may still be left with the nagging doubt that I didn't really avoid throwing an exception. I think that the NotEmptyCollection<T> constructor strikes a pragmatic balance. If you look only at the information revealed by the type (i.e. what an IDE would display), you'll see this when you program against the class:
public NotEmptyCollection(T head, params T[] tail)
While you could, technically, pass null as the head parameter, it should be clear to you that you're trying to do something you're not supposed to do: head is not an optional argument. Had it been optional, the API designer should have provided an overload that you could call without any value. Such a constructor overload isn't available here, so if you try to cheat the compiler by passing null, don't be surprised to get a run-time exception.
For what it's worth, I believe that you can only be pragmatic if you know how to be dogmatic. Is it possible to protect NotEmptyCollection<T>'s invariants without throwing exceptions?
Yes, you could do that by making the constructor private and instead afford a static factory method that returns a Maybe or Either value. In Haskell, this is typically called a smart constructor. It's only a few lines of code, so I could easily show it here. I chose not to, though, because I'm concerned that readers will interpret this article the wrong way. I like Maybe and Either a lot, but I agree with the above critics that it may not be idiomatic in object-oriented languages.
Summary #
Encapsulation is central to object-oriented design. It's the notion that it's an object's own responsibility to protect its invariants. In statically typed object-oriented programming languages, objects are instances of classes. Classes are types. Types encapsulate invariants; they carry with them guarantees.
You can sometimes model invariants by using types. Instead of performing a run-time check on input arguments, you can declare constructors and methods in such a way that they only take arguments that are already guaranteed to be valid.
That's one way to reduce the amount of exceptions that your code throws.
Comments
Great post. I too prefer to avoid exceptions by strengthening preconditions using types.
Sincetssinfinitely repeatsts, theAveragemethod call (theoretically) loops forever; in fact it quickly overflows because it keeps addingTimeSpanvalues together.
I am not sure what you mean here. My best guess is that you are saying that this code would execute forever except that it will overflow, which will halt the execution. However, I think the situation is ambiguous. This code is impure because, as the Checked and Unchecked documentation says, its behavior depends on whether or not the -checked compiler option is given. This dependency on the compiler option can be removed by wrapping this code in a checked or unchecked block, which would either result in a thrown exception or an infinite loop respectively.
This gets the job done in most situations, but it has two error modes. It doesn't work if timeSpans is empty, and it doesn't work if it's infinite.
There is a third error mode, and it exists in every implementation you gave. The issue of overflow is not restricted to the case of infinitely many TimeSpans. It only takes two. I know of or remember this bug as "the last binary search bug". That article shows how to correctly compute the average of two integers without overflowing. A correct implementation for computing the average of more than two integers is to map each element to a mixed fraction with the count as the divisor and then appropriately aggregate those values. The implementation given in this Quora answer seems correct to me.
I know all this is unrelated to the topic of your post, but I also know how much you prefer to use examples that avoid this kind of accidental complexity. Me too! However, I still like your example and can't think of a better one at the moment.
Tyson, thank you for writing. Given an infinite stream of values, the method throws an OverflowException. This is because TimeSpan addition explicitly does that:
> TimeSpan.MaxValue + new TimeSpan(1) System.OverflowException: TimeSpan overflowed because the duration is too long. + System.TimeSpan.Add(System.TimeSpan) + System.TimeSpan.op_Addition(System.TimeSpan, System.TimeSpan)
This little snippet from C# Interactive also illustrates the third error mode that I hadn't considered. Good point, that.
Ah, yes. You are correct. Thanks for pointing out my mistake. Another way to verify this is inspecting TimeSpan.Add in Mircosoft's reference source. I should have done those checks before posting. Thanks again!
The Maître d' kata
A programming kata.
I recently wrote about doing programming katas. You can find katas in many different places. Some sites exist exclusively for that purpose, such as the Coding Dojo or CodeKata. In other cases, you can find individual katas on blogs; one of my favourites is the Diamond kata. You can also lift exercises from other sources and treat them as katas. For example, I recently followed Mike Hadlow's lead and turned a job applicant test into a programming exercise. I've also taken exercises from books and repurposed them. For example, I've implemented the Graham Scan algorithm for finding convex hulls a couple of times.
In this article, I'll share an exercise that I've found inspiring myself. I'll call it the Maître d' kata.
I present no code in this article. Part of what makes the exercise interesting, I think, is to figure out how to model the problem domain. I will, however, later publish one of my attempts at the kata.
Problem statement #
Imagine that you're developing an online restaurant reservation system. Part of the behaviour of such a system is to decide whether or not to accept a reservation. At a real restaurant, employees fill various roles required to make it work. In a high-end restaurant, the maître d' is responsible for taking reservations. I've named the kata after this role. If you're practising domain-driven design, you might want to name your object, class, or module MaîtreD or some such.
The objective of the exercise is to implement the MaîtreD decision logic.
Reservations are accepted on a first-come, first-served basis. As long as the restaurant has available seats for the desired reservation, it'll accept it.
A reservation contains, at a minimum, a date and time as well as a positive quantity. Here's some examples:
| Date | Quantity |
| August 8, 2050 at 19:30 | 3 |
| November 27, 2022 at 18:45 | 4 |
| February 27, 2014 at 13:22 | 12 |
Notice that dates can be in your future or past. You might want to assume that the maître d' would reject reservations in the past, but you can't assume when the code runs (or ran), so don't worry about that. Notice also that quantities are positive integers. While a quantity shouldn't be negative or zero, it could conceivably be large. I find it realistic, however, to keep quantities at low two-digit numbers or less.
A reservation will likely contain other data, such as the name of the person making the reservation, contact information such as email or phone number, possibly also an ID, and so on. You may add these details if you want to make the exercise more realistic, but they're not required.
I'm going to present one feature requirement at a time. If you read the entire article before you do the exercise, it'd correspond to gathering detailed requirements before starting to code. Alternatively, you could read the first requirement, do the exercise, read the next requirement, refactor your code, and so on. This would simulate a situation where your organisation gradually uncovers how the system ought to work.
Boutique restaurant #
As readers of my book may have detected, I'm a foodie. Some years ago I ate at Blanca in Brooklyn. That restaurant has one communal bar where everyone sits. There was room for twelve people, and dinner started at 19:00 whether you arrived on time or not. Such restaurants actually exist. It's an easy first step for the kata. Assume that the restaurant is only open for dinner, has no second seating, and a single shared table. This implies that the time of day of reservations doesn't matter, while the date still matters. Some possible test cases could be:
| Table size | Existing reservations | Candidate reservation | Expected outcome |
| 12 | none | Quantity: 1 | Accepted |
| 12 | none | Quantity: 13 | Rejected |
| 12 | none | Quantity: 12 | Accepted |
| 4 | Quantity: 2, Date: 2023-09-14 | Quantity: 3, Date: 2023-09-14 | Rejected |
| 10 | Quantity: 2, Date: 2023-09-14 | Quantity: 3, Date: 2023-09-14 | Accepted |
| 10 |
Quantity: 3, Date: 2023-09-14 Quantity: 2, Date: 2023-09-14 Quantity: 3, Date: 2023-09-14 |
Quantity: 3, Date: 2023-09-14 | Rejected |
| 4 | Quantity: 2, Date: 2023-09-15 | Quantity: 3, Date: 2023-09-14 | Accepted |
This may not be an exhaustive set of test cases, but hopefully illustrates the desired behaviour. Try using the Devil's Advocate technique or property-based testing to identify more test cases.
Haute cuisine #
The single-shared-table configuration is unusual. Most restaurants have separate tables. High-end restaurants like those on the World's 50 best list, or those with Michelin stars often have only a single seating. This is a good expansion of the domain logic.
Assume that a restaurant has several tables, perhaps of different sizes. A table for four will seat one, two, three, or four people. Once a table is reserved, however, all the seats at that table are reserved. A reservation for three people will occupy a table for four, and the redundant seat is wasted. Obviously, the restaurant wants to maximise the number of guests, so it'll favour reserving two-person tables for one and two people, four-person tables for three and four people, and so on.
In order to illustrate the desired behaviour, here's some extra test cases to add to the ones already in place:
| Tables | Existing reservations | Candidate reservation | Expected outcome |
|
Two tables for two Two tables for four |
none | Quantity: 4, Date: 2024-06-07 | Accepted |
|
Two tables for two Two tables for four |
none | Quantity: 5, Date: 2024-06-07 | Rejected |
|
Two tables for two One table for four |
Quantity: 2, Date: 2024-06-07 | Quantity: 4, Date: 2024-06-07 | Accepted |
|
Two tables for two One table for four |
Quantity: 3, Date: 2024-06-07 | Quantity: 4, Date: 2024-06-07 | Rejected |
Again, you should consider adding more test cases if you're unit-testing the kata.
Second seatings #
Some restaurants (even some of those on the World's 50 best list) have a second seating. As a diner, you have a limited time (e.g. 2½ hours) to complete your meal. After that, other guests get your table.
This implies that you must now consider the time of day of reservations. You should also be able to use an arbitrary (positive) seating duration. All previous rules should still apply. New test cases include:
| Seating duration | Tables | Existing reservations | Candidate reservation | Expected outcome |
| 2 hours |
Two tables for two One table for four |
Quantity: 4, Date: 2023-10-22, Time: 18:00 | Quantity: 3, Date: 2023-10-22, Time: 20:00 | Accepted |
| 2½ hours |
One table for two Two tables for four |
Quantity: 2, Date: 2023-10-22, Time: 18:00 Quantity: 1, Date: 2023-10-22, Time: 18:15 Quantity: 2, Date: 2023-10-22, Time: 17:45 |
Quantity: 3, Date: 2023-10-22, Time: 20:00 | Rejected |
| 2½ hours |
One table for two Two tables for four |
Quantity: 2, Date: 2023-10-22, Time: 18:00 Quantity: 2, Date: 2023-10-22, Time: 17:45 |
Quantity: 3, Date: 2023-10-22, Time: 20:00 | Accepted |
| 2½ hours |
One table for two Two tables for four |
Quantity: 2, Date: 2023-10-22, Time: 18:00 Quantity: 1, Date: 2023-10-22, Time: 18:15 Quantity: 2, Date: 2023-10-22, Time: 17:45 |
Quantity: 3, Date: 2023-10-22, Time: 20:15 | Accepted |
If you make the seating duration short enough, you may even make room for a third seating, and so on.
Alternative table configurations #
If tables are rectangular, the restaurant has the option to combine several smaller tables into one larger. Consider a typical restaurant layout like this:
There's a round four-person table, as well as a few small tables that can't easily be pushed together. There's also three (orange) two-person tables where one guest sits against the wall, and the other diner faces him or her. These can be used as shown above, but the restaurant can also push two of these tables together to accommodate four people:
This still leaves one of the adjacent two-person tables as an individual table, but the restaurant can also push all three tables together to accommodate six people:
Implement decision logic that allows for alternative table configurations. Remember to take seating durations into account. Consider both the configuration illustrated, as well as other configurations. Note that in the above configuration, not all two-person tables can be combined.
More domain logic #
You can, if you will, invent extra rules. For example, restaurants have opening hours. A restaurant that opens at 18:00 and closes at 0:00 will not accept reservations for 13:30, regardless of table configuration, existing reservations, seating duration, and so on.
Building on that idea, some restaurants have different opening hours on various weekdays. Some are closed Mondays, serve dinner only Tuesday to Friday, but are then open for both lunch and dinner in the weekend.
Going in that direction, however, opens a can of worms. Perhaps the restaurant is closed on public holidays. Or perhaps it's explicitly open on public holidays, to cater for an audience that may not otherwise dine out. But implementing a holiday calender is far from as simple as it sounds. That's the reason I left such rules out of the above specifications of the kata.
Another idea that you may consider is to combine communal bar seating with more traditional tables. The Clove Club is an example of restaurant that does it that way.
Summary #
This is a programming kata description. Implement the decision logic of a maître d': Can the restaurant accept a given reservation?
After some time has gone by, I'll post at least one of my own attempts. You're welcome to leave a comment if you do the kata and wish to share your results.
Algebraic data types aren't numbers on steroids
A common red herring in the type debate.
I regularly get involved in debates about static versus dynamic typing. This post isn't an attempt to persuade anyone that static types are better. One of the reasons that I so often find myself debating this topic is that it intrigues me. I get the impression that most of the software luminaries that I admire (e.g. Kent Beck, Robert C. Martin, Michael Feathers) seem to favour dynamically typed languages. What is it that smart people have figured out that I haven't?
The debate continues, and this article isn't going to stop it. It may, perhaps, put one misconception to rest. There are still good arguments on either side. It's not my goal to dispute any of the good arguments. It's my goal to counter a common bad argument.
Misconception: static typing as numbers on steroids #
I get the impression that many people think about static types as something that has to do with strings and numbers - particularly numbers. Introductions to programming languages often introduce strings first. That's natural, since the most common first example is Hello, world!. After that usually follows an introduction to basic arithmetic, and that often includes an explanation about types of numbers - at least the distinction between integers and floating-point numbers. At the time I'm writing this, the online C# tutorial is a typical example of this. Real World Haskell takes the same approach to introducing types.
It's a natural enough way to introduce static types, but it seems to leave some learners with the impression that static types are mostly useful to prevent them from calling a method with a floating-point number when an integer was expected. That's the vibe I'm getting from this article by Robert C. Martin.
When presented with the notion of a 'stronger' type system, people with that mindset seem to extrapolate what they already know about static types.

If you mostly think of static types as a way to distinguish between various primitive types (such as strings and a zoo of number types), I can't blame you for extrapolating that notion. This seems to happen often, and it leads to a lot of frustration.
People who want 'stronger numbers' try to:
- Model natural numbers; i.e. to define a type that represents only positive integers
- Model positive numbers; i.e. rational or real numbers greater than zero
- Model non-negative numbers
- Model numbers in a particular range; e.g. between 0 and 100
- Model money in different currencies
Haskell does have a powerful type system, but it's a type system that builds on the concept of algebraic data types. (If you want to escape the jargon of that Wikipedia article, I recommend Tomas Petricek's lucid and straightforward explanation Power of mathematics: Reasoning about functional types.)
There are type systems that enable you to take the notion of numbers to the next level. This is called either refinement types or dependent types, contingent on what exactly it is that you want to do. Haskell doesn't support that out of the box. The most prominent dependently-typed programming language is probably Idris, which is still a research language. As far as I know, there's no 'production strength' languages that support refinement or dependent types, unless you consider Liquid Haskell to fit that description. Honestly, all this is at the fringe of my expertise.
I'll return to an example of this kind of frustration later, and also suggest a simple alternative. Before I do that, though, I'd like to outline what it is proponents of 'strong' type systems mean.
Make illegal states unrepresentable #
Languages like Haskell, OCaml, and F# have algebraic type systems. They still distinguish between various primitive types, but they take the notion of static types in a completely different direction. They introduce a new dimension of static type safety, so to speak.
It's a completely different way to think about static types. The advantage isn't that it prevents you from using a floating point where an integer was required. The advantage is that it enables you to model domain logic in a way that flushes out all sorts of edge cases at compile time.
I've previously described a real-world example of domain modelling with types, so I'm not going to repeat that effort here. Most business processes can be described as a progression of states. With algebraic data types, not only can you model what a valid state looks like - you can also model the state machine in such a way that you can't represent illegal states.
This notion is eloquently captured by the aphorism:
This is solving an entirely different type of problem than distinguishing between 32-bit and 64-bit integers. Writing even moderately complex code involves dealing with many edge cases. In most mainstream languages (including C# and Java), it's your responsibility to ensure that you've handled all edge cases. It's easy to overlook or forget a few of those. With algebraic data types, the compiler keeps track of that for you. That's a tremendous boon because it enables you to forget about those technical details and instead focus on adding value.Make illegal states unrepresentable.
Scott Wlaschin wrote an entire book about domain modelling with algebraic data types. That's what we talk about when we talk about stronger type systems. Not 'numbers on steroids'.
Exhibit: summing notionals #
I consider this notion of strong type systems viewed as numbers on steroids a red herring. I don't blame anyone from extrapolating from what they already know. That's a natural way to try to make sense of the world. We all do it.
I came across a recent example of this way of thinking in a great article by Alex Nixon titled Static types are dangerously interesting. The following is in no way meant to excoriate Alex or his article, but I think it's a great example of how easily one can be lead astray by thinking that strong type systems imply numbers on steroids.
You should read the article. It's well-written and uses more sophisticated features of Haskell than I'm comfortable with. The example problem it tries to solve is basically this: Given a set of trades, calculate the total notional in each currency. Consider a collection of trades:
Quantity, Ticker, Price, Currency 100, VOD.L, 1, GBP 200, VOD.L, 2, GBP 300, AAPL.O, 3, USD 50, 4151.T, 5, JPY
I'll let Alex explain what it is that he wants to do:
If given the above trades, the output would be:"I want to write a function which calculates the total notional in each currency. The word notional is a fancy way of saying
price * quantity. Think of it as "value of the thing that changed hands"."For illustration, the function signature might look something like this:
"
sumNotionals :: [Trade] -> Map Currency Rational"In English, it’s a function that takes a list of trades and returns a map from currency to quantity."
Currency, Notional GBP, 500 USD, 900 JPY, 250
The article proceeds to explore how to model this problem with Haskell's strong type system. Alex wants to be able to calculate with money, but on the other hand, he wants the type system to prevent accidents. You can't add 100 GBP to 300 USD. The type system should prevent that.
Early on, he defines a sum type to model currencies:
data Currency = USD | GBP | JPY deriving (Eq, Ord, Show)
Things basically go downhill from there. Read the article; it's good.
Sum types should distinguish behaviour, not values #
I doubt that Alex Nixon views his proposed Currency type as anything but a proof of concept. In a 'real' code base, you'd enumerate all the currencies you'd trade, right?
I wouldn't. This is the red herring in action. Algebraic data types are useful because they enable us to distinguish between cases that we should treat differently, by writing specific code that deals with each case. That's not the case with a currency. You add US dollars together in exactly the same way that you add euros together. The currency doesn't change the behaviour of that operation.
But we can't just enable addition of arbitrary monetary values, right? After all, we shouldn't be able to add 20 USD and 300 DKK. At least, without an exchange rate, that shouldn't compile.
Let's imagine, for the sake of argument, that we encode all the currencies we trade into a type. What happens if our traders decide to trade a currency that they haven't previously traded? What if a country decides to reset their currency? What if a country splits into two countries, each with their own currency?
If you model currency as a type, you'd have to edit and recompile your code every time such an external event occurs. I don't think this is a good use of a type system.
Types should, I think, help us programmers identify the parts of our code bases where we need to treat various cases differently. They shouldn't be used to distinguish run-time values. Types provide value at compile time; run-time values only exist at run time. To paraphrase Kent Beck, keep things together that change together; keep things apart that don't.
I'd model currency as a run-time value, because the behaviour of money doesn't vary with the currency.
Boring Haskell #
How would I calculate the notionals, then? With boring Haskell. Really boring Haskell, in fact. I'm only going to need two imports and no language pragmas:
module Trades where import Data.List import Data.Map.Strict (Map) import qualified Data.Map.Strict as Map
Which types do I need? For this particular purpose, I think I'll just stick with a single Trade type:
data Trade = Trade { tradeQuantity :: Int , tradeTicker :: String , tradePrice :: Rational , tradeCurrency :: String } deriving (Eq, Show)
Shouldn't I introduce a Money type? I could, but I don't have to. As Alexis King so clearly explains, you don't have to model more than you need to do the job.
By not introducing a Money type and making it an instance of various type classes, I still prevent client code from adding things together that shouldn't be added together. You can't add Trade values together because Trade isn't a Num instance.
How do we calculate the notionals, then? It's easy; it's a one-liner:
sumNotionals :: Foldable t => t Trade -> Map String Rational sumNotionals = foldl' (\m t -> Map.insertWith (+) (key t) (value t) m) Map.empty where key (Trade _ _ _ currency) = currency value (Trade quantity _ price _) = toRational quantity * price
Okay, that looks more like four lines of code, but the first is an optional type declaration, so it doesn't count. The key and value functions could be inlined to make the function a single (wide) line of code, but I made them two named functions in order to make the code more readable.
It gets the job done:
*Trades> sumNotionals trades
fromList [("GBP",500 % 1),("JPY",250 % 1),("USD",900 % 1)]
While this code addresses this particular problem, you probably consider it cheating because I've failed to address a wider concern. How does one model money in several currencies? I've previously covered that, including a simple Haskell example, but in general, I consider it more productive to have a problem and then go looking for a solution, rather than inventing a solution and go looking for a problem.
Summary #
When people enter into a debate, they use the knowledge they have. This is also the case in the debate about static versus dynamic types. Most programmers have experience with statically typed languages like C# or Java. It's natural to argue from what you know, and extrapolate from that.
I think that when confronted with a phrase like a more powerful type system, many people extrapolate and think that they know what that means. They think that it means statically typed numbers on steroids. That's a red herring.
That's usually not what we mean when we talk about more powerful type systems. We talk about algebraic data types, which make illegal states unrepresentable. Judged by the debates I've participated in, you can't extrapolate from mainstream type systems to algebraic data types. If you haven't tried programming with both sum and product types, you aren't going to grok what we mean when we talk about strong type systems.
Comments
"but in general, I consider it more productive to have a problem and then go looking for a solution, rather than inventing a solution and go looking for a problem."
This really resonates with me. I've been observing this in my current team and the tendency to "lookout" for the solutions to problems not yet present, just for the sake of "making it a robust solution" so to say.
I really like the properties of the Haskell solution. It handles all the currencies (no matter how many of them come in the dataset) without explicitly specifying them. And you can't accidentally add two different currencies together. The last part would be pretty verbose to implement in C#.
I'm not sure the above is a good example of what you're trying to say about algebraic data types. The problem can be solve identically (at least semantically) in C#. Granted, the definition of the Trade type would be way more verbose, but once you have that, the SumNotionals method is basically the same as you code, albeit with different syntax:
Dictionary<string, int> SumNotionals(IEnumerable<Trade> trades)
{
return trades
.GroupBy(t => t.Currency, t => t.Price * t.Quantity)
.ToDictionary(g => g.Key, g => g.Sum());
}
Am I missing something?
You are right Andrew. The LINQ query indeed has the same properites as the Haskell function.
I'm not sure what I was thinking yesterday, but I think I subconsciously "wanted" C# to be less robust.
Andrew, thank you for writing. I didn't intend to say much about algebraic data types in this article. It wasn't the topic I had in mind. It can be difficult to communicate any but the simplest ideas, so it's possible that I didn't state my intention well enough. If so, the fault is mine. I've tried to demonstrate the power of algebraic data types before, so I didn't want to repeat the effort, since my agenda was another. That's why I linked to that other article.
The reason I discussed Alex Nixon's blog post was that it was the article that originally inspired me to write this article. I always try to include an example so that the reader gets to see the connection between the general concept and specifics.
I could have discussed Alex' article solely on its merits of showcasing failed attempts to model a 'stronger number'. That would, however, have left the reader without a resolution. I found that a bad way to structure my text. Readers would be left with questions. Okay Mark, that's all fine, but then how would you solve the problem?
So I decided to include a simple solution in an attempt to cut the Gordian know, so to speak.
Mark, thanks for your response. It does indeed clear up my confusion. In my eagerness to learn more about algrebraic data types I read the second half of your post the wrong way. Thanks for clearing it up.
On doing katas
Approach programming katas differently than martial arts katas.
Would you like to become a better programmer? Then practice. It's no different from becoming a better musician, a better sports(wo)man, a better cook, a better artist, etcetera.
How do you practice programming?
There's many ways. Doing programming katas is one way.
Variation, not repetition #
When I talk to other programmers about katas, I often get the impression that people fail to extract value from the exercises. You can find catalogues of exercises on the internet, but there's a dearth of articles that discuss how to do katas.
Part of the problem is, I think, that the term comes from martial arts practice. In martial arts, one repeats the same movements over and over again in order to build up muscle memory. Repetition produces improvements.
Some people translate that concept literally. They try to do programming katas by doing the same exercise again and again, with no variation. After a few days or weeks, they stop because they can't see the point.
That's no wonder. Neither can I.
Programming and software design is mostly an intellectual (and perhaps artistic) endeavour. Unless you can't touch type, there's little need to build up muscle memory. You train your brain unlike you train your muscles. Repetition numbs the brain. Variation stimulates it.
Suggested variations #
I find that doing a kata is a great opportunity to explore alternatives. A kata is usually a limited exercise, which means that you can do it multiple times and compare outcomes.
You can find various kata catalogues on the internet. One of my favourites is the Coding Dojo. Among the katas there, I particularly like the Tennis kata. I'll use that as an example to describe how I often approach a kata.
The first time I encounter a kata I've never done before, I do it with as little fuss as possible. I use the programming language I'm most comfortable with, and don't attempt any stunts. I no longer remember when I first encountered the Tennis kata, but it's many years ago, and C# was my preferred language. I'd do the Tennis kata in C#, then, just to get acquainted with the problem.
Most good katas contain small surprises. They may sound simpler than they actually turn out to be. On the other hand, they're typically not overwhelmingly difficult. It pays to overcome the surprise the kata may hold without getting bogged down by trying some feat. The Tennis kata, for example, sounds easy, but most people stumble on the rules associated with deuce and advantage. How to model the API? How do you implement the algorithm?
Once you're comfortable with the essence of the exercise, introduce variations. Most of the variations I use take the form of some sort of constraint. Constraints liberate. Less is more.
Here's a list of suggestions:
- Follow test-driven development (TDD). That's my usual modus operandi, but if you don't normally practice TDD, a kata is a great opportunity.
- Use the (Gollum style) Devil's Advocate technique with TDD.
- Follow the Transformation Priority Premise.
- Do TDD without mocks.
- Do TDD with mocks.
- Use the Test Data Builder design pattern.
- Try property-based testing. I've done that with the Tennis kata multiple times.
- Put your mouse away.
- Hide the file tree in your editor or IDE. In Visual Studio, this is called the Solution Explorer, in Visual Studio Code it's just Explorer. Navigate the code by other means.
- Use another editor or IDE.
- Use another programming language. A kata is a great way to practice a new language. When you're learning a new language, you're often fighting with unfamiliar syntax, which is the reason I recommend that you first do the kata in a language with which you're familiar.
- Use only immutable data structures. This is a good first step towards learning functional programming.
- Keep the cyclomatic complexity of all methods at 1. I once did that with the Tennis kata.
- Use an unfamiliar API. If you normally use NUnit then try xUnit.net instead. Use a new Test Double library. Use a different assertion library. I once did the Tennis kata in Haskell using the lens library because I wanted to hone those skills. I've also done the Mark IV coffee maker exercise from APPP with Reactive Extensions.
- Employ a design pattern you'd like to understand better. I've had particular success with the Visitor design pattern.
- Refactor an existing kata solution to another design.
- Refactor another programmer's kata solution.
- Pair-program the kata.
- Use the Ping Pong pattern when pair programming.
- Mob-program it.
What I like about katas is that they're small enough that you can do the same exercise multiple times, but with different designs. This makes it easy to learn new ways of doing things, because you can compare different approaches to the same problem.
Conclusion #
The way that the idea of a programming kata was originally introduced is a bit unfortunate. On one hand, the metaphor may have helped adoption because martial arts are cool, and Japanese is a beautiful language. On the other hand, the underlying message is one of repetition, which is hardly helpful when it comes to exercising the brain.
Repetition dulls the brain, while variation stimulates it. Katas are great because they're short exercises, but you have to deliberately introduce diversity to make them work for you. You're not building muscle memory, you're forming new neural pathways.
Comments
Regarding kata variations, I'd like mention Jeff Bay's Object Calisthenics (by Jeff Bay). One could use all rules at once or just a subset of them.
Just briefly, this are the rules (details can be found on the web):
- One level of indentation per method
- Don’t use the ELSE keyword
- Wrap all primitives and strings
- First class collections
- One dot per line
- Don't abbreviate
- Keep all entities small
- No classes with more than two instance variables
- No getters/setters/properties
Johannes, that list is a great addition to my suggestions. Thank you.
The case of the unbalanced brackets
A code mystery.
One of my clients was kind enough to let me look at some of their legacy code. As I was struggling to understand how it worked, I encountered something that looked like this:
ApplyDueAmountG89.Calculate(postState.PartialMebershipsBAT.Where( d => (d.Data.Choicetype == GarplyChoicetype.AtoC || retirablePartialMembershipNr.Contains(d.Data.PartialMembershipNr)).ToList(), ApplyDueAmountG89.Situation.Depreciation, ApplyDueAmountG89.RecordType.Primo);
For the record, this isn't the actual code that my client gave me. I wouldn't post someone else's code without their permission. It is, however, a faithful imitation of the original code. What's wrong with it?
I'll wait.
Brackets #
Count the brackets. There's a missing closing bracket.
Yet, the code compiles. How?
Legacy code isn't humane code. There's a multitude of ways in which code can be obscure. This article describes one of them.
When brackets are nested and far apart, it's hard for the brain to parse and balance them. Yet, on closer inspection the brackets seem unbalanced.
Show whitespace #
Ever since I started programming in F#, I've turned on the Visual Studio feature that shows whitespace. F# does, after all, use significant whitespace (AKA the Off-side rule), and it helps to be able to detect if a tab character has slipped in among the spaces.
Visual Studio shows whitespace with pale blue dots and arrows. When that feature is turned on (Ctrl + e, s), the above code example looks different:
ApplyDueAmountG89.Calculate(postState.PartialMebershipsBAT.Where( ····d·=>·(d.Data.Choicetype·==·GarplyChoicetype.AtoC·||··············································· ············retirablePartialMembershipNr.Contains(d.Data.PartialMembershipNr)).ToList(), ············ApplyDueAmountG89.Situation.Depreciation, ············ApplyDueAmountG89.RecordType.Primo);
Notice the space characters that seem to run off to the right of the || operator. What's at the end of those spaces?
Yes, you guessed it: another Boolean expression, including the missing closing bracket:
d.Data.Choicetype == GarplyChoicetype.BtoC) &&
If you delete all those redundant spaces, this is the actual code:
ApplyDueAmountG89.Calculate(postState.PartialMebershipsBAT.Where( d => (d.Data.Choicetype == GarplyChoicetype.AtoC || d.Data.Choicetype == GarplyChoicetype.BtoC) && retirablePartialMembershipNr.Contains(d.Data.PartialMembershipNr)).ToList(), ApplyDueAmountG89.Situation.Depreciation, ApplyDueAmountG89.RecordType.Primo);
Imagine troubleshooting code like that, and not realising that there's another Boolean expression so far right that even a large screen doesn't show it. In the actual legacy code where I found this example, the extra Boolean expression started at column 209.
Conclusion #
Hiding significant code so far right that it's effectively invisible seems positively evil, but I don't think anyone did it deliberately. Rather, my guess is that someone performed a search-and-replace through the code base, and that this automatic change somehow removed a newline character.
In any case, keeping an eye on the line width of code could prevent something like this from happening. Stay within 80 characters.

Comments
I know of essentially one occurrence in .NET. Starting with
IEnumerable<T>, calling either of the extension methods OrderBy or OrderByDescending returnsIOrderedEnumerable<T>, which has the additional extension methods ThenBy and ThenByDescending.Quoting your recent Builder isomorphisms post.
I also find the builder pattern useful because its methods typically accept one argument one at a time. The builders in your recent posts are like this. The
OrderByandThenBymethods and theirDescendingalternatives in .NET are also examples of this.However, some of the builders in your recent posts have some constructors that take multiple arguments. That is the situation that I was trying to address when I asked
This could be a kata variation: all public functions accept at most one argument. So
Foo(a, b)would not be allowed butFoo.WithA(a).WithB(b)would. In an issue on this blog's GitHub, jaco0646 nicely summerized the reasoning that could lead to applying this design philosophy to production code by sayingThat comment by jaco0646 also supplied names by which this type of design is known. Those names (with the same links from the comment) are Builder with a twist or Step Builder. This is great, because I didn't have any good names. (I vaguely recall once thinking that another name was "progressive API" or "progressive fluent API", but now when I search for anything with "progressive", all I get are false positives for progressive web app.
When replacing a multi-argument constructor with a sequence of function calls that each accept one argument, care must be taken to ensure that illegal state remains unrepresentable. My general impression is that many libraries have designed such APIs well. The two that I have enough experience with to recommend as good examples of this design are the fluent configuration API in Entity Framework and Fluent Assertions. As I said before, the most formal treatment I have seen about this type of API design was in this blog post.
Tyson, apart from as a kata constraint, is there any reason to prefer such a design?
I'll be happy to give it a more formal treatment if there's reasonable scenario. Can you think of one?
I don't find the motivation given by jaco0646 convincing. If you have more than a handful of required parameters, I agree that that's an issue with complexity, but I don't agree that the solution is to add more complexity on top of it. Builders add complexity.
At a glance, though, with something like
Foo.WithA(a).WithB(b)it seems to me that you're essentially reinventing currying the hard way around.Related to the overall Builder discussion (but not to currying) you may also find this article and this Stack Overflow answer interesting.
Yes. Just like you, I want to write small functions. In that post, you suggest an arbitrary maximum of 24 lines. One thing I find fascinating about functional programming is how useful the common functions are (such as
map) and how they are implemented in only a few lines (often just one line). There is a correlation between the number of function arguments and the length of the function. So to help control the length of a function, it helps to control the number of arguments to the functions. I think Robert Martin has a similar argument. When talking about functions in chapter 3 of Clean Code, his first section is about writing small functions and a later section about function arguments open by sayingIn the C# code
a.Foo(b),Foois an instance method that "feels" like it only has one argument. In reality, its two inputs areaandb, and that code uses infix notation. The situation is similar in the F# codea |> List.map f. The functionList.map(as well as the operator|>) has two arguments and is applied using infix notation. I try to avoid creating functions that have more than two arguments.I am not sure how you are measuring complexity. I like to think that there are two types of complexity: local and global. For the sake of argument, let's suppose
- that local complexity is only defined for a function and is the number of arguments of that function and
- that global complexity is only defined for a entire program and is the number of lines in the program.
I would argue that many required arguments is an issue of local complexity. We can decrease the local complexity at the expense of increasing the global complexity by replacing one function accepting many arguments with several functions accepting fewer arguments. I like to express this idea with the phrase "minimize the maximum (local) complexity".Indeed, that is a nice article. Finite state machines/automata (both deterministic and nondeterministic) have the same expressiveness as regular expressions.
It is. As a regular expression, it would be something like
AB. I was just trying to give a simple example. The point of the article you shared is that the builder pattern is much more expressive. I have previously shared a similar article, but I like yours better. Thanks :)Wow. That is extremely cleaver! I would never thought of that. Thank you very much for sharing.
As I said above, I often try to find ways to minimize the maximum complexity of the code that I write. In this case, the reason that I originally asked you about the builder pattern is that I was trying to improve the API for creating a binding in Elmish.WPF. The tutorial has a great section about bindings. There are many binding types, and each has multiple ways to create it. Most arguments are required and some are optional.
Here is a closed issue that was created during the transition to the current binding API, which uses method overloading. In an attempt to come up with a better API, I suggested that we could use your suggestion to replace overloading with discriminated unions, but my co-maintainer wasn't convinced that it would be better.
Three days later, I increased the expressiveness of our bindings in this pull request. Conceptually it was a small change; I added a single optional argument. For a regular expression, such a change is trivial. However, in my case it was a delta of +300 lines of mind-numbingly boring code.
I agree with my co-maintainer that the current binding API is pretty good for the user. On the implementation side though, I am not satisfied. I want to find something better without sacrificing (and maybe even improving) the user's experience.