ploeh blog danish software design
Decouple to delete
Don't try to predict the future.
Do you know why it's called spaghetti code? It's a palatable metaphor. You may start with a single spaghetto, but usually, as you wind your fork around it, the whole dish follows along. Unless you're careful, eating spaghetti can be a mess.

Spaghetti code is tangled and everything is directly or transitively connected to everything else. As you try to edit the code, every change you make affects other code. Fix one thing and another thing breaks, cascading through the code base.
I was recently reading Clean Architecture, and as Robert C. Martin was explaining the Dependency Inversion Principle for the umpteenth time, my brain made a new connection. To be clear: Connecting (coupling) code is bad, but connecting ideas is good.
What a tangled web we weave #
It's impractical to write code that depends on nothing else. Most code will call other code, which again calls other code. It behoves us, though, to be careful that the web of dependencies don't get too tangled.
Imagine a code base where the dependency graph looks like this:
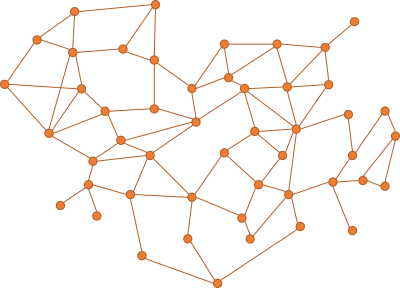
Think of each node as a unit of code; a class or a module. While a dependency graph is a directed graph, I didn't indicate the directions. Imagine that most edges point both ways, so that the nodes are interdependent. In other ways, the graph has cycles. This is not uncommon in C# code.
Pick any node in such a graph, and chances are that other nodes depend on it. This makes it hard to make changes to the code in that node, because a change may affect the code that depends on it. As you try to fix the depending code, that change, too, ripples through the network.
This already explains why tight coupling is problematic.
It is difficult to make predictions, especially about the future #
When you write source code, you might be tempted to try to take into account future needs and requirements. There may be a historical explanation for that tendency.
"That is, once it was a sign of failure to change product code. You should have gotten it right the first time."
In the days of punchcards, you had to schedule time to use a computer. If you made a mistake in your program, you typically didn't have time to fix it during your timeslot. A mistake could easily cost you days as you scrambled to schedule a new time. Not surprisingly, emphasis was on correctness.
With this mindset, it's natural to attempt to future-proof code.
YAGNI #
With interactive development environments you can get rapid feedback. If you make a mistake, change the code and observe the outcome. Don't add code because you think that you might need it later. You probably will not.
While you should avoid speculative generality, that alone is no guarantee of clean code. Unless you're careful, you can easily make a mess by tightly coupling different parts of your code base.
How do produce a code base that is as easy to change as possible?
Write code that is easy to delete #
Write code that is easy to change. The ultimate change you can make is to delete code. After that, you can write something else that better does what you need.
"A system where you can delete parts without rewriting others is often called loosely coupled"
I don't mean that you should always delete code in order to make changes, but often, looking at extremes can provide insights into less extreme cases.
When you have a tangled web as shown above, most of the code is coupled to other parts. If you delete a node, then you break something else. You'd think that deleting code is the easiest thing in the world, but it's not.
What if, on the other hand, you have smaller clusters of nodes that are independent?
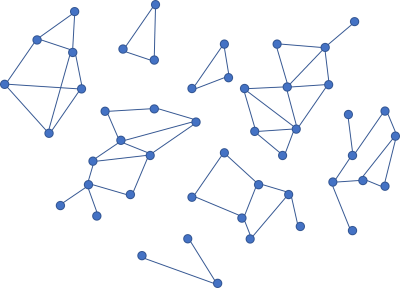
If your dependency graph looks like this, you can at least delete each of the 'islands' without impacting the other sub-graphs.
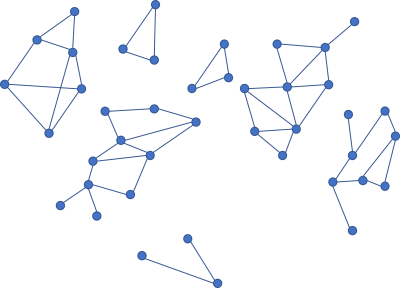
Writing code that is easy to delete may be a good idea, but even that is easier said that done. Loose coupling is, once more, key to good architecture.
Add something better #
Once you've deleted a cluster of code, you have the opportunity to add something that is even less coupled than the island you deleted.
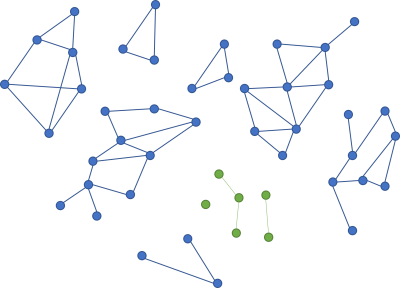
If you add new code that is less coupled than the code you deleted, it's even easier to delete again.
Conclusion #
Coupling is a key factor in code organisation. Tightly coupled code is difficult to change. Loosely coupled code is easier to change. As a thought experiment, consider how difficult it would be to delete a particular piece of code. The easier it is to delete the code, the less coupled it is.
Deleting a small piece of code to add new code in its stead is the ultimate change. You can often get by with a less radical edit, but if all else fails, delete part of your code base and start over. The less coupled the code is, the easier it is to change.
The Reader monad
Normal functions form monads. An article for object-oriented programmers.
This article is an instalment in an article series about monads. A previous article described the Reader functor. As is the case with many (but not all) functors, Readers also form monads.
This article continues where the Reader functor article stopped. It uses the same code base.
Flatten #
A monad must define either a bind or join function, although you can use other names for both of these functions. Flatten is in my opinion a more intuitive name than join, since a monad is really just a functor that you can flatten. Flattening is relevant if you have a nested functor; in this case a Reader within a Reader. You can flatten such a nested Reader with a Flatten function:
public static IReader<R, A> Flatten<R, A>( this IReader<R, IReader<R, A>> source) { return new FlattenReader<R, A>(source); } private class FlattenReader<R, A> : IReader<R, A> { private readonly IReader<R, IReader<R, A>> source; public FlattenReader(IReader<R, IReader<R, A>> source) { this.source = source; } public A Run(R environment) { IReader<R, A> newReader = source.Run(environment); return newReader.Run(environment); } }
Since the source Reader is nested, calling its Run method once returns a newReader. You can Run that newReader one more time to get an A value to return.
You could easily chain the two calls to Run together, one after the other. That would make the code terser, but here I chose to do it in two explicit steps in order to show what's going on.
Like the previous article about the State monad, a lot of ceremony is required because this variation of the Reader monad is defined with an interface. You could also define the Reader monad on a 'raw' function of the type Func<R, A>, in which case Flatten would be simpler:
public static Func<R, A> Flatten<R, A>(this Func<R, Func<R, A>> source) { return environment => source(environment)(environment); }
In this variation source is a function, so you can call it with environment, which returns another function that you can again call with environment. This produces an A value for the function to return.
SelectMany #
When you have Flatten you can always define SelectMany (monadic bind) like this:
public static IReader<R, B> SelectMany<R, A, B>( this IReader<R, A> source, Func<A, IReader<R, B>> selector) { return source.Select(selector).Flatten(); }
First use functor-based mapping. Since the selector returns a Reader, this mapping produces a Reader within a Reader. That's exactly the situation that Flatten addresses.
The above SelectMany example works with the IReader<R, A> interface, but the 'raw' function version has the exact same implementation:
public static Func<R, B> SelectMany<R, A, B>( this Func<R, A> source, Func<A, Func<R, B>> selector) { return source.Select(selector).Flatten(); }
Only the method declaration differs.
Query syntax #
Monads also enable query syntax in C# (just like they enable other kinds of syntactic sugar in languages like F# and Haskell). As outlined in the monad introduction, however, you must add a special SelectMany overload:
public static IReader<R, T1> SelectMany<R, T, U, T1>( this IReader<R, T> source, Func<T, IReader<R, U>> k, Func<T, U, T1> s) { return source.SelectMany(x => k(x).Select(y => s(x, y))); }
As already predicted in the monad introduction, this boilerplate overload is always implemented in the same way. Only the signature changes. With it, you could write an expression like this nonsense:
IReader<int, bool> r = from dur in new MinutesReader() from b in new Thingy(dur) select b;
Where MinutesReader was already shown in the article Reader as a contravariant functor. I couldn't come up with a good name for another reader, so I went with Dan North's naming convention that if you don't yet know what to call a class, method, or function, don't pretend that you know. Be explicit that you don't know.
Here it is, for the sake of completion:
public sealed class Thingy : IReader<int, bool> { private readonly TimeSpan timeSpan; public Thingy(TimeSpan timeSpan) { this.timeSpan = timeSpan; } public bool Run(int environment) { return new TimeSpan(timeSpan.Ticks * environment).TotalDays < 1; } }
I'm not claiming that this class makes sense. These articles are deliberate kept abstract in order to focus on structure and behaviour, rather than on practical application.
Return #
Apart from flattening or monadic bind, a monad must also define a way to put a normal value into the monad. Conceptually, I call this function return (because that's the name that Haskell uses):
public static IReader<R, A> Return<R, A>(A a) { return new ReturnReader<R, A>(a); } private class ReturnReader<R, A> : IReader<R, A> { private readonly A a; public ReturnReader(A a) { this.a = a; } public A Run(R environment) { return a; } }
This implementation returns the a value and completely ignores the environment. You can do the same with a 'naked' function.
Left identity #
We need to identify the return function in order to examine the monad laws. Now that this is accomplished, let's see what the laws look like for the Reader monad, starting with the left identity law.
[Theory] [InlineData(UriPartial.Authority, "https://example.com/f?o=o")] [InlineData(UriPartial.Path, "https://example.net/b?a=r")] [InlineData(UriPartial.Query, "https://example.org/b?a=z")] [InlineData(UriPartial.Scheme, "https://example.gov/q?u=x")] public void LeftIdentity(UriPartial a, string u) { Func<UriPartial, IReader<Uri, UriPartial>> @return = up => Reader.Return<Uri, UriPartial>(up); Func<UriPartial, IReader<Uri, string>> h = up => new UriPartReader(up); Assert.Equal( @return(a).SelectMany(h).Run(new Uri(u)), h(a).Run(new Uri(u))); }
In order to compare the two Reader values, the test has to Run them and then compare the return values.
This test and the next uses a Reader implementation called UriPartReader, which almost makes sense:
public sealed class UriPartReader : IReader<Uri, string> { private readonly UriPartial part; public UriPartReader(UriPartial part) { this.part = part; } public string Run(Uri environment) { return environment.GetLeftPart(part); } }
Almost.
Right identity #
In a similar manner, we can showcase the right identity law as a test.
[Theory] [InlineData(UriPartial.Authority, "https://example.com/q?u=ux")] [InlineData(UriPartial.Path, "https://example.net/q?u=uuz")] [InlineData(UriPartial.Query, "https://example.org/c?o=rge")] [InlineData(UriPartial.Scheme, "https://example.gov/g?a=rply")] public void RightIdentity(UriPartial a, string u) { Func<UriPartial, IReader<Uri, string>> f = up => new UriPartReader(up); Func<string, IReader<Uri, string>> @return = s => Reader.Return<Uri, string>(s); IReader<Uri, string> m = f(a); Assert.Equal( m.SelectMany(@return).Run(new Uri(u)), m.Run(new Uri(u))); }
As always, even a parametrised test constitutes no proof that the law holds. I show the tests to illustrate what the laws look like in 'real' code.
Associativity #
The last monad law is the associativity law that describes how (at least) three functions compose. We're going to need three functions. For the purpose of demonstrating the law, any three pure functions will do. While the following functions are silly and not at all 'realistic', they have the virtue of being as simple as they can be (while still providing a bit of variety). They don't 'mean' anything, so don't worry too much about their behaviour. It is, as far as I can tell, nonsensical.
public sealed class F : IReader<int, string> { private readonly char c; public F(char c) { this.c = c; } public string Run(int environment) { return new string(c, environment); } } public sealed class G : IReader<int, bool> { private readonly string s; public G(string s) { this.s = s; } public bool Run(int environment) { return environment < 42 || s.Contains("a"); } } public sealed class H : IReader<int, TimeSpan> { private readonly bool b; public H(bool b) { this.b = b; } public TimeSpan Run(int environment) { return b ? TimeSpan.FromMinutes(environment) : TimeSpan.FromSeconds(environment); } }
Armed with these three classes, we can now demonstrate the Associativity law:
[Theory] [InlineData('a', 0)] [InlineData('b', 1)] [InlineData('c', 42)] [InlineData('d', 2112)] public void Associativity(char a, int i) { Func<char, IReader<int, string>> f = c => new F(c); Func<string, IReader<int, bool>> g = s => new G(s); Func<bool, IReader<int, TimeSpan>> h = b => new H(b); IReader<int, string> m = f(a); Assert.Equal( m.SelectMany(g).SelectMany(h).Run(i), m.SelectMany(x => g(x).SelectMany(h)).Run(i)); }
In case you're wondering, the four test cases produce the outputs 00:00:00, 00:01:00, 00:00:42, and 00:35:12. You can see that reproduced below:
Haskell #
In Haskell, normal functions a -> b are already Monad instances, which means that you can easily replicate the functions from the Associativity test:
> f c = \env -> replicate env c > g s = \env -> env < 42 || 'a' `elem` s > h b = \env -> if b then secondsToDiffTime (toEnum env * 60) else secondsToDiffTime (toEnum env)
I've chosen to write the f, g, and h as functions that return lambda expressions in order to emphasise that each of these functions return Readers. Since Haskell functions are already curried, I could also have written them in the more normal function style with two normal parameters, but that might have obscured the Reader aspect of each.
Here's the composition in action:
> f 'a' >>= g >>= h $ 0 0s > f 'b' >>= g >>= h $ 1 60s > f 'c' >>= g >>= h $ 42 42s > f 'd' >>= g >>= h $ 2112 2112s
In case you are wondering, 2,112 seconds is 35 minutes and 12 seconds, so all outputs fit with the results reported for the C# example.
What the above Haskell GHCi (REPL) session demonstrates is that it's possible to compose functions with Haskell's monadic bind operator >>= operator exactly because all functions are (Reader) monads.
Conclusion #
In Haskell, it can occasionally be useful that a function can be used when a Monad is required. Some Haskell libraries are defined in very general terms. Their APIs may enable you to call functions with any monadic input value. You can, say, pass a Maybe, a List, an Either, a State, but you can also pass a function.
C# and most other languages (F# included) doesn't come with that level of abstraction, so the fact that a function forms a monad is less useful there. In fact, I can't recall having made explicit use of this knowledge in C#, but one never knows if that day arrives.
In a similar vein, knowing that endomorphisms form monoids (and thereby also semigroups) enabled me to quickly identify the correct design for a validation problem.
Who knows? One day the knowledge that functions are monads may come in handy.
Next: Reactive monad.
Applicative assertions
An exploration.
In a recent Twitter exchange, Lucas DiCioccio made an interesting observation:
"Imho the properties you want of an assertion-framework are really close (the same as?) applicative-validation: one assertion failure with multiple bullet points composed mainly from combinators."
In another branch off my initial tweet Josh McKinney pointed out the short-circuiting nature of standard assertions:
"short circuiting often causes weaker error messages in failing tests than running compound assertions. E.g.
TransferTest { a.transfer(b,50); a.shouldEqual(50); b.shouldEqual(150); // never reached? }
Most standard assertion libraries work by throwing exceptions when an assertion fails. Once you throw an exception, remaining code doesn't execute. This means that you only get the first assertion message. Further assertions are not evaluated.
Josh McKinney later gave more details about a particular scenario. Although in the general case I don't consider the short-circuiting nature of assertions to be a problem, I grant that there are cases where proper assertion composition would be useful.
Lucas DiCioccio's suggestion seems worthy of investigation.
Ongoing exploration #
I asked Lucas DiCioccio whether he'd done any work with his idea, and the day after he replied with a Haskell proof of concept.
I found the idea so interesting that I also wanted to carry out a few proofs of concept myself, perhaps within a more realistic setting.
As I'm writing this, I've reached some preliminary conclusions, but I'm also aware that they may not hold in more general cases. I'm posting what I have so far, but you should expect this exploration to evolve over time. If I find out more, I'll update this post with more articles.
- An initial proof of concept of applicative assertions in C#
- Error-accumulating composable assertions in C#
- Built-in alternatives to applicative assertions
A preliminary summary is in order. Based on the first two articles, applicative assertions look like overkill. I think, however, that it's because of the degenerate nature of the example. Some assertions are essentially one-stop verifications: Evaluate a predicate, and throw an exception if the result is false. These assertions return unit or void. Examples from xUnit include Assert.Equal, Assert.True, Assert.False, Assert.All, and Assert.DoesNotContain.
These are the kinds of assertions that the initial two articles explore.
There are other kinds of assertions that return a value in case of success. xUnit.net examples include Assert.Throws, Assert.Single, Assert.IsAssignableFrom, and some overloads of Assert.Contains. Assert.Single, for example, verifies that a collection contains only a single element. While it throws an exception if the collection is either empty or has more than one element, in the success case it returns the single value. This can be useful if you want to add more assertions based on that value.
I haven't experimented with this yet, but as far as can tell, you'll run into the following problem: If you make such an assertion return an applicative functor, you'll need some way to handle the success case. Combining it with another assertion-producing function, such as a -> Asserted e b (pseudocode) is possible with functor mapping, but will leave you with a nested functor.
You'll probably want to flatten the nested functor, which is exactly what monads do. Monads, on the other hand, short circuit, so you don't want to make your applicative assertion type a monad. Instead, you'll need to use an isomorphic monad container (Either should do) to move in and out of. Doable, but is the complexity warranted?
I realise that the above musings are abstract, and that I really should show rather than tell. I'll add some more content here if I ever collect something worthy of an article. if you ask me now, though, I consider that a bit of a toss-up.
The first two examples also suffer from being written in C#, which doesn't have good syntactic support for applicative functors. Perhaps I'll add some articles that use F# or Haskell.
Conclusion #
There's the occasional need for composable assertions. You can achieve that with an applicative functor, but the question is whether it's warranted. Could you make something simpler based on the list monad?
As I'm writing this, I don't consider that question settled. Even so, you may want to read on.
Next: An initial proof of concept of applicative assertions in C#.
A regular grid emerges
The code behind a lecture animation.
If you've seen my presentation Fractal Architecture, you may have wondered how I made the animation where a regular(ish) hexagonal grid emerges from adding more and more blobs to an area.
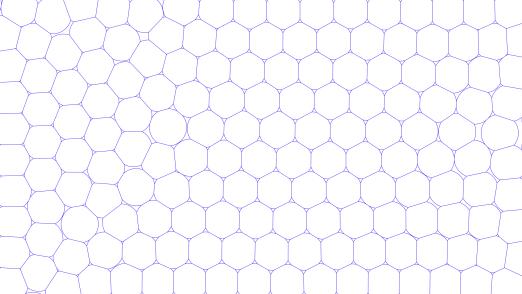
Like a few previous blog posts, today's article appears on Observable, which is where the animation and the code that creates it lives. Go there to read it.
If you have time, watch the animation evolve. Personally I find it quite mesmerising.
Encapsulation in Functional Programming
Encapsulation is only relevant for object-oriented programming, right?
The concept of encapsulation is closely related to object-oriented programming (OOP), and you rarely hear the word in discussions about (statically-typed) functional programming (FP). I will argue, however, that the notion is relevant in FP as well. Typically, it just appears with a different catchphrase.
Contracts #
I base my understanding of encapsulation on Object-Oriented Software Construction. I've tried to distil it in my Pluralsight course Encapsulation and SOLID.
In short, encapsulation denotes the distinction between an object's contract and its implementation. An object should fulfil its contract in such a way that client code doesn't need to know about its implementation.
Contracts, according to Bertrand Meyer, describe three properties of objects:
- Preconditions: What client code must fulfil in order to successfully interact with the object.
- Invariants: Statements about the object that are always true.
- Postconditions: Statements that are guaranteed to be true after a successful interaction between client code and object.
You can replace object with value and I'd argue that the same concerns are relevant in FP.
In OOP invariants often point to the properties of an object that are guaranteed to remain even in the face of state mutation. As you change the state of an object, the object should guarantee that its state remains valid. These are the properties (i.e. qualities, traits, attributes) that don't vary - i.e. are invariant.
An example would be helpful around here.
Table mutation #
Consider an object that models a table in a restaurant. You may, for example, be working on the Maître d' kata. In short, you may decide to model a table as being one of two kinds: Standard tables and communal tables. You can reserve seats at communal tables, but you still share the table with other people.
You may decide to model the problem in such a way that when you reserve the table, you change the state of the object. You may decide to describe the contract of Table objects like this:
- Preconditions
- To create a
Tableobject, you must supply a type (standard or communal). - To create a
Tableobject, you must supply the size of the table, which is a measure of its capacity; i.e. how many people can sit at it. - The capacity must be a natural number. One (1) is the smallest valid capacity.
- When reserving a table, you must supply a valid reservation.
- When reserving a table, the reservation quantity must be less than or equal to the table's remaining capacity.
- To create a
- Invariants
- The table capacity doesn't change.
- The table type doesn't change.
- The number of remaining seats is never negative.
- The number of remaining seats is never greater than the table's capacity.
- Postconditions
- After reserving a table, the number of remaining seats can't be greater than the previous number of remaining seats minus the reservation quantity.
This list may be incomplete, and if you add more operations, you may have to elaborate on what that means to the contract.
In C# you may implement a Table class like this:
public sealed class Table { private readonly List<Reservation> reservations; public Table(int capacity, TableType type) { if (capacity < 1) throw new ArgumentOutOfRangeException( nameof(capacity), $"Capacity must be greater than zero, but was: {capacity}."); reservations = new List<Reservation>(); Capacity = capacity; Type = type; RemaingSeats = capacity; } public int Capacity { get; } public TableType Type { get; } public int RemaingSeats { get; private set; } public void Reserve(Reservation reservation) { if (RemaingSeats < reservation.Quantity) throw new InvalidOperationException( "The table has no remaining seats."); if (Type == TableType.Communal) RemaingSeats -= reservation.Quantity; else RemaingSeats = 0; reservations.Add(reservation); } }
This class has good encapsulation because it makes sure to fulfil the contract. You can't put it in an invalid state.
Immutable Table #
Notice that two of the invariants for the above Table class is that the table can't change type or capacity. While OOP often revolves around state mutation, it seems reasonable that some data is immutable. A table doesn't all of a sudden change size.
In FP data is immutable. Data doesn't change. Thus, data has that invariant property.
If you consider the above contract, it still applies to FP. The specifics change, though. You'll no longer be dealing with Table objects, but rather Table data, and to make reservations, you call a function that returns a new Table value.
In F# you could model a Table like this:
type Table = private Standard of int * Reservation list | Communal of int * Reservation list module Table = let standard capacity = if 0 < capacity then Some (Standard (capacity, [])) else None let communal capacity = if 0 < capacity then Some (Communal (capacity, [])) else None let remainingSeats = function | Standard (capacity, []) -> capacity | Standard _ -> 0 | Communal (capacity, rs) -> capacity - List.sumBy (fun r -> r.Quantity) rs let reserve r t = match t with | Standard (capacity, []) when r.Quantity <= remainingSeats t -> Some (Standard (capacity, [r])) | Communal (capacity, rs) when r.Quantity <= remainingSeats t -> Some (Communal (capacity, r :: rs)) | _ -> None
While you'll often hear fsharpers say that one should make illegal states unrepresentable, in practice you often have to rely on predicative data to enforce contracts. I've done this here by making the Table cases private. Code outside the module can't directly create Table data. Instead, it'll have to use one of two functions: Table.standard or Table.communal. These are functions that return Table option values.
That's the idiomatic way to model predicative data in statically typed FP. In Haskell such functions are called smart constructors.
Statically typed FP typically use Maybe (Option) or Either (Result) values to communicate failure, rather than throwing exceptions, but apart from that a smart constructor is just an object constructor.
The above F# Table API implements the same contract as the OOP version.
If you want to see a more elaborate example of modelling table and reservations in F#, see An F# implementation of the Maître d' kata.
Functional contracts in OOP languages #
You can adopt many FP concepts in OOP languages. My book Code That Fits in Your Head contains sample code in C# that implements an online restaurant reservation system. It includes a Table class that, at first glance, looks like the above C# class.
While it has the same contract, the book's Table class is implemented with the FP design principles in mind. Thus, it's an immutable class with this API:
public sealed class Table { public static Table Standard(int seats) public static Table Communal(int seats) public int Capacity { get; } public int RemainingSeats { get; } public Table Reserve(Reservation reservation) public T Accept<T>(ITableVisitor<T> visitor) public override bool Equals(object? obj) public override int GetHashCode() }
Notice that the Reserve method returns a Table object. That's the table with the reservation associated. The original Table instance remains unchanged.
The entire book is written in the Functional Core, Imperative Shell architecture, so all domain models are immutable objects with pure functions as methods.
The objects still have contracts. They have proper encapsulation.
Conclusion #
Functional programmers may not use the term encapsulation much, but that doesn't mean that they don't share that kind of concern. They often throw around the phrase make illegal states unrepresentable or talk about smart constructors or partial versus total functions. It's clear that they care about data modelling that prevents mistakes.
The object-oriented notion of encapsulation is ultimately about separating the affordances of an API from its implementation details. An object's contract is an abstract description of the properties (i.e. qualities, traits, or attributes) of the object.
Functional programmers care so much about the properties of data and functions that property-based testing is often the preferred way to perform automated testing.
Perhaps you can find a functional programmer who might be slightly offended if you suggest that he or she should consider encapsulation. If so, suggest instead that he or she considers the properties of functions and data.
Comments
I wonder what's the goal of illustrating OOP-ish examples exclusively in C# and FP-ish ones in F# when you could stick to just one language for the reader. It might not always be as effective depending on the topic, but for encapsulation and the examples shown in this article, a C# version would read just as effective as an F# one. I mean when you get round to making your points in the Immutable Table section of your article, you could demonstrate the ideas with a C# version that's nearly identical to and reads as succinct as the F# version:
#nullable enable readonly record struct Reservation(int Quantity); abstract record Table; record StandardTable(int Capacity, Reservation? Reservation): Table; record CommunalTable(int Capacity, ImmutableArray<Reservation> Reservations): Table; static class TableModule { public static StandardTable? Standard(int capacity) => 0 < capacity ? new StandardTable(capacity, null) : null; public static CommunalTable? Communal(int capacity) => 0 < capacity ? new CommunalTable(capacity, ImmutableArray<Reservation>.Empty) : null; public static int RemainingSeats(this Table table) => table switch { StandardTable { Reservation: null } t => t.Capacity, StandardTable => 0, CommunalTable t => t.Capacity - t.Reservations.Sum(r => r.Quantity) }; public static Table? Reserve(this Table table, Reservation r) => table switch { StandardTable t when r.Quantity <= t.RemainingSeats() => t with { Reservation = r }, CommunalTable t when r.Quantity <= t.RemainingSeats() => t with { Reservations = t.Reservations.Add(r) }, _ => null, }; }
This way, I can just point someone to your article for enlightenment, 😉 but not leave them feeling frustrated that they need F# to (practice and) model around data instead of state mutating objects. It might still be worthwhile to show an F# version to draw the similarities and also call out some differences; like Table being a true discriminated union in F#, and while it appears to be emulated in C#, they desugar to the same thing in terms of CLR types and hierarchies.
By the way, in the C# example above, I modeled the standard table variant differently because if it can hold only one reservation at a time then the model should reflect that.
Atif, thank you for supplying and example of an immutable C# implementation.
I already have an example of an immutable, functional C# implementation in Code That Fits in Your Head, so I wanted to supply something else here. I also tend to find it interesting to compare how to model similar ideas in different languages, and it felt natural to supply an F# example to show how a 'natural' FP implementation might look.
Your point is valid, though, so I'm not insisting that this was the right decision.
I took your idea, Atif, and wrote something that I think is more congruent with the example here. In short, I’m
- using polymorphism to avoid having to switch over the Table type
- hiding subtypes of Table to simplify the interface.
Here's the code:
#nullable enable
using System.Collections.Immutable;
readonly record struct Reservation(int Quantity);
abstract record Table
{
public abstract Table? Reserve(Reservation r);
public abstract int RemainingSeats();
public static Table? Standard(int capacity) =>
capacity > 0 ? new StandardTable(capacity, null) : null;
public static Table? Communal(int capacity) =>
capacity > 0 ? new CommunalTable(
capacity,
ImmutableArray<Reservation>.Empty) : null;
private record StandardTable(int Capacity, Reservation? Reservation) : Table
{
public override Table? Reserve(Reservation r) => RemainingSeats() switch
{
var seats when seats >= r.Quantity => this with { Reservation = r },
_ => null,
};
public override int RemainingSeats() => Reservation switch
{
null => Capacity,
_ => 0,
};
}
private record CommunalTable(
int Capacity,
ImmutableArray<Reservation> Reservations) : Table
{
public override Table? Reserve(Reservation r) => RemainingSeats() switch
{
var seats when seats >= r.Quantity =>
this with { Reservations = Reservations.Add(r) },
_ => null,
};
public override int RemainingSeats() =>
Capacity - Reservations.Sum(r => r.Quantity);
}
}
I’d love to hear your thoughts on this approach. I think that one of its weaknesses is that calls to Table.Standard() and Table.Communal() will yield two instances of Table that can never be equal. For instance, Table.Standard(4) != Table.Communal(4), even though they’re both of type Table? and have the same number of seats.
Calling GetType() on each of the instances reveals that their types are actually Table+StandardTable and Table+CommunalTable respectively; however, this isn't transparent to callers. Another solution might be to expose the Table subtypes and give them private constructors – I just like the simplicity of not exposing the individual types of tables the same way you’re doing here, Mark.
Mark,
How do you differentiate encapsulation from abstraction?
Here's an excerpt from your book Dependency Injection: Principles, Practices, and Patterns.
Section: 1.3 - What to inject and what not to inject Subsection: 1.3.1 - Stable Dependencies
"Other examples [of libraries that do not require to be injected] may include specialized libraries that encapsulate alogorithms relevant to your application".
In that section, you and Steven were giving examples of stable dependencies that do not require to be injected to keep modularity. You define a library that "encapsulates an algorithm" as an example.
Now, to me, encapsulation is "protecting data integrity", plain and simple. A class is encapsulated as long as it's impossible or nearly impossible to bring it to an invalid or inconsistent state.
Protection of invariants, implementation hiding, bundling data and operations together, pre- and postconditions, Postel's Law all come into play to achieve this goal.
Thus, a class, to be "encapsulatable", has to have a state that can be initialized and/or modified by the client code.
Now I ask: most of the time when we say that something is encapsulating another, don't we really mean abstracting?
Why is it relevant to know that the hypothetical algorithm library protects it's invariants by using the term "encapsulate"?
Abstraction, under the light of Robert C. Martin's definition of it, makes much more sense in that context: "a specialized library that abstracts algorithms relevant to your application". It amplifies the essential (by providing a clear API), but eliminates the irrelevant (by hiding the alogirthm's implementation details).
Granted, there is some overlap between encapsulation and abstraction, specially when you bundle data and operations together (rich domain models), but they are not the same thing, you just use one to achieve another sometimes.
Would it be correct to say that the .NET Framework encapsulates math algorithms in the System.Math class? Is there any state there to be preserved? They're all static methods and constants. On the other hand, they're surely eliminating some pretty irrelevant (from a consumer POV) trigonometric algorithms.
Thanks.
Alexandre, thank you for writing. How do I distinguish between abstraction and encapsulation?
There's much overlap, to be sure.
As I write, my view on encapsulation is influenced by Bertrand Meyer's notion of contract. Likewise, I do use Robert C. Martin's notion of amplifying the essentials while hiding the irrelevant details as a guiding light when discussing abstraction.
While these concepts may seem synonymous, they're not quite the same. I can't say that I've spent too much time considering how these two words relate, but shooting from the hip I think that abstraction is a wider concept.
You don't need to read much of Robert C. Martin before he'll tell you that the Dependency Inversion Principle is an important part of abstraction:
"Abstractions should not depend on details. Details should depend on abstractions."
It's possible to implement a code base where this isn't true, even if classes have good encapsulation. You could imagine a domain model that depends on database details like a particular ORM. I've seen plenty of those in my career, although I grant that most of them have had poor encapsulation as well. It is not, however, impossible to imagine such a system with good encapsulation, but suboptimal abstraction.
Does it go the other way as well? Can we have good abstraction, but poor encapsulation?
An example doesn't come immediately to mind, but as I wrote, it's not an ontology that I've given much thought.
Stubs and mocks break encapsulation
Favour Fakes over dynamic mocks.
For a while now, I've favoured Fakes over Stubs and Mocks. Using Fake Objects over other Test Doubles makes test suites more robust. I wrote the code base for my book Code That Fits in Your Head entirely with Fakes and the occasional Test Spy, and I rarely had to fix broken tests. No Moq, FakeItEasy, NSubstitute, nor Rhino Mocks. Just hand-written Test Doubles.
It recently occurred to me that a way to explain the problem with Mocks and Stubs is that they break encapsulation.
You'll see some examples soon, but first it's important to be explicit about terminology.
Terminology #
Words like Mocks, Stubs, as well as encapsulation, have different meanings to different people. They've fallen victim to semantic diffusion, if ever they were well-defined to begin with.
When I use the words Test Double, Fake, Mock, and Stub, I use them as they are defined in xUnit Test Patterns. I usually try to avoid the terms Mock and Stub since people use them vaguely and inconsistently. The terms Test Double and Fake fare better.
We do need, however, a name for those libraries that generate Test Doubles on the fly. In .NET, they are libraries like Moq, FakeItEasy, and so on, as listed above. Java has Mockito, EasyMock, JMockit, and possibly more like that.
What do we call such libraries? Most people call them mock libraries or dynamic mock libraries. Perhaps dynamic Test Double library would be more consistent with the xUnit Test Patterns vocabulary, but nobody calls them that. I'll call them dynamic mock libraries to at least emphasise the dynamic, on-the-fly object generation these libraries typically use.
Finally, it's important to define encapsulation. This is another concept where people may use the same word and yet mean different things.
I base my understanding of encapsulation on Object-Oriented Software Construction. I've tried to distil it in my Pluralsight course Encapsulation and SOLID.
In short, encapsulation denotes the distinction between an object's contract and its implementation. An object should fulfil its contract in such a way that client code doesn't need to know about its implementation.
Contracts, according to Meyer, describe three properties of objects:
- Preconditions: What client code must fulfil in order to successfully interact with the object.
- Invariants: Statements about the object that are always true.
- Postconditions: Statements that are guaranteed to be true after a successful interaction between client code and object.
As I'll demonstrate in this article, objects generated by dynamic mock libraries often break their contracts.
Create-and-read round-trip #
Consider the IReservationsRepository interface from Code That Fits in Your Head:
public interface IReservationsRepository { Task Create(int restaurantId, Reservation reservation); Task<IReadOnlyCollection<Reservation>> ReadReservations( int restaurantId, DateTime min, DateTime max); Task<Reservation?> ReadReservation(int restaurantId, Guid id); Task Update(int restaurantId, Reservation reservation); Task Delete(int restaurantId, Guid id); }
I already discussed some of the contract properties of this interface in an earlier article. Here, I want to highlight a certain interaction.
What is the contract of the Create method?
There are a few preconditions:
- The client must have a properly initialised
IReservationsRepositoryobject. - The client must have a valid
restaurantId. - The client must have a valid
reservation.
A client that fulfils these preconditions can successfully call and await the Create method. What are the invariants and postconditions?
I'll skip the invariants because they aren't relevant to the line of reasoning that I'm pursuing. One postcondition, however, is that the reservation passed to Create must now be 'in' the repository.
How does that manifest as part of the object's contract?
This implies that a client should be able to retrieve the reservation, either with ReadReservation or ReadReservations. This suggests a kind of property that Scott Wlaschin calls There and back again.
Picking ReadReservation for the verification step we now have a property: If client code successfully calls and awaits Create it should be able to use ReadReservation to retrieve the reservation it just saved. That's implied by the IReservationsRepository contract.
SQL implementation #
The 'real' implementation of IReservationsRepository used in production is an implementation that stores reservations in SQL Server. This class should obey the contract.
While it might be possible to write a true property-based test, running hundreds of randomly generated test cases against a real database is going to take time. Instead, I chose to only write a parametrised test:
[Theory] [InlineData(Grandfather.Id, "2022-06-29 12:00", "e@example.gov", "Enigma", 1)] [InlineData(Grandfather.Id, "2022-07-27 11:40", "c@example.com", "Carlie", 2)] [InlineData(2, "2021-09-03 14:32", "bon@example.edu", "Jovi", 4)] public async Task CreateAndReadRoundTrip( int restaurantId, string at, string email, string name, int quantity) { var expected = new Reservation( Guid.NewGuid(), DateTime.Parse(at, CultureInfo.InvariantCulture), new Email(email), new Name(name), quantity); var connectionString = ConnectionStrings.Reservations; var sut = new SqlReservationsRepository(connectionString); await sut.Create(restaurantId, expected); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual); }
The part that we care about is the three last lines:
await sut.Create(restaurantId, expected); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual);
First call Create and subsequently ReadReservation. The value created should equal the value retrieved, which is also the case. All tests pass.
Fake #
The Fake implementation is effectively an in-memory database, so we expect it to also fulfil the same contract. We can test it with an almost identical test:
[Theory] [InlineData(RestApi.Grandfather.Id, "2022-06-29 12:00", "e@example.gov", "Enigma", 1)] [InlineData(RestApi.Grandfather.Id, "2022-07-27 11:40", "c@example.com", "Carlie", 2)] [InlineData(2, "2021-09-03 14:32", "bon@example.edu", "Jovi", 4)] public async Task CreateAndReadRoundTrip( int restaurantId, string at, string email, string name, int quantity) { var expected = new Reservation( Guid.NewGuid(), DateTime.Parse(at, CultureInfo.InvariantCulture), new Email(email), new Name(name), quantity); var sut = new FakeDatabase(); await sut.Create(restaurantId, expected); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual); }
The only difference is that the sut is a different class instance. These test cases also all pass.
How is FakeDatabase implemented? That's not important, because it obeys the contract. FakeDatabase has good encapsulation, which makes it possible to use it without knowing anything about its internal implementation details. That, after all, is the point of encapsulation.
Dynamic mock #
How does a dynamic mock fare if subjected to the same test? Let's try with Moq 4.18.2 (and I'm not choosing Moq to single it out - I chose Moq because it's the dynamic mock library I used to love the most):
[Theory] [InlineData(RestApi.Grandfather.Id, "2022-06-29 12:00", "e@example.gov", "Enigma", 1)] [InlineData(RestApi.Grandfather.Id, "2022-07-27 11:40", "c@example.com", "Carlie", 2)] [InlineData(2, "2021-09-03 14:32", "bon@example.edu", "Jovi", 4)] public async Task CreateAndReadRoundTrip( int restaurantId, string at, string email, string name, int quantity) { var expected = new Reservation( Guid.NewGuid(), DateTime.Parse(at, CultureInfo.InvariantCulture), new Email(email), new Name(name), quantity); var sut = new Mock<IReservationsRepository>().Object; await sut.Create(restaurantId, expected); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual); }
If you've worked a little with dynamic mock libraries, you will not be surprised to learn that all three tests fail. Here's one of the failure messages:
Ploeh.Samples.Restaurants.RestApi.Tests.MoqRepositoryTests.CreateAndReadRoundTrip(↩ restaurantId: 1, at: "2022-06-29 12:00", email: "e@example.gov", name: "Enigma", quantity: 1) Source: MoqRepositoryTests.cs line 17 Duration: 1 ms Message: Assert.Equal() Failure Expected: Reservation↩ {↩ At = 2022-06-29T12:00:00.0000000,↩ Email = e@example.gov,↩ Id = c9de4f95-3255-4e1f-a1d6-63591b58ff0c,↩ Name = Enigma,↩ Quantity = 1↩ } Actual: (null) Stack Trace: MoqRepositoryTests.CreateAndReadRoundTrip(↩ Int32 restaurantId, String at, String email, String name, Int32 quantity) line 35 --- End of stack trace from previous location where exception was thrown ---
(I've introduced line breaks and indicated them with the ↩ symbol to make the output more readable. I'll do that again later in the article.)
Not surprisingly, the return value of Create is null. You typically have to configure a dynamic mock in order to give it any sort of behaviour, and I didn't do that here. In that case, the dynamic mock returns the default value for the return type, which in this case correctly is null.
You may object that the above example is unfair. How can a dynamic mock know what to do? You have to configure it. That's the whole point of it.
Retrieval without creation #
Okay, let's set up the dynamic mock:
var dm = new Mock<IReservationsRepository>(); dm.Setup(r => r.ReadReservation(restaurantId, expected.Id)).ReturnsAsync(expected); var sut = dm.Object;
These are the only lines I've changed from the previous listing of the test, which now passes.
A common criticism of dynamic-mock-heavy tests is that they mostly 'just test the mocks', and this is exactly what happens here.
You can make that more explicit by deleting the Create method call:
var dm = new Mock<IReservationsRepository>(); dm.Setup(r => r.ReadReservation(restaurantId, expected.Id)).ReturnsAsync(expected); var sut = dm.Object; var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual);
The test still passes. Clearly it only tests the dynamic mock.
You may, again, demur that this is expected, and it doesn't demonstrate that dynamic mocks break encapsulation. Keep in mind, however, the nature of the contract: Upon successful completion of Create, the reservation is 'in' the repository and can later be retrieved, either with ReadReservation or ReadReservations.
This variation of the test no longer calls Create, yet ReadReservation still returns the expected value.
Do SqlReservationsRepository or FakeDatabase behave like that? No, they don't.
Try to delete the Create call from the test that exercises SqlReservationsRepository:
var sut = new SqlReservationsRepository(connectionString); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual);
Hardly surprising, the test now fails because actual is null. The same happens if you delete the Create call from the test that exercises FakeDatabase:
var sut = new FakeDatabase(); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual);
Again, the assertion fails because actual is null.
The classes SqlReservationsRepository and FakeDatabase behave according to contract, while the dynamic mock doesn't.
Alternative retrieval #
There's another way in which the dynamic mock breaks encapsulation. Recall what the contract states: Upon successful completion of Create, the reservation is 'in' the repository and can later be retrieved, either with ReadReservation or ReadReservations.
In other words, it should be possible to change the interaction from Create followed by ReadReservation to Create followed by ReadReservations.
First, try it with SqlReservationsRepository:
await sut.Create(restaurantId, expected); var min = expected.At.Date; var max = min.AddDays(1); var actual = await sut.ReadReservations(restaurantId, min, max); Assert.Contains(expected, actual);
The test still passes, as expected.
Second, try the same change with FakeDatabase:
await sut.Create(restaurantId, expected); var min = expected.At.Date; var max = min.AddDays(1); var actual = await sut.ReadReservations(restaurantId, min, max); Assert.Contains(expected, actual);
Notice that this is the exact same code as in the SqlReservationsRepository test. That test also passes, as expected.
Third, try it with the dynamic mock:
await sut.Create(restaurantId, expected); var min = expected.At.Date; var max = min.AddDays(1); var actual = await sut.ReadReservations(restaurantId, min, max); Assert.Contains(expected, actual);
Same code, different sut, and the test fails. The dynamic mock breaks encapsulation. You'll have to go and fix the Setup of it to make the test pass again. That's not the case with SqlReservationsRepository or FakeDatabase.
Dynamic mocks break the SUT, not the tests #
Perhaps you're still not convinced that this is of practical interest. After all, Bertrand Meyer had limited success getting mainstream adoption of his thought on contract-based programming.
That dynamic mocks break encapsulation does, however, have real implications.
What if, instead of using FakeDatabase, I'd used dynamic mocks when testing my online restaurant reservation system? A test might have looked like this:
[Theory] [InlineData(1049, 19, 00, "juliad@example.net", "Julia Domna", 5)] [InlineData(1130, 18, 15, "x@example.com", "Xenia Ng", 9)] [InlineData( 956, 16, 55, "kite@example.edu", null, 2)] [InlineData( 433, 17, 30, "shli@example.org", "Shanghai Li", 5)] public async Task PostValidReservationWhenDatabaseIsEmpty( int days, int hours, int minutes, string email, string name, int quantity) { var at = DateTime.Now.Date + new TimeSpan(days, hours, minutes, 0); var dm = new Mock<IReservationsRepository>(); dm.Setup(r => r.ReadReservations(Grandfather.Id, at.Date, at.Date.AddDays(1).AddTicks(-1))) .ReturnsAsync(Array.Empty<Reservation>()); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Grandfather.Restaurant), dm.Object); var expected = new Reservation( new Guid("B50DF5B1-F484-4D99-88F9-1915087AF568"), at, new Email(email), new Name(name ?? ""), quantity); await sut.Post(expected.ToDto()); dm.Verify(r => r.Create(Grandfather.Id, expected)); }
This is yet another riff on the PostValidReservationWhenDatabaseIsEmpty test - the gift that keeps giving. I've previously discussed this test in other articles:
- Branching tests
- Waiting to happen
- Parametrised test primitive obsession code smell
- The Equivalence contravariant functor
Here I've replaced the FakeDatabase Test Double with a dynamic mock. (I am, again, using Moq, but keep in mind that the fallout of using a dynamic mock is unrelated to specific libraries.)
To go 'full dynamic mock' I should also have replaced SystemClock and InMemoryRestaurantDatabase with dynamic mocks, but that's not necessary to illustrate the point I wish to make.
This, and other tests, describe the desired outcome of making a reservation against the REST API. It's an interaction that looks like this:
POST /restaurants/90125/reservations?sig=aco7VV%2Bh5sA3RBtrN8zI8Y9kLKGC60Gm3SioZGosXVE%3D HTTP/1.1
content-type: application/json
{
"at": "2022-12-12T20:00",
"name": "Pearl Yvonne Gates",
"email": "pearlygates@example.net",
"quantity": 4
}
HTTP/1.1 201 Created
Content-Length: 151
Content-Type: application/json; charset=utf-8
Location: [...]/restaurants/90125/reservations/82e550b1690742368ea62d76e103b232?sig=fPY1fSr[...]
{
"id": "82e550b1690742368ea62d76e103b232",
"at": "2022-12-12T20:00:00.0000000",
"email": "pearlygates@example.net",
"name": "Pearl Yvonne Gates",
"quantity": 4
}
What's of interest here is that the response includes the JSON representation of the resource that the interaction created. It's mostly a copy of the posted data, but enriched with a server-generated ID.
The code responsible for the database interaction looks like this:
private async Task<ActionResult> TryCreate(Restaurant restaurant, Reservation reservation) { using var scope = new TransactionScope(TransactionScopeAsyncFlowOption.Enabled); var reservations = await Repository .ReadReservations(restaurant.Id, reservation.At) .ConfigureAwait(false); var now = Clock.GetCurrentDateTime(); if (!restaurant.MaitreD.WillAccept(now, reservations, reservation)) return NoTables500InternalServerError(); await Repository.Create(restaurant.Id, reservation).ConfigureAwait(false); scope.Complete(); return Reservation201Created(restaurant.Id, reservation); }
The last line of code creates a 201 Created response with the reservation as content. Not shown in this snippet is the origin of the reservation parameter, but it's the input JSON document parsed to a Reservation object. Each Reservation object has an ID that the server creates when it's not supplied by the client.
The above TryCreate helper method contains all the database interaction code related to creating a new reservation. It first calls ReadReservations to retrieve the existing reservations. Subsequently, it calls Create if it decides to accept the reservation. The ReadReservations method is actually an internal extension method:
internal static Task<IReadOnlyCollection<Reservation>> ReadReservations( this IReservationsRepository repository, int restaurantId, DateTime date) { var min = date.Date; var max = min.AddDays(1).AddTicks(-1); return repository.ReadReservations(restaurantId, min, max); }
Notice how the dynamic-mock-based test has to replicate this internal implementation detail to the tick. If I ever decide to change this just one tick, the test is going to fail. That's already bad enough (and something that FakeDatabase gracefully handles), but not what I'm driving towards.
At the moment the TryCreate method echoes back the reservation. What if, however, you instead want to query the database and return the record that you got from the database? In this particular case, there's no reason to do that, but perhaps in other cases, something happens in the data layer that either enriches or normalises the data. So you make an innocuous change:
private async Task<ActionResult> TryCreate(Restaurant restaurant, Reservation reservation) { using var scope = new TransactionScope(TransactionScopeAsyncFlowOption.Enabled); var reservations = await Repository .ReadReservations(restaurant.Id, reservation.At) .ConfigureAwait(false); var now = Clock.GetCurrentDateTime(); if (!restaurant.MaitreD.WillAccept(now, reservations, reservation)) return NoTables500InternalServerError(); await Repository.Create(restaurant.Id, reservation).ConfigureAwait(false); var storedReservation = await Repository .ReadReservation(restaurant.Id, reservation.Id) .ConfigureAwait(false); scope.Complete(); return Reservation201Created(restaurant.Id, storedReservation!); }
Now, instead of echoing back reservation, the method calls ReadReservation to retrieve the (possibly enriched or normalised) storedReservation and returns that value. Since this value could, conceivably, be null, for now the method uses the ! operator to insist that this is not the case. A new test case might be warranted to cover the scenario where the query returns null.
This is perhaps a little less efficient because it implies an extra round-trip to the database, but it shouldn't change the behaviour of the system!
But when you run the test suite, that PostValidReservationWhenDatabaseIsEmpty test fails:
Ploeh.Samples.Restaurants.RestApi.Tests.ReservationsTests.PostValidReservationWhenDatabaseIsEmpty(↩
days: 433, hours: 17, minutes: 30, email: "shli@example.org", name: "Shanghai Li", quantity: 5)↩
[FAIL]
System.NullReferenceException : Object reference not set to an instance of an object.
Stack Trace:
[...]\Restaurant.RestApi\ReservationsController.cs(94,0): at↩
[...].RestApi.ReservationsController.Reservation201Created↩
(Int32 restaurantId, Reservation r)
[...]\Restaurant.RestApi\ReservationsController.cs(79,0): at↩
[...].RestApi.ReservationsController.TryCreate↩
(Restaurant restaurant, Reservation reservation)
[...]\Restaurant.RestApi\ReservationsController.cs(57,0): at↩
[...].RestApi.ReservationsController.Post↩
(Int32 restaurantId, ReservationDto dto)
[...]\Restaurant.RestApi.Tests\ReservationsTests.cs(73,0): at↩
[...].RestApi.Tests.ReservationsTests.PostValidReservationWhenDatabaseIsEmpty↩
(Int32 days, Int32 hours, Int32 minutes, String email, String name, Int32 quantity)
--- End of stack trace from previous location where exception was thrown ---
Oh, the dreaded NullReferenceException! This happens because ReadReservation returns null, since the dynamic mock isn't configured.
The typical reaction that most people have is: Oh no, the tests broke!
I think, though, that this is the wrong perspective. The dynamic mock broke the System Under Test (SUT) because it passed an implementation of IReservationsRepository that breaks the contract. The test didn't 'break', because it was never correct from the outset.
Shotgun surgery #
When a test code base uses dynamic mocks, it tends to do so pervasively. Most tests create one or more dynamic mocks that they pass to their SUT. Most of these dynamic mocks break encapsulation, so when you refactor, the dynamic mocks break the SUT.
You'll typically need to revisit and 'fix' all the failing tests to accommodate the refactoring:
[Theory] [InlineData(1049, 19, 00, "juliad@example.net", "Julia Domna", 5)] [InlineData(1130, 18, 15, "x@example.com", "Xenia Ng", 9)] [InlineData( 956, 16, 55, "kite@example.edu", null, 2)] [InlineData( 433, 17, 30, "shli@example.org", "Shanghai Li", 5)] public async Task PostValidReservationWhenDatabaseIsEmpty( int days, int hours, int minutes, string email, string name, int quantity) { var at = DateTime.Now.Date + new TimeSpan(days, hours, minutes, 0); var expected = new Reservation( new Guid("B50DF5B1-F484-4D99-88F9-1915087AF568"), at, new Email(email), new Name(name ?? ""), quantity); var dm = new Mock<IReservationsRepository>(); dm.Setup(r => r.ReadReservations(Grandfather.Id, at.Date, at.Date.AddDays(1).AddTicks(-1))) .ReturnsAsync(Array.Empty<Reservation>()); dm.Setup(r => r.ReadReservation(Grandfather.Id, expected.Id)).ReturnsAsync(expected); var sut = new ReservationsController( new SystemClock(), new InMemoryRestaurantDatabase(Grandfather.Restaurant), dm.Object); await sut.Post(expected.ToDto()); dm.Verify(r => r.Create(Grandfather.Id, expected)); }
The test now passes (until the next change in the SUT), but notice how top-heavy it becomes. That's a test code smell when using dynamic mocks. Everything has to happen in the Arrange phase.
You typically have many such tests that you need to edit. The name of this antipattern is Shotgun Surgery.
The implication is that refactoring by definition is impossible:
"to refactor, the essential precondition is [...] solid tests"
You need tests that don't break when you refactor. When you use dynamic mocks, tests tend to fail whenever you make changes in SUTs. Even though you have tests, they don't enable refactoring.
To add spite to injury, every time you edit existing tests, they become less trustworthy.
To address these problems, use Fakes instead of Mocks and Stubs. With the FakeDatabase the entire sample test suite for the online restaurant reservation system gracefully handles the change described above. No tests fail.
Spies #
If you spelunk the test code base for the book, you may also find this Test Double:
internal sealed class SpyPostOffice : Collection<SpyPostOffice.Observation>, IPostOffice { public Task EmailReservationCreated( int restaurantId, Reservation reservation) { Add(new Observation(Event.Created, restaurantId, reservation)); return Task.CompletedTask; } public Task EmailReservationDeleted( int restaurantId, Reservation reservation) { Add(new Observation(Event.Deleted, restaurantId, reservation)); return Task.CompletedTask; } public Task EmailReservationUpdating( int restaurantId, Reservation reservation) { Add(new Observation(Event.Updating, restaurantId, reservation)); return Task.CompletedTask; } public Task EmailReservationUpdated( int restaurantId, Reservation reservation) { Add(new Observation(Event.Updated, restaurantId, reservation)); return Task.CompletedTask; } internal enum Event { Created = 0, Updating, Updated, Deleted } internal sealed class Observation { public Observation( Event @event, int restaurantId, Reservation reservation) { Event = @event; RestaurantId = restaurantId; Reservation = reservation; } public Event Event { get; } public int RestaurantId { get; } public Reservation Reservation { get; } public override bool Equals(object? obj) { return obj is Observation observation && Event == observation.Event && RestaurantId == observation.RestaurantId && EqualityComparer<Reservation>.Default.Equals(Reservation, observation.Reservation); } public override int GetHashCode() { return HashCode.Combine(Event, RestaurantId, Reservation); } } }
As you can see, I've chosen to name this class with the Spy prefix, indicating that this is a Test Spy rather than a Fake Object. A Spy is a Test Double whose main purpose is to observe and record interactions. Does that break or realise encapsulation?
While I favour Fakes whenever possible, consider the interface that SpyPostOffice implements:
public interface IPostOffice { Task EmailReservationCreated(int restaurantId, Reservation reservation); Task EmailReservationDeleted(int restaurantId, Reservation reservation); Task EmailReservationUpdating(int restaurantId, Reservation reservation); Task EmailReservationUpdated(int restaurantId, Reservation reservation); }
This interface consist entirely of Commands. There's no way to query the interface to examine the state of the object. Thus, you can't check that postconditions hold exclusively via the interface. Instead, you need an additional retrieval interface to examine the posterior state of the object. The SpyPostOffice concrete class exposes such an interface.
In a sense, you can view SpyPostOffice as an in-memory message sink. It fulfils the contract.
Concurrency #
Perhaps you're still not convinced. You may argue, for example, that the (partial) contract that I stated is naive. Consider, again, the implications expressed as code:
await sut.Create(restaurantId, expected); var actual = await sut.ReadReservation(restaurantId, expected.Id); Assert.Equal(expected, actual);
You may argue that in the face of concurrency, another thread or process could be making changes to the reservation after Create, but before ReadReservation. Thus, you may argue, the contract I've stipulated is false. In a real system, we can't expect that to be the case.
I agree.
Concurrency makes things much harder. Even in that light, I think the above line of reasoning is appropriate, for two reasons.
First, I chose to model IReservationsRepository like I did because I didn't expect high contention on individual reservations. In other words, I don't expect two or more concurrent processes to attempt to modify the same reservation at the same time. Thus, I found it appropriate to model the Repository as
"a collection-like interface for accessing domain objects."
A collection-like interface implies both data retrieval and collection manipulation members. In low-contention scenarios like the reservation system, this turns out to be a useful model. As the aphorism goes, all models are wrong, but some models are useful. Treating IReservationsRepository as a collection accessed in a non-concurrent manner turned out to be useful in this code base.
Had I been more worried about data contention, a move towards CQRS seems promising. This leads to another object model, with different contracts.
Second, even in the face of concurrency, most unit test cases are implicitly running on a single thread. While they may run in parallel, each unit test exercises the SUT on a single thread. This implies that reads and writes against Test Doubles are serialised.
Even if concurrency is a real concern, you'd still expect that if only one thread is manipulating the Repository object, then what you Create you should be able to retrieve. The contract may be a little looser, but it'd still be a violation of the principle of least surprise if it was any different.
Conclusion #
In object-oriented programming, encapsulation is the notion of separating the affordances of an object from its implementation details. I find it most practical to think about this in terms of contracts, which again can be subdivided into sets of preconditions, invariants, and postconditions.
Polymorphic objects (like interfaces and base classes) come with contracts as well. When you replace 'real' implementations with Test Doubles, the Test Doubles should also fulfil the contracts. Fake objects do that; Test Spies may also fit that description.
When Test Doubles obey their contracts, you can refactor your SUT without breaking your test suite.
By default, however, dynamic mocks break encapsulation because they don't fulfil the objects' contracts. This leads to fragile tests.
Favour Fakes over dynamic mocks. You can read more about this way to write tests by following many of the links in this article, or by reading my book Code That Fits in Your Head.
Comments
Excellent article exploring the nuances of encapsulation as it relates to testing. That said, the examples here left me with one big question: what exactly is covered by the tests using `FakeDatabase`?
This line in particular is confusing me (as to its practical use in a "real-world" setting): `var sut = new FakeDatabase();`
How can I claim to have tested the real system's implementation when the "system under test" is, in this approach, explicitly _not_ my real system? It appears the same criticism of dynamic mocks surfaces: "you're only testing the fake database". Does this approach align with any claim you are testing the "real database"?
When testing the data-layer, I have historically written (heavier) tests that integrate with a real database to exercise a system's data-layer (as you describe with `SqlReservationsRepository`). I find myself reaching for dynamic mocks in the context of exercising an application's domain layer -- where the data-layer is a dependency providing indirect input/output. Does this use of mocks violate encapsulation in the way this article describes? I _think_ not, because in that case a dynamic mock is used to represent states that are valid "according to the contract", but I'm hoping you could shed a bit more light on the topic. Am I putting the pieces together correctly?
Rephrasing the question using your Reservations example code, I would typically inject `IReservationsRepository` into `MaitreD` (which you opt not to do) and outline the posssible database return values (or commands) using dynamic mocks in a test suite of `MaitreD`. What drawbacks, if any, would that approach lead to with respect to encapsulation and test fragility?
Matthew, thank you for writing. I apologise if the article is unclear about this, but nowhere in the real code base do I have a test of FakeDatabase. I only wrote the tests that exercise the Test Doubles to illustrate the point I was trying to make. These tests only exist for the benefit of this article.
The first CreateAndReadRoundTrip test in the article shows a real integration test. The System Under Test (SUT) is the SqlReservationsRepository class, which is part of the production code - not a Test Double.
That class implements the IReservationsRepository interface. The point I was trying to make is that the CreateAndReadRoundTrip test already exercises a particular subset of the contract of the interface. Thus, if one replaces one implementation of the interface with another implementation, according to the Liskov Substitution Principle (LSP) the test should still pass.
This is true for FakeDatabase. While the behaviour is different (it doesn't persist data), it still fulfils the contract. Dynamic mocks, on the other hand, don't automatically follow the LSP. Unless one is careful and explicit, dynamic mocks tend to weaken postconditions. For example, a dynamic mock doesn't automatically return the added reservation when you call ReadReservation.
This is an essential flaw of dynamic mock objects that is independent of where you use them. My article already describes how a fairly innocuous change in the production code will cause a dynamic mock to break the test.
I no longer inject dependencies into domain models, since doing so makes the domain model impure. Even if I did, however, I'd still have the same problem with dynamic mocks breaking encapsulation.
Refactoring a saga from the State pattern to the State monad
A slightly less unrealistic example in C#.
This article is one of the examples that I promised in the earlier article The State pattern and the State monad. That article examines the relationship between the State design pattern and the State monad. It's deliberately abstract, so one or more examples are in order.
In the previous example you saw how to refactor Design Patterns' TCP connection example. That example is, unfortunately, hardly illuminating due to its nature, so a second example is warranted.
This second example shows how to refactor a stateful asynchronous message handler from the State pattern to the State monad.
Shipping policy #
Instead of inventing an example from scratch, I decided to use an NServiceBus saga tutorial as a foundation. Read on even if you don't know NServiceBus. You don't have to know anything about NServiceBus in order to follow along. I just thought that I'd embed the example code in a context that actually executes and does something, instead of faking it with a bunch of unit tests. Hopefully this will help make the example a bit more realistic and relatable.
The example is a simple demo of asynchronous message handling. In a web store shipping department, you should only ship an item once you've received the order and a billing confirmation. When working with asynchronous messaging, you can't, however, rely on message ordering, so perhaps the OrderBilled message arrives before the OrderPlaced message, and sometimes it's the other way around.
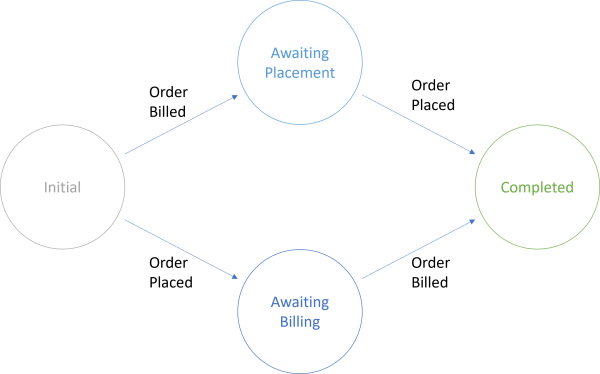
Only when you've received both messages may you ship the item.
It's a simple workflow, and you don't really need the State pattern. So much is clear from the sample code implementation:
public class ShippingPolicy : Saga<ShippingPolicyData>, IAmStartedByMessages<OrderBilled>, IAmStartedByMessages<OrderPlaced> { static ILog log = LogManager.GetLogger<ShippingPolicy>(); protected override void ConfigureHowToFindSaga(SagaPropertyMapper<ShippingPolicyData> mapper) { mapper.MapSaga(sagaData => sagaData.OrderId) .ToMessage<OrderPlaced>(message => message.OrderId) .ToMessage<OrderBilled>(message => message.OrderId); } public Task Handle(OrderPlaced message, IMessageHandlerContext context) { log.Info($"OrderPlaced message received."); Data.IsOrderPlaced = true; return ProcessOrder(context); } public Task Handle(OrderBilled message, IMessageHandlerContext context) { log.Info($"OrderBilled message received."); Data.IsOrderBilled = true; return ProcessOrder(context); } private async Task ProcessOrder(IMessageHandlerContext context) { if (Data.IsOrderPlaced && Data.IsOrderBilled) { await context.SendLocal(new ShipOrder() { OrderId = Data.OrderId }); MarkAsComplete(); } } }
I don't expect you to be familiar with the NServiceBus API, so don't worry about the base class, the interfaces, or the ConfigureHowToFindSaga method. What you need to know is that this class handles two types of messages: OrderPlaced and OrderBilled. What the base class and the framework does is handling message correlation, hydration and dehydration, and so on.
For the purposes of this demo, all you need to know about the context object is that it enables you to send and publish messages. The code sample uses context.SendLocal to send a new ShipOrder Command.
Messages arrive asynchronously and conceptually with long wait times between them. You can't just rely on in-memory object state because a ShippingPolicy instance may receive one message and then risk that the server it's running on shuts down before the next message arrives. The NServiceBus framework handles message correlation and hydration and dehydration of state data. The latter is modelled by the ShippingPolicyData class:
public class ShippingPolicyData : ContainSagaData { public string OrderId { get; set; } public bool IsOrderPlaced { get; set; } public bool IsOrderBilled { get; set; } }
Notice that the above sample code inspects and manipulates the Data property defined by the Saga<ShippingPolicyData> base class.
When the ShippingPolicy methods are called by the NServiceBus framework, the Data is automatically populated. When you modify the Data, the state data is automatically persisted when the message handler shuts down to wait for the next message.
Characterisation tests #
While you can draw an explicit state diagram like the one above, the sample code doesn't explicitly model the various states as objects. Instead, it relies on reading and writing two Boolean values.
There's nothing wrong with this implementation. It's the simplest thing that could possibly work, so why make it more complicated?
In this article, I am going to make it more complicated. First, I'm going to refactor the above sample code to use the State design pattern, and then I'm going to refactor that code to use the State monad. From a perspective of maintainability, this isn't warranted, but on the other hand, I hope it's educational. The sample code is just complex enough to showcase the structures of the State pattern and the State monad, yet simple enough that the implementation logic doesn't get in the way.
Simplicity can be deceiving, however, and no refactoring is without risk.
"to refactor, the essential precondition is [...] solid tests"
I found it safest to first add a few Characterisation Tests to make sure I didn't introduce any errors as I changed the code. It did catch a few copy-paste goofs that I made, so adding tests turned out to be a good idea.
Testing NServiceBus message handlers isn't too hard. All the tests I wrote look similar, so one should be enough to give you an idea.
[Theory] [InlineData("1337")] [InlineData("baz")] public async Task OrderPlacedAndBilled(string orderId) { var sut = new ShippingPolicy { Data = new ShippingPolicyData { OrderId = orderId } }; var ctx = new TestableMessageHandlerContext(); await sut.Handle(new OrderPlaced { OrderId = orderId }, ctx); await sut.Handle(new OrderBilled { OrderId = orderId }, ctx); Assert.True(sut.Completed); var msg = Assert.Single(ctx.SentMessages.Containing<ShipOrder>()); Assert.Equal(orderId, msg.Message.OrderId); }
The tests use xUnit.net 2.4.2. When I downloaded the NServiceBus saga sample code it targeted .NET Framework 4.8, and I didn't bother to change the version.
While the NServiceBus framework will automatically hydrate and populate Data, in a unit test you have to remember to explicitly populate it. The TestableMessageHandlerContext class is a Test Spy that is part of NServiceBus testing API.
You'd think I was paid by Particular Software to write this article, but I'm not. All this is really just the introduction. You're excused if you've forgotten the topic of this article, but my goal is to show a State pattern example. Only now can we begin in earnest.
State pattern implementation #
Refactoring to the State pattern, I chose to let the ShippingPolicy class fill the role of the pattern's Context. Instead of a base class with virtual method, I used an interface to define the State object, as that's more Idiomatic in C#:
public interface IShippingState { Task OrderPlaced(OrderPlaced message, IMessageHandlerContext context, ShippingPolicy policy); Task OrderBilled(OrderBilled message, IMessageHandlerContext context, ShippingPolicy policy); }
The State pattern only shows examples where the State methods take a single argument: The Context. In this case, that's the ShippingPolicy. Careful! There's also a parameter called context! That's the NServiceBus context, and is an artefact of the original example. The two other parameters, message and context, are run-time values passed on from the ShippingPolicy's Handle methods:
public IShippingState State { get; internal set; } public async Task Handle(OrderPlaced message, IMessageHandlerContext context) { log.Info($"OrderPlaced message received."); Hydrate(); await State.OrderPlaced(message, context, this); Dehydrate(); } public async Task Handle(OrderBilled message, IMessageHandlerContext context) { log.Info($"OrderBilled message received."); Hydrate(); await State.OrderBilled(message, context, this); Dehydrate(); }
The Hydrate method isn't part of the State pattern, but finds an appropriate state based on Data:
private void Hydrate() { if (!Data.IsOrderPlaced && !Data.IsOrderBilled) State = InitialShippingState.Instance; else if (Data.IsOrderPlaced && !Data.IsOrderBilled) State = AwaitingBillingState.Instance; else if (!Data.IsOrderPlaced && Data.IsOrderBilled) State = AwaitingPlacementState.Instance; else State = CompletedShippingState.Instance; }
In more recent versions of C# you'd be able to use more succinct pattern matching, but since this code base is on .NET Framework 4.8 I'm constrained to C# 7.3 and this is as good as I cared to make it. It's not important to the topic of the State pattern, but I'm showing it in case you where wondering. It's typical that you need to translate between data that exists in the 'external world' and your object-oriented, polymorphic code, since at the boundaries, applications aren't object-oriented.
Likewise, the Dehydrate method translates the other way:
private void Dehydrate() { if (State is AwaitingBillingState) { Data.IsOrderPlaced = true; Data.IsOrderBilled = false; return; } if (State is AwaitingPlacementState) { Data.IsOrderPlaced = false; Data.IsOrderBilled = true; return; } if (State is CompletedShippingState) { Data.IsOrderPlaced = true; Data.IsOrderBilled = true; return; } Data.IsOrderPlaced = false; Data.IsOrderBilled = false; }
In any case, Hydrate and Dehydrate are distractions. The important part is that the ShippingPolicy (the State Context) now delegates execution to its State, which performs the actual work and updates the State.
Initial state #
The first time the saga runs, both Data.IsOrderPlaced and Data.IsOrderBilled are false, which means that the State is InitialShippingState:
public sealed class InitialShippingState : IShippingState { public readonly static InitialShippingState Instance = new InitialShippingState(); private InitialShippingState() { } public Task OrderPlaced( OrderPlaced message, IMessageHandlerContext context, ShippingPolicy policy) { policy.State = AwaitingBillingState.Instance; return Task.CompletedTask; } public Task OrderBilled( OrderBilled message, IMessageHandlerContext context, ShippingPolicy policy) { policy.State = AwaitingPlacementState.Instance; return Task.CompletedTask; } }
As the above state transition diagram indicates, the only thing that each of the methods do is that they transition to the next appropriate state: AwaitingBillingState if the first event was OrderPlaced, and AwaitingPlacementState when the event was OrderBilled.
"State object are often Singletons"
Like in the previous example I've made all the State objects Singletons. It's not that important, but since they are all stateless, we might as well. At least, it's in the spirit of the book.
Awaiting billing #
AwaitingBillingState is another IShippingState implementation:
public sealed class AwaitingBillingState : IShippingState { public readonly static IShippingState Instance = new AwaitingBillingState(); private AwaitingBillingState() { } public Task OrderPlaced( OrderPlaced message, IMessageHandlerContext context, ShippingPolicy policy) { return Task.CompletedTask; } public async Task OrderBilled( OrderBilled message, IMessageHandlerContext context, ShippingPolicy policy) { await context.SendLocal( new ShipOrder() { OrderId = policy.Data.OrderId }); policy.Complete(); policy.State = CompletedShippingState.Instance; } }
This State doesn't react to OrderPlaced because it assumes that an order has already been placed. It only reacts to an OrderBilled event. When that happens, all requirements have been fulfilled to ship the item, so it sends a ShipOrder Command, marks the saga as completed, and changes the State to CompletedShippingState.
The Complete method is a little wrapper method I had to add to the ShippingPolicy class, since MarkAsComplete is a protected method:
internal void Complete() { MarkAsComplete(); }
The AwaitingPlacementState class is similar to AwaitingBillingState, except that it reacts to OrderPlaced rather than OrderBilled.
Terminal state #
The fourth and final state is the CompletedShippingState:
public sealed class CompletedShippingState : IShippingState { public readonly static IShippingState Instance = new CompletedShippingState(); private CompletedShippingState() { } public Task OrderPlaced( OrderPlaced message, IMessageHandlerContext context, ShippingPolicy policy) { return Task.CompletedTask; } public Task OrderBilled( OrderBilled message, IMessageHandlerContext context, ShippingPolicy policy) { return Task.CompletedTask; } }
In this state, the saga is completed, so it ignores both events.
Move Commands to output #
The saga now uses the State pattern to manage state-specific behaviour as well as state transitions. To be clear, this complexity isn't warranted for the simple requirements. This is, after all, an example. All tests still pass, and smoke testing also indicates that everything still works as it's supposed to.
The goal of this article is now to refactor the State pattern implementation to pure functions. When the saga runs it has an observable side effect: It eventually sends a ShipOrder Command. During processing it also updates its internal state. Both of these are sources of impurity that we have to decouple from the decision logic.
I'll do this in several steps. The first impure action I'll address is the externally observable message transmission. A common functional-programming trick is to turn a side effect into a return value. So far, the IShippingState methods don't return anything. (This is strictly not true; they each return Task, but we can regard Task as 'asynchronous void'.) Thus, return values are still available as a communications channel.
Refactor the IShippingState methods to return Commands instead of actually sending them. Each method may send an arbitrary number of Commands, including none, so the return type has to be a collection:
public interface IShippingState { IReadOnlyCollection<ICommand> OrderPlaced( OrderPlaced message, IMessageHandlerContext context, ShippingPolicy policy); IReadOnlyCollection<ICommand> OrderBilled( OrderBilled message, IMessageHandlerContext context, ShippingPolicy policy); }
When you change the interface you also have to change all the implementing classes, including AwaitingBillingState:
public sealed class AwaitingBillingState : IShippingState { public readonly static IShippingState Instance = new AwaitingBillingState(); private AwaitingBillingState() { } public IReadOnlyCollection<ICommand> OrderPlaced( OrderPlaced message, IMessageHandlerContext context, ShippingPolicy policy) { return Array.Empty<ICommand>(); } public IReadOnlyCollection<ICommand> OrderBilled( OrderBilled message, IMessageHandlerContext context, ShippingPolicy policy) { policy.Complete(); policy.State = CompletedShippingState.Instance; return new[] { new ShipOrder() { OrderId = policy.Data.OrderId } }; } }
In order to do nothing a method like OrderPlaced now has to return an empty collection of Commands. In order to 'send' a Command, OrderBilled now returns it instead of using the context to send it. The context is already redundant, but since I prefer to move in small steps, I'll remove it in a separate step.
It's now the responsibility of the ShippingPolicy class to do something with the Commands returned by the State:
public async Task Handle(OrderBilled message, IMessageHandlerContext context) { log.Info($"OrderBilled message received."); Hydrate(); var result = State.OrderBilled(message, context, this); await Interpret(result, context); Dehydrate(); } private async Task Interpret( IReadOnlyCollection<ICommand> commands, IMessageHandlerContext context) { foreach (var cmd in commands) await context.SendLocal(cmd); }
In functional programming, you often run an interpreter over the instructions returned by a pure function. Here the interpreter is just a private helper method.
The IShippingState methods are no longer asynchronous. Now they just return collections. I consider that a simplification.
Remove context parameter #
The context parameter is now redundant, so remove it from the IShippingState interface:
public interface IShippingState { IReadOnlyCollection<ICommand> OrderPlaced(OrderPlaced message, ShippingPolicy policy); IReadOnlyCollection<ICommand> OrderBilled(OrderBilled message, ShippingPolicy policy); }
I used Visual Studio's built-in refactoring tools to remove the parameter, which automatically removed it from all the call sites and implementations.
This takes us part of the way towards implementing the states as pure functions, but there's still work to be done.
public IReadOnlyCollection<ICommand> OrderBilled(OrderBilled message, ShippingPolicy policy) { policy.Complete(); policy.State = CompletedShippingState.Instance; return new[] { new ShipOrder() { OrderId = policy.Data.OrderId } }; }
The above OrderBilled implementation calls policy.Complete to indicate that the saga has completed. That's another state mutation that must be eliminated to make this a pure function.
Return complex result #
How do you refactor from state mutation to pure function? You turn the mutation statement into an instruction, which is a value that you return. In this case you might want to return a Boolean value: True to complete the saga. False otherwise.
There seems to be a problem, though. The IShippingState methods already return data: They return a collection of Commands. How do we get around this conundrum?
Introduce a complex object:
public sealed class ShippingStateResult { public ShippingStateResult( IReadOnlyCollection<ICommand> commands, bool completeSaga) { Commands = commands; CompleteSaga = completeSaga; } public IReadOnlyCollection<ICommand> Commands { get; } public bool CompleteSaga { get; } public override bool Equals(object obj) { return obj is ShippingStateResult result && EqualityComparer<IReadOnlyCollection<ICommand>>.Default .Equals(Commands, result.Commands) && CompleteSaga == result.CompleteSaga; } public override int GetHashCode() { int hashCode = -1668187231; hashCode = hashCode * -1521134295 + EqualityComparer<IReadOnlyCollection<ICommand>> .Default.GetHashCode(Commands); hashCode = hashCode * -1521134295 + CompleteSaga.GetHashCode(); return hashCode; } }
That looks rather horrible, but most of the code is generated by Visual Studio. The only thing I wrote myself was the class declaration and the two read-only properties. I then used Visual Studio's Generate constructor and Generate Equals and GetHashCode Quick Actions to produce the rest of the code.
With more modern versions of C# I could have used a record, but as I've already mentioned, I'm on C# 7.3 here.
The IShippingState interface can now define its methods with this new return type:
public interface IShippingState { ShippingStateResult OrderPlaced(OrderPlaced message, ShippingPolicy policy); ShippingStateResult OrderBilled(OrderBilled message, ShippingPolicy policy); }
This change reminds me of the Introduce Parameter Object refactoring, but instead applied to the return value instead of input.
Implementers now have to return values of this new type:
public sealed class AwaitingBillingState : IShippingState { public readonly static IShippingState Instance = new AwaitingBillingState(); private AwaitingBillingState() { } public ShippingStateResult OrderPlaced(OrderPlaced message, ShippingPolicy policy) { return new ShippingStateResult(Array.Empty<ICommand>(), false); } public ShippingStateResult OrderBilled(OrderBilled message, ShippingPolicy policy) { policy.State = CompletedShippingState.Instance; return new ShippingStateResult( new[] { new ShipOrder() { OrderId = policy.Data.OrderId } }, true); } }
Moving a statement to an output value implies that the effect must happen somewhere else. It seems natural to put it in the ShippingPolicy class' Interpret method:
public async Task Handle(OrderBilled message, IMessageHandlerContext context) { log.Info($"OrderBilled message received."); Hydrate(); var result = State.OrderBilled(message, this); await Interpret(result, context); Dehydrate(); } private async Task Interpret(ShippingStateResult result, IMessageHandlerContext context) { foreach (var cmd in result.Commands) await context.SendLocal(cmd); if (result.CompleteSaga) MarkAsComplete(); }
Since Interpret is an instance method on the ShippingPolicy class I can now also delete the internal Complete method, since MarkAsComplete is already callable (it's a protected method defined by the Saga base class).
Use message data #
Have you noticed an odd thing about the code so far? It doesn't use any of the message data!
This is an artefact of the original code example. Refer back to the original ProcessOrder helper method. It uses neither OrderPlaced nor OrderBilled for anything. Instead, it pulls the OrderId from the saga's Data property. It can do that because NServiceBus makes sure that all OrderId values are correlated. It'll only instantiate a saga for which Data.OrderId matches OrderPlaced.OrderId or OrderBilled.OrderId. Thus, these values are guaranteed to be the same, and that's why ProcessOrder can get away with using Data.OrderId instead of the message data.
So far, through all refactorings, I've retained this detail, but it seems odd. It also couples the implementation methods to the ShippingPolicy class rather than the message classes. For these reasons, refactor the methods to use the message data instead. Here's the AwaitingBillingState implementation:
public ShippingStateResult OrderBilled(OrderBilled message, ShippingPolicy policy) { policy.State = CompletedShippingState.Instance; return new ShippingStateResult( new[] { new ShipOrder() { OrderId = message.OrderId } }, true); }
Compare this version with the previous iteration, where it used policy.Data.OrderId instead of message.OrderId.
Now, the only reason to pass ShippingPolicy as a method parameter is to mutate policy.State. We'll get to that in due time, but first, there's another issue I'd like to address.
Immutable arguments #
Keep in mind that the overall goal of the exercise is to refactor the state machine to pure functions. For good measure, method parameters should be immutable as well. Consider a method like OrderBilled shown above in its most recent iteration. It mutates policy by setting policy.State. The long-term goal is to get rid of that statement.
The method doesn't mutate the other argument, message, but the OrderBilled class is actually mutable:
public class OrderBilled : IEvent { public string OrderId { get; set; } }
The same is true for the other message type, OrderPlaced.
For good measure, pure functions shouldn't take mutable arguments. You could argue that, since none of the implementation methods actually mutate the messages, it doesn't really matter. I am, however, enough of a neat freak that I don't like to leave such a loose strand dangling. I'd like to refactor the IShippingState API so that only immutable message data is passed as arguments.
In a situation like this, there are (at least) three options:
-
Make the message types immutable. This would mean making
OrderBilledandOrderPlacedimmutable. These message types are by default mutable Data Transfer Objects (DTO), because NServiceBus needs to serialise and deserialise them to transmit them over durable queues. There are ways you can configure NServiceBus to use serialisation mechanisms that enable immutable records as messages, but for an example code base like this, I might be inclined to reach for an easier solution if one presents itself. -
Add an immutable 'mirror' class. This may often be a good idea if you have a rich domain model that you'd like to represent. You can see an example of that in Code That Fits in Your Head, where there's both a mutable
ReservationDtoclass and an immutableReservationValue Object. This makes sense if the invariants of the domain model are sufficiently stronger than the DTO. That hardly seems to be the case here, since both messages only contain anOrderId. -
Dissolve the DTO into its constituents and pass each as an argument. This doesn't work if the DTO is complex and nested, but here there's only a single constituent element, and that's the
OrderIdproperty.
The third option seems like the simplest solution, so refactor the IShippingState methods to take an orderId parameter instead of a message:
public interface IShippingState { ShippingStateResult OrderPlaced(string orderId, ShippingPolicy policy); ShippingStateResult OrderBilled(string orderId, ShippingPolicy policy); }
While this is the easiest of the three options given above, the refactoring doesn't hinge on this. It would work just as well with one of the two other options.
Implementations now look like this:
public ShippingStateResult OrderBilled(string orderId, ShippingPolicy policy) { policy.State = CompletedShippingState.Instance; return new ShippingStateResult( new[] { new ShipOrder() { OrderId = orderId } }, true); }
The only impure action still lingering is the mutation of policy.State. Once we're rid of that, the API consists of pure functions.
Return state #
As outlined by the parent article, instead of mutating the caller's state, you can return the state as part of a tuple. This means that you no longer need to pass ShippingPolicy as a parameter:
public interface IShippingState { Tuple<ShippingStateResult, IShippingState> OrderPlaced(string orderId); Tuple<ShippingStateResult, IShippingState> OrderBilled(string orderId); }
Why not expand the ShippingStateResult class, or conversely, dissolve that class and instead return a triple (a three-tuple)? All of these are possible as alternatives, as they'd be isomorphic to this particular design. The reason I've chosen this particular return type is that it's the idiomatic implementation of the State monad: The result is the first element of a tuple, and the state is the second element. This means that you can use a standard, reusable State monad library to manipulate the values, as you'll see later.
An implementation now looks like this:
public sealed class AwaitingBillingState : IShippingState { public readonly static IShippingState Instance = new AwaitingBillingState(); private AwaitingBillingState() { } public Tuple<ShippingStateResult, IShippingState> OrderPlaced(string orderId) { return Tuple.Create( new ShippingStateResult(Array.Empty<ICommand>(), false), (IShippingState)this); } public Tuple<ShippingStateResult, IShippingState> OrderBilled(string orderId) { return Tuple.Create( new ShippingStateResult( new[] { new ShipOrder() { OrderId = orderId } }, true), CompletedShippingState.Instance); } }
Since the ShippingPolicy class that calls these methods now directly receives the state as part of the output, it no longer needs a mutable State property. Instead, it immediately handles the return value:
public async Task Handle(OrderPlaced message, IMessageHandlerContext context) { log.Info($"OrderPlaced message received."); var state = Hydrate(); var result = state.OrderPlaced(message.OrderId); await Interpret(result.Item1, context); Dehydrate(result.Item2); } public async Task Handle(OrderBilled message, IMessageHandlerContext context) { log.Info($"OrderBilled message received."); var state = Hydrate(); var result = state.OrderBilled(message.OrderId); await Interpret(result.Item1, context); Dehydrate(result.Item2); }
Each Handle method is now an impureim sandwich.
Since the result is now a tuple, the Handle methods now have to pass the first element (result.Item1) to the Interpret helper method, and the second element (result.Item2) - the state - to Dehydrate. It's also possible to pattern match (or destructure) each of the elements directly; you'll see an example of that later.
Since the mutable State property is now gone, the Hydrate method returns the hydrated state:
private IShippingState Hydrate() { if (!Data.IsOrderPlaced && !Data.IsOrderBilled) return InitialShippingState.Instance; else if (Data.IsOrderPlaced && !Data.IsOrderBilled) return AwaitingBillingState.Instance; else if (!Data.IsOrderPlaced && Data.IsOrderBilled) return AwaitingPlacementState.Instance; else return CompletedShippingState.Instance; }
Likewise, the Dehydrate method takes the new state as an input parameter:
private void Dehydrate(IShippingState state) { if (state is AwaitingBillingState) { Data.IsOrderPlaced = true; Data.IsOrderBilled = false; return; } if (state is AwaitingPlacementState) { Data.IsOrderPlaced = false; Data.IsOrderBilled = true; return; } if (state is CompletedShippingState) { Data.IsOrderPlaced = true; Data.IsOrderBilled = true; return; } Data.IsOrderPlaced = false; Data.IsOrderBilled = false; }
Since each Handle method only calls a single State-valued method, they don't need the State monad machinery. This only becomes useful when you need to compose multiple State-based operations.
This might be useful in unit tests, so let's examine that next.
State monad #
In previous articles about the State monad you've seen it implemented based on an IState interface. I've also dropped hints here and there that you don't need the interface. Instead, you can implement the monad functions directly on State-valued functions. That's what I'm going to do here:
public static Func<S, Tuple<T1, S>> SelectMany<S, T, T1>( this Func<S, Tuple<T, S>> source, Func<T, Func<S, Tuple<T1, S>>> selector) { return s => { var tuple = source(s); var f = selector(tuple.Item1); return f(tuple.Item2); }; }
This SelectMany implementation works directly on another function, source. This function takes a state of type S as input and returns a tuple as a result. The first element is the result of type T, and the second element is the new state, still of type S. Compare that to the IState interface to convince yourself that these are just two representations of the same idea.
The return value is a new function with the same shape, but where the result type is T1 rather than T.
You can implement the special SelectMany overload that enables query syntax in the standard way.
The return function also mirrors the previous interface-based implementation:
public static Func<S, Tuple<T, S>> Return<S, T>(T x) { return s => Tuple.Create(x, s); }
You can also implement the standard Get, Put, and Modify functions, but we are not going to need them here. Try it as an exercise.
State-valued event handlers #
The IShippingState methods almost look like State values, but the arguments are in the wrong order. A State value is a function that takes state as input and returns a tuple. The methods on IShippingState, however, take orderId as input and return a tuple. The state is also present, but as the instance that exposes the methods. We have to flip the arguments:
public static Func<IShippingState, Tuple<ShippingStateResult, IShippingState>> Billed( this string orderId) { return s => s.OrderBilled(orderId); } public static Func<IShippingState, Tuple<ShippingStateResult, IShippingState>> Placed( this string orderId) { return s => s.OrderPlaced(orderId); }
This is a typical example of how you have to turn things on their heads in functional programming, compared to object-oriented programming. These two methods convert OrderBilled and OrderPlaced to State monad values.
Testing state results #
A unit test demonstrates how this enables you to compose multiple stateful operations using query syntax:
[Theory] [InlineData("90125")] [InlineData("quux")] public void StateResultExample(string orderId) { var sf = from x in orderId.Placed() from y in orderId.Billed() select new[] { x, y }; var (results, finalState) = sf(InitialShippingState.Instance); Assert.Equal( new[] { false, true }, results.Select(r => r.CompleteSaga)); Assert.Single( results .SelectMany(r => r.Commands) .OfType<ShipOrder>() .Select(msg => msg.OrderId), orderId); Assert.Equal(CompletedShippingState.Instance, finalState); }
Keep in mind that a State monad value is a function. That's the reason I called the composition sf - for State Function. When you execute it with InitialShippingState as input it returns a tuple that the test immediately pattern matches (destructures) into its constituent elements.
The test then asserts that the results and finalState are as expected. The assertions against results are a bit awkward, since C# collections don't have structural equality. These assertions would have been simpler in F# or Haskell.
Testing with an interpreter #
While the Arrange and Act phases of the above test are simple, the Assertion phase seems awkward. Another testing strategy is to run a test-specific interpreter over the instructions returned as the State computation result:
[Theory] [InlineData("1984")] [InlineData("quuz")] public void StateInterpretationExample(string orderId) { var sf = from x in orderId.Placed() from y in orderId.Billed() select new[] { x, y }; var (results, finalState) = sf(InitialShippingState.Instance); Assert.Equal(CompletedShippingState.Instance, finalState); var result = Interpret(results); Assert.True(result.CompleteSaga); Assert.Single( result.Commands.OfType<ShipOrder>().Select(msg => msg.OrderId), orderId); }
It helps a little, but the assertions still have to work around the lack of structural equality of result.Commands.
Monoid #
The test-specific Interpret helper method is interesting in its own right, though:
private ShippingStateResult Interpret(IEnumerable<ShippingStateResult> results) { var identity = new ShippingStateResult(Array.Empty<ICommand>(), false); ShippingStateResult Combine(ShippingStateResult x, ShippingStateResult y) { return new ShippingStateResult( x.Commands.Concat(y.Commands).ToArray(), x.CompleteSaga || y.CompleteSaga); } return results.Aggregate(identity, Combine); }
It wasn't until I started implementing this helper method that I realised that ShippingStateResult gives rise to a monoid! Since monoids accumulate, you can start with the identity and use the binary operation (here called Combine) to Aggregate an arbitrary number of ShippingStateResult values into one.
The ShippingStateResult class is composed of two constituent values (a collection and a Boolean value), and since both of these give rise to one or more monoids, a tuple of those monoids itself gives rise to one or more monoids. The ShippingStateResult is isomorphic to a tuple, so this result carries over.
Should you move the Combine method and the identity value to the ShippingStateResult class itself. After all, putting them in a test-specific helper method smells a bit of Feature Envy.
This seems compelling, but it's not clear that arbitrary client code might need this particular monoid. After all, there are four monoids over Boolean values, and at least two over collections. That's eight possible combinations. Which one should ShippingStateResult expose as members?
The monoid used in Interpret combines the normal collection monoid with the any monoid. That seems appropriate in this case, but other clients might rather need the all monoid.
Without more usage examples, I decided to leave the code as an Interpret implementation detail for now.
In any case, I find it worth noting that by decoupling the state logic from the NServiceBus framework, it's possible to test it without running asynchronous workflows.
Conclusion #
In this article you saw how to implement an asynchronous messaging saga in three different ways. First, as a simple ad-hoc solution, second using the State pattern, and third implemented with the State monad. Both the State pattern and State monad implementations are meant exclusively to showcase these two techniques. The first solution using two Boolean flags is by far the simplest solution, and the one I'd use in a production system.
The point is that you can use the State monad if you need to write stateful computations. This may include finite state machines, as otherwise addressed by the State design pattern, but could also include other algorithms where you need to keep track of state.
Next: Postel's law as a profunctor.
Some thoughts on the economics of programming
On the net value of process and code quality.
Once upon a time there was a software company that had a special way of doing things. No other company had ever done things quite like that before, but the company had much success. In short time it rose to dominance in the market, outcompeting all serious competition. Some people disliked the company because of its business tactics and sheer size, but others admired it.
Even more wanted to be like it.
How did the company achieve its indisputable success? It looked as though it was really, really good at making software. How did they write such good software?
It turned out that the company had a special software development process.
Other software organisations, hoping to be able to be as successful, tried to copy the special process. The company was willing to share. Its employees wrote about the process. They gave conference presentations on their special sauce.
Which company do I have in mind, and what was the trick that made it so much better than its competition? Was it microservices? Monorepos? Kubernetes? DevOps? Serverless?
No, the company was Microsoft and the development process was called Microsoft Solutions Framework (MSF).
What?! do you say.
You've never heard of MSF?
That's hardly surprising. I doubt that MSF was in any way related to Microsoft's success.
Net profits #
These days, many people in technology consider Microsoft an embarrassing dinosaur. While you know that it's still around, does it really matter, these days?
You can't deny, however, that Microsoft made a lot of money in the Nineties. They still do.
What's the key to making a lot of money? Have a revenue larger than your costs.
I'm too lazy to look up the actual numbers, but clearly Microsoft had (and still has) a revenue vastly larger than its costs:
Compared to real, historic numbers, this may be exaggerated, but I'm trying to make a general point - not one that hinges on actual profit numbers of Microsoft, Apple, Amazon, Google, or any other tremendously profitable company. I'm also aware that real companies have costs that aren't directly related to software development: Marketing, operations, buildings, sales, etcetera. They also make money in other ways than from their software, mainly from investments of the profits.
The difference between the revenue and the cost is the profit or net value.
If the graph looks like the above, is managing cost the main cause of success? Hardly. The cost is almost a rounding error on the profits.
If so, is the technology or process key to such a company's success? Was it MSF that made Microsoft the wealthiest company in the world? Are two-pizza teams the only explanation of Amazon's success? Is Google the dominant search engine because the source code is organised in a monorepo?
I'd be surprised were that the case. Rather, I think that these companies were at the right place at the right time. While there were search engines before Google, Google was so much better that users quickly migrated. Google was also better at making money than earlier search engines like AltaVista or Yahoo! Likewise, Microsoft made more successful PC operating systems than the competition (which in the early Windows era consisted exclusively of OS/2) and better professional software (word processor, spreadsheet, etcetera). Amazon made a large-scale international web shop before anyone else. Apple made affordable computers with graphical user interfaces before other companies. Later, they introduced a smartphone at the right time.
All of this is simplified. For example, it's not really true that Apple made the first smartphone. When the iPhone was introduced, I already carried a Pocket PC Phone Edition device that could browse the internet, had email, phone, SMS, and so on. There were other precursors even earlier.
I'm not trying to explain away excellence of execution. These companies succeeded for a variety of reasons, including that they were good at what they were doing. Lots of companies, however, are good at what they are doing, and still they fail. Being at the right place at the right time matters. Once in a while, a company finds itself in such favourable circumstances that success is served on a silver platter. While good execution is important, it doesn't explain the magnitude of the success.
Bad execution is likely to eliminate you in the long run, but it doesn't follow logically that good execution guarantees success.
Perhaps the successful companies succeeded because of circumstances, and despite mediocre execution. As usual, you should be wary not to mistake correlation for causation.
Legacy code #
You should be sceptical of adopting processes or technology just because a Big Tech company uses it. Still, if that was all I had in mind, I could probably had said that shorter. I have another point to make.
I often encounter resistance to ideas about better software development on the grounds that the status quo is good enough. Put bluntly,
""legacy," [...] is condescending-engineer-speak for "actually makes money.""
To be clear, I have nothing against the author or the cited article, which discusses something (right-sizing VMs) that I know nothing about. The phrase, or variations thereof, however, is such a fit meme that it spreads. It strongly indicates that people who discuss code quality are wankers, while 'real programmers' produce code that makes money. I consider that a false dichotomy.
Most software organisations aren't in the fortunate situation that revenues are orders of magnitude greater than costs. Most software organisations can make a decent profit if they find a market and execute on a good idea. Perhaps the revenue starts at 'only' double the cost.
If you can consistently make the double of your costs, you'll be in business for a long time. As the above line chart indicates, however, is that if the costs rise faster than the revenue, you'll eventually hit a point when you start losing money.
The Big Tech companies aren't likely to run into that situation because their profit margins are so great, but normal companies are very much at risk.
The area between the revenue and the cost represents the profit. Thus, looking back, it may be true that a software system has been making money. This doesn't mean, however, that it will keep making money.
In the above chart, the cost eventually exceeds the revenue. If this cost is mainly driven by rising software development costs, then the company is in deep trouble.
I've worked with such a company. When I started with it, it was a thriving company with many employees, most of them developers or IT professionals. In the previous decade, it had turned a nice profit every year.
This all started to change around the time that I arrived. (I will, again, remind the reader that correlation does not imply causation.) One reason I was engaged was that the developers were stuck. Due to external market pressures they had to deliver a tremendous amount of new features, and they were stuck in analysis paralysis.
I helped them get unstuck, but as we started working on the new features, we discovered the size of the mess of the legacy code base.
I recall a conversation I later had with the CEO. He told me, after having discussed the situation with several key people: "I knew that we had a legacy code base... but I didn't know it was this bad!"
Revenue remained constant, but costs kept rising. Today, the company is no longer around.
This was a 100% digital service company. All revenue was ultimately based on software. The business idea was good, but the company couldn't keep up with competitors. As far as I can tell, it was undone by its legacy code base.
Conclusion #
Software should provide some kind of value. Usually profits, but sometimes savings, and occasionally wider concerns are in scope. It's reasonable and professional to consider value as you produce software. You should, however, be aware of a too myopic focus on immediate and past value.
Finding safety in past value is indulging in complacency. Legacy software can make money from day one, but that doesn't mean that it'll keep making money. The main problem with legacy code is that costs keep rising. When non-technical business stakeholders start to notice this, it may be too late.
The is one of many reasons I believe that we, software developers, have a responsibility to combat the mess. I don't think there's anything condescending about that attitude.
Refactoring the TCP State pattern example to pure functions
A C# example.
This article is one of the examples that I promised in the earlier article The State pattern and the State monad. That article examines the relationship between the State design pattern and the State monad. That article is deliberately abstract, so one or more examples are in order.
In this article, I show you how to start with the example from Design Patterns and refactor it to an immutable solution using pure functions.
The code shown here is available on GitHub.
TCP connection #
The example is a class that handles TCP connections. The book's example is in C++, while I'll show my C# interpretation.
A TCP connection can be in one of several states, so the TcpConnection class keeps an instance of the polymorphic TcpState, which implements the state and transitions between them.
TcpConnection plays the role of the State pattern's Context, and TcpState of the State.
public class TcpConnection { public TcpState State { get; internal set; } public TcpConnection() { State = TcpClosed.Instance; } public void ActiveOpen() { State.ActiveOpen(this); } public void PassiveOpen() { State.PassiveOpen(this); } // More members that delegate to State follows...
The TcpConnection class' methods delegate to a corresponding method on TcpState, passing itself an argument. This gives the TcpState implementation an opportunity to change the TcpConnection's State property, which has an internal setter.
State #
This is the TcpState class:
public class TcpState { public virtual void Transmit(TcpConnection connection, TcpOctetStream stream) { } public virtual void ActiveOpen(TcpConnection connection) { } public virtual void PassiveOpen(TcpConnection connection) { } public virtual void Close(TcpConnection connection) { } public virtual void Synchronize(TcpConnection connection) { } public virtual void Acknowledge(TcpConnection connection) { } public virtual void Send(TcpConnection connection) { } }
I don't consider this entirely idiomatic C# code, but it seems closer to the book's C++ example. (It's been a couple of decades since I wrote C++, so I could be mistaken.) It doesn't matter in practice, but instead of a concrete class with no-op virtual methods, I would usually define an interface. I'll do that in the next example article.
The methods have the same names as the methods on TcpConnection, but the signatures are different. All the TcpState methods take a TcpConnection parameter, whereas the TcpConnection methods take no arguments.
While the TcpState methods don't do anything, various classes can inherit from the class and override some or all of them.
Connection closed #
The book shows implementations of three classes that inherit from TcpState, starting with TcpClosed. Here's my translation to C#:
public class TcpClosed : TcpState { public static TcpState Instance = new TcpClosed(); private TcpClosed() { } public override void ActiveOpen(TcpConnection connection) { // Send SYN, receive SYN, Ack, etc. connection.State = TcpEstablished.Instance; } public override void PassiveOpen(TcpConnection connection) { connection.State = TcpListen.Instance; } }
This implementation overrides ActiveOpen and PassiveOpen. In both cases, after performing some work, they change connection.State.
"
TCPStatesubclasses maintain no local state, so they can be shared, and only one instance of each is required. The unique instance ofTCPStatesubclass is obtained by the staticInstanceoperation. [...]"This make each
TCPStatesubclass a Singleton [...]."
I've maintained that property of each subclass in my C# code, even though it has no impact on the structure of the State pattern.
The other subclasses #
The next subclass, TcpEstablished, is cast in the same mould:
public class TcpEstablished : TcpState { public static TcpState Instance = new TcpEstablished(); private TcpEstablished() { } public override void Close(TcpConnection connection) { // send FIN, receive ACK of FIN connection.State = TcpListen.Instance; } public override void Transmit( TcpConnection connection, TcpOctetStream stream) { connection.ProcessOctet(stream); } }
As is TcpListen:
public class TcpListen : TcpState { public static TcpState Instance = new TcpListen(); private TcpListen() { } public override void Send(TcpConnection connection) { // Send SYN, receive SYN, ACK, etc. connection.State = TcpEstablished.Instance; } }
I admit that I find these examples a bit anaemic, since there's really no logic going on. None of the overrides change state conditionally, which would be possible and make the examples a little more interesting. If you're interested in an example where this happens, see my article Tennis kata using the State pattern.
Refactor to pure functions #
There's only one obvious source of impurity in the example: The literal State mutation of TcpConnection:
public TcpState State { get; internal set; }
While client code can't set the State property, subclasses can, and they do. After all, it's how the State pattern works.
It's quite a stretch to claim that if we can only get rid of that property setter then all else will be pure. After all, who knows what all those comments actually imply:
// Send SYN, receive SYN, ACK, etc.
To be honest, we must imagine that I/O takes place here. This means that even though it's possible to refactor away from mutating the State property, these implementations are not really going to be pure functions.
I could try to imagine what that SYN and ACK would look like, but it would be unfounded and hypothetical. I'm not going to do that here. Instead, that's the reason I'm going to publish a second article with a more realistic and complex example. When it comes to the present example, I'm going to proceed with the unreasonable assumption that the comments hide no nondeterministic behaviour or side effects.
As outlined in the article that compares the State pattern and the State monad, you can refactor state mutation to a pure function by instead returning the new state. Usually, you'd have to return a tuple, because you'd also need to return the 'original' return value. Here, however, the 'return type' of all methods is void, so this isn't necessary.
void is isomorphic to unit, so strictly speaking you could refactor to a return type like Tuple<Unit, TcpConnection>, but that is isomorphic to TcpConnection. (If you need to understand why that is, try writing two functions: One that converts a Tuple<Unit, TcpConnection> to a TcpConnection, and another that converts a TcpConnection to a Tuple<Unit, TcpConnection>.)
There's no reason to make things more complicated than they have to be, so I'm going to use the simplest representation: TcpConnection. Thus, you can get rid of the State mutation by instead returning a new TcpConnection from all methods:
public class TcpConnection { public TcpState State { get; } public TcpConnection() { State = TcpClosed.Instance; } private TcpConnection(TcpState state) { State = state; } public TcpConnection ActiveOpen() { return new TcpConnection(State.ActiveOpen(this)); } public TcpConnection PassiveOpen() { return new TcpConnection(State.PassiveOpen(this)); } // More members that delegate to State follows...
The State property no longer has a setter; there's only a public getter. In order to 'change' the state, code must return a new TcpConnection object with the new state. To facilitate that, you'll need to add a constructor overload that takes the new state as an input. Here I made it private, but making it more accessible is not prohibited.
This implies, however, that the TcpState methods also return values instead of mutating state. The base class now looks like this:
public class TcpState { public virtual TcpState Transmit(TcpConnection connection, TcpOctetStream stream) { return this; } public virtual TcpState ActiveOpen(TcpConnection connection) { return this; } public virtual TcpState PassiveOpen(TcpConnection connection) { return this; } // And so on...
Again, all the methods previously 'returned' void, so while, according to the State monad, you should strictly speaking return Tuple<Unit, TcpState>, this simplifies to TcpState.
Individual subclasses now do their work and return other TcpState implementations. I'm not going to tire you with all the example subclasses, so here's just TcpEstablished:
public class TcpEstablished : TcpState { public static TcpState Instance = new TcpEstablished(); private TcpEstablished() { } public override TcpState Close(TcpConnection connection) { // send FIN, receive ACK of FIN return TcpListen.Instance; } public override TcpState Transmit( TcpConnection connection, TcpOctetStream stream) { TcpConnection newConnection = connection.ProcessOctet(stream); return newConnection.State; } }
The trickiest implementation is Transmit, since ProcessOctet returns a TcpConnection while the Transmit method has to return a TcpState. Fortunately, the Transmit method can achieve that goal by returning newConnection.State. It feels a bit roundabout, but highlights a point I made in the previous article: The TcpConnection and TcpState classes are isomorphic - or, they would be if we made the TcpConnection constructor overload public. Thus, the TcpConnection class is redundant and might be deleted.
Conclusion #
This article shows how to refactor the TCP connection sample code from Design Patterns to pure functions.
If it feels as though something's missing there's a good reason for that. The example, as given, is degenerate because all methods 'return' void, and we don't really know what the actual implementation code (all that Send SYN, receive SYN, ACK, etc.) looks like. This means that we actually don't have to make use of the State monad, because we can get away with endomorphisms. All methods on TcpConnection are really functions that take TcpConnection as input (the instance itself) and return TcpConnection. If you want to see a more realistic example showcasing that perspective, see my article From State tennis to endomorphism.
Even though the example is degenerate, I wanted to show it because otherwise you might wonder how the book's example code fares when exposed to the State monad. To be clear, because of the nature of the example, the State monad never becomes necessary. Thus, we need a second example.
Next: Refactoring a saga from the State pattern to the State monad.
When to refactor
FAQ: How do I convince my manager to let me refactor?
This question frequently comes up. Developers want to refactor, but are under the impression that managers or other stakeholders will not let them.
Sometimes people ask me how to convince their managers to get permission to refactor. I can't answer that. I don't know how to convince other people. That's not my métier.
I also believe that professional programmers should make their own decisions. You don't ask permission to add three lines to a file, or create a new class. Why do you feel that you have to ask permission to refactor?
Does refactoring take time? #
In Code That Fits in Your Head I tell the following story:
"I once led an effort to refactor towards deeper insight. My colleague and I had identified that the key to implementing a new feature would require changing a fundamental class in our code base.
"While such an insight rarely arrives at an opportune time, we wanted to make the change, and our manager allowed it.
"A week later, our code still didn’t compile.
"I’d hoped that I could make the change to the class in question and then lean on the compiler to identify the call sites that needed modification. The problem was that there was an abundance of compilation errors, and fixing them wasn’t a simple question of search-and-replace.
"My manager finally took me aside to let me know that he wasn’t satisfied with the situation. I could only concur.
"After a mild dressing down, he allowed me to continue the work, and a few more days of heroic effort saw the work completed.
"That’s a failure I don’t intend to repeat."
There's a couple of points to this story. Yes, I did ask for permission before refactoring. I expected the process to take time, and I felt that making such a choice of prioritisation should involve my manager. While this manager trusted me, I felt a moral obligation to be transparent about the work I was doing. I didn't consider it professional to take a week out of the calendar and work on one thing while the rest of the organisation was expecting me to be working on something else.
So I can understand why developers feel that they have to ask permission to refactor. After all, refactoring takes time... Doesn't it?
Small steps #
This may unearth the underlying assumption that prevents developers from refactoring: The notion that refactoring takes time.
As I wrote in Code That Fits in Your Head, that was a failure I didn't intend to repeat. I've never again asked permission to refactor, because I've never since allowed myself to be in a situation where refactoring would take significant time.
The reason I tell the story in the book is that I use it to motivate using the Strangler pattern at the code level. The book proceeds to show an example of that.
Migrating code to a new API by allowing the old and the new to coexist for a while is only one of many techniques for taking smaller steps. Another is the use of feature flags, a technique that I also show in the book. Martin Fowler's Refactoring is literally an entire book about how to improve code bases in small, controlled steps.
Follow the red-green-refactor checklist and commit after each green and refactor step. Move in small steps and use Git tactically.
I'm beginning to realise, though, that moving in small steps is a skill that must be explicitly learned. This may seem obvious once posited, but it may also be helpful to explicitly state it.
Whenever I've had a chance to talk to other software professionals and thought leaders, they agree. As far as I can tell, universities and coding boot camps don't teach this skill, and if (like me) you're autodidact, you probably haven't learned it either. After all, few people insist that this is an important skill. It may, however, be one of the most important programming skills you can learn.
Make it work, then make it right #
When should you refactor? As the boy scout rule suggests: All the time.
You can, specifically, do it after implementing a new feature. As Kent Beck perhaps said or wrote: Make it work, then make it right.
How long does it take to make it right?
Perhaps you think that it takes as much time as it does to make it work.

Perhaps you think that making it right takes even more time.

If this is how much time making the code right takes, I can understand why you feel that you need to ask your manager. That's what I did, those many years ago. But what if the proportions are more like this?
Do you still feel that you need to ask for permission to refactor?
Writing code so that the team can keep a sustainable pace is your job. It's not something you should have to ask for permission to do.
"Any fool can write code that a computer can understand. Good programmers write code that humans can understand."
Making the code right is not always a huge endeavour. It can be, if you've already made a mess of it, but if it's in good condition, keeping it that way doesn't have to take much extra effort. It's part of the ongoing design process that programming is.
How do you know what right is? Doesn't this make-it-work-make-it-right mentality lead to speculative generality?
No-one expects you to be able to predict the future, so don't try. Making it right means making the code good in the current context. Use good names, remove duplication, get rid of code smells, keep methods small and complexity low. Refactor if you exceed a threshold.
Make code easy to change #
The purpose of keeping code in a good condition is to make future changes as easy as possible. If you can't predict the future, however, then how do you know how to factor the code?
Another Kent Beck aphorism suggests a tactic:
"for each desired change, make the change easy (warning: this may be hard), then make the easy change"
In other words, when you know what you need to accomplish, first refactor the code so that it becomes easier to achieve the goal, and only then write the code to do that.

Should you ask permission to refactor in such a case? Only if you sincerely believe that you can complete the entire task significantly faster without first improving the code. How likely is that? If the code base is already a mess, how easy is it to make changes? Not easy, and granted: That will also be true for refactoring. The difference between first refactoring and not refactoring, however, is that if you refactor, you leave the code in a better state. If you don't, you leave it in a worse state.
These decisions compound.
But what if, as Kent Beck implies, refactoring is hard? Then the situation might look like this:

Should you ask for permission to refactor? I don't think so. While refactoring in this diagram is most of the work, it makes the change easy. Thus, once you're done refactoring, you make the easy change. The total amount of time this takes may turn out to be quicker than if you hadn't refactored (compare this figure to the previous figure: they're to scale). You also leave the code base in a better state so that future changes may be easier.
Conclusion #
There are lots of opportunities for refactoring. Every time you see something that could be improved, why not improve it? The fact that you're already looking at a piece of code suggests that it's somehow relevant to your current task. If it takes ten, fifteen minutes to improve it, why not do it? What if it takes an hour?
Most people think nothing of spending hours in meetings without asking their managers. If this is true, you can also decide to use a couple of hours improving code. They're likely as well spent as the meeting hours.
The key, however, is to be able to perform opportunistic refactoring. You can't do that if you can only move in day-long iterations; if hours, or days, go by when you can't compile, or when most tests fail.
On the other hand, if you're able to incrementally improve the code base in one-minute, or fifteen-minute, steps, then you can improve the code base every time an occasion arrives.
This is a skill that you need to learn. You're not born with the ability to improve in small steps. You'll have to practice - for example by doing katas. One customer of mine told me that they found Kent Beck's TCR a great way to teach that skill.
You can refactor in small steps. It's part of software engineering. Usually, you don't need to ask for permission.
Comments
I've always had a problem with the notion of "red, green, refactor" and "first get it working, then make it right." I think the order is completely wrong.
As an explanation, I refer you to the first chapter of the first edition of Martin Fowler's Refactoring book. In that chapter is an example of a working system and we are presented with a change request.
In the example, the first thing that Fowler points out and does is the refactoring. And one of the highlighted ideas in the chapter says:
When you find you have to add a feature to a program, and the program's code is not structured in a convenient way to add the feature, first refactor the program to make it easy to add the feature, then add the feature.
In other words, the refactoring comes first. You refactor as part of adding the feature, not as a separate thing that is done after you have working code. It may not trip off the tongue as nicely, but the saying should be "refactor, red, green."
Once you have working code, you are done, and when you are estimating the time it will take to add the feature, you include the refactoring time. Lastly, you never refactor "just because," you refactor in order to make a new feature easy to add.
This mode of working makes much more sense to me. I feel that refactoring with no clear goal in mind ("improve the design" is not a clear goal) just leads to an over-designed/unnecessarily complex system. What do you think of this idea?
Daniel, thank you for writing. You make some good points.
The red-green-refactor cycle is useful as a feedback cycle for new development work. It's not the only way to work. Particularly, as you point out, when you have existing code, first refactoring and then adding new code is a useful order.
Typically, though, when you're adding a new feature, you can rarely implement a new feature only by refactoring existing code. Normally you also need to add some new code. I still find the red-green-refactor cycle useful for that kind of work. I don't view it as an either-or proposition, but rather as a both-this-and-that way of working.
"you never refactor "just because," you refactor in order to make a new feature easy to add."
Never say never. I don't agree with that point of view. There are more than one reason for refactoring, and making room for a new feature is certainly one of them. This does not, however, rule out other reasons. I can easily think of a handful of other reasons that I consider warranted, but I don't want to derail the discussion by listing all of them. The list is not going to be complete anyway. I'll just outline one:
Sometimes, you read existing code because you need to understand what's going on. If the code is badly structured, it can take significant time and effort to reach such understanding. If, at that point you can see a simpler way to achieve the same behaviour, why not refactor the code? In that way, you make it easier for future readers of the code to understand what's going on. If you've already spent (wasted) significant time understanding something, why let other readers suffer and waste time if you can simplify the code?
This is essentially the boy scout rule, but as I claimed, there are other reasons to refactor as well.
Finally, thank you for the quote from Refactoring. I've usually been using this Kent Beck quote:
"for each desired change, make the change easy (warning: this may be hard), then make the easy change"
but that's from 2012, and Refactoring is from 1999. It's such a Kent Beck thing to say, though, and Kent is a coauthor of Refactoring, so who knows who came up with that. I'm happy to know of the earlier quote, though.
I don't view it as an either-or proposition, but rather as a both-this-and-that way of working.
I think it is worth elaborating on this. I think am correct in saying that Mark believes that type-driven development and test-driven development are a both-this-and-that way of working instead of an either-or way of working. He did exactly this in his Pluralsight course titled Type-Driven Development with F# by first obtaining an implementation using type-driven development and then deleting his implementation but keeping his types and obtaining a second implementation using test-driven development.
When implementing a new feature, it is important to as quickly as possible derisk by discovering any surprises (aka unknown unknowns) and analyze all challenges (aka known unknowns). The reason for this is to make sure the intended approach is feasible. During this phase of work, we are in the "green" step of test-driven development. Anything goes. There are no rules. The code can horribly ugly or unmaintainable. Just get the failing test to pass.
After the test passes, you have proved that the approach is sound. Now you need to share your solution with others. Here is where refactoring first occurs. Just like in Mark's course, I often find it helpful to start over. Now that I know where I am going, I can first refactor the code to make the functional change, which I know will make the test pass. In this way, I know that all my refactors have a clear goal.
You refactor as part of adding the feature, not as a separate thing that is done after you have working code.
I agree that refactoring should be done as part of the feature, but I disagree that it should (always) be done before you have working code. It is often done after you have working code.
Once you have working code, you are done, and when you are estimating the time it will take to add the feature, you include the refactoring time.
I agree that estimating should include the refactoring time, but I disagree that you are done when you have working code. When you have working code, you are approximately halfway done. Your code is currently optimized for writing. You still need to optimize it for reading.

Comments
I want my assertion type to be both applicative and monadic. So does Paul Loath, the creator of Language Ext, which is most clearly seen via this Validation test code. So does Alexis King (as you pointed out to me) in her Haskell Validation package, which violiates Hakell's monad type class, and which she defends here.
When I want (or typically need) short-circuiting behavior, then I use the type's monadic API. When I want "error-collecting behavior", then I use the type's applicative API.
The best syntactic support for applicative functors in C# that I have seen is in Langauge Ext. A comment explains in that same Validation test how it works, and the line after the comment shows it in action.
Tyson, thank you for writing. Whether or not you want to enable monadic short-circuiting for assertions or validations depends, I think, on 'developer ergonomics'. It's a trade-off mainly between ease and simplicity as outlined by Rich Hickey. Enabling a monadic API for something that isn't naturally monadic does indeed provide ease of use, in that the compositional capabilities of a monad are readily 'at hand'.
If you don't have that capability you'll have to map back and forth between, say,
ValidationandEither(if using the validation package). This is tedious, but explicit.Making validation or assertions monadic makes it easier to compose nested values, but also (in my experience) makes it easier to make mistakes, in the sense that you (or a colleague) may think that the behaviour is error-collecting, whereas in reality it's short-circuiting.
In the end, the trade-off may reduce to how much you trust yourself (and co-workers) to steer clear of mistakes, and how important it is to avoid errors. In this case, how important is it to collect the errors, rather than short-circuiting?
You can choose one alternative or the other by weighing such concerns.