ploeh blog danish software design
The case of the unbalanced brackets
A code mystery.
One of my clients was kind enough to let me look at some of their legacy code. As I was struggling to understand how it worked, I encountered something that looked like this:
ApplyDueAmountG89.Calculate(postState.PartialMebershipsBAT.Where( d => (d.Data.Choicetype == GarplyChoicetype.AtoC || retirablePartialMembershipNr.Contains(d.Data.PartialMembershipNr)).ToList(), ApplyDueAmountG89.Situation.Depreciation, ApplyDueAmountG89.RecordType.Primo);
For the record, this isn't the actual code that my client gave me. I wouldn't post someone else's code without their permission. It is, however, a faithful imitation of the original code. What's wrong with it?
I'll wait.
Brackets #
Count the brackets. There's a missing closing bracket.
Yet, the code compiles. How?
Legacy code isn't humane code. There's a multitude of ways in which code can be obscure. This article describes one of them.
When brackets are nested and far apart, it's hard for the brain to parse and balance them. Yet, on closer inspection the brackets seem unbalanced.
Show whitespace #
Ever since I started programming in F#, I've turned on the Visual Studio feature that shows whitespace. F# does, after all, use significant whitespace (AKA the Off-side rule), and it helps to be able to detect if a tab character has slipped in among the spaces.
Visual Studio shows whitespace with pale blue dots and arrows. When that feature is turned on (Ctrl + e, s), the above code example looks different:
ApplyDueAmountG89.Calculate(postState.PartialMebershipsBAT.Where( ····d·=>·(d.Data.Choicetype·==·GarplyChoicetype.AtoC·||··············································· ············retirablePartialMembershipNr.Contains(d.Data.PartialMembershipNr)).ToList(), ············ApplyDueAmountG89.Situation.Depreciation, ············ApplyDueAmountG89.RecordType.Primo);
Notice the space characters that seem to run off to the right of the || operator. What's at the end of those spaces?
Yes, you guessed it: another Boolean expression, including the missing closing bracket:
d.Data.Choicetype == GarplyChoicetype.BtoC) &&
If you delete all those redundant spaces, this is the actual code:
ApplyDueAmountG89.Calculate(postState.PartialMebershipsBAT.Where( d => (d.Data.Choicetype == GarplyChoicetype.AtoC || d.Data.Choicetype == GarplyChoicetype.BtoC) && retirablePartialMembershipNr.Contains(d.Data.PartialMembershipNr)).ToList(), ApplyDueAmountG89.Situation.Depreciation, ApplyDueAmountG89.RecordType.Primo);
Imagine troubleshooting code like that, and not realising that there's another Boolean expression so far right that even a large screen doesn't show it. In the actual legacy code where I found this example, the extra Boolean expression started at column 209.
Conclusion #
Hiding significant code so far right that it's effectively invisible seems positively evil, but I don't think anyone did it deliberately. Rather, my guess is that someone performed a search-and-replace through the code base, and that this automatic change somehow removed a newline character.
In any case, keeping an eye on the line width of code could prevent something like this from happening. Stay within 80 characters.
Semigroup resonance FizzBuzz
An alternative solution to the FizzBuzz kata.
A common solution to the FizzBuzz kata is to write a loop from 1 to 100 and perform a modulo check for each number. Functional programming languages like Haskell don't have loops, so instead you'd typically solve the kata like this:
isAMultipleOf :: Integral a => a -> a -> Bool isAMultipleOf i multiplier = i `mod` multiplier == 0 convert :: (Integral a, Show a) => a -> String convert i | i `isAMultipleOf` 3 && i `isAMultipleOf` 5 = "FizzBuzz" convert i | i `isAMultipleOf` 3 = "Fizz" convert i | i `isAMultipleOf` 5 = "Buzz" convert i = show i main :: IO () main = mapM_ putStrLn $ convert <$> [1..100]
There's more than one way to skin this cat. In this article, I'll demonstrate one based on Semigroup resonance.
Fizz stream #
The fundamental idea is to use infinite streams that repeat at different intervals. That idea isn't mine, but I've never seen it done without resorting to some sort of Boolean conditional or pattern matching.
You start with a finite sequence of values that represent the pulse of Fizz values:
[Nothing, Nothing, Just "Fizz"]
If you repeat that sequence indefinitely, you now have a pulse of Fizz values:
fizzes :: [Maybe String] fizzes = cycle [Nothing, Nothing, Just "Fizz"]
This stream of values is one-based, since the first two entries are Nothing, and only every third is Just "Fizz":
*FizzBuzz> take 9 fizzes [Nothing, Nothing, Just "Fizz", Nothing, Nothing, Just "Fizz", Nothing, Nothing, Just "Fizz"]
If you're wondering why I chose a stream of Maybe String instead of just a stream of String values, I'll explain that now.
Buzz stream #
You can define an equivalent infinite stream of Buzz values:
buzzes :: [Maybe String] buzzes = cycle [Nothing, Nothing, Nothing, Nothing, Just "Buzz"]
The idea is the same, but the rhythm is different:
*FizzBuzz> take 10 buzzes [Nothing, Nothing, Nothing, Nothing, Just "Buzz", Nothing, Nothing, Nothing, Nothing, Just "Buzz"]
Why not simply generate a stream of String values, like the following?
*FizzBuzz> take 10 $ cycle ["", "", "", "", "Buzz"] ["", "", "", "", "Buzz", "", "", "", "", "Buzz"]
At first glance this looks simpler, but it makes it harder to merge the stream of Fizz and Buzz values with actual numbers. Distinguishing between Just and Nothing values enables you to use the Maybe catamorphism.
Resonance #
You can now zip the fizzes with the buzzes:
fizzBuzzes :: [Maybe String] fizzBuzzes = zipWith (<>) fizzes buzzes
You combine the values by monoidal composition. Any Maybe over a Semigroup itself gives rise to a Monoid, and since String forms a Monoid (and therefore also a Semigroup) over concatenation, you can zip the two streams using the <> operator.
*FizzBuzz> take 20 fizzBuzzes [Nothing, Nothing, Just "Fizz", Nothing, Just "Buzz", Just "Fizz", Nothing, Nothing, Just "Fizz", Just "Buzz", Nothing, Just "Fizz", Nothing, Nothing, Just "FizzBuzz", Nothing, Nothing, Just "Fizz", Nothing, Just "Buzz"]
Notice how the stream of fizzes enters into a resonance pattern with the stream of buzzes. Every fifteenth element the values Fizz and Buzz amplify each other and become FizzBuzz.
Numbers #
While you have an infinite stream of fizzBuzzes, you also need a list of numbers. That's easy:
numbers :: [String] numbers = show <$> [1..100]
You just use a list comprehension and map each number to its String representation using show:
*FizzBuzz> take 18 numbers ["1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11", "12", "13", "14", "15", "16", "17", "18"]
Now you just need to figure out how to merge the fizzBuzzes with the numbers.
Zip with catamorphism #
While you can trivially zip fizzBuzzes with numbers, it doesn't solve the problem of which value to pick:
*FizzBuzz> take 5 $ zip numbers fizzBuzzes
[("1", Nothing), ("2", Nothing), ("3", Just "Fizz"), ("4", Nothing), ("5", Just "Buzz")]
You want to use the second element of each tuple when there's a value, and only use the first element (the number) when the second element is Nothing.
That's easily done with fromMaybe (you'll need to import Data.Maybe for that):
*FizzBuzz> fromMaybe "2" Nothing "2" *FizzBuzz> fromMaybe "3" $ Just "Fizz" "Fizz"
That's just what you need, so zip numbers with fizzBuzzes using fromMaybe:
elements :: [String] elements = zipWith fromMaybe numbers fizzBuzzes
These elements is a list of the values the kata instructs you to produce:
*FizzBuzz> take 14 elements ["1", "2", "Fizz", "4", "Buzz", "Fizz", "7", "8", "Fizz", "Buzz", "11", "Fizz", "13", "14"]
fromMaybe is a specialisation of the Maybe catamorphism. I always find it interesting when I can solve a problem with catamorphisms and monoids, because it shows that perhaps, there's some value in knowing universal abstractions.
From 1 to 100 #
The kata instructions are to write a program that prints the numbers from 1 to 100, according to the special rules. You can use mapM_ putStrLn for that:
main :: IO () main = mapM_ putStrLn elements
When you execute the main function, you get the desired output:
1 2 Fizz 4 Buzz Fizz 7 8 Fizz Buzz 11 Fizz 13 14 FizzBuzz 16
... and so on.
Golf #
Haskell golfers may complain that the above code is unnecessarily verbose. I disagree, but you can definitely write the entire kata as a 'one-liner' if you want to:
main :: IO () main = mapM_ putStrLn $ zipWith fromMaybe (show <$> [1..100]) $ zipWith (<>) (cycle [Nothing, Nothing, Just "Fizz"]) (cycle [Nothing, Nothing, Nothing, Nothing, Just "Buzz"])
I've just mechanically in-lined all the values like fizzes, buzzes, etc. and formatted the code so that it fits comfortable in a 80x24 box. Apart from that, I don't think that this is an improvement, but it has the same behaviour as the above, more verbose alternative.
Conclusion #
You can implement the FizzBuzz kata using the fundamental concepts catamorphism, semigroup and monoid. No if-then-else instructions or pattern matching is required. Instead, you use the string concatenation semigroup to enable resonance between two pulses, and the maybe catamorphism to combine with the list of numbers.
The case of the mysterious curly bracket
The story of a curly bracket that I thought was redundant. Not so.
One of my clients was kind enough to show me some of their legacy code. As I was struggling to understand how it worked, I encountered something like this:
// A lot of code has come before this. This is really on line 665, column 29. foreach (BARLifeScheme_BAR scheme in postPartialMembership.SchemesFilterObsolete(BARCompany.ONETIMESUM, false)) { var schemeCalculated = (BARLifeSchemeCalculated_BAR)scheme.SchemeCalculatedObsolete[basis.Data.Basis1order]; { decimal hfcFactor; if (postState.OverallFuturerule == BAROverallFuturerule.Standard) { var bonusKey = new BonusKey(postState.PNr()); hfcFactor = 1M - CostFactory.Instance() .CostProvider(postState.Data.FrameContractNr, postState.StateDate) .GetAdministrationpercentageContribution(bonusKey, basis.Data.Basis1order) / 100M; } // Much more code comes after this... } // ...and after this... }
For the record, this isn't the actual code that my client gave me. I wouldn't post someone else's code without their permission. It is, however, a faithful imitation of the original code.
The actual code started at line 665 and further to the right. It was part of a larger block of code with if statements within foreach loops within if statements within foreach loops, and so on. The foreach keyword actually appeared at column 29. The entire file was 1708 lines long.
The code has numerous smells, but here I'll focus on a single oddity.
Inexplicable bracket #
Notice the curly bracket on the line before hfcFactor. Why is it there?
Take a moment and see if you can guess.
It doesn't seem to be required. It just surrounds a block of code, but it belongs to none of the usual language constructs that would normally call for the use of curly brackets. There's no if, foreach, using, or try before it.
Residue #
I formed a theory as to why those brackets where in place. I thought that it might be the residue of an if statement that was no longer there; that, perhaps, once the code had looked like this:
if (something < somethingElse) { decimal hfcFactor;
Later, a developer had discovered that the code in that block should always be executed, and had removed the if statement without removing the curly brackets.
That was my theory, but then I noticed that this structure appeared frequently throughout the code. Mysterious curly brackets were common, sometimes even nesting each other.
This idiom appeared too often that it looked like the legacy from earlier epochs. It looked deliberate.
The real reason #
When I had the opportunity, I asked one of the developers.
He smiled sheepishly when he told me that those curly brackets were there to introduce a variable scope. The curly brackets protected variables within them from colliding with other variables elsewhere in the 744-line method.
Those scopes enabled programmers to declare variables with names that would otherwise collide with other variables. They even enabled developers to declare a variable with the same name, but a different type.
I was appalled.
Legacy #
I didn't write this article to point fingers. I don't think that professional software developers deliberately decide to write obscure code.
Code becomes obscure over time. It's a slow, unyielding process. As Brian Foote and Joseph Yoder wrote in The Selfish Class (here quoted from Pattern Languages of Program Design 3, p. 461):
That's a disturbing thought. It suggests that 'good' code is unstable. I suspect that code tends to rot beyond comprehension. It's death by a thousand cuts. It's not any single edit that produces legacy code. It's the glacial, inexorable slide towards increasingly complicated code."Will highly comprehensible code, by virtue of being easy to modify, inevitably be supplanted by increasingly less elegant code until some equilibrium is achieved between comprehensibility and fragility?"
Conclusion #
Methods may grow to such sizes that variables collide. The solution isn't to add artificial variable scopes. The solution is to extract helper methods. Keep methods small.
Zone of Ceremony
Static typing doesn't have to involve much ceremony.
I seem to get involved in long and passionate debates about static versus dynamic typing on a regular basis. I find myself clearly on the side of static typing, but this article isn't about the virtues of static versus dynamic typing. The purpose is to correct a common misconception about statically typed languages.
Ceremony #
People who favour dynamically typed languages over statically typed languages often emphasise that they find the lack of ceremony productive. That seems reasonable; only, it's a false dichotomy.
"Ceremony is what you have to do before you get to do what you really want to do."
Dynamically typed languages do seem to be light on ceremony, but you can't infer from that that statically typed languages have to require lots of ceremony. Unfortunately, all mainstream statically typed languages belong to the same family, and they do involve ceremony. I think that people extrapolate from what they know; they falsely conclude that all statically typed languages must come with the overhead of ceremony.
It looks to me more as though there's an unfortunate Zone of Ceremony:
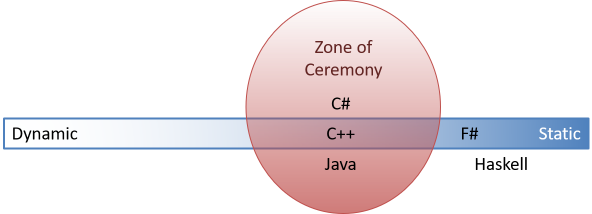
Such a diagram can never be anything but a simplification, but I hope that it's illuminating. C++, Java, and C# are all languages that involve ceremony. To the right of them are what we could term the trans-ceremonial languages. These include F# and Haskell.
In the following, I'll show some code examples in various languages. I'll discuss ceremony according to the above definition. The discussion focuses on the amount of preparatory work one has to do, such as creating a new file, declaring a new class, and declaring types. The discussion is not about the implementation code. For that reason, I've removed colouring from the implementation code, and emphasised the code that I consider ceremonial.
Low ceremony of JavaScript #
Imagine that you're given a list of numbers, as well as a quantity. The quantity is a number to be consumed. You must remove elements from the left until you've consumed at least that quantity. Then return the rest of the list.
> consume ([1,2,3], 1); [ 2, 3 ] > consume ([1,2,3], 2); [ 3 ] > consume ([1,2,3], 3); [ 3 ] > consume ([1,2,3], 4); []
The first example consumes only the leading 1, while both the second and the third example consumes both 1 and 2 because the sum of those values is 3, and the requested quantity is 2 and 3, respectively. The fourth example consumes all elements because the requested quantity is 4, and you need both 1, 2, and 3 before the sum is large enough. You have to pick strictly from the left, so you can't decide to just take the elements 1 and 3.
If you're wondering why such a function would be useful, here's my motivating example.
In JavaScript, you could implement the consume function like this:
var consume = function (source, quantity) { if (!source) { return []; } var accumulator = 0; var result = []; for (var i = 0; i < source.length; i++) { var x = source[i]; if (quantity <= accumulator) result.push(x); accumulator += x; } return result; }
I'm a terrible JavaScript programmer, so I'm sure that it could have been done more elegantly, but as far as I can tell, it gets the job done. I wrote some tests, and I have 17 passing test cases. The point isn't about how you write the function, but how much ceremony is required. In JavaScript you don't need to declare any types. Just name the function and its arguments, and you're ready to write code.
High ceremony of C# #
Contrast the JavaScript example with C#. The same function in C# would look like this:
public static class Enumerable { public static IEnumerable<int> Consume( this IEnumerable<int> source, int quantity) { if (source is null) yield break; var accumulator = 0; foreach (var i in source) { if (quantity <= accumulator) yield return i; accumulator += i; } } }
Here you have to declare the type of each method argument, as well as the return type of the method. You also have to put the method in a class. This may not seem like much overhead, but if you later need to change the types, editing is required. This can affect downstream callers, so simple type changes ripple through code bases.
It gets worse, though. The above Consume method only handles int values. What if you need to call the method with long arrays?
You'd have to add an overload:
public static IEnumerable<long> Consume( this IEnumerable<long> source, long quantity) { if (source is null) yield break; var accumulator = 0L; foreach (var i in source) { if (quantity <= accumulator) yield return i; accumulator += i; } }
Do you need support for short? Add an overload. decimal? Add an overload. byte? Add an overload.
No wonder people used to dynamic languages find this awkward.
Low ceremony of F# #
You can write the same functionality in F#:
let inline consume quantity = let go (acc, xs) x = if quantity <= acc then (acc, Seq.append xs (Seq.singleton x)) else (acc + x, xs) Seq.fold go (LanguagePrimitives.GenericZero, Seq.empty) >> snd
There's no type declaration in sight, but nonetheless the function is statically typed. It has this somewhat complicated type:
quantity: ^a -> (seq< ^b> -> seq< ^b>)
when ( ^a or ^b) : (static member ( + ) : ^a * ^b -> ^a) and
^a : (static member get_Zero : -> ^a) and ^a : comparison
While this looks arcane, it means that it support sequences of any type that comes with a zero value and supports addition and comparison. You can call it with both 32-bit integers, decimals, and so on:
> consume 2 [1;2;3];; val it : seq<int> = seq [3] > consume 2m [1m;2m;3m];; val it : seq<decimal> = seq [3M]
Static typing still means that you can't just call it with any type of value. An expression like consume "foo" [true;false;true] will not compile.
You can explicitly declare types in F# (like you can in C#), but my experience is that if you don't, type changes tend to just propagate throughout your code base. Change a type of a function, and upstream callers generally just 'figure it out'. If you think of functions calling other functions as a graph, you often only have to adjust leaf nodes even when you change the type of something deep in your code base.
Low ceremony of Haskell #
Likewise, you can write the function in Haskell:
consume quantity = reverse . snd . foldl go (0, []) where go (acc, ys) x = if quantity <= acc then (acc, x:ys) else (acc + x, ys)
Again, you don't have to explicitly declare any types. The compiler figures them out. You can ask GHCi about the function's type, and it'll tell you:
> :t consume consume :: (Foldable t, Ord a, Num a) => a -> t a -> [a]
It's more compact than the inferred F# type, but the idea is the same. It'll compile for any Foldable container t and any type a that belongs to the classes of types called Ord and Num. Num supports addition and Ord supports comparison.
There's little ceremony involved with the types in Haskell or F#, yet both languages are statically typed. In fact, their type systems are more powerful than C#'s or Java's. They can express relationships between types that those languages can't.
Summary #
In debates about static versus dynamic typing, contributors often generalise from their experience with C++, Java, or C#. They dislike the amount of ceremony required in these languages, but falsely believe that it means that you can't have static types without ceremony.
The statically typed mainstream languages seem to occupy a Zone of Ceremony.
Static typing without ceremony is possible, as evidenced by languages like F# and Haskell. You could call such languages trans-ceremonial languages. They offer the best of both worlds: compile-time checking and little ceremony.
Put cyclomatic complexity to good use
An actually useful software metric.
In Humane Code I argue that software development suffers from a lack of useful measurements. While I stand by that general assertion, a few code metrics can be useful. Cyclomatic complexity, while no silver bullet, can be put to good use.
Recap #
I think of cyclomatic complexity as a measure of the number of pathways through a piece of code. Even the simplest body of code affords a single pathway, so the minimum cyclomatic complexity is 1. You can easily 'calculate' the cyclomatic complexity of a method for function. You start at one, and then you count how many times if and for occurs. For each of these keywords you find, you increment the number (which started at 1).
The specifics are language-dependent. The idea is to count branching and looping instructions. In C#, for example, you'd also have to include foreach, while, do, and each case in a switch block. In other languages, the keywords to count will differ.
What's the cyclomatic complexity of this TryParse method?
public static bool TryParse(string candidate, out UserNamePassworCredentials? credentials) { credentials = null; var arr = candidate.Split(','); if (arr.Length < 2) return false; credentials = new UserNamePassworCredentials(arr[0], arr[1]); return true; }
The cyclomatic complexity of this method is 2. You start with the number 1 and then increment it every time you find one of the branching keywords. In this case, there's only a single if, so increment 1 to 2. That's it. If you're in doubt, Visual Studio can calculate metrics for you. (It calculates other metrics as well, but I don't find those useful.)
Guide for unit testing #
I find cyclomatic complexity useful because it measures the number of pathways through a method. As such, it indicates the minimum number of test cases you ought to furnish. (Edit July 14, 2023: While this tends to work well in practice, it turns out that it's not strictly true in general. See the article Is cyclomatic complexity really related to branch coverage? and the comments for more details.) This is useful when reviewing code and tests.
Sometimes I'm presented with code that other people wrote. When I look through the production code, I consider its cyclomatic complexity. If, for example, a method has a cyclomatic complexity of 5, I'd expect to find at least five test cases to cover that method.
At other times, I start by reading the tests. The number of test cases gives me a rough indication of what degree of complexity to expect. If I see four distinct tests for the same method, I expect it to have a cyclomatic complexity about 4.
I don't demand 100% coverage. Sometimes, people don't write tests for guard clauses, and I usually accept such omissions. On the other hand, I think that proper decision logic should be covered by tests. If I were to stick unwaveringly to cyclomatic complexity, that would make my reviews more objective, but not necessarily better. I could insist on 100% code coverage, but I don't consider that a good idea.
Presented with the above TryParse method, I'd expect to see at least two unit tests, since the cyclomatic complexity is 2.
The need for more test cases #
Two unit tests aren't enough, though. You could write these two tests:
[Fact] public void TryParseSucceeds() { var couldParse = UserNamePassworCredentials.TryParse("foo,bar", out var actual); Assert.True(couldParse); var expected = new UserNamePassworCredentials("foo", "bar"); Assert.Equal(expected, actual); } [Fact] public void TryParseFails() { var couldParse = UserNamePassworCredentials.TryParse("foo", out var actual); Assert.False(couldParse); Assert.Null(actual); }
Using the Devil's advocate technique, however, this implementation of TryParse passes both tests:
public static bool TryParse(string candidate, out UserNamePassworCredentials? credentials) { credentials = null; if (candidate != "foo,bar") return false; credentials = new UserNamePassworCredentials("foo", "bar"); return true; }
This is clearly not the correct implementation, but it has 100% code coverage. It also still has cyclomatic complexity of 2. The metric suggests a minimum number of tests - not a sufficient number.
More test cases #
It often makes sense to cover each branch with a single parametrised test:
[Theory] [InlineData("foo,bar", "foo", "bar")] [InlineData("baz,qux", "baz", "qux")] [InlineData("ploeh,fnaah", "ploeh", "fnaah")] [InlineData("foo,bar,baz", "foo", "bar")] public void TryParseSucceeds(string candidate, string userName, string password) { var couldParse = UserNamePassworCredentials.TryParse(candidate, out var actual); Assert.True(couldParse); var expected = new UserNamePassworCredentials(userName, password); Assert.Equal(expected, actual); } [Theory] [InlineData("")] [InlineData("foobar")] [InlineData("foo;bar")] [InlineData("foo")] public void TryParseFails(string candidate) { var couldParse = UserNamePassworCredentials.TryParse(candidate, out var actual); Assert.False(couldParse); Assert.Null(actual); }
Is a total of eight test cases the correct number? Cyclomatic complexity can't help you here. You'll have to rely on other heuristics, such as test-driven development, the transformation priority premise, and the Devil's Advocate.
Humane Code #
I also find cyclomatic complexity useful for another reason. I keep an eye on complexity because I care about code maintainability. In my Humane Code video, I discuss the magic number seven, plus or minus two.
When you read code, you essentially run a little emulator in your brain. You have to maintain state in order to interpret the code you look at. Will this conditional evaluate to true or false? Is the code going to exit that loop now? Is that array index out of bounds? You can only follow the code by keeping track of variables' contents, and your brain can keep track of approximately seven things.
Cyclomatic complexity is a measure of pathways - not how many things you need to keep track of. Still, in my experience, there seems to be a useful correlation. Code with high cyclomatic complexity tends to have many moving parts. There's too much to keep track of. With low cyclomatic complexity, on the other hand, the code involves few moving parts.
I use cyclomatic complexity 7 as an approximate maximum for that reason. It's only a rule of thumb, since I'm painfully aware that I'm transplanting experimental psychology to a context where no conclusions can be scientifically drawn. But like the 80/24 rule I find that it works well in practice.
Complexity of a method call #
Consider the above parametrised tests. Some of the test cases provide enough triangulation to defeat the Devil's attempt at hard-coding return values. This explains test values like "foo,bar", "baz,qux", and "ploeh,fnaah", but why did I include the "foo,bar,baz" test case? And why did I include the empty string as one of the test cases for TryParseFails?
When I write tests, I aspire to compose tests that verify the behaviour rather than the implementation of the System Under Test. The desired behaviour, I decided, is that any extra entries in the comma-separated input should be ignored. Likewise, if there's fewer than two entries, parsing should fail. There must be both a user name and a password.
Fortunately, this happens to be how Split already works. If you consider all the behaviour that Split exhibits, it encapsulates moderate complexity. It can split on multiple alternative delimiters, it can throw away empty entries, and so on. What would happen if you inline some of that functionality?
public static bool TryParse(string candidate, out UserNamePassworCredentials? credentials) { credentials = null; var l = new List<string>(); var element = ""; foreach (var c in candidate) { if (c == ',') { l.Add(element); element = ""; } else element += c; } l.Add(element); if (l.Count < 2) return false; credentials = new UserNamePassworCredentials(l[0], l[1]); return true; }
This isn't as sophisticated as the Split method it replaces, but it passes all eight test cases. Why did I do this? To illustrate the following point.
What's the cyclomatic complexity now?
Keep in mind that the externally observable behaviour (as defined by eight test cases) hasn't changed. The cyclomatic complexity, however, has. It's now 4 - double the previous metric.
A method call (like a call to Split) can hide significant cyclomatic complexity. That's a desirable situation. This is the benefit that encapsulation offers: that you don't have to worry about implementation details as long as both caller and callee fulfils the contract.
When you calculate cyclomatic complexity, a method call doesn't increment the complexity, regardless of the degree of complexity that it encapsulates.
Summary #
Cyclomatic complexity is one of the rare programming metrics that I find useful. It measures the number of pathways through a body of code.
You can use it to guide your testing efforts. The number is the minimum number of tests you must write in order to cover all branches. You'll likely need more test cases than that.
You can also use the number as a threshold. I suggest that 7 ought to be the maximum cyclomatic complexity of a method or function. You're welcome to pick another number, but keeping an eye on cyclomatic complexity is useful. It tells you when it's time to refactor a complex method.
Cyclomatic complexity considers only the code that directly implements a method or function. That code can call other code, but what happens behind a method call doesn't impact the metric.
Comments
Do you know of a tool to calculate cyclomatic complexity for F#? It appears that the Visual Studio feature doesn't support it.
Ghillie, thank you for writing. I'm not aware of any such tool.
FWIW, it's not difficult to manually calculate cyclometric complexity for F#, but clearly that doesn't help if you'd like to automate the process.
It might be a fine project for anyone looking for a way to contribute to the F# ecosystem.
Hi, Mark. Thanks for your article. I'd commenting because I'd like to learn more about your thoughts on mutation testing. I ask this because I know you're not the biggest fan of code coverage as a useful metric. I'm not either, or at least I wasnt, until I learned about mutation testing.
My current view is that code coverage is only (mostly) meaningless if you don't have a way of measuring the quality of the tests. Since mutation testing's goal is exactly that (to test the tests, if you will) my opinion is that, if you use a mutation testing tool, then code coverage become really useful and you should try to get to 100%. I've even written a post about this subject.
So, in short: what are your thoughts on mutation testing and how it affects the meaning of code coverage, if at all? Looking forward to read your answer. A whole post on this would be even better!
Thanks!
Carlos, thank you for writing. I'm sympathetic to the idea of mutation testing, but apart from that, I have no opinion of it. I don't think that I ought to have an opinion about something with which I've no experience.
I first heard about mutation testing decades ago, but I've never come across a mutation testing tool for C# (or F#, for that matter). Can you recommend one?
Unfortunately, tooling is indeed one of the main Achilles heels of mutation testing, at least when it comes to .NET.
In the Java world, they have PIT, which is considered state of the art. For C#, I have tried a few tools, with no success. The most promising solution I've found so far, for C#, is Stryker.net, which is a port of the Stryker mutation, designed originally for JavaScript. The C# version is still in its early phases but it's already usable and it looks very promising.
Is mutation testing the automated version of what Mark has called the Devil's Advocate technique?
Tyson, I actually discuss the relationship with mutation testing in that article.
Refactoring registration flow to functional architecture
An example showing a refactoring from F# partial application 'dependency injection' to an impure/pure/impure sandwich.
In a comment to Dependency rejection, I wrote:
"I'd welcome a simplified, but still concrete example where the impure/pure/impure sandwich described here isn't going to be possible."Christer van der Meeren kindly replied with a suggestion.
The code in question relates to validationverification of user accounts. You can read the complete description in the linked comment, but I'll try to summarise it here. I'll then show a refactoring to a functional architecture - specifically, to an impure/pure/impure sandwich.
The code is available on GitHub.
Registration flow #
The system in question uses two-factor authentication with mobile phones. When you sign up for the service, you give your phone number. You then receive an SMS, and must use whatever is in that SMS to prove ownership of the phone number. Christer van der Meeren illustrates the flow like this:
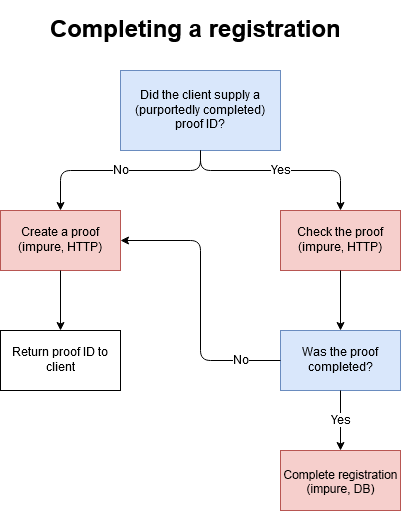
He also supplies sample code:
let completeRegistrationWorkflow (createProof: Mobile -> Async<ProofId>) (verifyProof: Mobile -> ProofId -> Async<bool>) (completeRegistration: Registration -> Async<unit>) (proofId: ProofId option) (registration: Registration) : Async<CompleteRegistrationResult> = async { match proofId with | None -> let! proofId = createProof registration.Mobile return ProofRequired proofId | Some proofId -> let! isValid = verifyProof registration.Mobile proofId if isValid then do! completeRegistration registration return RegistrationCompleted else let! proofId = createProof registration.Mobile return ProofRequired proofId }
While this is F#, it's not functional, since it uses partial application for dependency injection. From the description, I find it safe to assume that we can consider Async as a surrogate for IO.
The code implies the existence of other types. I decided to define them like this:
type Mobile = Mobile of int type ProofId = ProofId of Guid type Registration = { Mobile : Mobile } type CompleteRegistrationResult = ProofRequired of ProofId | RegistrationCompleted
In reality, they're probably more complicated, but this is enough to make the code compile.
Is it possible to refactor completeRegistrationWorkflow to an impure/pure/impure sandwich?
Applicability #
It is possible to refactor completeRegistrationWorkflow to an impure/pure/impure sandwich. You'll see how to do that soon. Before we start that work, however, I'd like to warn against jumping to conclusions. It's possible that the problem statement doesn't capture some subtleties that one would have to deal with in the real world. It's also possible that I've misunderstood the essence of Christer van der Meeren's problem description.
It's (relatively) easy to teach the basics of programming. You teach a beginner about keywords, programming constructs, how to compile or interpret a program, and so on.
On the other hand, it's hard to write about dealing with complicated code. There are ways to make legacy code better, but the moves you have to make depend on myriad details. Complicated code is, by definition, something that's hard to learn. This means that truly complicated legacy code is rarely suitable for instructive examples. One has to strike a delicate balance and produce an example that looks complicated enough to warrant improvement, but on the other hand still be simple enough to be understood.
I think that Christer van der Meeren has struck that balance. With three dependencies, the sample code looks just complicated enough to warrant refactoring. On the other hand, you can understand what it's supposed to do in a few minutes. There's a risk, however, that the example is too simplified. That could weaken the result of the refactoring that follows. Could you still apply that refactoring if the problem was more complicated?
It's my experience that it's conspicuously often possible to implement an impure/pure/impure sandwich.
Fakes #
In the rest of this article, I want to show how to refactor completeRegistrationWorkflow to an impure/pure/impure sandwich. As Refactoring admonishes:
Right now, however, there's no tests, so I'm going to add some."to refactor, the essential precondition is [...] solid tests"
The tests will need some Test Doubles to stand in for the three dependency functions. If possible, I prefer state-based testing over interaction-based testing. First, then, we need some Fakes.
While completeRegistrationWorkflow takes three dependency functions, it looks as though there's only two architectural dependencies:
- A two-factor authentication service
- A registration database (or service)
type Fake2FA () = let mutable proofs = Map.empty member _.CreateProof mobile = match Map.tryFind mobile proofs with | Some (proofId, _) -> proofId | None -> let proofId = ProofId (Guid.NewGuid ()) proofs <- Map.add mobile (proofId, false) proofs proofId |> fun proofId -> async { return proofId } member _.VerifyProof mobile proofId = match Map.tryFind mobile proofs with | Some (_, true) -> true | _ -> false |> fun b -> async { return b } member _.VerifyMobile mobile = match Map.tryFind mobile proofs with | Some (proofId, _) -> proofs <- Map.add mobile (proofId, true) proofs | _ -> ()
In F#, I find that the easiest way to model a mutable resource is to use an object. This one just keeps track of a collection of proofs. The CreateProof method fits the function signature of completeRegistrationWorkflow's createProof function argument. It looks for an existing proof for the mobile number so that it can reuse the same proof multiple times. If there's no proof for mobile, it creates a new Guid and returns it after having first added it to the collection.
Likewise, the VerifyProof method fits the type of the verifyProof function argument. Proofs are actually tuples of IDs and a flag that keeps track of whether or not they've been verified. The method returns the flag if it's there, and false otherwise.
The third VerifyMobile method is a test-specific functionality that enables a test to mark a proof as having been verified via two-factor authentication.
Compared to Fake2FA, the Fake registration database is simple:
type FakeRegistrationDB () = inherit Collection<Registration> () member this.CompleteRegistration r = async { this.Add r }
Again, the CompleteRegistration method fits the completeRegistration function argument to completeRegistrationWorkflow. It just makes the inherited Add method Async.
Fixture creation #
My plan is to add Characterisation Tests so that I can refactor. I do, however, plan to change the API of the System Under Test (SUT). This could break the tests, which would defy their purpose. To protect against this, I'll test against a Facade. Initially, this Facade will be equivalent to the completeRegistrationWorkflow function, but this will change as I refactor.
In addition to the SUT Facade, the tests will also need access to the 'injected' dependencies. You can address this by creating a Fixture Object:
let createFixture () = let twoFA = Fake2FA () let db = FakeRegistrationDB () let sut = completeRegistrationWorkflow twoFA.CreateProof twoFA.VerifyProof db.CompleteRegistration sut, twoFA, db
This function return a triple of values: the SUT Facade and the two Fakes.
The SUT Facade is a partially applied function of the type ProofId option -> Registration -> Async<CompleteRegistrationResult>. In other words, it abstracts away the specifics about how impure actions are executed. It seems reasonable to imagine that the two remaining input arguments, ProofId option and Registration, are run-time values. Regardless of refactoring, the resulting function should be able to receive those arguments and produce the desired outcome.
Characterising the missing proof ID case #
It looks like the cyclomatic complexity of completeRegistrationWorkflow is 3, so you're going to need three Characterisation Tests. You can add them in any order you like, but in this case I found it natural to follow the order in which the branches are laid out in the SUT.
This test case verifies what happens if the proof ID is missing:
[<Theory>] [<InlineData 123>] [<InlineData 432>] let ``Missing proof ID`` mobile = async { let sut, twoFA, db = createFixture () let r = { Mobile = Mobile mobile } let! actual = sut None r let! expectedProofId = twoFA.CreateProof r.Mobile let expected = ProofRequired expectedProofId expected =! actual test <@ Seq.isEmpty db @> }
All the tests in this article use xUnit.net 2.4.0 with Unquote 5.0.0.
This test calls the sut Facade with a None proof ID and an arbitrary Registration r. Had I used a property-based testing framework such as FsCheck or Hedgehog, I could have made the Registration value itself an arbitrary test argument, but I thought that this was overkill for this situation.
In order to figure out the expectedProofId, the test relies on the behaviour of the Fake2FA class. The CreateProof method is idempotent, so calling it several times with the same number should return the same proof. In this test case, we expect the sut to have done so already, so calling the method once more from the test should return the same value that the SUT received. The test then wraps the proof ID in the ProofRequired case and uses Unquote's =! (must equal) operator to verify that expected is equal to actual.
Finally, the test also verifies that the reservations database remains empty.
Since this is a Characterisation Test it already passes, which makes it untrustworthy. How do I know that I didn't write a Tautological Assertion?
When I write Characterisation Tests, I always try to change the SUT to verify that the test fails for the appropriate reason. In order to fail the first assertion, I can make this change to the None branch of the SUT:
match proofId with | None -> //let! proofId = createProof registration.Mobile let proofId = ProofId (Guid.NewGuid ()) return ProofRequired proofId
This fails the expected =! actual assertion, as expected.
Likewise, you can fail the second assertion with this change:
match proofId with | None -> do! completeRegistration registration let! proofId = createProof registration.Mobile return ProofRequired proofId
The addition of the completeRegistration statement causes the test <@ Seq.isEmpty db @> assertion to fail, again as expected.
Now I trust that test.
Characterising the valid proof ID case #
Next, you have the case where all is good. The proof ID is present and valid. You can characterise the behaviour with this test:
[<Theory>] [<InlineData 987>] [<InlineData 247>] let ``Valid proof ID`` mobile = async { let sut, twoFA, db = createFixture () let r = { Mobile = Mobile mobile } let! p = twoFA.CreateProof r.Mobile twoFA.VerifyMobile r.Mobile let! actual = sut (Some p) r RegistrationCompleted =! actual test <@ Seq.contains r db @> }
This test uses CreateProof to create a proof before the sut is exercised. It also uses the test-specific VerifyMobile method to mark the mobile number (and thereby the proof) as valid.
Again, there's two assertions: one against the return value actual, and one that verifies that the registration database db now contains the registration r.
As before, you can't trust a Characterisation Test before you've seen it fail, so first edit the isValid branch of the SUT like this:
if isValid then do! completeRegistration registration //return RegistrationCompleted return ProofRequired proofId
This fails the RegistrationCompleted =! actual assertion, as expected.
Now make this change:
if isValid then //do! completeRegistration registration return RegistrationCompleted
Now the test <@ Seq.contains r db @> assertion fails, as expected.
This test also seems trustworthy.
Characterising the invalid proof ID case #
The final test case is when a proof ID exists, but it's invalid:
[<Theory>] [<InlineData 327>] [<InlineData 666>] let ``Invalid proof ID`` mobile = async { let sut, twoFA, db = createFixture () let r = { Mobile = Mobile mobile } let! p = twoFA.CreateProof r.Mobile let! actual = sut (Some p) r let! expectedProofId = twoFA.CreateProof r.Mobile let expected = ProofRequired expectedProofId expected =! actual test <@ Seq.isEmpty db @> }
The arrange phase of the test is comparable to the previous test case. The only difference is that the new test doesn't invoke twoFA.VerifyMobile r.Mobile. This leaves the generated proof ID p invalid.
The assertions, on the other hand, are identical to those of the Missing proof ID test case, which means that you can make the same edits to the else branch as you can to the None branch, as described above. If you do that, the assertions fail as they're supposed to. You can also trust this Characterisation Test.
Eta expansion #
While I want to keep the SUT Facade's type unchanged, I do want change the way I compose it. The goal is an impure/pure/impure sandwich: Do something impure first, then call a pure function with the data obtained, and finally do something impure with the output of the pure function.
This means that the composition is going to manipulate the input values to the SUT Facade. To make that easier, I perform an eta conversion on the sut:
let createFixture () = let twoFA = Fake2FA () let db = FakeRegistrationDB () let sut pid r = completeRegistrationWorkflow twoFA.CreateProof twoFA.VerifyProof db.CompleteRegistration pid r sut, twoFA, db
This doesn't change the behaviour or how the SUT is composed. It only makes the pid and r arguments explicitly visible.
Move proof verification #
When you consider the current implementation of completeRegistrationWorkflow, it seems that the impure actions are interleaved with the decision-making code. How to separate them?
The first opportunity that I identified was that it always calls verifyProof in the Some case. Whenever you want to call a method only in the Some case, but not in the None case, it suggest Option.map.
It should be possible to run Option.map (twoFA.VerifyProof r.Mobile) pid as the initial impure action of the impure/pure/impure sandwich. If that's possible, we could pass the output of that pure function as an argument to completeRegistrationWorkflow. That would already make it simpler:
let completeRegistrationWorkflow (createProof: Mobile -> Async<ProofId>) (completeRegistration: Registration -> Async<unit>) (proof: bool option) (registration: Registration) : Async<CompleteRegistrationResult> = async { match proof with | None -> let! proofId = createProof registration.Mobile return ProofRequired proofId | Some isValid -> if isValid then do! completeRegistration registration return RegistrationCompleted else let! proofId = createProof registration.Mobile return ProofRequired proofId }
Notice that by changing the proof argument to a bool option, you no longer need to call verifyProof, so you can remove it.
There's just one problem. The result of Option.map (twoFA.VerifyProof r.Mobile) pid is an Option<Async<bool>>, but you need an Option<bool>.
You can compose the SUT Facade in an asynchronous workflow, and use a let! binding, but that's not going to solve the problem. A let! binding only works when the outer container is Async. Here, the outermost container is Option. You're going to need to flip the containers around so that you get an Async<Option<bool>> that you can let!-bind:
let sut pid r = async { let! p = match Option.map (twoFA.VerifyProof r.Mobile) pid with | Some b -> async { let! b' = b return Some b' } | None -> async { return None } return! completeRegistrationWorkflow twoFA.CreateProof db.CompleteRegistration p r }
By pattern-matching on Option.map (twoFA.VerifyProof r.Mobile) pid, you can return one of two alternative asynchronous workflows.
Due to the let! binding, p is a bool option that you can pass to completeRegistrationWorkflow.
Traversal #
I know what you're going to say. You'll protest that I just moved complex behaviour out of completeRegistrationWorkflow. The implied assumption here is that completeRegistrationWorkflow is the top-level behaviour that you'd compose in a Composition Root. The createFixture function plays that role in this refactoring exercise.
You'd normally view the Composition Root as a Humble Object - an object that we accept isn't covered by tests because it has a cyclomatic complexity of one. This is no longer the case.
The conversion of Option<Async<bool>> to Async<Option<bool>> is, however, a well-known operation. In Haskell this is known as a traversal, and it's a completely generic operation:
// ('a -> Async<'b>) -> 'a option -> Async<'b option> let traverse f = function | Some x -> async { let! x' = f x return Some x' } | None -> async { return None }
You can put this function in a general-purpose module called AsyncOption and cover it by unit tests if you will. You can even put this module in a separate library; it's perfectly decoupled from the the specifics of the registration flow domain.
If you do that, completeRegistrationWorkflow doesn't change, but the composition does:
let sut pid r = async { let! p = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid return! completeRegistrationWorkflow twoFA.CreateProof db.CompleteRegistration p r }
You're now back where you'd like to be: One impure action produces a value that you can pass to another function. There's no explicit branching in the code. The cyclomatic complexity remains one.
Change return type #
That first refactoring takes care of one out of three impure dependencies. Next, you can get rid of createProof. This one seems to be more difficult to get rid of. It doesn't seem to be required only in the Some case, so a map or traverse can't work. In both cases, however, the result of calling createProof is handled in exactly the same way.
Here's another common trick in functional programming: Decouple decisions from effects. Return a value that indicates the decision that the function reaches, and then let the second impure action of the impure/pure/impure sandwich act on the decision.
In this case, you can model your decision as a Mobile option. You might want to consider a more explicit type, in order to better communicate intent, but it's best to keep each refactoring step small:
let completeRegistrationWorkflow (completeRegistration: Registration -> Async<unit>) (proof: bool option) (registration: Registration) : Async<Mobile option> = async { match proof with | None -> return Some registration.Mobile | Some isValid -> if isValid then do! completeRegistration registration return None else return Some registration.Mobile }
Notice that the createProof dependency is no longer required. I've removed it from the argument list of completeRegistrationWorkflow.
The composition now looks like this:
let createFixture () = let twoFA = Fake2FA () let db = FakeRegistrationDB () let sut pid r = async { let! p = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid let! res = completeRegistrationWorkflow db.CompleteRegistration p r let! pidr = AsyncOption.traverse twoFA.CreateProof res return pidr |> Option.map ProofRequired |> Option.defaultValue RegistrationCompleted }
Thanks to the let! binding, the result res is a Mobile option. You can now let the twoFA.CreateProof method traverse over res. This produces an Async<Option<ProofId>> that you can let!-bind to pidr - a ProofId option.
You can use Option.map to wrap the ProofId value in a ProofRequired case, if it's there. This step of the final pipeline produces a CompleteRegistrationResult option.
Finally, you can use Option.defaultValue to fold the option into a CompleteRegistrationResult. The default value is RegistrationCompleted. This is the case value that'll be used if the option is None.
Again, the composition has a cyclomatic complexity of one, and the type of the sut remains ProofId option -> Registration -> Async<CompleteRegistrationResult>. This is a true refactoring. The type of the SUT remains the same, and no behaviour changes. The tests still pass, even though I haven't had to edit them.
Change return type to Result #
Consider the intent of completeRegistrationWorkflow. The purpose of the operation is to complete a registration workflow. The name is quite explicit. Thus, the happy path is when the proof ID is valid and the function can call completeRegistration.
Usually, when you call a function that returns an option, the implied contract is that the Some case represents the happy path. That's not the case here. The Some case carries information about the error paths. This isn't idiomatic.
It'd be more appropriate to use a Result return value:
let completeRegistrationWorkflow (completeRegistration: Registration -> Async<unit>) (proof: bool option) (registration: Registration) : Async<Result<unit, Mobile>> = async { match proof with | None -> return Error registration.Mobile | Some isValid -> if isValid then do! completeRegistration registration return Ok () else return Error registration.Mobile }
This change is in itself small, but it does require some changes to the composition. Just as you had to add an Option.traverse function when the return type was an option, you'll now have to add similar functionality to Result. Result is also known as Either. Not only is it a bifunctor, you can also traverse both axes. Haskell calls this a bitraversable functor.
// ('a -> Async<'b>) -> ('c -> Async<'d>) -> Result<'a,'c> -> Async<Result<'b,'d>> let traverseBoth f g = function | Ok x -> async { let! x' = f x return Ok x' } | Error e -> async { let! e' = g e return Error e' }
Here I just decided to call the function traverseBoth and the module AsyncResult.
You're also going to need the equivalent of Option.defaultValue for Result. Something that translates both dimensions of Result into the same type. That's the Either catamorphism, so you could, for example, introduce another general-purpose function called cata:
// ('a -> 'b) -> ('c -> 'b) -> Result<'a,'c> -> 'b let cata f g = function | Ok x -> f x | Error e -> g e
This is another entirely general-purpose function that you can put in a general-purpose module called Result, in a general-purpose library. You can also cover it by unit tests, if you like.
These two general-purpose functions enable you to compose the workflow:
let createFixture () = let twoFA = Fake2FA () let db = FakeRegistrationDB () let sut pid r = async { let! p = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid let! res = completeRegistrationWorkflow db.CompleteRegistration p r let! pidr = AsyncResult.traverseBoth (fun () -> async { return () }) twoFA.CreateProof res return pidr |> Result.cata (fun () -> RegistrationCompleted) ProofRequired } sut, twoFA, db
This looks more confused than previous iterations. From here, though, it'll get better again. The first two lines of code are the same as before, but now res is a Result<unit, Mobile>. You still need to let twoFA.CreateProof traverse the 'error path', but now you also need to take care of the happy path.
In the Ok case you have a unit value (()), but traverseBoth expects its f and g functions to return Async values. I could have fixed that with a more specialised traverseError function, but we'll soon move on from here, so it's hardly worthwhile.
In Haskell, you can 'elevate' a value simply with the pure function, but in F#, you need the more cumbersome (fun () -> async { return () }) to achieve the same effect.
The traversal produces pidr (for Proof ID Result) - a Result<unit, ProofId> value.
Finally, it uses Result.cata to turn both the Ok and Error dimensions into a single CompleteRegistrationResult that can be returned.
Removing the last dependency #
There's still one dependency left: the completeRegistration function, but it's now trivial to remove. Instead of calling the dependency function from within completeRegistrationWorkflow you can use the same trick as before. Decouple the decision from the effect.
Return information about the decision the function made. In the above incarnation of the code, the Ok dimension is currently empty, since it only returns unit. You can use that 'channel' to communicate that you decided to complete a registration:
let completeRegistrationWorkflow (proof: bool option) (registration: Registration) : Async<Result<Registration, Mobile>> = async { match proof with | None -> return Error registration.Mobile | Some isValid -> if isValid then return Ok registration else return Error registration.Mobile }
This is another small change. When isValid is true, the function no longer calls completeRegistration. Instead, it returns Ok registration. This means that the return type is now Async<Result<Registration, Mobile>>. It also means that you can remove the completeRegistration function argument.
In order to compose this variation, you need one new general-purpose function. Perhaps you find this barrage of general-purpose functions exhausting, but it's an artefact of a design philosophy of the F# language. The F# base library contains only few general-purpose functions. Contrast this with GHC's base library, which comes with all of these functions built in.
The new function is like Result.cata, but over Async<Result<_>>.
// ('a -> 'b) -> ('c -> 'b) -> Async<Result<'a,'c>> -> Async<'b> let cata f g r = async { let! r' = r return Result.cata f g r' }
Since this function does conceptually the same as Result.cata I decided to retain the name cata and just put it in the AsyncResult module. (This may not be strictly correct, as I haven't really given a lot of thought to what a catamorphism for Async would look like, if one exists. I'm open to suggestions about better naming. After all, cata is hardly an idiomatic F# name.)
With AsyncResult.cata you can now compose the system:
let sut pid r = async { let! p = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid let! res = completeRegistrationWorkflow p r return! res |> AsyncResult.traverseBoth db.CompleteRegistration twoFA.CreateProof |> AsyncResult.cata (fun () -> RegistrationCompleted) ProofRequired }
Not only did the call to completeRegistrationWorkflow get even simpler, but you also now avoid the awkwardly named pidr value. Thanks to the let! binding, res has the type Result<Registration, Mobile>.
Note that you can now let both impure actions (db.CompleteRegistration and twoFA.CreateProof) traverse the result. This step produces an Async<Result<unit, ProofId>> that's immediately piped to AsyncResult.cata. This reduces the two alternative dimensions of the Result to a single Async<CompleteRegistrationResult> value.
The completeRegistrationWorkflow function now begs to be further simplified.
Pure registration workflow #
Once you remove all dependencies, your domain logic doesn't have to be asynchronous. Nothing asynchronous happens in completeRegistrationWorkflow, so simplify it:
let completeRegistrationWorkflow (proof: bool option) (registration: Registration) : Result<Registration, Mobile> = match proof with | None -> Error registration.Mobile | Some isValid -> if isValid then Ok registration else Error registration.Mobile
Gone is the async computation expression, including the return keyword. This is now a pure function.
You'll have to adjust the composition once more, but it's only a minor change:
let sut pid r = async { let! p = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid return! completeRegistrationWorkflow p r |> AsyncResult.traverseBoth db.CompleteRegistration twoFA.CreateProof |> AsyncResult.cata (fun () -> RegistrationCompleted) ProofRequired }
The result of invoking completeRegistrationWorkflow is no longer an Async value, so there's no reason to let!-bind it. Instead, you can call it and immediately pipe its output to AsyncResult.traverseBoth.
DRY #
Consider completeRegistrationWorkflow. Can you make it simpler?
At this point it should be evident that two of the branches contain duplicate code. Applying the DRY principle you can simplify it:
let completeRegistrationWorkflow (proof: bool option) (registration: Registration) : Result<Registration, Mobile> = match proof with | Some true -> Ok registration | _ -> Error registration.Mobile
I'm not too fond of this style of type annotation for simple functions like this, so I'd like to remove it:
let completeRegistrationWorkflow proof registration = match proof with | Some true -> Ok registration | _ -> Error registration.Mobile
These two steps are pure refactorings: they only reorganise the code that implements completeRegistrationWorkflow, so the composition doesn't change.
Essential complexity #
While reading this article, you may have felt frustration gather. This is cheating! You took out all of the complexity. Now there's nothing left! You're likely to feel that I've moved a lot of behaviour into untestable code. I've done nothing of the sort.
I'll remind you that while functions like AsyncOption.traverse and AsyncResult.cata do contain branching behaviour, they can be tested. In fact, since they're pure functions, they're intrinsically testable.
It's true that a composition of a pure function with its impure dependencies may not be (unit) testable, but that's also true for a Dependency Injection-based object graph composed in a Composition Root.
Compositions of functions may look non-trivial, but to a degree, the type system will assist you. If your composition compiles, it's likely that you've composed the impure/pure/impure sandwich correctly.
Did I take out all the complexity? I didn't. There's a bit left; the function now has a cyclomatic complexity of two. If you look at the original function, you'll see that the duplication was there all along. Once you remove all the accidental complexity, you uncover the essential complexity. This happens to me so often when I apply functional programming principles that I fancy that functional programming is a silver bullet.
Pipeline composition #
We're mostly done now. The problem now appears in all its simplicity, and you have an impure/pure/impure sandwich.
You can still improve the code, though.
If you consider the current composition, you may find that p isn't the best variable name. I admit that I struggled with naming that variable. Sometimes, variable names are in the way and the code might be clearer if you could elide them by composing a pipeline of functions.
That's always worth an attempt. This time, ultimately I find that it doesn't improve things, but even an attempt can be illustrative.
If you want to eliminate a named value, you can often do so by piping the output of the function that produced the variable directly to the next function. This does, however, require that the function argument is the right-most. Currently, that's not the case. registration is right-most, and proof is to the left.
There's no compelling reason that the arguments should come in that order, so flip them:
let completeRegistrationWorkflow registration proof = match proof with | Some true -> Ok registration | _ -> Error registration.Mobile
This enables you to write the entire composition as a single pipeline:
let sut pid r = async { return! AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid |> Async.map (completeRegistrationWorkflow r) |> Async.bind ( AsyncResult.traverseBoth db.CompleteRegistration twoFA.CreateProof >> AsyncResult.cata (fun () -> RegistrationCompleted) ProofRequired) }
This does, however, call for two new general-purpose functions: Async.map and Async.bind:
// ('a -> 'b) -> Async<'a> -> Async<'b> let map f x = async { let! x' = x return f x' } // ('a -> Async<'b>) -> Async<'a> -> Async<'b> let bind f x = async { let! x' = x return! f x' }
In my opinion, these functions ought to belong to F#'s Async module, but for for reasons that aren't clear to me, they don't. As you can see, though, they're easy to add.
While the this change gets rid of the p variable, I don't think it makes the overall composition easier to understand. The action of swapping the function arguments does, however, enable another simplification.
Eta reduction #
Now that proof is completeRegistrationWorkflow's last function argument, you can perform an eta reduction:
let completeRegistrationWorkflow registration = function | Some true -> Ok registration | _ -> Error registration.Mobile
Not everyone is a fan of the point-free style, but I like it. YMMV.
Sandwich #
Regardless of whether you prefer completeRegistrationWorkflow in point-free or pointed style, I think that the composition needs improvement. It should explicitly communicate that it's an impure/pure/impure sandwich. This makes it necessary to reintroduce some variables, so I'm also going to bite the bullet and devise some better names.
let sut pid r = async { let! validityOfProof = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid let decision = completeRegistrationWorkflow r validityOfProof return! decision |> AsyncResult.traverseBoth db.CompleteRegistration twoFA.CreateProof |> AsyncResult.cata (fun () -> RegistrationCompleted) ProofRequired }
Instead of p, I decided to call the first value validityOfProof. This is the result of the first impure action in the sandwich (the upper slice of bread).
While validityOfProof is the result of an impure action, the value itself is pure and can be used as input to completeRegistrationWorkflow. This is the pure part of the sandwich. I called the output decision because the workflow makes a decision based on its input, and it's up to the caller to act on that decision.
Notice that decision is bound with a let binding (instead of a let! binding), despite taking place inside an async workflow. This is because completeRegistrationWorkflow is pure. It doesn't return an Async value.
The second impure action acts on decision through a pipeline of AsyncResult.traverseBoth and AsyncResult.cata, as previously explained.
I think that the impure/pure/impure sandwich is more visible like this, so that was my final edit. I'm happy with how it looks now.
Conclusion #
I don't claim that you can always refactor code to an impure/pure/impure sandwich. In fact, I can easily envision categories of software where such an architecture seems impossible.
Still, I find it intriguing that when I find myself in the realm of web services or message-based applications, I can't recall a case where a sandwich has been impossible. Surely, there must cases where it is so. That's the reason that I solicit examples. This article was a response to such an example. I found it fruitful, because it enabled me to discuss several useful techniques for composing behaviour in a functional architecture. On the other hand, it failed to be a counter-example.
I'm sure that some readers are left with a nagging doubt. That's all very impressive, but would you actually write code like that in a piece of production software?
If it was up to me, then: yes. I find that when I can keep code pure, it's trivial to unit test and there's no test-induced damage. Functions also compose in a way objects don't easily do, so there's many advantages to functional programming. I'll take them when they're available.
As always, context matters. I've been in team settings where other team members would embrace this style of programming, and in other environments where team members wouldn't understand what was going on. In the latter case, I'd adjust my approach to challenge, not alienate, other team members.
My intention with this article was to show what's possible, not to dictate what you should do. That's up to you.
This article is the December 2 entry in the F# Advent Calendar in English 2019.
Comments
Thank you so much for the comprehensive reply to my comment. It was very instructive to see refactoring process, from thought to code. The post is an excellent reply to the question I asked.
A slight modification
In my original comment, I made one simplification that, in hindsight, I perhaps should not have made. It is not critical, but it complicates things slightly. In reality, the completeRegistration function does not return Async<unit>, but Async<Result<unit, CompleteRegistrationError>> (where, currently, CompleteRegistrationError has the single case UserExists, returned if the DB throws a unique constraint error).
As I see it, the impact of this to your refactoring is two-fold:
- You can't easily use
AsyncResult.traverseBoth, since the signatures between the two cases aren't compatible (unless you want to mess around with nestedResultvalues). You could write a customtraversefunction just for the needed signature, but then we’ve traveled well into the lands of “generic does not imply general”. - It might be better to model the registration result (completed vs. proof required) as its own DU, with
Resultbeing reserved for actual errors.
Evaluating the refactoring
My original comment ended in the following question (emphasis added):
Is it possible to refactor this to direct input/output, in a way that actually reduces complexity where it matters?
With this (vague) question and the above modifications in mind, let's look at the relevant code before/after. In both cases, there are two functions: The workflow/logic, and the composition.
Before
Before refactoring, we have a slightly complex impure workflow (which still is fairly easily testable using state-based testing, as you so aptly demonstrated) – note the asyncResult CE (I’m using the excellent FsToolkit.ErrorHandling, if anyone wonders) and the updated signatures; otherwise it’s the same:
let completeRegistrationWorkflow
(createProof: Mobile -> Async<ProofId>)
(verifyProof: Mobile -> ProofId -> Async<bool>)
(completeRegistration: Registration -> Async<Result<unit, CompleteRegistrationError>>)
(proofId: ProofId option)
(registration: Registration)
: Async<Result<CompleteRegistrationResult, CompleteRegistrationError>> =
asyncResult {
match proofId with
| None ->
let! proofId = createProof registration.Mobile
return ProofRequired proofId
| Some proofId ->
let! isValid = verifyProof registration.Mobile proofId
if isValid then
do! completeRegistration registration
return RegistrationCompleted
else
let! proofId = createProof registration.Mobile
return ProofRequired proofId
}
Secondly, we have the trivial "humble object" composition, which looks like this:
let complete proofId validReg =
Workflows.Registration.complete
Http.createMobileClaimProof
Http.verifyMobileClaimProof
Db.completeRegistration
proofId
validReg
The composition is, indeed, humble – the only thing it does is call the higher-order workflow function with the correct parameters. It has no cyclomatic complexity and is trivial to read, and I don't think anyone would consider it necessary to test.
After
After refactoring, we have the almost trivial pure function we extracted (for simplicity I let it return Result here, as you proposed):
let completePure reg proofValidity =
match proofValidity with
| Some true -> Ok reg
| Some false | None -> Error reg.Mobile
Secondly, we have the composition function. Now, with the modification to completeRegistration (returning Async<Result<_,_>>), it can't as easily be written in point-free style. You might certainly be able to improve it, but here is my quick initial take.
let complete proofId reg : Async<Result<CompleteRegistrationResult, CompleteRegistrationError>> =
asyncResult {
let! proofValidity =
proofId |> Option.traverseAsync (Http.verifyMobileClaimProof reg.Mobile)
match completePure reg proofValidity with
| Ok reg ->
do! Db.completeRegistration reg
return RegistrationCompleted
| Error mobile ->
let! proofId = Http.createMobileClaimProof mobile
return ProofRequired proofId
}
Evaluation
Now that we have presented the code before/after, let us take stock of what we have gained and lost by the refactoring.
Pros:
- We have gotten rid of the "DI workflow" entirely
- More of the logic is pure
Cons:
- The logic we extracted to a pure function is almost trivial. This is not in itself bad, but one can wonder whether it was worth it (apart from the purely instructive aspects).
- If the extracted logic is pure, where then did the rest of the complexity go? The only place it could – it ended up in the "composition", i.e. the "humble object". The composition function isn't just calling a higher-order function with the correct function arguments any more; it has higher cyclomatic complexity and is much harder to read, and can't be easily tested (since it's a composition function). The new composition is, so to say, quite a bit less humble than the original composition. This is particularly evident in my updated version, but personally I also have to look at your simpler(?), point-free version a couple of times to convince myself that it is, really, not doing anything wrong. (Though regardless of whether a function is written point-free or not, it does the exact same thing and has the same complexity.)
- To the point above: The composition function needs many "complex" helper functions that would likely confuse, if not outright alienate beginner F# devs (which could, for example, lead to worse onboarding). This is particularly relevant for non-standard functions like
AsyncOption.traverse,AsyncResult.traverseBoth,AsyncResult.cata, etc.
Returning to my initial question: Does the refactoring “reduce complexity where it matters?“ I’m not sure. This is (at least partly) “personal opinions” territory, of course, and my vague question doesn’t help. But personally I find the result of the refactoring more complex to understand than the original, DI workflow-based version.
Based on Scott Wlaschin’s book Domain Modelling Made Functional, it’s possible he might agree. He seems very fond of the “DI workflow” approach there. I personally prefer a bit more dependency rejection than that, because I find “DR”/sandwiches often leads to simpler code, but in this particular case, I may prefer the impure DI workflow, tested using state-based testing. At least for the more complex code I described, but perhaps also for your original example.
Still, I truly appreciate your taking the time to respond in this manner. It was very instructive, as always, which was after all the point. And you’re welcome to share any insights regarding this comment, too.
Christer, thank you for writing. This is great! One of your comments inspires me to compose another article that I've long wanted to write. If I manage to produce it in time, I'll publish it Monday. Once that's done, I'll respond here in a more thorough manner.
When I do that, however, I don't plan to reproduce your updated example, or address it in detail. I see nothing in it that invalidates what I've already written. As far as I can tell, you don't need to explicitly pattern-match on completePure reg proofValidity. You should be able to map or traverse over it like already shown. If you want my help with the details, I'll be happy to do so, but then please prepare a minimal working example like I did for this article. You can either fork my example or make a new repository.
This is a fantastic post Mark! Thank you very much for going step-by-step while explaining how you refactored this code.
I find it intriguing that when I find myself in the realm of web services or message-based applications, I can't recall a case where a [impure/pure/impure] sandwich has been impossible. Surely, there must cases where it is so. That's the reason that I solicit examples.
I would like to suggest a example in the realm of web services or message-based applications that cannot be expressed as a impure/pure/impure sandwich.
Let's call an "impure/pure/impure sandwich" an impure-pure-impure composition. More generally, any impure funciton can be expressed as a composition of the form [pure-]impure(-pure-impure)*[-pure]. That is, (1) it might begin with a pure step, then (2) there is an impure step, then (3) there is a sequence of length zero or more containing a pure step followed by an impure step, and lastly (4) it might end with another pure step. One reason an impure fucntion might intentially be expressed by a composition that ends with a pure step is to erase senitive informaiton form the memory hierarchy. For simplicity though, let's assume that any impure function can be refactored so that the corresponding composition ends with an impure step. Let the length of a composition be one plus the number of dashes (-) that it contains.
Suppose f is a function with an impure-pure-impure composition such that f cannot be refactored to a fucntion with a composition of a smaller length. Then there exists fucntion f' with a pure-impure-pure-impure composition. The construction uses public-key cryptography. I think this is a natural and practical example.
Here is the definition of f' in words. The user sends to the server ciphertext encryped using the server's public key. The user's request is received by a process that already has the server's private key loaded into memory. This process decrypts the user's ciphertext using its private key to obtain some plantext p. This step is pure. Then the process passes p into f.
Using symmetric-key cryptography, it is possible to construct a function with a composition of an arbitrarily high length. The following construction reminds me of how union routing works (though each decryption in that case is intended to happen in a different process on a different server). I admit that this example is not very natural or practical.
Suppose f is a function with a composition of length n. Then there exists fucntion f' with a composition of length greater than n. Specifically, if the original composition starts with a pure step, then the length is larger by one; if the original composition starts with an impure step, then the length is larger by two.
Here is the definition of f' in words. The user sends to the server an ID and ciphertext encryped using a symmetric key that corresponds to the ID. The user's request is received by a process that does not have any keys loaded into memory. First, this process obtains from disk the appropriate symmetric key using the ID. This step is impure. Then this process decrypts the user's ciphertext using this key to obtain some plantext p. This step is pure. Then the process passes p into f.
Tyson, thank you for writing. Unfortunately, I don't follow your chain of reasoning. Cryptography strikes me as fitting the impure/pure/impure sandwich architecture quite well. There's definitely an initial impure step because you have to initialise a random number generator, as well as load keys, salts, and whatnot from storage. From there, though, the cryptographic algorithms are, as far as I'm aware, pure calculation. I don't see how asymmetric cryptography changes that.
The reason that I'm soliciting examples that defy the impure/pure/impure sandwich architecture, however, is that I'm looking for a compelling example. What to do when the sandwich architecture is impossible is a frequently asked question. To be clear, I know what to do in that situation, but I'd like to write an article that answers the question in a compelling way. For that, I need an example that an uninitiated reader can follow.
Sorry that my explanation was unclear. I should have included an example.
Cryptography strikes me as fitting the impure/pure/impure sandwich architecture quite well. There's definitely an initial impure step because you have to initialise a random number generator, as well as load keys, salts, and whatnot from storage. From there, though, the cryptographic algorithms are, as far as I'm aware, pure calculation. I don't see how asymmetric cryptography changes that.
I agree that cyptographic algorithms are pure. From your qoute that I included above, I get the impression that you have neglected to consider what computation is to be done with the output of the cyptogrpahic algorithm.
Here is a specific example of my first construction, which uses public-key cyptography. Consider the function sut that concluded your post. I repeat it for clarity.
let sut pid r = async { let! validityOfProof = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid let decision = completeRegistrationWorkflow r validityOfProof return! decision |> AsyncResult.traverseBoth db.CompleteRegistration twoFA.CreateProof |> AsyncResult.cata (fun () -> RegistrationCompleted) ProofRequired }
Let sut be the function f in that construction. In particular, sut is an impure/pure/impure sandwich, or equivalently an impure-pure-impure composition that of course has length 3. Furthermore, I think it is clear that this behavior cannot be expressed as a pure-impure-pure composition, a pure-impure composition, an impure-pure composition, or an impure composition. You worked very hard to simplfy that code, and I believe an implicit claim of yours is that it cannot be simplified any further.
In this case, f' would be the following function.
let privateKey = ... let sut' ciphertext = async { let (pid, r) = decrypt privateKey ciphertext let! validityOfProof = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid let decision = completeRegistrationWorkflow r validityOfProof return! decision |> AsyncResult.traverseBoth db.CompleteRegistration twoFA.CreateProof |> AsyncResult.cata (fun () -> RegistrationCompleted) ProofRequired }
As I defined it, this function is a pure-impure-pure-impure composition, which has length 4. Maybe in your jargon you would call this a pure/impure/pure/impure sandwich. My claim is that this function cannot be refactored into an impure/pure/impure sandwich.
Do you think that my claim is correct?
Tyson, thank you for your patience with me. Now I get it. As stated, your composition looks like a pure-impure-pure-impure composition, but unless you hard-code privateKey, you'll have to load that value, which is an impure operation. That would make it an impure-pure-impure-pure-impure composition.
The decryption step itself is an impure-pure composition, assuming that we need to load keys, salts, etc. from persistent storage. You might also want to think of it as a 'mostly' pure function, since you could probably load decryption keys once when the application process starts, and keep them around for its entire lifetime.
It's a correct example of a more involved interaction model. Thank you for supplying it. Unfortunately, it's not one I can use for an article. Like other cross-cutting concerns like caching, logging, retry mechanisms, etcetera, security can be abstracted away as middleware. This implies that you'd have a middleware action that's implemented as an impure-pure-impure sandwich, and an application feature that's implemented as another impure-pure-impure sandwich. These two sandwiches are unrelated. A change to one of them is unlikely to trigger a change in the other. Thus, we can still base our application architecture on the notion of the impure-pure-impure sandwich.
I hope I've explained my demurral in a sensible way.
This implies that you'd have a middleware action that's implemented as an impure-pure-impure sandwich, and an application feature that's implemented as another impure-pure-impure sandwich. These two sandwiches are unrelated. A change to one of them is unlikely to trigger a change in the other.
The are unrelated semantically. Syntatically, the whole application sandwich is the last piece of impure bread on the middleware sandwich. This reminds me of a thought I have had and also heard recently, which is that the structure of code is like a fractal.
Anyway, I am hearing you say that you want functions to have "one responsibility", to do "one thing", to change for "one reason". With that constraint satisfied, you are requesting an example of a funciton that is not an impure/pure/impure sandwich. I am up to that challenge. Here is another attempt.
Suppose our job is to implement a man-in-the-middle attack in the style of Schneier's Chess Grandmaster Problem in which Alice and Bob know that they are communicating with Malory while Malory simply repeats what she hears to the other person. Specifically, Alice is a client and Bob is a server. Mailory acts like a server to Alice and like a client to Bob. The funciton would look something like this.
let malroyInTheMiddle aliceToMalory = async { let maloryToBob = convertIncoming aliceToMalory let! bobToMalory = service maloryToBob let maloryToAlice = convertOutgoing bobToMalory return maloryToAlice }
This is a pure-impure-pure composition, which is different from an impure-pure-impure composition.
Tyson, thank you for writing. The way I understand it, we are to assume that both convertIncoming and convertOutgoing are complicated functions that require substantial testing to get right. Under that assumption, I think that you're right. This doesn't directly fit the impure-pure-impure sandwich architecture.
It does, however, fit a simple function composition. As far as I can see, it's equivalent to something like this:
let malroyInTheMiddle =
Async.fromResult
>> Async.map convertIncoming
>> Async.bind service
>> Async.map convertOutgoing
I haven't tested it, but I'd imagine it to be something like that.
To nitpick, this isn't a pure-impure-pure composition, but rather an impure-pure-impure-pure-impure composition. The entry point of a system is always impure, as is the output.
Christer, I'd hoped that I'd already addressed some of your concerns in the article itself, but I may not have done a good enough job of it. Overall, given a question like
"Is it possible to refactor this to direct input/output, in a way that actually reduces complexity where it matters?"I tend to put emphasis on is it possible. Not that the rest of the question is unimportant, but it's more subjective. Perhaps you find that my article didn't answer your question, but I hope at least that I managed to establish that, yes, it's possible to refactor to an impure-pure-impure sandwich.
Does it matter? I think it does, but that's subjective. I do think, though, that I can objectively say that my refactoring is functional, whereas passing impure functions as arguments isn't. Whether or not an architecture ought to be functional is, again, subjective. No-one says that it has to be. That's up to you.
As I wrote in my preliminary response, I'm not going to address your modification. I don't see that it matters. Even when you return an Async<Result<_,_>> you can map, bind, or traverse over it. You may not be able to use AsyncResult.traverseBoth, but you can derive specialisations like AsyncResult.traverseOk and AsyncResult.traverseError.
First, like you did, I find it illustrative to juxtapose the alternatives. I'm going to use the original example first:
let completeRegistrationWorkflow (createProof: Mobile -> Async<ProofId>) (verifyProof: Mobile -> ProofId -> Async<bool>) (completeRegistration: Registration -> Async<unit>) (proofId: ProofId option) (registration: Registration) : Async<CompleteRegistrationResult> = async { match proofId with | None -> let! proofId = createProof registration.Mobile return ProofRequired proofId | Some proofId -> let! isValid = verifyProof registration.Mobile proofId if isValid then do! completeRegistration registration return RegistrationCompleted else let! proofId = createProof registration.Mobile return ProofRequired proofId } let sut = completeRegistrationWorkflow twoFA.CreateProof twoFA.VerifyProof db.CompleteRegistration
In contrast, here's my refactoring:
let completeRegistrationWorkflow registration = function | Some true -> Ok registration | _ -> Error registration.Mobile let sut pid r = async { let! validityOfProof = AsyncOption.traverse (twoFA.VerifyProof r.Mobile) pid let decision = completeRegistrationWorkflow r validityOfProof return! decision |> AsyncResult.traverseBoth db.CompleteRegistration twoFA.CreateProof |> AsyncResult.cata (fun () -> RegistrationCompleted) ProofRequired }
It's true that my composition (sut) seems more involved than yours, but the overall trade-off looks good to me. In total, the code is simpler.
In your evaluation, you make some claims that I'd like to specifically address. Most are reasonable, but I think a few require special attention:
"The logic we extracted to a pure function is almost trivial."Indeed. This should be listed as a pro, not a con. Whether or not it's worth it is a different discussion.
As I wrote in the article:
"If you look at the original function, you'll see that the duplication was there all along. Once you remove all the accidental complexity, you uncover the essential complexity."(Emphasis from the original.) Isn't it always worth it to take away accidental complexity?
"The composition function isn't just calling a higher-order function with the correct function arguments any more; it has higher cyclomatic complexity"No, it doesn't. It has a cyclomatic complexity of 1, exactly like the original humble object.
"can't be easily tested"True, but neither can the original humble object.
"The new composition is, so to say, quite a bit less humble than the original composition."According to which criterion? It has the same cyclomatic complexity, but I admit that more characters went into typing it. On the other hand, the composition juxtaposed with the actual function has far fewer characters than the original example.
You also write that
"The composition function needs many "complex" helper functions [...]. This is particularly relevant for non-standard functions likeI don't like the epithet non-standard. It's true that these functions aren't inAsyncOption.traverse,AsyncResult.traverseBoth,AsyncResult.cata, etc."
FSharp.Core, for reasons that aren't clear to me. In comparison, they're part of the standard base library in Haskell.
There's nothing non-standard about functions like these. Like map and bind, traversals and catamorphisms are universal abstractions. They exist independently of particular programming languages or library packages.
I think that it's fair criticism that they may not be friendly to absolute beginners, but they're still fairly basic ideas that address real needs. The same can be said for the asyncResult computation expression that you've decided to use. It's also 'non-standard' only in the sense that it's not part of FSharp.Core, but otherwise standard in that it's just a stack of monads, and plenty of libraries supply that functionality. You can also write that computation expression yourself in a dozen lines of code.
In the end, all of this is subjective. As I also wrote in my conclusion:
What I do, however, think is important to realise is that what I suggest is to learn a set of concepts once. Once you understand functors, monads, traversals etcetera, that's knowledge that applies to F#, Haskell, C#, JavaScript (I suppose) and so on."I've been in team settings where [...] team members wouldn't understand what was going on. In the latter case, I'd adjust my approach to challenge, not alienate, other team members.
"My intention with this article was to show what's possible, not to dictate what you should do."
Personally, I find it a better investment of my time to learn a general concept once, and then work with trivial code, rather than having to learn, over and over again, how to deal with each new code base's accidental complexity.
Mark, thank you for getting back to me with a detailed response.
First, a general remark. I see that my comment might have been a bit "sharp around the edges” and phrased somewhat carelessly, giving the impression that I was not happy with your treatment of my example. I’d just like to clearly state that I am. You replied in your usual clear manner to exactly the question I posed, and seeing your process and solution was instructive for me.
We are all learning, all the time, and if I use a strong voice, that is primarily because strong opinions, weakly held often seems to be a fruitful way to drive discussion and learning.
With that in mind, allow me to address some of your remarks and possibly soften my previous comment.
Perhaps you find that my article didn't answer your question, but I hope at least that I managed to establish that, yes, it's possible to refactor to an impure-pure-impure sandwich.
Your article did indeed answer my question. My takeaway (then, not necessarily now after reading the rest of your comment) was that you managed to refactor to impure-pure-impure at the "expense” of making the non-pure part harder to understand. But as you say, that’s subjective, and your remarks on that later in your comment was a good point of reflection for me. I’ll get to that later.
Does it matter? I think it does, but that's subjective. I do think, though, that I can objectively say that my refactoring is functional, whereas passing impure functions as arguments isn't. Whether or not an architecture ought to be functional is, again, subjective. No-one says that it has to be. That's up to you.
I agree on all points.
First, like you did, I find it illustrative to juxtapose the alternatives.
I don’t agree 100% that it’s a completely fair comparison, since you’re leaving out the implementations of AsyncOption.traverse, AsyncResult.traverseBoth, and AsyncResult.cata. However, I get why you are doing it. These are generic utility functions for universal concepts that, as you say later in your comment, you “learn once”. In that respect, it’s fair to leave them out. My only issue with it is that since F# doesn’t have higher-kinded types, these utility functions have to be specific to the monads and monad stacks in use. I originally thought this made such functions less understandable and less useful, but after reading the rest of your comment, I’m not sure they are. More on that below.
In your evaluation
(Emphasis yours.) Just in case: “Evaluation” might have been a poor choice of words. I hope you did not take it to mean that I was a teacher grading a student’s test. This was not in any way intended personally (e.g. evaluating "your solution”). I was merely looking to sum up my subjective opinions about the refactoring.
Isn't it always worth it to take away accidental complexity?
I find it hard to say an unequivocal "yes” to such general statements. Ultimately it depends on the specific context and tradeoffs involved. If the context is “a codebase to be used for onboarding new F# devs” and the tradeoffs are “use generic helper functions to traverse bifunctors in a stack of monads”, then I’m not sure. (It may still be, but it’s certainly not a given.)
But generally, though I haven’t reflected deeply on this, I’m sure you’re right that it’s worthwhile to always take away accidental complexity.
No, it doesn't. It has a cyclomatic complexity of 1, exactly like the original humble object.
You’re right. Thank you for the clarifying article on cyclomatic complexity.
can't be easily tested
True, but neither can the original humble object.
That’s correct, but my point was that the original composition was trivial (just calling a “DI function” with the correct arguments/dependencies) and didn’t need to be tested, whereas the refactored composition does more and might warrant testing (at least to a larger degree than the original).
This raises an interesting point. It seems (subjectively to me based on what I’ve read) to be a general consensus that a function can be left untested (is “humble”, so to speak) as long as it consists of just generic helpers, like the refactored composition. That "if it compiles, it works”. This is not a general truth, since for some signatures there may exist several transformations from the input type to the output type, where the output value is different for the different transformations. I have come across such cases, and even had bugs because I used the wrong transformation. Which is why I said:
The new composition is, so to say, quite a bit less humble than the original composition.
According to which criterion?
It is more complex in the sense that it doesn’t just call a function with the correct dependencies. The original composition is more or less immediately recognizable as correct. The refactored composition, as I said, required me to look at it more carefully to convince myself that it was correct. (I will grant that this is to some extent subjective, though.)
I don't like the epithet non-standard. It's true that these functions aren't in
FSharp.Core, for reasons that aren't clear to me. In comparison, they're part of the standardbaselibrary in Haskell.There's nothing non-standard about functions like these. Like
mapandbind, traversals and catamorphisms are universal abstractions. They exist independently of particular programming languages or library packages.I think that it's fair criticism that they may not be friendly to absolute beginners, but they're still fairly basic ideas that address real needs.
…
What I do, however, think is important to realise is that what I suggest is to learn a set of concepts once. Once you understand functors, monads, traversals etcetera, that's knowledge that applies to F#, Haskell, C#, JavaScript (I suppose) and so on.
Personally, I find it a better investment of my time to learn a general concept once, and then work with trivial code, rather than having to learn, over and over again, how to deal with each new code base's accidental complexity.
This is the primary point of reflection for me in your comment. While I frequently use monads and monad stacks (particularly Async<Result<_,_>>) and often write utility code to transform when needed (e.g. List.traverseResult), I try to limit the number of such custom utility functions. Why? I’m not sure, actually. It may very well have to do with my work environment, where for a long time I have been the only F# dev and I don’t want to alienate the other .NET devs before they even get started with F#.
In light of your comment, perhaps F# devs are doing others a disservice if we limit our use of important, general concepts like functors, monads, traversals etc.? Then again, there’s certainly a balance to be struck. I got started (and thrilled) with F# by reading F# for fun and profit and learning about algebraic types, the concise syntax, "railway-oriented programming” etc. If my first glimpse of F# had instead been AsyncSeq.traverseAsyncResultOption, then I might never have left the warm embrace of C#.
I might check out FSharpPlus, which seems to make this kind of programming easier. I have previously steered away from that library because I deemed it “too complex” (c.f. my remarks about alienating coworkers), but it might be time to reconsider. If you have tried it, I would love to hear your thoughts on it in some form or another, though admittedly that isn’t directly related to the topic at hand.
Christer, don't worry about the tone of the debate. I'm not in the least offended or vexed. On the contrary, I find this a valuable discussion, and I'm glad that we're having it in a medium where it's also visible to other people.
I think that we're gravitating towards consensus. I definitely agree that the changes I suggest aren't beginner-friendly.
People sometimes ask me for advice on how to get started with functional programming, and I always tell .NET developers to start with F#. It's a friendly language that enables everyone to learn gradually. If you already know C# (or Visual Basic .NET) the only thing you need to learn about F# is some syntax. Then you can write object-oriented F#. As you learn new functional concepts, you can gradually change the way you write F# code. That's what I did.
I agree with your reservations about onboarding and beginner-friendliness. When that's a concern, I wouldn't write the F# code like I suggested either.
For a more sophisticated team, however, I feel that my suggestions are improvements that matter. I grant you that the composition seems more convoluted, but I consider the overall trade-off beneficial. In the terminology suggested by Rich Hickey, it may not be easier, bit it's simpler.
I have no experience with FSharpPlus or any similar libraries. I usually just add the monad stacks and functions to my code base on an as-needed basis. As we've seen here, such functions are mostly useful to compose other functions, so they rarely need to be exported as part of a code base's surface area.
TimeSpan configuration values in .NET Core
You can use a standard string format for TimeSpan values in configuration files.
Sometimes you need to make TimeSpan values configurable. I often see configuration files that look like this:
{
"SeatingDurationInSeconds": "9000"
}
Code can read such values from configuration files like this:
var seatingDuration = TimeSpan.FromSeconds(Configuration.GetValue<int>("SeatingDurationInSeconds"));
This works, but is abstruse. How long is 9000 seconds?
The idiomatic configuration file format for .NET Core is JSON, which even prevents you from adding comments. Had the configuration been in XML, at least you could have added a comment:
<!--9000 seconds = 2½ hours--> <SeatingDurationInSeconds>9000</SeatingDurationInSeconds>
In this case, however, it doesn't matter. Use the standard TimeSpan string representation instead:
{
"SeatingDuration": "2:30:00"
}
Code can read the value like this:
var seatingDuration = Configuration.GetValue<TimeSpan>("SeatingDuration");
I find a configuration value like "2:30:00" much easier to understand than 9000, and the end result is the same.
I haven't found this documented anywhere, but from experience I know that this capability is present in the .NET Framework, so I wondered if it was also available in .NET Core. It is.
Comments
There is actually an ISO 8601 standard for durations.
In your example you can use
{ "SeatingDuration": "P9000S" } or { "SeatingDuration": "P2H30M" } which is also quite readable in my opinion.
Not every JSON serializer supports it though.
Rex, thank you for writing. I was aware of the ISO standard, although I didn't know that you can use it in a .NET Core configuration file. This is clearly subjective, but I don't find that format as readable as 2:30:00.
Small methods are easy to troubleshoot
Write small methods. How small? Small enough that any unhandled exception is easy to troubleshoot.
Imagine that you receive a bug report. This one include a logged exception:
System.NullReferenceException: Object reference not set to an instance of an object. at Ploeh.Samples.BookingApi.Validator.Validate(ReservationDto dto) at Ploeh.Samples.BookingApi.ReservationsController.Post(ReservationDto dto) at lambda_method(Closure , Object , Object[] ) at Microsoft.Extensions.Internal.ObjectMethodExecutor.Execute(Object target, Object[] parameters) at Microsoft.AspNetCore.Mvc.Internal.ActionMethodExecutor.SyncActionResultExecutor.Execute(IActionResultTypeMapper mapper, ObjectMethodExecutor executor, Object controller, Object[] arguments) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeActionMethodAsync() at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeNextActionFilterAsync() at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.Rethrow(ActionExecutedContext context) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.Next(State& next, Scope& scope, Object& state, Boolean& isCompleted) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeInnerFilterAsync() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeNextResourceFilter() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.Rethrow(ResourceExecutedContext context) at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.Next(State& next, Scope& scope, Object& state, Boolean& isCompleted) at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeFilterPipelineAsync() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeAsync() at Microsoft.AspNetCore.Builder.RouterMiddleware.Invoke(HttpContext httpContext) at Microsoft.AspNetCore.Diagnostics.DeveloperExceptionPageMiddleware.Invoke(HttpContext context)
Oh, no, you think, not a NullReferenceException.
If you find it hard to troubleshoot NullReferenceExceptions, you're not alone. It doesn't have to be difficult, though. Open the method at the top of the stack trace, Validate:
public static class Validator { public static string Validate(ReservationDto dto) { if (!DateTime.TryParse(dto.Date, out var _)) return $"Invalid date: {dto.Date}."; return ""; } }
Take a moment to consider this method in the light of the logged exception. What do you think went wrong? Which object was null?
Failed hypothesis #
You may form one of a few hypotheses about which object was null. Could it be dto? dto.Date? Those are the only options I can see.
When you encounter a bug in a production system, if at all possible, reproduce it as a unit test.
If you think that the problem is that dto.Date is null, test your hypothesis in a unit test:
[Fact] public void ValidateNullDate() { var dto = new ReservationDto { Date = null }; string actual = Validator.Validate(dto); Assert.NotEmpty(actual); }
If you think that a null dto.Date should reproduce the above exception, you'd expect the test to fail. When you run it, however, it passes. It passes because DateTime.TryParse(null, out var _) returns false. It doesn't throw an exception.
That's not the problem, then.
That's okay, this sometimes happens. You form a hypothesis and fail to validate it. Reject it and move on.
Validated hypothesis #
If the problem isn't with dto.Date, it must be with dto itself. Write a unit test to test that hypothesis:
[Fact] public void ValidateNullDto() { string actual = Validator.Validate(null); Assert.NotEmpty(actual); }
When you run this test, it does indeed fail:
Ploeh.Samples.BookingApi.UnitTests.ValidatorTests.ValidateNullDto
Duration: 6 ms
Message:
System.NullReferenceException : Object reference not set to an instance of an object.
Stack Trace:
Validator.Validate(ReservationDto dto) line 12
ValidatorTests.ValidateNullDto() line 36
This looks like the exception included in the bug report. You can consider this as validation of your hypothesis. This test reproduces the defect.
It's easy to address the issue:
public static string Validate(ReservationDto dto) { if (dto is null) return "No reservation data supplied."; if (!DateTime.TryParse(dto.Date, out var _)) return $"Invalid date: {dto.Date}."; return ""; }
The point of this article, however, is to show that small methods are easy to troubleshoot. How you resolve the problem, once you've identified it, is up to you.
Ambiguity #
Methods are usually more complex than the above example. Imagine, then, that you receive another bug report with this logged exception:
System.NullReferenceException: Object reference not set to an instance of an object. at Ploeh.Samples.BookingApi.MaîtreD.CanAccept(IEnumerable`1 reservations, Reservation reservation) at Ploeh.Samples.BookingApi.ReservationsController.Post(ReservationDto dto) at lambda_method(Closure , Object , Object[] ) at Microsoft.Extensions.Internal.ObjectMethodExecutor.Execute(Object target, Object[] parameters) at Microsoft.AspNetCore.Mvc.Internal.ActionMethodExecutor.SyncActionResultExecutor.Execute(IActionResultTypeMapper mapper, ObjectMethodExecutor executor, Object controller, Object[] arguments) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeActionMethodAsync() at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeNextActionFilterAsync() at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.Rethrow(ActionExecutedContext context) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.Next(State& next, Scope& scope, Object& state, Boolean& isCompleted) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeInnerFilterAsync() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeNextResourceFilter() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.Rethrow(ResourceExecutedContext context) at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.Next(State& next, Scope& scope, Object& state, Boolean& isCompleted) at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeFilterPipelineAsync() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeAsync() at Microsoft.AspNetCore.Builder.RouterMiddleware.Invoke(HttpContext httpContext) at Microsoft.AspNetCore.Diagnostics.DeveloperExceptionPageMiddleware.Invoke(HttpContext context)
When you open the code file for the MaîtreD class, this is what you see:
public class MaîtreD { public MaîtreD(int capacity) { Capacity = capacity; } public int Capacity { get; } public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { int reservedSeats = 0; foreach (var r in reservations) reservedSeats += r.Quantity; if (Capacity < reservedSeats + reservation.Quantity) return false; return true; } }
This code throws a NullReferenceException, but which object is null? Can you identify it from the code?
I don't think that you can. It could be reservations or reservation (or both). Without more details, you can't tell. The exception is ambiguous.
The key to making troubleshooting easy is to increase your chances that, when exceptions are thrown, they're unambiguous. The problem with a NullReferenceException is that you can't tell which object was null.
Remove ambiguity by protecting invariants #
Consider the CanAccept method. Clearly, it requires both reservations and reservation in order to work. This requirement is, however, currently implicit. You can make it more explicit by letting the method protect its invariants. (This is also known as encapsulation. For more details, watch my Pluralsight course Encapsulation and SOLID.)
A simple improvement is to add a Guard Clause for each argument:
public bool CanAccept(IEnumerable<Reservation> reservations, Reservation reservation) { if (reservations is null) throw new ArgumentNullException(nameof(reservations)); if (reservation is null) throw new ArgumentNullException(nameof(reservation)); int reservedSeats = 0; foreach (var r in reservations) reservedSeats += r.Quantity; if (Capacity < reservedSeats + reservation.Quantity) return false; return true; }
If you'd done that from the start, the logged exception would instead have been this:
System.ArgumentNullException: Value cannot be null. Parameter name: reservations at Ploeh.Samples.BookingApi.MaîtreD.CanAccept(IEnumerable`1 reservations, Reservation reservation) at Ploeh.Samples.BookingApi.ReservationsController.Post(ReservationDto dto) at lambda_method(Closure , Object , Object[] ) at Microsoft.Extensions.Internal.ObjectMethodExecutor.Execute(Object target, Object[] parameters) at Microsoft.AspNetCore.Mvc.Internal.ActionMethodExecutor.SyncActionResultExecutor.Execute(IActionResultTypeMapper mapper, ObjectMethodExecutor executor, Object controller, Object[] arguments) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeActionMethodAsync() at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeNextActionFilterAsync() at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.Rethrow(ActionExecutedContext context) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.Next(State& next, Scope& scope, Object& state, Boolean& isCompleted) at Microsoft.AspNetCore.Mvc.Internal.ControllerActionInvoker.InvokeInnerFilterAsync() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeNextResourceFilter() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.Rethrow(ResourceExecutedContext context) at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.Next(State& next, Scope& scope, Object& state, Boolean& isCompleted) at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeFilterPipelineAsync() at Microsoft.AspNetCore.Mvc.Internal.ResourceInvoker.InvokeAsync() at Microsoft.AspNetCore.Builder.RouterMiddleware.Invoke(HttpContext httpContext) at Microsoft.AspNetCore.Diagnostics.DeveloperExceptionPageMiddleware.Invoke(HttpContext context)
It's now clear that it was the reservations argument that was null. Now fix that issue. Why does the CanAccept receive a null argument?
You may now consider examining the next frame in the stack trace: ReservationsController.Post:
public ActionResult Post(ReservationDto dto) { var validationMsg = Validator.Validate(dto); if (validationMsg != "") return BadRequest(validationMsg); var reservation = Mapper.Map(dto); var reservations = Repository.ReadReservations(reservation.Date); var accepted = maîtreD.CanAccept(reservations, reservation); if (!accepted) return StatusCode( StatusCodes.Status500InternalServerError, "Couldn't accept."); var id = Repository.Create(reservation); return Ok(id); }
The Post code only calls CanAccept once, so again, you can unambiguously deduce where the null reference comes from. It comes from the Repository.ReadReservations method call. Now go there and figure out why it returns null.
Notice how troubleshooting is trivial when the methods are small.
Size matters #
How small is a small method? How large does a method have to be before it's no longer small?
A method is small when you can easily troubleshoot it based exclusively on a logged exception.
Until you get the hang of it, it can be hard to predict if a method is going to be easy to troubleshoot. I therefore also follow another rule of thumb:
For languages like C#, methods should have a maximum size of 80x24 characters.
What if you already have bigger methods? Those are much harder to troubleshoot. If you have a method that spans hundreds of lines of code, a logged exception is rarely sufficient for troubleshooting. In order to save space, I'm not going to show en example of such a method, but I'm sure that you can easily find one in the code base that you professionally work with. Such a method is likely to have dozens of objects that could be null, so a NullReferenceException and a stack trace will contain too little information to assist troubleshooting.
I often see developers add tracing or logging to such code in order to facilitate troubleshooting. This makes the code even more bloated, and harder to troubleshoot.
Instead, cut the big method into smaller helper methods. You can keep the helper methods private so that you don't change the API. Even so, a logged exception will now report the helper method in its stack trace. Keep those helper methods small, and troubleshooting becomes trivial.
Conclusion #
Small methods come with many benefits. One of these is that it's easy to troubleshoot a small method from a logged exception. Small methods typically take few arguments, and use few variables. A logged exception will often be all that you need to pinpoint where the problem occurred.
A large method body, on the other hand, is difficult to troubleshoot. If all you have is a logged exception, you'll be able to find multiple places in the code where that exception could have been thrown.
Refactor big methods into smaller helper methods. If one of these helper methods throws an exception, the method name will be included in the stack trace of a logged exception. When the helper method is small, you can easily troubleshoot it.
Keep methods small. Size does matter.
Comments
How did you create those exception stack traces?
Compared to your examples, I am used to seeing each stack frame line end with the source code line number. (Although, sometimes I have seen all line numbers being 0, which is equivalent to having no line numbers at all.) The exception stack trace in your unit test includes line numbers but your other exception stack traces do not. This Stack Overflow answer contains an exception stack trace like with line numbers like I am used to seeing.
The line containing "lambda_method" also seem odd to me. As I recall, invoking a lambda expression also contributes more information to the stack trace than your examples include. Although, that information is cryptic enough that I don't remember off the top of my head what it means. (After a quick search, I didn't find a good example of how I am used to seeing lambda expressions displayed in a stack trace.)
With this additional informaiton, the methods can be longer while reamining unambiguous (in the sense you described).
Tyson, thank you for writing. IIRC, you only see line numbers for code compiled with debug information. That's why you normally don't see line numbers for .NET base class library methods, ASP.NET Core, etc.
While you can deploy and run an application in Debug mode, I wouldn't. When you compile in Release mode, the compiler makes optimisations (such as in-lining) that it can't do when it needs to retain a map to a specific source. In Debug mode, you squander those optimisations.
I've always deployed systems in Release mode. To make the examples realistic, I didn't include the line numbers in the stack trace, because in Release mode, they aren't going to be there.
When you're troubleshooting by reproducing a logged exception as a unit test, on the other hand, it's natural to do so in Debug mode.
I just tried to verify this. I didn't find any difference between compiling in Debug or Release mode as well as no fundemental issue with in-lining. In all four cases (debug vs release and in-lining vs no inlining), exception stack traces still included line numbers. When in-lining, the only different was the absense of the in-lined method from the stack trace.
Instead, I found that line numbers are included in exception stack traces if and only if the corresponding .pdb file is next to the .exe file when executed.
Tyson, that sounds correct. To be honest, I stopped putting effort into learning advanced debugging skills a long time ago. Early in my career we debugged by writing debug statements directly to output! Then I learned test-driven development, and with that disappeared most of the need to debug full systems. At the time I began working with systems that logged unhandled exceptions, the habit of writing small methods was already so entrenched that I never felt that I needed the line numbers.
FWIW, more than five years ago, I decided to publish symbols with AutoFixture, but I never found it useful.
I recommend setting DebugType to Embedded in every project file. This puts the PDB file inside the DLL. Having separate files is harmful in the same way that NuGet package restore is harmful. I don't think of this as an advanced debugging skill. It is trivial for one person to add the required line to each project. Then every future stack trace seen by any developer will include line numbers. Seems like an easy win to me.
Diamond rock
A diamond kata implementation written in Rockstar
I've previously written about the diamond kata, which has become one of my favourite programming exercises. I wanted to take the Rockstar language out for a spin, and it seemed a good candidate problem.
Rockstar #
If you're not aware of the Rockstar programming language, it started with a tweet from Paul Stovell:
This inspired Dylan Beattie to create the Rockstar programming language. The language's landing page already sports an idiomatic implementation of the FizzBuzz kata, so I had to pick another exercise. The diamond kata was a natural choice for me."To really confuse recruiters, someone should make a programming language called Rockstar."
Lyrics #
I'll start with the final result. What follows here are the final lyrics to Diamond rock. As you'll see, it starts with a short prologue after which it settles into a repetitive pattern. I imagine that this might make it useful for audience participation, in the anthem rock style of e.g. We Will Rock You.
After 25 repetitions the lyrics change. I haven't written music to any of them, but I imagine that this essentially transitions into another song, just like We Will Rock You traditionally moves into We Are the Champions. The style of the remaining lyrics does, however, suggest something musically more complex than a rock anthem.
Your memory says The way says A Despair takes your hope The key is nothing Your courage is a tightrope Let it be without it If your hope is your courage Let the key be the way Build your courage up If your hope is your courage The key says B Build your courage up If your hope is your courage The key says C Build your courage up If your hope is your courage The key says D Build your courage up If your hope is your courage The key says E Build your courage up If your hope is your courage The key says F Build your courage up If your hope is your courage The key says G Build your courage up If your hope is your courage The key says H Build your courage up If your hope is your courage The key says I Build your courage up If your hope is your courage The key says J Build your courage up If your hope is your courage The key says K Build your courage up If your hope is your courage The key says L Build your courage up If your hope is your courage The key says M Build your courage up If your hope is your courage The key says N Build your courage up If your hope is your courage The key says O Build your courage up If your hope is your courage The key says P Build your courage up If your hope is your courage The key says Q Build your courage up If your hope is your courage The key says R Build your courage up If your hope is your courage The key says S Build your courage up If your hope is your courage The key says T Build your courage up If your hope is your courage The key says U Build your courage up If your hope is your courage The key says V Build your courage up If your hope is your courage The key says W Build your courage up If your hope is your courage The key says X Build your courage up If your hope is your courage The key says Y Build your courage up If your hope is your courage The key says Z Give back the key Dream takes a tightrope Your hope's start'n'stop While Despair taking your hope ain't a tightrope Build your hope up Give back your hope Raindrop is a wintercrop Light is a misanthrope Let it be without raindrop Darkness is a kaleidoscope Let it be without raindrop Diamond takes your hour, love, and your day If love is the way Let your sorrow be your hour without light Put your sorrow over darkness into flight Put your memory of flight into motion Put it with love, and motion into the ocean Whisper the ocean If love ain't the way Let ray be your day of darkness without light Let your courage be your hour without darkness, and ray Put your courage over darkness into the night Put your memory of ray into action Let satisfaction be your memory of the night Let alright be satisfaction with love, action, love, and satisfaction Shout alright Listen to the wind Let flight be the wind Let your heart be Dream taking flight Let your breath be your heart of darkness with light Your hope's stop'n'start While your hope is lower than your heart Let away be Despair taking your hope Diamond taking your breath, away, and your hope Build your hope up Renown is southbound While your hope is as high as renown Let away be Despair taking your hope Diamond taking your breath, away, and your hope Knock your hope down
Not only do these look like lyrics, but it's also an executable program!
Execution #
If you want to run the program, you can copy the text and paste it into the web-based Rockstar interpreter; that's what I did.
When you Rock! the lyrics, the interpreter will prompt you for an input. There's no instructions or input validation, but the only valid input is the letters A to Z, and only in upper case. If you type anything else, I don't know what'll happen, but most likely it'll just enter an infinite loop, and you'll have to reboot your computer.
If you input, say, E, the output will be the expected diamond figure:
A
B B
C C
D D
E E
D D
C C
B B
A
When you paste the code, be sure to include everything. There's significant whitespace in those lyrics; I'll explain later.
Readable code #
As the Rockstar documentation strongly implies, singability is more important than readability. You can, however, write more readable Rockstar code, and that's what I started with:
Space says LetterA says A GetLetter takes index If index is 0 Give back LetterA If index is 1 retVal says B Give back retVal If index is 2 retVal says C Give back retVal GetIndex takes letter Index is 0 While GetLetter taking Index ain't letter Build Index up Give back Index PrintLine takes width, l, lidx If l is LetterA Let completeSpaceCount be width minus 1 Let paddingCount be completeSpaceCount over 2 Let padding be Space times paddingCount Let line be padding plus l plus padding Say line Else Let internalSpaceSize be lidx times 2 minus 1 Let filler be Space times internalSpaceSize Let totalOuterPaddingSize be width minus 2, internalSpaceSize Let paddingSize be totalOuterPaddingSize over 2 Let padding be Space times paddingSize Let line be padding plus l, filler, l, padding Say line Listen to input Let idx be GetIndex taking input Let width be idx times 2 plus 1 Let counter be 0 While counter is lower than idx Let l be GetLetter taking counter PrintLine taking width, l, counter Build counter up While counter is as high as 0 Let l be GetLetter taking counter PrintLine taking width, l, counter Knock counter down
This prototype only handled the input letters A, B, and C, but it was enough to verify that the algorithm worked. I've done the diamond kata several times before, so I only had to find the most imperative implementation on my hard drive. It wasn't too hard to translate to Rockstar.
Although Rockstar supports mainstream quoted strings like "A", "B", and so on, you can see that I went straight for poetic string literals. Before I started persisting Rockstar code to a file, I experimented with the language using the online interpreter. I wanted the program to look as much like rock lyrics as I could, so I didn't want to have too many statements like Shout "FizzBuzz!" in my code.
Obscuring space #
My first concern was whether I could obscure the space character. Using a poetic string literal, I could:
Space says
The rules of poetic string literals is that everything between says and the newline character becomes the value of the string variable. So there's an extra space after says !
After I renamed all the variables and functions, that line became:
Your memory says
Perhaps it isn't an unprintable character, but it is unsingable.
No else #
The keyword Else looks conspicuously like a programming construct, so I wanted to get rid of that as well. That was easy, because I could just invert the initial if condition:
If l ain't LetterA
This effectively switches between the two alternative code blocks.
Obscuring letter indices #
I also wanted to obscure the incrementing index values 1, 2, 3, etcetera. Since the indices are monotonically increasing, I realised that I could use a counter and increment it:
number is 0 If index is number Let retVal be LetterA Build number up If index is number retVal says B Build number up If index is number retVal says C
The function initialises number to 0 and assigns a value to retVal if the input index is also 0.
If not, it increments the number (so that it's now 1) and again compares it to index. This sufficiently obscures the indices, but if there's a way to hide the letters of the alphabet, I'm not aware of it.
After I renamed the variables, the code became:
Your courage is a tightrope Let it be without it If your hope is your courage Let the key be the way Build your courage up If your hope is your courage The key says B Build your courage up If your hope is your courage The key says C
There's one more line of code in the final lyrics, compared to the above snippet. The line Let it be without it has no corresponding line of code in the readable version. What's going on?
Obscuring numbers #
Like poetic string literals, Rockstar also supports poetic number literals. Due to its modulo-ten-based system, however, I found it difficult to come up with a good ten-letter word that fit the song's lyrical theme. I could have done something like this to produce the number 0:
Your courage is barbershop
or some other ten-letter word. My problem was that regardless of what I chose, it didn't sound good. Some article like a or the would sound better, but that would change the value of the poetic number literal. a tightrope is the number 19, because a has one letter, and tightrope has nine.
There's a simple way to produce 0 from any number: just subtract the number from itself. That's what Let it be without it does. I could also have written it as Let your courage be without your courage, but I chose to take advantage of Rockstar's pronoun feature instead. I'd been looking for an opportunity to include the phrase Let It Be ever since I learned about the Let x be y syntax.
The following code snippet initialises the variable Your courage to 19, but on the next line subtracts 19 from 19 and updates the variable so that its value is now 0.
Your courage is a tightrope Let it be without it
I had the same problem with initialising the numbers 1 and 2, so further down I resorted to similar tricks:
Raindrop is a wintercrop Light is a misanthrope Let it be without raindrop Darkness is a kaleidoscope Let it be without raindrop
Here I had the additional constraint that I wanted the words to rhyme. The rhymes are a continuation of the previous lines' up and hope, so I struggled to come up with a ten-letter word that rhymes with up; wintercrop was the best I could do. a wintercrop is 10, and the strategy is to define Light and Darkness as 11 and 12, and then subtract 10 from both. At the first occurrence of Let it be without raindrop, it refers to Light, whereas the second time it refers to Darkness.
Lyrical theme #
Once I had figured out how to obscure strings and numbers, it was time to rename all the readable variables and function names into idiomatic Rockstar.
At first, I thought that I'd pattern my lyrics after Shine On You Crazy Diamond, but I soon ran into problems with the keyword taking. I found it difficult to find words that would naturally succeed taking. Some options I thought of were:
- taking the bus
- taking a chance
- taking hold
- taking flight
- taking time
times is a keyword, and apparently time is reserved as well. At least, the online interpreter choked on it.
Taking a chance sounded too much like ABBA. Taking hold created the derived problem that I had to initialise and use a variable called hold, and I couldn't make that work.
Taking flight, on the other hand, turned out to provide a fertile opening.
I soon realised, though, that my choice of words pulled the lyrical theme away from idiomatic Rockstar vocabulary. While I do get the Tommy and Gina references, I didn't feel at home in that poetic universe.
On the other hand, I thought that the words started to sound like Yes. I've listened to a lot of Yes. The lyrics are the same kind of lame and vapid as what was taking form in my editor. I decided to go in that direction.
Granted, this is no longer idiomatic Rockstar, since it's more prog rock than hair metal. I invoke creative license.
Soon I also conceived of the extra ambition that I wanted the verses to rhyme. Here, it proved fortunate that the form let x be y is interchangeable with the form put y into x. Some words, like darkness, are difficult to rhyme with, so it helps that you can hide them within a put y into x form.
Over the hours(!) I worked on this, a theme started to emerge. I'm particularly fond of the repeated motifs like:
Your hope's start'n'stop
which rhymes with up, but then later it appears again as
Your hope's stop'n'start
which rhymes with heart. Both words, by the way, represent the number 0, since there's ten letters when you ignore the single quotes.
Conclusion #
I spent more time on this that I suppose I ought to, but once I got started, it was hard to stop. I found the translation from readable code into 'idiomatic' Rockstar at least as difficult as writing working software. There's a lesson there, I believe.
Rockstar is still a budding language, so I did miss a few features, chief among which would be arrays, but I'm not sure how one would make arrays sufficiently rock'n'roll.
A unit testing framework would also be nice.
If you liked this article, please endorse my Rockstar skills on LinkedIn so that we can "confuse recruiters."
The 80/24 rule
Write small blocks of code. How small? Here's how small.
One of the most common questions I get is this:
If you could give just one advice to programmers, what would it be?
That's easy:
Write small blocks of code.
Small methods. Small functions. Small procedures.
How small?
Few lines of code #
You can't give a universally good answer to that question. Among other things, it depends on the programming language in question. Some languages are much denser than others. The densest language I've ever encountered is APL.
Most mainstream languages, however, seem to be verbose to approximately the same order of magnitude. My experience is mostly with C#, so I'll use that (and similar languages like Java) as a starting point.
When I write C# code, I become uncomfortable when my method size approaches fifteen or twenty lines of code. C# is, however, a fairly wordy language, so it sometimes happens that I have to allow a method to grow larger. My limit is probably somewhere around 25 lines of code.
That's an arbitrary number, but if I have to quote a number, it would be around that size. Since it's arbitrary anyway, let's make it 24, for reasons that I'll explain later.
The maximum line count of a C# (or Java, or JavaScript, etc.) method, then, should be 24.
To repeat the point from before, this depends on the language. I'd consider a 24-line Haskell or F# function to be so huge that if I received it as a pull request, I'd reject it on the grounds of size alone.
Narrow line width #
Most languages allow for flexibility in layout. For example, C-based languages use the ; character as a delimiter. This enables you to write more than one statement per line:
var foo = 32; var bar = foo + 10; Console.WriteLine(bar);
You could attempt to avoid the 24-line-height rule by writing wide lines. That would, however, be to defeat the purpose.
The purpose of writing small methods is to nudge yourself towards writing readable code; code that fits in your brain. The smaller, the better.
For completeness sake, let's institute a maximum line width as well. If there's any accepted industry standard for maximum line width, it's 80 characters. I've used that maximum for years, and it's a good maximum.
Like all other programmers, other people's code annoys me. The most common annoyance is that people write too wide code.
This is probably because most programmers have drunk the Cool Aid that bigger screens make you more productive. When you code on a big screen, you don't notice how wide your lines become.
There's many scenarios where wide code is problematic:
- When you're comparing changes to a file side-by-side. This often happens when you review pull requests. Now you have only half of your normal screen width.
- When you're looking at code on a smaller device.
- When you're getting old, or are otherwise visually impaired. After I turned 40, I discovered that I found it increasingly difficult to see small things. I still use a 10-point font for programming, but I foresee that this will not last much longer.
- When you're mob programming you're limited to the size of the shared screen.
- When you're sharing your screen via the web, for remote pair programming or similar.
- When you're presenting code at meetups, user groups, conferences, etc.

Notice the red dotted vertical line that cuts through universe. It tells me where the 80 character limit is.
Terminal box #
The 80-character limit has a long and venerable history, but what about the 24-line limit? While both are, ultimately, arbitrary, both fit the size of the popular VT100 terminal, which had a display resolution of 80x24 characters.
A box of 80x24 characters thus reproduces the size of an old terminal. Does this mean that I suggest that you should write programs on terminals? No, people always misunderstand this. That should be the maximum size of a method. On larger screens, you'd be able to see multiple small methods at once. For example, you could view a unit test and its target in a split screen configuration.
The exact sizes are arbitrary, but I think that there's something fundamentally right about such continuity with the past.
I've been using the 80-character mark as a soft limit for years. I tend to stay within it, but I occasionally decide to make my code a little wider. I haven't paid quite as much attention to the number of lines of my methods, but only for the reason that I know that I tend to write methods shorter than that. Both limits have served me well for years.
Example #
Consider this example:
public ActionResult Post(ReservationDto dto) { var validationMsg = Validator.Validate(dto); if (validationMsg != "") return BadRequest(validationMsg); var reservation = Mapper.Map(dto); var reservations = Repository.ReadReservations(reservation.Date); var accepted = maîtreD.CanAccept(reservations, reservation); if (!accepted) return StatusCode( StatusCodes.Status500InternalServerError, "Couldn't accept."); var id = Repository.Create(reservation); return Ok(id); }
This method is 18 lines long, which includes the method declaration, curly brackets and blank lines. It easily stays within the 80-character limit. Note that I've deliberately formatted the code so that it behaves. You can see it in this fragment:
return StatusCode( StatusCodes.Status500InternalServerError, "Couldn't accept.");
Most people write it like this:
return StatusCode(StatusCodes.Status500InternalServerError, "Couldn't accept.");
That doesn't look bad, but I've seen much worse examples.
Another key to writing small methods is to call other methods. The above Post method doesn't look like much, but significant functionality could be hiding behind Validator.Validate, Repository.ReadReservations, or maîtreD.CanAccept. I hope that you agree that each of these objects and methods are named well enough to give you an idea about their purpose.
Code that fits in your brain #
As I describe in my Humane Code video, the human brain can only keep track of about seven things. I think that this rule of thumb applies to the way we read and interpret code. If you need to understand and keep track of more than seven separate things at the same time, the code becomes harder to understand.
This could explain why small methods are good. They're only good, however, if they're self-contained. When you look at a method like the above Post method, you'll be most effective if you don't need to have a deep understanding of how each of the dependencies work. If this is true, the method only juggles about five dependencies: Validator, Mapper, Repository, maîtreD, and its own base class (which provides the methods BadRequest, StatusCode, and Ok). Five dependencies is fewer than seven.
Another way to evaluate the cognitive load of a method is to measure its cyclomatic complexity. The Post method's cyclomatic complexity is 3, so that should be easily within the brain's capacity.
These are all heuristics, so read this for inspiration, not as law. They've served me well for years, though.
Conclusion #
You've probably heard about the 80/20 rule, also known as the Pareto principle. Perhaps the title lead you to believe that this article was a misunderstanding. I admit that I went for an arresting title; perhaps a more proper name is the 80x24 rule.
The exact numbers can vary, but I've found a maximum method size of 80x24 characters to work well for C#.
Comments
As a matter of fact, terminals had 80 characters lines, because IBM punch cards, representing only 1 line, had 80 symbols (even though only the first 72 were used at first). However, I don't know why terminals settled for 24 lines! In Java, which is similar to C# in term of verbosity, Clean Code tend to push towards 20-lines long functions or less. One of the danger to make functions even smaller is that many more functions can create many indirections, and that becomes harder to keep track within our brains.
{kind=link}
Some additional terminal sizing history in Mike Hoye's recent similarly-named post: http://exple.tive.org/blarg/2019/10/23/80x25/ Spoiler - Banknotes!

Comments
In your initial
intC# example, I think your point is that method arguments and the return type require manifest typing. Then for your example aboutlong(and comments aboutshort,decimal, andbyte), I think your point is that C#'s type system is primarily nominal. You then contrast those C# examples with F# and Haskell examples that utilize inferred and structural aspects of their type systems.I also sometimes get involved in debates about static versus dynamic typing and find myself on the side of static typing. Furthermore, I also typically hear arguments against manifest and nominal typing instead of against static typing. In theory, I agree with those arguments; I also prefer type systems that are inferred and structural instead of those that are manifest and nominal.
I see the tradeoff as being among the users of the programming language, those responsible for writing and maintaining the compiler/interpreter, and what can be said about the correctness of the code. (In the rest of this paragraph, all statements about things being simple or complex are meant to be relative. I will also exaggerate for the sake of simplifying my statements.) For a dynamic language, the interpreter and coding are simple but there are no guarantees about correctness. For a static, manifest, and nominal language, the compiler is somewhere between simple and complex, the coding is complex, but at least there are some guarantees about correctness. For a static, inferred, structural language, the compiler is complex, coding is simple, and there are some guarantees about correctness.
Contrasting a dynamic language with one that is static, inferred, and structural, I see the tradeoff as being directly between the the compiler/interpreter writers and what can be said about the correctness of the code while the experience of those writing code in the language is mostly unchanged. I think that is your point being made by contrasting the JavaScript example (a dynamic language) with the F# and Haskell examples (that demonstrate the static, inferred, and structural behavior of their type systems).
While we are on the topic, I would like to say something that I think is controversial about duck typing. I think duck typing is "just" a dynamic type system that is also structural. This contradicts the lead of its Wikipedia article (linked above) as well as the subsection about structural type systems. They both imply that nominal vs structural typing is a spectrum that only exists for static languages. I disagree; I think dynamic languages can also exist on that spectrum. It is just that most dynamic languages are also structural. In contrast, I think that the manifest vs inferred spectrum exists for static languages but not for dynamic languages.
Nonetheless, that subsection makes a great observation. For structural languages, the difference between static and dynamic languages is not just some guarantees about correctness. Dynamic languages check for type correctness at the last possible moment. (That is saying more than saying that the type check happens at runtime.) For example, consider a function with dead code that "doesn't type". If the type system were static, then this function cannot be executed, but if the type system were dynamic, then it could be executed. More practically, suppose the function is a simple
if-elsestatement with code in theelsebranch that "doesn't type" and that the corresponding Boolean expression always evaluates totrue. If the type system were static, then this function cannot be executed, but if the type system were dynamic, then it could be executed.In my experience, the typical solution of a functional programmer would be to strengthen the input types so that the
elsebranch can be proved by the compiler to be dead code and then delete the dead code. This approach makes this one function simpler, and I generally am in favor of this. However, there is a sense in which we can't always repeat this for the calling function. Otherwise, we would end up with a program that is provably correct, which is impossible for a Turning-complete language. Instead, I think the practical solution is to (at some appropriate level) short-circuit the computation when given input that is not known to be good and either do nothing or report back to the user that the input wasn't accepted.Using mostly both C# and TypeScript, two statically typed languages, I’ve experienced how it’s terser in TypeScript, essentially thanks to its type inference and its structural typing. I like the notion of “Ceremony” you gave to describe this and the fact that it’s not correlated to the kind of typing, dynamic or static 👍
Still, TypeScript is more verbose than F#, as we can see with the following code translation from F# to TypeScript using object literal instead of tuple for the better support of the former:
// const consume = (source: number[], quantity: number): number[] const consume = (source: number[], quantity: number) => source.reduce(({ acc, xs }, x) => quantity <= acc ? { acc, xs: xs.concat(x) } : { acc: acc + x, xs }, { acc: 0, xs: [] as number[] } ).xs;Checks:
As we can see, the code is a little more verbose than in JavaScript but still terser than in C#. The returned type is inferred as
number[]but theas number[]is a pity, necessary because the inferred type of the empty array[]isany[].consumeis not generic: TypeScript/JavaScript as only one primitive for numbers:number. It works for common scenarios but their no simple way to make it work withBigInt, for instance using the union typenumber | bigint. The more pragmatic option would be to copy-paste, replacingnumberwithbigintand0with0n.