ploeh blog danish software design
Song recommendations as an F# Impureim Sandwich
A pure function on potentially massive data.
This article is part of a larger article series titled Alternative ways to design with functional programming. In the previous article, you saw an example of applying the Impureim Sandwich pattern to the problem at hand: A song recommendation engine that sifts through much historical data.
As already covered in Song recommendations as an Impureim Sandwich, the drawback, if you will, of a Recawr Sandwich is that you need to collect all data from impure sources before you can pass it to a pure function. It may happen that you need so much data that this strategy becomes untenable. This may be the case here, but surprisingly often, what strikes us humans as being vast amounts are peanuts for computers.
So even if you don't find this particular example realistic, I'll forge ahead and show how to apply the Recawr Sandwich pattern to this problem. This is essentially a port to F# of the C# code from the previous article. If you rather want to see some more realistic architectures to deal with the overall problem, you can always go back to the table of contents in the first article of the series.
In this article, I'm working with the fsharp-pure-function branch of the Git repository.
Collecting all the data #
Like in the previous article, we may start by adding two more members to the SongService interface, which will enable us to enumerate all songs and all users. The full interface, with all four methods, then looks like this:
type SongService = abstract GetAllSongs : unit -> Task<IEnumerable<Song>> abstract GetAllUsers : unit -> Task<IEnumerable<User>> abstract GetTopListenersAsync : songId : int -> Task<IReadOnlyCollection<User>> abstract GetTopScrobblesAsync : userName : string -> Task<IReadOnlyCollection<Scrobble>>
If you compare with the interface definition shown in the article Porting song recommendations to F#, you'll see that GetAllSongs and GetAllUsers are the new methods.
They enable you to collect all top listeners, and all top scrobbles, even though it may take some time. To gather all the top listeners, we may add this collectAllTopListeners action:
let collectAllTopListeners (songService : SongService) = task { let d = Dictionary<int, IReadOnlyCollection<User>> () let! songs = songService.GetAllSongs () do! songs |> TaskSeq.iter (fun s -> task { let! topListeners = songService.GetTopListenersAsync s.Id d.Add (s.Id, topListeners) } ) return d :> IReadOnlyDictionary<_, _> }
Likewise, you can amass all the top scrobbles with a similar action:
let collectAllTopScrobbles (songService : SongService) = task { let d = Dictionary<string, IReadOnlyCollection<Scrobble>> () let! users = songService.GetAllUsers () do! users |> TaskSeq.iter (fun u -> task { let! topScrobbles = songService.GetTopScrobblesAsync u.UserName d.Add (u.UserName, topScrobbles) } ) return d :> IReadOnlyDictionary<_, _> }
As you may have noticed, they're so similar that, had there been more than two, we might consider extracting the similar parts to a reusable operation.
In both cases, we start with the action that enables us to enumerate all the resources (songs or scrobbles) that we're interested in. For each of these, we then invoke the action to get the 'top' resources for that song or scrobble. There's a massive n+1 problem here, but you could conceivably parallelize all these queries, as they're independent. Still, it's bound to take much time, possibly hours.
All the data is kept in a dictionary per action, so two massive dictionaries in all. Once these two actions return, we're done with the read phase of the Recawr Sandwich.
Traversals #
You may have wondered about the above TaskSeq.iter action. That's not part of the standard library. What is it, and where does it come from?
It's a specialized traversal, designed to make asynchronous Commands more streamlined.
let iter f xs = task { let! units = traverse f xs Seq.iter id units }
If you've ever wondered why the identity function (id) is useful, here's an example. In the first line of code, units is a unit seq value; i.e. a sequence of unit values. To make TaskSeq.iter as easy to use as possible, it should turn that multitude of unit values into a single unit value. There's more than one way to do that, but I found that using Seq.iter was about the most succinct option I could think of. Be that as it may, Seq.iter requires as an argument a function that returns unit, and since we already have unit values, id does the job.
The iter action uses the TaskSeq module's traverse function, which is defined like this:
let traverse f xs = let go acc x = task { let! x' = x let! acc' = acc return Seq.append acc' [x'] } xs |> Seq.map f |> Seq.fold go (task { return [] })
The type of traverse is ('a -> #Task<'c>) -> 'a seq -> Task<'c seq>; that is, it applies an asynchronous action to each of a sequence of 'a values, and returns an asynchronous workflow that contains a sequence of 'c values.
Dictionary lookups #
In .NET, queries that may fail are idiomatically modelled with methods that take out parameters. This is also true for dictionary lookups. Since that kind of design doesn't compose well, it's useful to add a little helper function that instead may return an empty value. While you'd generally do that by returning an option value, in this case, an empty collection is more appropriate.
let findOrEmpty key (d : IReadOnlyDictionary<_, IReadOnlyCollection<_>>) = match d.TryGetValue key with | true, v -> v | _ -> List.empty
You may have noticed that I also added a similar helper function in the C# example, although there I called it GetOrEmpty.
Pure function with local mutation #
As a first step, we may wish to turn the GetRecommendationsAsync method into a pure function. If you look through the commits in the Git repository, you can see that I actually did this through a series of micro-commits, but here I only present a more coarse-grained version of the changes I made.
Instead of a method on a class, we now have a self-contained function that takes, as arguments, two dictionaries, but no SongService dependency.
let getRecommendations topScrobbles topListeners userName = // 1. Get user's own top scrobbles // 2. Get other users who listened to the same songs // 3. Get top scrobbles of those users // 4. Aggregate the songs into recommendations let scrobbles = topScrobbles |> Dict.findOrEmpty userName let scrobblesSnapshot = scrobbles |> Seq.sortByDescending (fun s -> s.ScrobbleCount) |> Seq.truncate 100 |> Seq.toList let recommendationCandidates = ResizeArray () for scrobble in scrobblesSnapshot do let otherListeners = topListeners |> Dict.findOrEmpty scrobble.Song.Id let otherListenersSnapshot = otherListeners |> Seq.filter (fun u -> u.TotalScrobbleCount >= 10_000) |> Seq.sortByDescending (fun u -> u.TotalScrobbleCount) |> Seq.truncate 20 |> Seq.toList for otherListener in otherListenersSnapshot do let otherScrobbles = topScrobbles |> Dict.findOrEmpty otherListener.UserName let otherScrobblesSnapshot = otherScrobbles |> Seq.filter (fun s -> s.Song.IsVerifiedArtist) |> Seq.sortByDescending (fun s -> s.Song.Rating) |> Seq.truncate 10 |> Seq.toList otherScrobblesSnapshot |> List.map (fun s -> s.Song) |> recommendationCandidates.AddRange let recommendations = recommendationCandidates |> Seq.sortByDescending (fun s -> s.Rating) |> Seq.truncate 200 |> Seq.toList :> IReadOnlyCollection<_> recommendations
Since this is now a pure function, there's no need to run as an asynchronous workflow. The function no longer returns a Task, and I've also dispensed with the Async suffix.
The implementation still has imperative remnants. It initializes an empty ResizeArray (AKA List<T>), and loops through nested loops to repeatedly call AddRange.
Even though the function contains local state mutation, none of it escapes the function's scope. The function is referentially transparent because it always returns the same result when given the same input, and it has no side effects.
You might still wish that it was 'more functional', which is certainly possible.
A single expression #
A curious property of expression-based languages is that you can conceivably write functions in 'one line of code'. Granted, it would often be a terribly wide line, not at all readable, a beast to maintain, and often with poor performance, so not something you'd want to alway do.
In this case, however, we can do that, although in order to stay within an 80x24 box, we break the expression over multiple lines.
let getRecommendations topScrobbles topListeners userName = // 1. Get user's own top scrobbles // 2. Get other users who listened to the same songs // 3. Get top scrobbles of those users // 4. Aggregate the songs into recommendations topScrobbles |> Dict.findOrEmpty userName |> Seq.sortByDescending (fun s -> s.ScrobbleCount) |> Seq.truncate 100 |> Seq.collect (fun scrobble -> topListeners |> Dict.findOrEmpty scrobble.Song.Id |> Seq.filter (fun u -> u.TotalScrobbleCount >= 10_000) |> Seq.sortByDescending (fun u -> u.TotalScrobbleCount) |> Seq.truncate 20 |> Seq.collect (fun otherListener -> topScrobbles |> Dict.findOrEmpty otherListener.UserName |> Seq.filter (fun s -> s.Song.IsVerifiedArtist) |> Seq.sortByDescending (fun s -> s.Song.Rating) |> Seq.truncate 10 |> Seq.map (fun s -> s.Song))) |> Seq.sortByDescending (fun s -> s.Rating) |> Seq.truncate 200 |> Seq.toList :> IReadOnlyCollection<_>
To be honest, the four lines of comments push the function definition over the edge of 24 lines of code, but without them, this variation actually does fit an 80x24 box. Even so, I'm not arguing that this is the best possible way to organize and lay out this function.
You may rightly complain that it's too dense. Perhaps you're also concerned about the arrow code tendency.
I'm not disagreeing, but at least this represents a milestone where the function is not only referentially transparent, but also implemented without local mutation. Not that that really should be the most important criterion, but once you have an entirely expression-based implementation, it's usually easier to break it up into smaller building blocks.
Composition from smaller functions #
To improve readability and maintainability, we may now extract helper functions. The first one easily suggests itself.
let private getUsersOwnTopScrobbles topScrobbles userName = topScrobbles |> Dict.findOrEmpty userName |> Seq.sortByDescending (fun s -> s.ScrobbleCount) |> Seq.truncate 100
Each of the subexpressions in the above code listing are candidates for the same kind of treatment, like this one:
let private getOtherUsersWhoListenedToTheSameSongs topListeners scrobble = topListeners |> Dict.findOrEmpty scrobble.Song.Id |> Seq.filter (fun u -> u.TotalScrobbleCount >= 10_000) |> Seq.sortByDescending (fun u -> u.TotalScrobbleCount) |> Seq.truncate 20
Notice that these helper methods are marked private so that they remain implementation details within the module that exports the getRecommendations function.
With a few more helper functions, you can now implement the getRecommendations function by composing the helpers.
let getRecommendations topScrobbles topListeners = getUsersOwnTopScrobbles topScrobbles >> Seq.collect ( getOtherUsersWhoListenedToTheSameSongs topListeners >> Seq.collect (getTopSongsOfOtherUser topScrobbles)) >> aggregateSongsIntoRecommendations
Notice that I've named each of the helper functions after the code comments that accompanied the previous incarnations of this function. If we consider code comments apologies for not properly organizing the code, we've now managed to structure it in such a way that those apologies are no longer required.
Conclusion #
If you accept the (perhaps preposterous) assumption that it's possible to fit the required data in persistent data structures, refactoring the recommendation algorithm to a pure function isn't that difficult. That's the pure part of a Recawr Sandwich. While I haven't shown the actual sandwich here, it's identical to the example shown in Song recommendations as a C# Impureim Sandwich.
I find the final incarnation of the code shown here to be quite attractive. While I've kept the helper functions private, it's always an option to promote them to public functions if you find that warranted. This could improve testability of the overall code base, albeit at the risk of increasing the surface area of the API that you have to maintain and secure.
There are always trade-offs to be considered. Even if you, eventually, find that for this particular example, the input data size is just too big to make this alternative viable, there are, in my experience, many other situations when this kind of architecture is a good solution. Even if the input size is a decent amount of megabytes, the simplification offered by an Impureim Sandwich may trump the larger memory footprint. As always, if you're concerned about performance, measure it.
Before we turn to alternative architectures, we'll survey how this variation looks in Haskell. As is generally the case in this article series, if you don't care about Haskell, you can always go back to the table of contents in the first article in the series and instead navigate to the next article that interests you.
Song recommendations proof-of-concept memory measurements
An attempt at measurement, and some results.
This is an article in a larger series about functional programming design alternatives, and a direct continuation of the previous article. The question lingering after the Impureim Sandwich proof of concept is: What are the memory requirements of front-loading all users, songs, and scrobbles?
One can guess, as I've already done, but it's safer to measure. In this article, you'll find a description of the experiment, as well as some results.
Test program #
Since I don't measure application memory profiles that often, I searched the web to learn how, and found this answer by Jon Skeet. That's a reputable source, so I'm assuming that the described approach is appropriate.
I added a new command-line executable to the source code and made this the entry point:
const int size = 100_000; static async Task Main() { var before = GC.GetTotalMemory(true); var (listeners, scrobbles) = await Populate(); var after = GC.GetTotalMemory(true); var diff = after - before; Console.WriteLine("Total memory: {0:N0}B.", diff); GC.KeepAlive(listeners); GC.KeepAlive(scrobbles); }
listeners and scrobbles are two dictionaries of data, as described in the previous article. Together, they contain the data that we measure. Both are populated by this method:
private static async Task<( IReadOnlyDictionary<int, IReadOnlyCollection<User>>, IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>>)> Populate() { var service = PopulateService(); var listeners = await service.CollectAllTopListeners(); var scrobbles = await service.CollectAllTopScrobbles(); return (listeners, scrobbles); }
The service variable is a FakeSongService object populated with randomly generated data. The CollectAllTopListeners and CollectAllTopScrobbles methods are the same as described in the previous article. When the method returns the two dictionaries, the service object goes out of scope and can be garbage-collected. When the program measures the memory load, it measures the size of the two dictionaries, but not service.
I've reused the FsCheck generators for random data generation:
private static SongService PopulateService() { var users = RecommendationsProviderTests.Gen.UserName.Sample(size); var songs = RecommendationsProviderTests.Gen.Song.Sample(size); var scrobbleGen = from user in Gen.Elements(users) from song in Gen.Elements(songs) from scrobbleCount in Gen.Choose(1, 10) select (user, song, scrobbleCount); var service = new FakeSongService(); foreach (var (user, song, scrobbleCount) in scrobbleGen.Sample(size)) service.Scrobble(user, song, scrobbleCount); return service; }
A Gen<T> object comes with a Sample method you can use to request a specified number of randomly generated values.
In order to keep the code simple, I used the size value for both the number of songs, number of users, and number of scrobbles. This probably creates too few scrobbles; a topic that requires further discussion later.
Measurements #
I ran the above program with various size values; 100,000 up to 1,000,000 in 100,000 increments, and from there up to 1,000,000 (one million) in 500,000 increments. At the higher values, it took a good ten minutes to run the program.
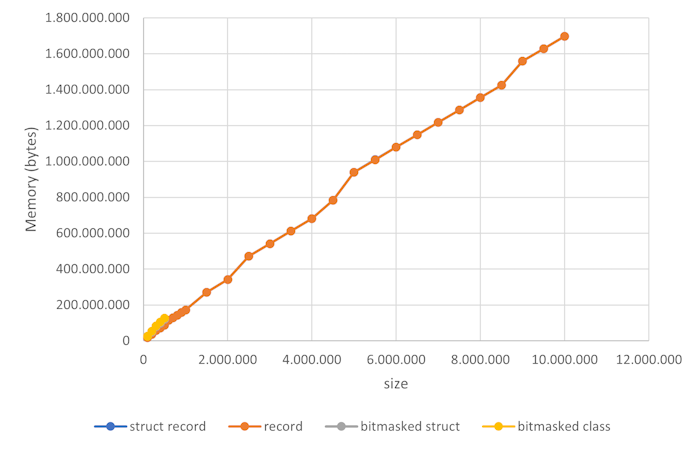
As the chart indicates, I ran the program with various data representations (more on that below). While there are four distinct data series, they overlap pairwise so perfectly that the graph doesn't show the difference. The record and struct record data series are so identical that you can't visibly see the difference. The same is true for the bitmasked class and the bitmasked struct data series, which only go to size 500,000.
There are small, but noticeable jumps from 4,500,000 to 5,000,000 and again from 8,500,000 to 9,000,000, but the overall impression is that the relationship is linear. It seems safe to conclude that the solution scales linearly with the data size.
The number of bytes per size is almost constant and averages to 178 bytes. How does that compare to my previous memory size estimates? There, I estimated a song and a scrobble to require 8 bytes each, and a user less than 32 bytes. The way the above simulation runs, it generates one song, one user, and one scrobble per size unit. Therefore, I'd expect the average memory cost per experiment size to be around 8 + 8 + 32 = 48, plus some overhead from the dictionaries.
Given that the number I measure is 178, that's 130 bytes of overhead. Honestly, that's more than I expected. I expect a dictionary to maintain an array of keys, perhaps hashed with a bucket per hash value. Perhaps, had I picked another data structure than a plain old Dictionary, it's possible that the overhead would be different. Or perhaps I just don't understand .NET's memory model, when push comes to shove.
I then tried to split the single size parameter into three that would control the number of users, songs, and scrobbles independently. Setting both the number of users and songs to ten million, I then ran a series of simulations with increasing scrobble counts.
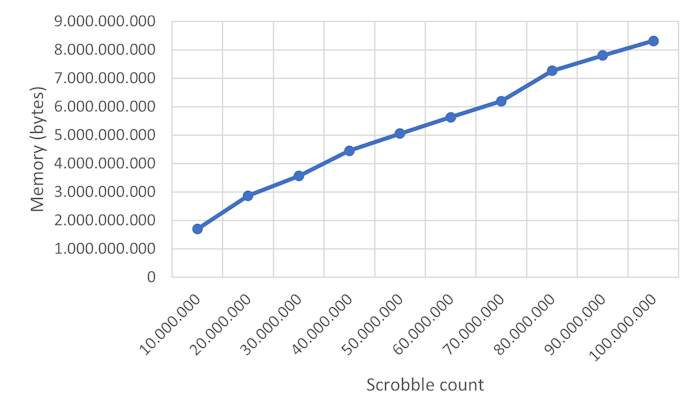
The relationship still looks linear, and at a hundred million scrobbles (and ten million users and ten million songs), the simulation uses 8.3 GB of memory.
I admit that I'm still a bit puzzled by the measurements, compared to my previous estimates. I would have expected those sizes to require about 1,2 GB, plus overhead, so the actual measurements are off by a factor of 7. Not quite an order of magnitude, but close.
Realism #
How useful are these measurements? How realistic are the experiments' parameters? Most streaming audio services report having catalogues with around 100 million songs, which is ten times more than what I've measured here. Such services may also have significantly more users than ten million, but what is going to make or break this architecture option (keeping all data in memory) is how many scrobbles users have, and how many times they listen to each song.
Even if we naively still believe that a scrobble only takes up 8 bytes, it doesn't follow automatically that 100 scrobbles take up 800 bytes. It depends on how many repeats there are. Recall how we may model a scrobble:
public sealed record Scrobble(Song Song, int ScrobbleCount);
If a user listens to the same song ten times, we don't have to create ten Scrobble objects; we can create one and set the ScrobbleCount to 10.
The memory requirement to store users' scrobbles depend on the average listening pattern. Even with millions of users, we may be able to store scrobbles in memory if users listen to relatively few songs. On the other hand, if they only listen to each song once, it's probably not going to fit in memory.
Still, we're dangerously close to the edge of what we can fit in memory. Shouldn't I just declare bankruptcy on that idea and move on?
The purpose of this overall article series is to demonstrate alternatives to the Impureim Sandwich pattern, so I'm ultimately going to do exactly that: Move on.
But not yet.
Sharding #
Some applications are truly global in nature, and when that's the case, keeping everything in memory may not be 'web scale'.
Still, I've seen more than one international company treat geographic areas as separate entities. This may be for legal reasons, or other business concerns that are unrelated to technology constraints.
As a programmer, you may think that a song recommendations service ought to be truly global. After all, more data produces more accurate results, right?
Your business owners may not think so. They may be concerned that regional music tastes may 'bleed over' market boundaries, and that this could ultimately scare customers away.
Even if you can technically prove that this isn't a relevant concern, because you can write an algorithm that takes this into account, you may get a direct order that, say, Southeast Asian scrobbles may not be used in North America, or vice verse.
It's worth investigating whether such business or legal constraints are already in place, because if they are, this may mean that you can shard the data, and that each shard still fits in memory.
You may still think that I'm trying to salvage a bad idea, but that's not my agenda. I discuss these topics because in my experience, many programmers don't consider them. Understanding the wider context of a problem may suggest solutions that you might otherwise dismiss.
But what if the business constraints change in the future? Shouldn't we be ready for that?
Yes and no. You should consider how such changes would impact the architecture. Then you discuss the advantages and disadvantages with other stakeholders.
Keep in mind that the reason to consider an Impureim Sandwich is because it's simple and easy to implement and maintain. Other alternatives may be more 'scalable', but also riskier to implement. You should involve other stakeholders in such decisions.
Song representations #
The first of the above charts draws graphs for four data series:
- struct record
- record
- bitmasked struct
- bitmasked class
These measure four different ways to model data; here more specifically a song.
My initial model of a song was a record:
public sealed record Song(int Id, bool IsVerifiedArtist, byte Rating);
Then I thought that perhaps, since the type only contains value types, it might be better to turn the above record into a record struct:
public record struct Song(int Id, bool IsVerifiedArtist, byte Rating);
It turns out that it makes no visible difference. In the chart, the two data series are so close to each other that you can't distinguish them.
Then I thought that instead of an int, a bool, and a byte, I could use a single bitmask to model all three values.
After all, I was only guessing when it came to data types anyway. It's likely that Rating is only a five-point or ten-point scale, but I still used a byte to model it. This suggests that I'm not using 96% of the data type's range. Perhaps I could use one of those redundant bits for IsVerifiedArtist, instead of an entire bool.
Taking this further, modelling the Id as an int suggests that you may have 4,294,967,295 unique songs. That's 4.3 billion songs - at least an order of magnitude more than those 100 million songs that we hear about. In reality though, most systems that use int for IDs only do so because int is CLS-compliant, and uint is not. In other words, most systems that use int for IDs most likely only use the positive half, which means there are 16 bytes to use for other purposes. Enter the bitmasked song:
public readonly struct Song { private const uint idMask = 0b0000_0111_1111_1111_1111_1111_1111_1111; private const uint isVerifiedArtistMask = 0b1000_0000_0000_0000_0000_0000_0000_0000; private const uint ratingMask = 0b0111_1000_0000_0000_0000_0000_0000_0000; private readonly uint bits; public Song(int id, bool isVerifiedArtist, byte rating) { var idBits = (uint)id & idMask; var isVerifiedArtistBits = isVerifiedArtist ? isVerifiedArtistMask : 0u; var ratingBits = ((uint)rating << 27) & ratingMask; bits = idBits | isVerifiedArtistBits | ratingBits; } public int Id => (int)(bits & idMask); public bool IsVerifiedArtist => (bits & isVerifiedArtistMask) == isVerifiedArtistMask; public byte Rating => (byte)((bits & ratingMask) >> 27); }
In this representation, I've set aside the lower 27 bits for the ID, enabling IDs to range between 0 and 134,217,727. The top bit is used for IsVerifiedArtist, and the remaining four bits for Rating.
This data structure only holds a single uint, and since I made it a struct, I thought it'd have minimal overhead.
As you can see in the above chart, that's not the case. When I run the experiment, this representation requires more memory.
Just to make sure I wasn't missing anything obvious, I tried making the bitmasked Song a class instead. No visible difference.
If you're wondering why the bitmasked data series only go to 500,000, it's because this change made the experiments glacial. It took somewhere between 12 and 24 hours to run the experiment with a size of 500,000.
For what it's worth, I don't think the slowdown is directly related to the data representation, but rather to the change I had to make to the FsCheck-based data generator:
let songParams = gen { let maxId = 0b0111_1111_1111_1111_1111_1111_1111 let! songId = Gen.choose (1, maxId) let! isVerified = ArbMap.generate ArbMap.defaults let! rating = Gen.choose (0, 10) |> Gen.map byte return songId, isVerified, rating } [<CompiledName "Song">] let song = gen { let! (id, isVerifiedArtist, rating) = songParams return Song (id, isVerifiedArtist, rating) }
I can't explain why the bitmasked representation requires more memory, but I'm increasingly having a nagging feeling that I've made a mistake somewhere. If you can spot a mistake, please let me know by leaving a comment.
Other data representations #
I also considered whether it'd make sense to represent the entire data set as a huge matrix. One could, for example, let rows represent users, and columns songs, and let each element represent the number of times a user has listened to a particular song:
| User | Song 1 | Song 2 | Song 3 | ... |
| 123 | 0 | 0 | 4 | ... |
| 456 | 2 | 0 | 4 | ... |
| ... | ||||
Let's say that you may expect some users to listen to a song more than 255 times, but probably not more than 65,535 times. Thus, you could store each play count as a ushort. Still, you would need users x songs values, so if you have 100 million songs and 10 million users, that implies 2 PB of memory. That doesn't sound useful.
On the other hand, most of those elements are going to be 0, so perhaps one could use an adjacency list instead. That is, however, essentially what an IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>> is, so we're now back where we started.
Conclusion #
This article reports on some measurements I've made of memory requirements, assuming that we keep all scrobble data in memory. While I suspect that I've made a mistake, it still seems reasonable to conclude that the song recommendations scenario is on the edge of what's possible with the Impureim Sandwich pattern.
That's okay. I'm interested in understanding the limitations of solutions.
I do think, however, that it's worth taking note of just how massive amounts of data are required before the Impureim Sandwich pattern becomes untenable.
When I describe the pattern, the most common reaction is that it doesn't scale. And, as this article has explored, it's true that it doesn't scale. But it scales much, much better than you think. You may have billions of entities in your system, and they may still fit in a few gigabytes. Don't dismiss the Impureim Sandwich before you've made a real effort to understand the memory implications of it. Your intuition is likely to work against you.
I'll round off this part of the article series by showing how the Impureim Sandwich looks in other, more functional languages.
Song recommendations as a C# Impureim Sandwich
A refactoring example.
This is an article in a larger series about functional programming design alternatives. I'm assuming that you've read the previous articles, but briefly told, I'm considering an example presented by Oleksii Holub in the article Pure-Impure Segregation Principle. The example gathers song recommendations for a user in a long-running process.
In the previous article I argued that while the memory requirements for this problem seem so vast that an Impureim Sandwich appears out of the question, it's nonetheless worthwhile to at least try it out. The refactoring isn't that difficult, and it turns out that it does simplify the code.
Enumeration API #
The data access API is a web service:
"I don't own the database, those are requests to an external API service (think Spotify API) that provides the data."
In order to read all data, we'll have to assume that there's a way to enumerate all songs and all users. With that assumption, I add the GetAllSongs and GetAllUsers methods to the SongService interface:
public interface SongService { Task<IEnumerable<Song>> GetAllSongs(); Task<IEnumerable<User>> GetAllUsers(); Task<IReadOnlyCollection<User>> GetTopListenersAsync(int songId); Task<IReadOnlyCollection<Scrobble>> GetTopScrobblesAsync(string userName); }
It is, of course, a crucial assumption, and it's possible that no such API exists. On the other hand, a REST API could expose such functionality as a paged feed. Leafing through potentially hundreds (or thousands) such pages is bound to take some time, so it's good to know that this is a background process. As I briefly mentioned in the previous article, we could imagine that we have a dedicated indexing server for this kind purpose. While we may rightly expect the initial data load to take some time (hours, even), once it's in memory, we should be able to reuse it to calculate song recommendations for all users, instead of just one user.
In the previous article I estimated that it should be possible to keep all songs in memory with less than a gigabyte. Users, without scrobbles, also take up surprisingly little space, to the degree that a million users fit in a few dozen megabytes. Even if, eventually, we may be concerned about memory, we don't have to be concerned about this part.
In any case, the addition of these two new methods doesn't break the existing example code, although I did have to implement the method in the FakeSongService class that I introduced in the article Characterising song recommendations:
public Task<IEnumerable<Song>> GetAllSongs() { return Task.FromResult<IEnumerable<Song>>(songs.Values); } public Task<IEnumerable<User>> GetAllUsers() { return Task.FromResult(users.Select(kvp => new User(kvp.Key, kvp.Value.Values.Sum()))); }
With those additions, we can load all data as the first layer (phase, really) of the sandwich.
Front-loading the data #
Loading all the data is the responsibility of this DataCollector module:
public static class DataCollector { public static async Task<IReadOnlyDictionary<int, IReadOnlyCollection<User>>> CollectAllTopListeners(this SongService songService) { var dict = new Dictionary<int, IReadOnlyCollection<User>>(); foreach (var song in await songService.GetAllSongs()) { var topListeners = await songService.GetTopListenersAsync(song.Id); dict.Add(song.Id, topListeners); } return dict; } public static async Task<IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>>> CollectAllTopScrobbles(this SongService songService) { var dict = new Dictionary<string, IReadOnlyCollection<Scrobble>>(); foreach (var user in await songService.GetAllUsers()) { var topScrobbles = await songService.GetTopScrobblesAsync(user.UserName); dict.Add(user.UserName, topScrobbles); } return dict; } }
These two methods work with any SongService implementation, so while the code base will work with FakeSongService, real 'production code' might as well use an HTTP-based implementation that pages through the implied web API.
The dictionaries returned by the methods are likely to be huge. That's a major point of this exercise. Once the change is implemented and Characterisation Tests show that it still works, it makes sense to generate data to get a sense of the memory footprint.
Table-driven methods #
Perhaps you wonder why the above CollectAllTopListeners and CollectAllTopScrobbles methods return dictionaries of exactly that shape.
Code Complete describes a programming technique called table-driven methods. The idea is to replace branching instructions such as if, else, and switch with a lookup table. The overall point, however, is that you can replace function calls with table lookups.
Consider the GetTopListenersAsync method. It takes an int as input, and returns a Task<IReadOnlyCollection<User>>
as output. If you ignore the Task, that's an IReadOnlyCollection<User>. In other words, you can exchange an int for an IReadOnlyCollection<User>.
If you have an IReadOnlyDictionary<int, IReadOnlyCollection<User>> you can also exchange an int for an IReadOnlyCollection<User>. These two APIs are functionally equivalent - although, of course, they have very different memory and run-time profiles.
The same goes for the GetTopScrobblesAsync method: It takes a string as input and returns an IReadOnlyCollection<Scrobble> as output (if you ignore the Task). An IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>> is equivalent.
To make it practical, it turns out that we also need a little helper method to deal with the case where the dictionary has no entry for a given key:
internal static IReadOnlyCollection<T> GetOrEmpty<T, TKey>( this IReadOnlyDictionary<TKey, IReadOnlyCollection<T>> dict, TKey key) { if (dict.TryGetValue(key, out var result)) return result; return Array.Empty<T>(); }
If there's no entry for a key, this function instead returns an empty array.
That should make it as easy as possible to replace calls to GetTopListenersAsync and GetTopScrobblesAsync with dictionary lookups.
Adding method parameters #
When refactoring, it's a good idea to proceed in small, controlled steps. You can see each of my micro-commits in the Git repository's refactor-to-function branch. Here, I'll give an overview.
First, I added two dictionaries as parameters to the GetRecommendationsAsync method. You may recall that the method used to look like this:
public async Task<IReadOnlyList<Song>> GetRecommendationsAsync(string userName)
After I added the two dictionaries, it looks like this:
public async Task<IReadOnlyList<Song>> GetRecommendationsAsync( string userName, IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>> topScrobbles, IReadOnlyDictionary<int, IReadOnlyCollection<User>> topListeners)
At this point, the GetRecommendationsAsync method uses neither the topScrobbles nor the topListeners parameter. Still, I consider this a distinct checkpoint that I commit to Git. As I've outlined in my book Code That Fits in Your Head, it's safest to either refactor production code while keeping test code untouched, or refactor test code without editing the production code. An API change like the current is an example of a situation where that separation is impossible. This is the reason I want to keep it small and isolated. While the change does touch both production code and test code, I'm not editing the behaviour of the System Under Test.
Tests now look like this:
[<Property>] let ``No data`` () = Gen.userName |> Arb.fromGen |> Prop.forAll <| fun userName -> task { let srvc = FakeSongService () let sut = RecommendationsProvider srvc let! topScrobbles = DataCollector.CollectAllTopScrobbles srvc let! topListeners = DataCollector.CollectAllTopListeners srvc let! actual = sut.GetRecommendationsAsync (userName, topScrobbles, topListeners) Assert.Empty actual } :> Task
The test now uses the DataCollector to front-load data into dictionaries that it then passes to GetRecommendationsAsync. Keep in mind that GetRecommendationsAsync doesn't yet use that data, but it's available to it once I make a change to that effect.
You may wish to compare this version of the No data test with the previous version shown in the article Characterising song recommendations.
Refactoring to function #
The code is now ready for refactoring from dependency injection to dependency rejection. It's even possible to do it one method call at a time, because the data in the FakeSongService is the same as the data in the two dictionaries. It's just two different representations of the same data.
Since, as described above, the dictionaries are equivalent to the SongService queries, each is easily replaced with the other. The first impure action in GetRecommendationsAsync, for example, is this one:
var scrobbles = await _songService.GetTopScrobblesAsync(userName);
The equivalent dictionary lookup enables us to change that line of code to this:
var scrobbles = topScrobbles.GetOrEmpty(userName);
Notice that the dictionary lookup is a pure function that the method need not await.
Even though the rest of GetRecommendationsAsync still queries the injected SongService, all tests pass, and I can commit this small, isolated change to Git.
Proceeding in a similar fashion enables us to eliminate the SongService queries one by one. There are only three method calls, so this can be done in three controlled steps. Once the last impure query has been replaced, the C# compiler complains about the async keyword in the declaration of the GetRecommendationsAsync method.
Not only is the async keyword no longer required, the method is no longer asynchronous. There's no reason to return a Task, and the Async method name suffix is also misleading.
public IReadOnlyList<Song> GetRecommendations( string userName, IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>> topScrobbles, IReadOnlyDictionary<int, IReadOnlyCollection<User>> topListeners)
The GetRecommendations method no longer uses the injected SongService, and since it's is the only method of the RecommendationsProvider class, we can now (r)eject the dependency.
This furthermore means that the class no longer has any class fields; we might as well make it (and the GetRecommendations function) static. Here's the final function in its entirety:
public static IReadOnlyList<Song> GetRecommendations( string userName, IReadOnlyDictionary<string, IReadOnlyCollection<Scrobble>> topScrobbles, IReadOnlyDictionary<int, IReadOnlyCollection<User>> topListeners) { // 1. Get user's own top scrobbles // 2. Get other users who listened to the same songs // 3. Get top scrobbles of those users // 4. Aggregate the songs into recommendations var scrobbles = topScrobbles.GetOrEmpty(userName); var scrobblesSnapshot = scrobbles .OrderByDescending(s => s.ScrobbleCount) .Take(100) .ToArray(); var recommendationCandidates = new List<Song>(); foreach (var scrobble in scrobblesSnapshot) { var otherListeners = topListeners.GetOrEmpty(scrobble.Song.Id); var otherListenersSnapshot = otherListeners .Where(u => u.TotalScrobbleCount >= 10_000) .OrderByDescending(u => u.TotalScrobbleCount) .Take(20) .ToArray(); foreach (var otherListener in otherListenersSnapshot) { var otherScrobbles = topScrobbles.GetOrEmpty(otherListener.UserName); var otherScrobblesSnapshot = otherScrobbles .Where(s => s.Song.IsVerifiedArtist) .OrderByDescending(s => s.Song.Rating) .Take(10) .ToArray(); recommendationCandidates.AddRange( otherScrobblesSnapshot.Select(s => s.Song) ); } } var recommendations = recommendationCandidates .OrderByDescending(s => s.Rating) .Take(200) .ToArray(); return recommendations; }
The overall structure is similar to the original version. Now that the code is simpler (because there's no longer any asynchrony) you could keep refactoring. With this C# code example, I'm going to stop here, but when I port it to F# I'm going to refactor more aggressively.
Sandwich #
One point of the whole exercise is to demonstrate how to refactor to an Impureim Sandwich. The GetRecommendations method shown above constitutes the pure filling of the sandwich, but what does the entire sandwich look like?
In this code base, the sandwiches only exist as unit tests, the simplest of which is still the No data test:
[<Property>] let ``No data`` () = Gen.userName |> Arb.fromGen |> Prop.forAll <| fun user -> task { let srvc = FakeSongService () let! topScrobbles = DataCollector.CollectAllTopScrobbles srvc let! topListeners = DataCollector.CollectAllTopListeners srvc let actual = RecommendationsProvider.GetRecommendations (user, topScrobbles, topListeners) Assert.Empty actual } :> Task
In the above code snippet, I've coloured in the relevant part of the test. I admit that it's a stretch to colour the last line red, since Assert.Empty is, at least, deterministic. One could argue that since it throws an exception on failure, it's not strictly free of side effects, but that's really a weak argument. It would be easy to refactor assertions to pure functions.
Instead, you may consider the bottom layer of the sandwich as a placeholder where something impure might happen. The background service that updates the song recommendations may, for example, save the result as a (CQRS-style) materialised view.
The above test snippet, then, is more of a sketch of how the Impureim Sandwich may look: First, front-load data using the DataCollector methods; second, call GetRecommendations; third, do something with the result.
Conclusion #
The changes demonstrated in this article serve two purposes. One is to show how to refactor an impure action to a pure function, pursuing the notion of an Impureim Sandwich. The second is to evaluate a proof-of-concept: If we do, indeed, front-load all of the data, is it realistic that all data fits in RAM?
We have yet to address that question, but since the present article is already substantial, I'll address that in a separate article.
Next: Song recommendations proof-of-concept memory measurements.Song recommendations as an Impureim Sandwich
Does your data fit in RAM?
This article is part of a series on functional programming design alternatives. In a previous article you saw how to add enough Characterisation Tests to capture the intended behaviour of the example song recommendations system originally presented by Oleksii Holub in the article Pure-Impure Segregation Principle.
Problem statement #
After showing how one problem can be refactored to pure functions, Oleksii Holub writes:
"Although very useful, the type of "lossless" refactoring shown earlier only works if the data required by the function can be easily encapsulated within its input parameters. Unfortunately, this is not always the case.
"Often a function may need to dynamically resolve data from an external API or a database, with no way of knowing about it beforehand. This typically results in an implementation where pure and impure concerns are interleaved with each other, creating a tightly coupled cohesive structure."
The article then proceeds to present the song recommendations example. It's a single C# method that queries a data store or third-party service to recommend songs. I'm imagining that it queries a third-party web service that contains usages data for a system like Spotify.
"The above algorithm works by retrieving the user's most listened songs, finding other people who have also listened to the same titles, and then extracting their top songs as well. Those songs are then aggregated into a list of recommendations and returned to the caller.
"It's quite clear that this function would benefit greatly from being pure, seeing how much business logic is encapsulated within it. Unfortunately, the technique we relied upon earlier won't work here.
"In order to fully isolate
GetRecommendationsAsync(...)from its impure dependencies, we would have to somehow supply the function with an entire list of songs, users, and their scrobbles upfront. If we assume that we're dealing with data on millions of users, it's obvious that this would be completely impractical and likely even impossible."
It does, indeed, sound impractical.
Data sizes #
Can you, however, trust your intuition? Research suggests that the human brain is ill-equipped to think about randomness and probabilities, and I've observed something similar when it comes to data sizes.

In the real world, a million of anything countable is an almost incomprehensible amount, so it's no wonder if our intuition fails us. A million records sounds like a lot, but if it's only a few integers, is it really that bad?
Many systems use 32-bit integers for various IDs. A million IDs, then, is 32 million bits, or approximately 4 MB. As I'm writing this, the smallest Azure instance (Free F1) has 1 GB of memory, and while the OS takes a big bite out of that, 4 MB is nothing.
The song recommendations problem implies larger memory pressure. It may not fit on every machine, but it's worth considering if, after all, it doesn't fit in RAM.
My real-life experience with developing streaming services #
It just so happens that I have professional experience developing REST APIs for a white-label audio streaming service. Back in the early 2010s I helped design and implement the company's online music catalogue, user system, and a few other services. The catalogue is particularly interesting in this regard, since it only changed nightly, and we were planning on relying on HTTP for caching.
I vividly recall a meeting we had with the IT operations specialist responsible for the new catalogue service. We explained that we'd set HTTP cache timeouts to 6 hours, and asked if he'd be able to set up a reverse proxy so that we didn't have to implement caching in our code base.
He asked how much cache space we needed.
We knew the size of a typical HTTP response, and the number of tracks, artists, and albums in the system, so after a back-of-the-envelope calculation, we told him: 18 GB.
He just shrugged and said "OK".
In 2012 I though that 18 GB was a fair amount of data (I actually still think that). Even so, the operations team had plenty of servers with that capacity.
Later, I did more work for that company, but most of it is less relevant to the song recommendations example. What does turn out to be relevant to the topic is something I learned the first few days of my engagement.
Early on, before I was involved, the company needed a recommendation system, but hadn't been able to find any off-the-shelf component. This was in the early 2000s and before Solr, but after Lucene. I'm not aware of all the forces that affected my then future client, but in the end, they decided to write their own search and recommendations engine.
Essentially, during the night a beefy server would read all relevant data from the database, crunch it, create data structures, and keep all data in memory. Like the reverse proxy, it required a server with more RAM than a normal pizza box, but not prohibitively so.
Costs #
Consider the cost of hardware, compared to developer time. A few specialised servers may set your organisation back a few thousand of dollars/pounds/euros. That's an amount you can easily burn through in salary if the code is too complicated, or has too many bugs.
You may argue that if you already have programmers on staff, they don't cost extra, but a too-complicated code base is still going to slow them down. Thus, the wrong software design could incur an opportunity cost greater than the cost of a server.
One of many reasons I'm interested in functional programming (FP) is its potential to make code bases simpler. The Impureim Sandwich is a wonderfully simple design, so it's worth pursuing; not only for some FP ideal, but because of its simplifying potential.
Intuition may tell us that the song recommendations scenario is prohibitively big, and therefore, an Impureim Sandwich is out of the question. As this overall article series explores, it's not the only alternative, but given its advantages, its worth giving it a second chance.
Analysis #
The GetRecommendationsAsync method from the example makes a lot of external calls, with its nested loops. The method uses the first call to GetTopScrobblesAsync to produce the scrobblesSnapshot variable, which is capped at 100 objects. If we assume that this method call returns at least 100 objects, the outer foreach loop will make 100 calls to GetTopListenersAsync.
If we again assume that each of these return enough data, the inner foreach loop will make 20 calls to GetTopScrobblesAsync, for each object in the outer loop. That's 2,000 external calls, plus the 100 calls in the outer loop, plus the initial call to GetTopScrobblesAsync, for a total of 2,101.
When I first saw the example, I didn't know much about the overall context. I didn't know if these impure actions were database queries or web service calls, so I asked Oleksii Holub.
It turns out that it's all web service calls, and as I interpret the response, GetRecommendationsAsync is being invoked from a background maintenance process.
"It takes around 10 min in total while maintaining it."
That's good to know, because if we're going to consider an Impureim Sandwich, it implies reading gigabytes of data in the first phase. That's going to take some time, but if this is a background process, we do have time.
Memory estimates #
One thing is to load an entire song catalogue into memory. That's what required 18 GB in 2012. Another thing is to load all scrobbles; i.e. statistics about plays. Fortunately, in order to produce song recommendations, we only need IDs. Consider again the data structures from the previous article:
public sealed record Song(int Id, bool IsVerifiedArtist, byte Rating); public sealed record Scrobble(Song Song, int ScrobbleCount); public sealed record User(string UserName, int TotalScrobbleCount);
Apart from the UserName all values are small predictable values: int, byte, and bool, and while a string may be arbitrarily long, we can make a guess at the average size of a user name. In the previous article, I assumed that the user name would be an alphanumeric string between one and twenty characters.
How many songs might a system contain? Some numbers thrown around for a system like Spotify suggest a number on the order of 100 million. With an int, a bool, and a byte, we can estimate that a song requires 6 bytes, plus some overhead. Let's guess 8 bytes. A 100 million songs would then require 800 million bytes, or around 800 MB. That eliminates the smallest cloud instances, but is in itself easily within reach for all modern computers. Your phone has more memory than that.
How about scrobbles? While I don't use Spotify, I do scrobble plays to Last.fm. At the moment I have around 114,000 scrobbles, and while I don't listen to music as much as I used to when I was younger, I have, on the other hand, been at it for a long time: Since 2007. If we assume that each user has 200,000 scrobbles, and a scrobble requires 8 bytes, that's 1,600,000 bytes, or 1.6 MB. Practically nothing.
The size of a User object depends on how long the user name is, but will probably, on average, be less than 32 bytes. Compared to the user's scrobbles, we can ignore the memory pressure of the user object itself.
As the number of users grow, it will dominate the memory requirements for the catalogue. How many users should we assume?
A million is probably too few, but for a frame of reference, that would require 1,6 TB. This is where it starts to sound unfeasible to keep all data in RAM. Even though servers with that much RAM exist, they're so expensive (still) that the above cost consideration no longer applies.
Still, there are some naive assumptions above. Instead of storing each scrobble in a separate Scrobble object, you could store repeated plays as a single object with the appropriate ScrobbleCount value. If you've listened to the same song 50 times, it doesn't require 400 bytes of storage, but only 8 bytes. That is, after all, orders of magnitude less.
In the end, back-of-the-envelope calculations are fine, but measurements are better. It might be worthwhile to develop a proof of concept and measure how much memory it requires.
In three articles, I'll explore how a song recommendations Impureim Sandwich looks in various constellations:
- Song recommendations as a C# Impureim Sandwich
- Song recommendations as an F# Impureim Sandwich
- Song recommendations as a Haskell Impureim Sandwich
In the end, it may turn out that for this particular system, an Impureim Sandwich truly is unfeasible. Keep in mind, though, that the purpose of this article series is to demonstrate alternative designs. The song recommendations problem is just a placeholder example. Perhaps you have another system where, intuitively, an Impureim Sandwich sounds impossible, but once you run the numbers, it might actually be not only possible, but desirable.
Conclusion #
Modern computers have so vast storage capacities that intuition often fails us. We may think that billions of data points sounds like something that can't possibly fit in RAM. When you run the numbers, however, it may turn out that the required data fits on a normal server.
If so, an Impureim Sandwich may still be an option. Load data into memory, pass it as argument to a pure function, and handle the return value.
The song recommendations scenario is interesting because an Impureim Sandwich seems to be pushing the envelope. It probably is impractical, but still worth a proof of concept. On the other hand, if it's impractical, it's worthwhile to also explore alternatives. Later articles will do that, but first, if you're interested, the next articles look at the proofs of concept in three languages.
Porting song recommendations to Haskell
An F# code base translated to Haskell.
This article is part of a larger article series that examines variations of how to take on a non-trivial problem using functional architecture. In a previous article we established a baseline C# code base. Future articles are going to use that C# code base as a starting point for refactored code. On the other hand, I also want to demonstrate what such solutions may look like in languages like F# or Haskell. In this article, you'll see how to port the baseline to Haskell. To be honest, I first ported the C# code to F#, and then used the F# code as a guide to implement equivalent Haskell code.
If you're following along in the Git repositories, this is a repository separate from the .NET repositories. The code shown here is from its master branch.
If you don't care about Haskell, you can always go back to the table of contents in the 'root' article and proceed to the next topic that interests you.
Data structures #
When working with statically typed functional languages like Haskell, it often makes most sense to start by declaring data structures.
data User = User { userName :: String , userScrobbleCount :: Int } deriving (Show, Eq)
This is much like an F# or C# record declaration, and this one echoes the corresponding types in F# and C#. The most significant difference is that here, a user's total count of scrobbles is called userScrobbleCount rather than TotalScrobbleCount. The motivation behind that variation is that Haskell data 'getters' are actually top-level functions, so it's usually a good idea to prefix them with the name of the data structure they work on. Since the data structure is called User, both 'getter' functions get the user prefix.
I found userTotalScrobbleCount a bit too verbose to my tastes, so I dropped the Total part. Whether or not that's appropriate remains to be seen. Naming in programming is always hard, and there's a risk that you don't get it right the first time around. Unless you're publishing a reusable library, however, the option to rename it later remains.
The other two data structures are quite similar:
data Song = Song { songId :: Int , songHasVerifiedArtist :: Bool , songRating :: Word8 } deriving (Show, Eq) data Scrobble = Scrobble { scrobbledSong :: Song , scrobbleCount :: Int } deriving (Show, Eq)
I thought that scrobbledSong was more descriptive than scrobbleSong, so I allowed myself that little deviation from the idiomatic naming convention. It didn't cause any problems, but I'm still not sure if that was a good decision.
How does one translate a C# interface to Haskell? Although type classes aren't quite the same as C# or Java interfaces, this language feature is close enough that I can use it in that role. I don't consider such a type class idiomatic in Haskell, but as an counterpart to the C# interface, it works well enough.
class SongService a where getTopListeners :: a -> Int -> IO [User] getTopScrobbles :: a -> String -> IO [Scrobble]
Any instance of the SongService class supports queries for top listeners of a particular song, as well as for top scrobbles for a user.
To reiterate, I don't intend to keep this type class around if I can help it, but for didactic reasons, it'll remain in some of the future refactorings, so that you can contrast and compare the Haskell code to its C# and F# peers.
Test Double #
To support tests, I needed a Test Double, so I defined the following Fake service, which is nothing but a deterministic in-memory instance. The type itself is just a wrapper of two maps.
data FakeSongService = FakeSongService { fakeSongs :: Map Int Song , fakeUsers :: Map String (Map Int Int) } deriving (Show, Eq)
Like the equivalent C# class, fakeSongs is a map from song ID to Song, while fakeUsers is a bit more complex. It's a map keyed on user name, but the value is another map. The keys of that inner map are song IDs, while the values are the number of times each song was scrobbled by that user.
The FakeSongService data structure is a SongService instance by explicit implementation:
instance SongService FakeSongService where getTopListeners srvc sid = do return $ uncurry User <$> Map.toList (sum <$> Map.filter (Map.member sid) (fakeUsers srvc)) getTopScrobbles srvc userName = do return $ fmap (\(sid, c) -> Scrobble (fakeSongs srvc ! sid) c) $ Map.toList $ Map.findWithDefault Map.empty userName (fakeUsers srvc)
In order to find all the top listeners of a song, it finds all the fakeUsers who have the song ID (sid) in their inner map, sum all of those users' scrobble counts together and creates User values from that data.
To find the top scrobbles of a user, the instance finds the user in the fakeUsers map, looks each of that user's scrobbled song up in fakeSongs, and creates Scrobble values from that information.
Finally, test code needs a way to add data to a FakeSongService value, which this test-specific helper function accomplishes:
scrobble userName s c (FakeSongService ss us) = let sid = songId s ss' = Map.insertWith (\_ _ -> s) sid s ss us' = Map.insertWith (Map.unionWith (+)) userName (Map.singleton sid c) us in FakeSongService ss' us'
Given a user name, a song, a scrobble count, and a FakeSongService, this function returns a new FakeSongService value with the new data added to the data already there.
QuickCheck Arbitraries #
In the F# test code I used FsCheck to get good coverage of the code. For Haskell, I'll use QuickCheck.
Porting the ideas from the F# tests, I define a QuickCheck generator for user names:
alphaNum :: Gen Char alphaNum = elements (['a'..'z'] ++ ['A'..'Z'] ++ ['0'..'9']) userName :: Gen String userName = do len <- choose (1, 19) first <- elements $ ['a'..'z'] ++ ['A'..'Z'] rest <- vectorOf len alphaNum return $ first : rest
It's not that the algorithm only works if usernames are alphanumeric strings that start with a letter and are no longer than twenty characters, but whenever a property is falsified, I'd rather look at a user name like "Yvj0D1I" or "tyD9P1eOqwMMa1Q6u" (which are already bad enough), than something with line breaks and unprintable characters.
Working with QuickCheck, it's often useful to wrap types from the System Under Test in test-specific Arbitrary wrappers:
newtype ValidUserName = ValidUserName { getUserName :: String } deriving (Show, Eq) instance Arbitrary ValidUserName where arbitrary = ValidUserName <$> userName
I also defined a (simpler) Arbitrary instance for Song called AnySong.
A few properties #
With FakeSongService in place, I proceeded to add the test code, starting from the top of the F# test code, and translating each as faithfully as possible. The first one is an Ice Breaker Test that only verifies that the System Under Test exists and doesn't crash when called.
testProperty "No data" $ \ (ValidUserName un) -> ioProperty $ do actual <- getRecommendations emptyService un return $ null actual
As I've done since at least 2019, it seems, I've inlined test cases as anonymous functions; this time as QuickCheck properties. This one just creates a FakeSongService that contains no data, and asks for recommendations. The expected result is that actual is empty (null), since there's nothing to recommend.
A slightly more involved property adds some data to the service before requesting recommendations:
testProperty "One user, some songs" $ \ (ValidUserName user) (fmap getSong -> songs) -> monadicIO $ do scrobbleCounts <- pick $ vectorOf (length songs) $ choose (1, 100) let scrobbles = zip songs scrobbleCounts let srvc = foldr (uncurry (scrobble user)) emptyService scrobbles actual <- run $ getRecommendations srvc user assertWith (null actual) "Should be empty"
A couple of things are worthy of note. First, the property uses a view pattern to project a list of songs from a list of Arbitraries, where getSong is the 'getter' that belongs to the AnySong newtype wrapper.
I find view patterns quite useful as a declarative way to 'promote' a single Arbitrary instance to a list. In a third property, I take it a step further:
(fmap getUserName -> NonEmpty users)
This not only turns the singular ValidUserName wrapper into a list, but by projecting it into NonEmpty, the test declares that users is a non-empty list. QuickCheck picks all that up and generates values accordingly.
If you're interested in seeing this more advanced view pattern in context, you may consult the Git repository.
Secondly, the "One user, some songs" test runs in monadicIO, which I didn't know existed before I wrote these tests. Together with pick, run, and assertWith, monadicIO is defined in Test.QuickCheck.Monadic. It enables you to write properties that run in IO, which these properties need to do, because getRecommendations is IO-bound.
There's one more QuickCheck property in the code base, but it mostly repeats techniques already shown here. See the Git repository for all the details, if necessary.
Examples #
In addition to the properties, I also ported the F# examples; that is, 'normal' unit tests. Here's one of them:
"One verified recommendation" ~: do let srvc = scrobble "ana" (Song 2 True 5) 9_9990 $ scrobble "ana" (Song 1 False 5) 10 $ scrobble "cat" (Song 1 False 6) 10 emptyService actual <- getRecommendations srvc "cat" [Song 2 True 5] @=? actual
This one is straightforward, but as I already discussed when characterizing the original code, some of the examples essentially document quirks in the implementation. Here's the relevant test, translated to Haskell:
"Only top-rated songs" ~: do -- Scale ratings to keep them less than or equal to 10. let srvc = foldr (\i -> scrobble "hyle" (Song i True (toEnum i `div` 2)) 500) emptyService [1..20] actual <- getRecommendations srvc "hyle" assertBool "Should not be empty" (not $ null actual) -- Since there's only one user, but with 20 songs, the implementation -- loops over the same songs 20 times, so 400 songs in total (with -- duplicates). Ordering on rating, only the top-rated 200 remains, that -- is, those rated 5-10. Note that this is a Characterization Test, so not -- necessarily reflective of how a real recommendation system should work. assertBool "Should have 5+ rating" (all ((>= 5) . songRating) actual)
This test creates twenty scrobbles for one user: One with a zero rating, two with rating 1, two with rating 2, and so on, up to a single song with rating 10.
The implementation of GetRecommendationsAsync uses these twenty songs to find 'other users' who have these top songs as well. In this case, there's only one user, so for every of those twenty songs, you get the same twenty songs, for a total of 400.
There are more unit tests than these. You can see them in the Git repository.
Implementation #
The most direct translation of the C# and F# 'reference implementation' that I could think of was this:
getRecommendations srvc un = do -- 1. Get user's own top scrobbles -- 2. Get other users who listened to the same songs -- 3. Get top scrobbles of those users -- 4. Aggregate the songs into recommendations -- Impure scrobbles <- getTopScrobbles srvc un -- Pure let scrobblesSnapshot = take 100 $ sortOn (Down . scrobbleCount) scrobbles recommendationCandidates <- newIORef [] forM_ scrobblesSnapshot $ \scrobble -> do -- Impure otherListeners <- getTopListeners srvc $ songId $ scrobbledSong scrobble -- Pure let otherListenersSnapshot = take 20 $ sortOn (Down . userScrobbleCount) $ filter ((10_000 <=) . userScrobbleCount) otherListeners forM_ otherListenersSnapshot $ \otherListener -> do -- Impure otherScrobbles <- getTopScrobbles srvc $ userName otherListener -- Pure let otherScrobblesSnapshot = take 10 $ sortOn (Down . songRating . scrobbledSong) $ filter (songHasVerifiedArtist . scrobbledSong) otherScrobbles forM_ otherScrobblesSnapshot $ \otherScrobble -> do let song = scrobbledSong otherScrobble modifyIORef recommendationCandidates (song :) recommendations <- readIORef recommendationCandidates -- Pure return $ take 200 $ sortOn (Down . songRating) recommendations
In order to mirror the original implementation as closely as possible, I declare recommendationCandidates as an IORef so that I can incrementally add to it as the action goes through its nested loops. Notice the modifyIORef towards the end of the code listing, which adds a single song to the list.
Once all the looping is done, the action uses readIORef to pull the recommendations out of the IORef.
As you can see, I also ported the comments from the original C# code.
I don't consider this idiomatic Haskell code, but the goal in this article was to mirror the C# code as closely as possible. Once I start refactoring, you'll see some more idiomatic implementations.
Conclusion #
Together with the previous two articles in this article series, this establishes a baseline from which I can refactor the code. While we might consider the original C# code idiomatic, this port to Haskell isn't. It is, on the other hand, similar enough to both its C# and F# peers that we can compare and contrast all three.
Particularly two design choices make this Haskell implementation less than idiomatic. One is the use of IORef to update a list of songs. The other is using a type class to model an external dependency.
As I cover various alternative architectures in this article series, you'll see how to get rid of both.
Porting song recommendations to F#
A C# code base translated to F#.
This article is part of a larger article series that examines variations of how to take on a non-trivial problem using functional architecture. In the previous article we established a baseline C# code base. Future articles are going to use that C# code base as a starting point for refactored code. On the other hand, I also want to demonstrate what such solutions may look like in languages like F# or Haskell. In this article, you'll see how to port the C# baseline to F#.
The code shown in this article is from the fsharp-port branch of the accompanying Git repository.
Data structures #
We may start by defining the required data structures. All are going to be records.
type User = { UserName : string; TotalScrobbleCount : int }
Just like the equivalent C# code, a User is just a string and an int.
When creating new values, record syntax can sometimes be awkward, so I also define a curried function to create User values:
let user userName totalScrobbleCount = { UserName = userName; TotalScrobbleCount = totalScrobbleCount }
Likewise, I define Song and Scrobble in the same way:
type Song = { Id : int; IsVerifiedArtist : bool; Rating : byte } let song id isVerfiedArtist rating = { Id = id; IsVerifiedArtist = isVerfiedArtist; Rating = rating } type Scrobble = { Song : Song; ScrobbleCount : int } let scrobble song scrobbleCount = { Song = song; ScrobbleCount = scrobbleCount }
To be honest, I only use those curried functions sparingly, so they're somewhat redundant. Perhaps I should consider getting rid of them. For now, however, they stay.
Since I'm moving all the code to F#, I also have to translate the interface.
type SongService = abstract GetTopListenersAsync : songId : int -> Task<IReadOnlyCollection<User>> abstract GetTopScrobblesAsync : userName : string -> Task<IReadOnlyCollection<Scrobble>>
The syntax is different from C#, but otherwise, this is the same interface.
Implementation #
Those are all the supporting types required to implement the RecommendationsProvider. This is the most direct translation of the C# code that I could think of:
type RecommendationsProvider (songService : SongService) = member _.GetRecommendationsAsync userName = task { // 1. Get user's own top scrobbles // 2. Get other users who listened to the same songs // 3. Get top scrobbles of those users // 4. Aggregate the songs into recommendations // Impure let! scrobbles = songService.GetTopScrobblesAsync userName // Pure let scrobblesSnapshot = scrobbles |> Seq.sortByDescending (fun s -> s.ScrobbleCount) |> Seq.truncate 100 |> Seq.toList let recommendationCandidates = ResizeArray () for scrobble in scrobblesSnapshot do // Impure let! otherListeners = songService.GetTopListenersAsync scrobble.Song.Id // Pure let otherListenersSnapshot = otherListeners |> Seq.filter (fun u -> u.TotalScrobbleCount >= 10_000) |> Seq.sortByDescending (fun u -> u.TotalScrobbleCount) |> Seq.truncate 20 |> Seq.toList for otherListener in otherListenersSnapshot do // Impure let! otherScrobbles = songService.GetTopScrobblesAsync otherListener.UserName // Pure let otherScrobblesSnapshot = otherScrobbles |> Seq.filter (fun s -> s.Song.IsVerifiedArtist) |> Seq.sortByDescending (fun s -> s.Song.Rating) |> Seq.truncate 10 |> Seq.toList otherScrobblesSnapshot |> List.map (fun s -> s.Song) |> recommendationCandidates.AddRange // Pure let recommendations = recommendationCandidates |> Seq.sortByDescending (fun s -> s.Rating) |> Seq.truncate 200 |> Seq.toList :> IReadOnlyCollection<_> return recommendations }
As you can tell, I've kept the comments from the original, too.
Test Double #
In the previous article, I'd written the Fake SongService in C#. Since, in this article, I'm translating everything to F#, I need to translate the Fake, too.
type FakeSongService () = let songs = ConcurrentDictionary<int, Song> () let users = ConcurrentDictionary<string, ConcurrentDictionary<int, int>> () interface SongService with member _.GetTopListenersAsync songId = let listeners = users |> Seq.filter (fun kvp -> kvp.Value.ContainsKey songId) |> Seq.map (fun kvp -> user kvp.Key (Seq.sum kvp.Value.Values)) |> Seq.toList Task.FromResult listeners member _.GetTopScrobblesAsync userName = let scrobbles = users.GetOrAdd(userName, ConcurrentDictionary<_, _> ()) |> Seq.map (fun kvp -> scrobble songs[kvp.Key] kvp.Value) |> Seq.toList Task.FromResult scrobbles member _.Scrobble (userName, song : Song, scrobbleCount) = let addScrobbles (scrobbles : ConcurrentDictionary<_, _>) = scrobbles.AddOrUpdate ( song.Id, scrobbleCount, fun _ oldCount -> oldCount + scrobbleCount) |> ignore scrobbles users.AddOrUpdate ( userName, ConcurrentDictionary<_, _> [ KeyValuePair.Create (song.Id, scrobbleCount) ], fun _ scrobbles -> addScrobbles scrobbles) |> ignore songs.AddOrUpdate (song.Id, song, fun _ _ -> song) |> ignore
Apart from the code shown here, only minor changes were required for the tests, such as using those curried creation functions instead of constructors, a cast to SongService, and a few other non-behavioural things like that. All tests still pass, so I consider this a faithful translation of the C# code base.
Conclusion #
This article does more groundwork. Since it may be illuminating to see one problem represented in more than one programming language, I present it in both C#, F#, and Haskell. The next article does exactly that: Translates this F# code to Haskell. Once all three bases are established, we can start introducing solution variations.
If you don't care about the Haskell examples, you can always go back to the first article in this article series and use the table of contents to jump to the next C# example.
Characterising song recommendations
Using characterisation tests and mutation testing to describe existing behaviour. An example.
This article is part of an article series that presents multiple design alternatives for a given problem that I call the song recommendations problem. In short, the problem is to recommend songs to a user based on a vast repository of scrobbles. The problem was originally proposed by Oleksii Holub as a an example of a problem that may not be a good fit for functional programming (FP).
As I've outlined in the introductory article, I'd like to use the opportunity to demonstrate alternative FP designs. Before I can do that, however, I need a working example of Oleksii Holub's code example, as well as a trustworthy test suite. That's what this article is about.
The code in this article mostly come from the master branch of the .NET repository that accompanies this article series, although some of the code is taken from intermediate commits on that branch.
Inferred details #
The original article only shows code, but doesn't link to an existing code base. While I suppose I could have asked Oleksii Holub if he had a copy he would share, the existence of such a code base isn't a given. In any case, inferring an entire code base from a comprehensive snippet is an interesting exercise in its own right.
The first step was to copy the example code into a code base. Initially it didn't compile because of some missing dependencies that I had to infer. It was only three Value Objects and an interface:
public sealed record Song(int Id, bool IsVerifiedArtist, byte Rating); public sealed record Scrobble(Song Song, int ScrobbleCount); public sealed record User(string UserName, int TotalScrobbleCount); public interface SongService { Task<IReadOnlyCollection<User>> GetTopListenersAsync(int songId); Task<IReadOnlyCollection<Scrobble>> GetTopScrobblesAsync(string userName); }
These type declarations are straightforward, but still warrant a few comments. First, Song, Scrobble, and User are C# records, which is a more recent addition to the language. If you're reading along here, but using another C-based language, or an older version of C#, you can implement such immutable Value Objects with normal language constructs; it just takes more code, instead of the one-liner syntax. F# developers will, of course, be familiar with the concept of records, and Haskell also has them.
Another remark about the above type declarations is that while SongService is an interface, it has no I prefix. This is syntactically legal, but not idiomatic in C#. I've used the name from the original code sample verbatim, so that's the immediate explanation. It's possible that Oleksii Holub intended the type to be a base class, but for various reasons I prefer interfaces, although in this particular example I don't think it would have made much of a difference. I'm only pointing it out because there's a risk that it might confuse some readers who are used to the C# naming convention. Java programmers, on the other hand, should feel at home.
As far as I remember, the only other change I had to make to the code in order to make it compile was to give the RecommendationsProvider class a constructor:
public RecommendationsProvider(SongService songService) { _songService = songService; }
This is just basic Constructor Injection, and while I find the underscore prefix redundant, I've kept it in order to stay as faithful to the original example as possible.
At this point the code compiles.
Test Double #
The goal of this article series is to present several alternative designs that implement the same behaviour. This means that as I refactor the code, I need to know that I didn't break existing functionality.
"to refactor, the essential precondition is [...] solid tests"
Currently, I have no tests, so I'll have to add some. Since RecommendationsProvider makes heavy use of its injected SongService, tests must supply that dependency in order to do meaningful work. Since Stubs and Mocks break encapsulation I instead favour state-based testing with Fake Objects.
After some experimentation, I arrived at this FakeSongService:
public sealed class FakeSongService : SongService { private readonly ConcurrentDictionary<int, Song> songs; private readonly ConcurrentDictionary<string, ConcurrentDictionary<int, int>> users; public FakeSongService() { songs = new ConcurrentDictionary<int, Song>(); users = new ConcurrentDictionary<string, ConcurrentDictionary<int, int>>(); } public Task<IReadOnlyCollection<User>> GetTopListenersAsync(int songId) { var listeners = from kvp in users where kvp.Value.ContainsKey(songId) select new User(kvp.Key, kvp.Value.Values.Sum()); return Task.FromResult<IReadOnlyCollection<User>>(listeners.ToList()); } public Task<IReadOnlyCollection<Scrobble>> GetTopScrobblesAsync( string userName) { var scrobbles = users .GetOrAdd(userName, new ConcurrentDictionary<int, int>()) .Select(kvp => new Scrobble(songs[kvp.Key], kvp.Value)); return Task.FromResult<IReadOnlyCollection<Scrobble>>(scrobbles.ToList()); } public void Scrobble(string userName, Song song, int scrobbleCount) { users.AddOrUpdate( userName, new ConcurrentDictionary<int, int>( new[] { KeyValuePair.Create(song.Id, scrobbleCount) }), (_, scrobbles) => AddScrobbles(scrobbles, song, scrobbleCount)); songs.AddOrUpdate(song.Id, song, (_, _) => song); } private static ConcurrentDictionary<int, int> AddScrobbles( ConcurrentDictionary<int, int> scrobbles, Song song, int scrobbleCount) { scrobbles.AddOrUpdate( song.Id, scrobbleCount, (_, oldCount) => oldCount + scrobbleCount); return scrobbles; } }
If you're wondering about the use of concurrent dictionaries, I use them because it made it easier to write the implementation, and not because I need the implementation to be thread-safe. In fact, I'm fairly sure that it's not thread-safe. That's not an issue. The tests aren't going to use shared mutable state.
The GetTopListenersAsync and GetTopScrobblesAsync methods implement the interface, and the Scrobble method (here, scrobble is a verb: to scrobble) is a back door that enables tests to populate the FakeSongService.
Icebreaker Test #
While the 'production code' is in C#, I decided to write the tests in F# for two reasons.
The first reason was that I wanted to be able to present the various FP designs in both C# and F#. Writing the tests in F# would make it easier to replace the C# code base with an F# alternative.
The second reason was that I wanted to leverage a property-based testing framework's ability to produce many randomly-generated test cases. I considered this important to build confidence that my tests weren't just a few specific examples that wouldn't catch errors when I made changes. Since the RecommendationsProvider API is asynchronous, the only .NET property-based framework I knew of that can run Task-valued properties is FsCheck. While it's possible to use FsCheck from C#, the F# API is more powerful.
In order to get started, however, I first wrote an Icebreaker Test without FsCheck:
[<Fact>] let ``No data`` () = task { let srvc = FakeSongService () let sut = RecommendationsProvider srvc let! actual = sut.GetRecommendationsAsync "foo" Assert.Empty actual }
This is both a trivial case and an edge case, but clearly, if there's no data in the SongService, the RecommendationsProvider can't recommend any songs.
As I usually do with Characterisation Tests, I temporarily sabotage the System Under Test so that the test fails. This is to ensure that I didn't write a tautological assertion. Once I've seen the test fail for the appropriate reason, I undo the sabotage and check in the code.
Refactor to property #
In the above No data test, the specific input value "foo" is irrelevant. It might as well have been any other string, so why not make it a property?
In this particular case, the userName could be any string, but it might be appropriate to write a custom generator that produces 'realistic' user names. Just to make things simple, I'm going to assume that user names are between one and twenty characters and assembled from alphanumeric characters, and that the fist character must be a letter:
module Gen = let alphaNumeric = Gen.elements (['a'..'z'] @ ['A'..'Z'] @ ['0'..'9']) let userName = gen { let! length = Gen.choose (1, 19) let! firstLetter = Gen.elements <| ['a'..'z'] @ ['A'..'Z'] let! rest = alphaNumeric |> Gen.listOfLength length return firstLetter :: rest |> List.toArray |> String }
Strictly speaking, as long as user names are distinct, the code ought to work, so this generator may be more conservative than necessary. Why am I constraining the generator? For two reasons: First, when FsCheck finds a counter-example, it displays the values that caused the property to fail. A twenty-character alphanumeric string is easier to relate to than some arbitrary string with line breaks and unprintable characters. The second reason is that I'm later going to measure memory load for some of the alternatives, and I wanted data to have realistic size. If user names are chosen by humans, they're unlikely to be longer than twenty characters on average (I've decided).
I can now rewrite the above No data test as an FsCheck property:
[<Property>] let ``No data`` () = Gen.userName |> Arb.fromGen |> Prop.forAll <| fun userName -> task { let srvc = FakeSongService () let sut = RecommendationsProvider srvc let! actual = sut.GetRecommendationsAsync userName Assert.Empty actual } :> Task
You may think that this is overkill just to be able to supply random user names to the GetRecommendationsAsync method. In isolation, I'd be inclined to agree, but this edit was an occasion to get my FsCheck infrastructure in place. I can now use that to add more properties.
Full coverage #
The cyclomatic complexity of the GetRecommendationsAsync method is only 3, so it doesn't require many tests to attain full code coverage. Not that 100% code coverage should be a goal in itself, but when adding tests to an untested code base, it can be useful as an indicator of confidence. Despite its low cyclomatic complexity, the method, with all of its filtering and sorting, is actually quite involved. 100% coverage strikes me as a low bar.
The above No data test exercises one of the three branches. At most two more tests are required to attain full coverage. I'll just show the simplest of them here.
The next test case requires a new FsCheck generator, in addition to Gen.userName already shown.
let song = ArbMap.generate ArbMap.defaults |> Gen.map Song
As a fairly simple one-liner, this seems close to the Fairbairn threshold, but I think that giving this generator a name makes the test easier to read.
[<Property>] let ``One user, some songs`` () = gen { let! user = Gen.userName let! songs = Gen.arrayOf Gen.song let! scrobbleCounts = Gen.choose (1, 100) |> Gen.arrayOfLength songs.Length return (user, Array.zip songs scrobbleCounts) } |> Arb.fromGen |> Prop.forAll <| fun (user, scrobbles) -> task { let srvc = FakeSongService () scrobbles |> Array.iter (fun (s, c) -> srvc.Scrobble (user, s, c)) let sut = RecommendationsProvider srvc let! actual = sut.GetRecommendationsAsync user Assert.Empty actual } :> Task
This test creates scrobbles for a single user and adds them to the Fake data store. It uses TIE-fighter syntax to connect the generators to the test body.
Since all the scrobble counts are generated between 1 and 100, none of them are greater than or equal to 10,000 and thus the test expects no recommendations.
You may think that I'm cheating - after all, why didn't I choose another range for the scrobble count? To be honest, I was still in an exploratory phase, trying to figure out how to express the tests, and as a first step, I was aiming for full code coverage. Even though this test's assertion is weak, it does exercise another branch of the GetRecommendationsAsync method.
I had to write only one more test to fully cover the System Under Test. That method is more complicated, so I'll spare you the details. If you're interested, you may consider consulting the example source code repository.
Mutation testing #
While I don't think that code coverage is useful as a target measure, it can be illuminating as a tool. In this case, knowing that I've now attained full coverage tells me that I need to resort to other techniques if I want another goal to aim for.
I chose mutation testing as my new technique. The GetRecommendationsAsync method makes heavy use of LINQ methods such as OrderByDescending, Take, and Where. Stryker for .NET knows about LINQ, so among all the automated sabotage is does, it tries to see what happens if it removes e.g. Where or Take.
Although I find the Stryker jargon childish, I set myself the goal to see if I could 'kill mutants' to a degree that I'd at least get a green rating.
I found that I could edge closer to that goal by a combination of appending assertions (thus strengthening postconditions) and adding tests. While I sometimes find it easier to define properties than examples, at other times, it's the other way around. In this case, I found it easier to add single examples, like this one:
[<Fact>] let ``One verified recommendation`` () = task { let srvc = FakeSongService () srvc.Scrobble ("cat", Song (1, false, 6uy), 10) srvc.Scrobble ("ana", Song (1, false, 5uy), 10) srvc.Scrobble ("ana", Song (2, true, 5uy), 9_9990) let sut = RecommendationsProvider srvc let! actual = sut.GetRecommendationsAsync "cat" Assert.Equal<Song> ([ Song (2, true, 5uy) ], actual) } :> Task
It adds three scrobbles to the data store, but only one of them is verified (which is what the true value indicates), so this is the only recommendation the test expects to see.
Notice that although song number 2 'only' has 9,9990 plays, the user ana has exactly 10,000 plays in all, so barely makes the cut. By carefully adding five examples like this one, I was able to 'kill all mutants'.
In all, I have eight tests; three FsCheck properties and five normal xUnit.net facts.
All tests work exclusively by supplying direct and indirect input to the System Under Test (SUT), and verify the return value of GetRecommendationsAsync. No Mocks or Stubs have opinions about how the SUT interacts with the injected SongService. This gives me confidence that the tests constitute a trustworthy regression test suite, and that they're still sufficiently decoupled from implementation details to enable me to completely rewrite the SUT.
Quirks #
When you add tests to an existing code base, you may discover edge cases that the original programmer overlooked. The GetRecommendationsAsync method is only a code example, so I don't blame Oleksii Holub for some casual coding, but it turns out that the code has some quirks.
For example, there's no deduplication, so I had to apologise in my test code:
[<Fact>] let ``Only top-rated songs`` () = task { let srvc = FakeSongService () // Scale ratings to keep them less than or equal to 10. [1..20] |> List.iter (fun i -> srvc.Scrobble ("hyle", Song (i, true, byte i / 2uy), 500)) let sut = RecommendationsProvider srvc let! actual = sut.GetRecommendationsAsync "hyle" Assert.NotEmpty actual // Since there's only one user, but with 20 songs, the implementation loops // over the same songs 20 times, so 400 songs in total (with duplicates). // Ordering on rating, only the top-rated 200 remains, that is, those rated // 5-10. Note that this is a Characterization Test, so not necessarily // reflective of how a real recommendation system should work. Assert.All (actual, fun s -> Assert.True (5uy <= s.Rating)) } :> Task
This test creates twenty scrobbles for one user: One with a zero rating, two with rating 1, two with rating 2, and so on, up to a single song with rating 10.
The implementation of GetRecommendationsAsync uses these twenty songs to find 'other users' who have these top songs as well. In this case, there's only one user, so for every of those twenty songs, you get the same twenty songs, for a total of 400.
You might protest that this is because my FakeSongService implementation is too unsophisticated. Obviously, it should not return the 'original' user's songs! Do, however, consider the implied signature of the GetTopListenersAsync method:
Task<IReadOnlyCollection<User>> GetTopListenersAsync(int songId);
The method only accepts a songId as input, and if we assume that the service is stateless, it doesn't know who the 'original' user is.
Should I fix the quirks? In a real system, it might be appropriate, but in this context I find it better to keep the them. Real systems often have quirks in the shape of legacy business rules and the like, so I only find it realistic that the system may exhibit some weird behaviour. The goal of this set of articles isn't to refactor this particular system, but rather to showcase alternative designs for a system sufficiently complicated to warrant refactorings. Simplifying the code might defeat that purpose.
As shown, I have an automated test that requires me to keep that behaviour. I think I'm in a good position to make sweeping changes to the code.
Conclusion #
As Martin Fowler writes, an essential precondition for refactoring is a trustworthy test suite. On a daily basis, millions of developers prove him wrong by deploying untested changes to production. There are other ways to make changes, including manual testing, A/B testing, testing in production, etc. Some of them may even work in some contexts.
In contrast to such real-world concerns, I don't have a production system with real users. Neither do I have a product owner or a department of manual testers. The best I can do is to add enough Characterisation Tests that I feel confident that I've described the behaviour, rather than the implementation, in enough detail to hold it in place. A Software Vise, as Michael Feathers calls it in Working Effectively with Legacy Code.
Most systems in 'the real world' have too few automated tests. Adding tests to a legacy code base is a difficult discipline, so I found it worthwhile to document this work before embarking on the actual design changes promised by this article series. Now that this is out of the way, we can proceed.
The next two articles do more groundwork to establish equivalent code bases in F# and Haskell. If you only care about the C# examples, you can go back to the first article in this article series and use the table of contents to jump to the next C# example.
Alternative ways to design with functional programming
A catalogue of FP solutions to a sample problem.
If you're past the novice stage of learning programming, you will have noticed that there's usually more than one way to solve a particular problem. Sometimes one way is better than alternatives, but often, there's no single clearly superior option.
It's a cliche that you should use the right tool for the job. For programmers, our most important tools are the techniques, patterns, algorithms, and data structures we know, rather than the IDEs we use. You can only choose the right tool for a job if you have more than one to choose from. Again, for programmers this implies knowing of more than one way to solve a problem. This is the reason I find doing katas so valuable.
Instead of a kata, in the series that this article commences I'll take a look at an example problem and in turn propose multiple alternative solutions. The problem I'll tackle is bigger than a typical kata, but you can think of this article series as a spirit companion to Thirteen ways of looking at a turtle by Scott Wlaschin.
Recommendations #
The problem I'll tackle was described by Oleksii Holub in 2020, and I've been considering how to engage with it ever since.
Oleksii Holub presents it as the second of two examples in an article named Pure-Impure Segregation Principle. In a nutshell, the problem is to identify song recommendations for a user, sourced from a vast repository of scrobbles.
The first code example in the article is fine as well, but it's not as rich a source of problems, so I don't plan to talk about it in this context.
Oleksii Holub's article does mention my article Dependency rejection as well as the Impureim Sandwich pattern.
It's my experience that the Impureim Sandwich is surprisingly often applicable, despite its seemingly obvious limitations. More than once, people have responded that it doesn't work in general.
I've never claimed that the Impureim Sandwich is a general-purpose solution to everything, only that it surprisingly often fits, once you massage the problem a bit:
- Refactoring registration flow to functional architecture
- A conditional sandwich example
- Functional file system
- A restaurant sandwich
- Song recommendations as a C# Impureim Sandwich
- Song recommendations as an F# Impureim Sandwich
- Song recommendations as a Haskell Impureim Sandwich
I have, however, solicited examples that challenge the pattern, and occasionally readers supply examples, for which I'm thankful. I'm trying to get a sense for just how widely applicable the Impureim Sandwich pattern is, and finding its limitations is an important part of that work.
The song recommendations problem is the most elusive one I've seen so far, so I'm grateful to Oleksii Holub for the example.
In the articles in this series, I'll present various alternative solutions to that problem. To make things as clear as I can, I don't do this because I think that the code shown in the original article is bad. Quite the contrary, I'd probably write it like that myself.
I offer the alternatives to teach. Only by knowing of more than one way of solving the problem can you pick the right tool for the job. It may turn out that the right design is the one already suggested by Oleksii Holub, but if you change circumstances, perhaps another design is better. Ultimately, I hope that the reader can extrapolate from this problem to other problems that he or she may encounter.
The way much online discourse is conducted today, I wish that I didn't have to emphasise the following: Someone may choose to read Oleksii Holub's article as a rebuttal of my ideas about functional architecture and the Impureim Sandwich. I don't read it that way, but rather as honest pursuit of intellectual inquiry. I engage with it in the same spirit, grateful for the rich example that it offers.
Code examples #
I'll show code in the languages with which I'm most comfortable: C#, F#, and Haskell. I'll attempt to write the C# code in such a way that programmers of Java, TypeScript, or similar languages can also read along. On the other hand, I'm not going to explain F# or Haskell, but I'll write the articles so that you can skip the F# or Haskell articles and still learn from the C# articles.
While I don't expect the majority of my readers to know Haskell, I find it an indispensable tool when evaluating whether or not a design is functional. F# is a good didactic bridge between C# and Haskell.
The code is available upon request against a small support donation of 10 USD (or more). If you're one of my regular supporters, you have my gratitude and can get the code without further donation. Also, on his blog, Oleksii Holub asks you to support Ukraine against the aggressor. If you can document that you've donated at least 10 USD to one of the charities listed there, on or after the publication of this article, I'll be happy to send you the code as well. In both cases, please write to me.
I've used Git branches for the various alternatives. In each article, I'll do my best to remember to write which branch corresponds to the article.
Articles #
This article series will present multiple alternatives in more than one programming language. I find it most natural to group the articles according to design first, and language second.
While you can view this list as a catalogue of functional programming designs, I'm under no illusion that it's complete.
- Characterising song recommendations
- Porting song recommendations to F#
- Porting song recommendations to Haskell
- Song recommendations as an Impureim Sandwich
- Song recommendations from combinators
- Song recommendations with pipes and filters
- Song recommendations with free monads
Some of the design alternatives will require detours to other interesting topics. While I'll do my best to write to enable you to skip the F# and Haskell content, few articles on this blog are self-contained. I do expect the reader to follow links when necessary, but if I've failed to explain anything to your satisfaction, please leave a comment.
Conclusion #
This article series examines multiple alternative designs to the song recommendations example presented by Oleksii Holub. The original example has interleaved impurities and is therefore not really functional, even though it looks 'functional' on the surface, due to its heavy use of filters and projections.
That example may leave some readers with the impression that there are some problems that, due to size or other 'real-world' constraints, are impossible to solve with functional programming. The present catalogue of design alternatives is my attempt to disabuse readers of that notion.
Ports and fat adapters
Is it worth it having a separate use-case layer?
When I occasionally post something about Ports and Adapters (also known as hexagonal architecture), a few reactions seem to indicate that I'm 'doing it wrong'. I apologize for the use of weasel words, but I don't intend to put particular people on the spot. Everyone has been nice and polite about it, and it's possible that I've misunderstood the criticism. Even so, a few comments have left me with the impression that there's an elephant in the room that I should address.
In short, I usually don't abstract application behaviour from frameworks. I don't create 'application layers', 'use-case classes', 'mediators', or similar. This is a deliberate architecture decision.
In this article, I'll use a motivating example to describe the reasoning behind such a decision.
Humble Objects #
A software architect should consider how the choice of particular technologies impact the development and future sustainability of a solution. It's often a good idea to consider whether it makes sense to decouple application code from frameworks and particular external dependencies. For example, should you hide database access behind an abstraction? Should you decouple the Domain Model from the web framework you use?
This isn't always the right decision, but in the following, I'll assume that this is the case.
When you apply the Dependency Inversion Principle (DIP) you let the application code define the abstractions it needs. If it needs to persist data, it may define a Repository interface. If it needs to send notifications, it may define a 'notification gateway' abstraction. Actual code that, say, communicates with a relational database is an Adapter. It translates the application interface into database SDK code.
I've been over this ground already, but to take an example from the sample code that accompanies Code That Fits in Your Head, here's a single method from the SqlReservationsRepository Adapter:
public async Task Create(int restaurantId, Reservation reservation) { if (reservation is null) throw new ArgumentNullException(nameof(reservation)); using var conn = new SqlConnection(ConnectionString); using var cmd = new SqlCommand(createReservationSql, conn); cmd.Parameters.AddWithValue("@Id", reservation.Id); cmd.Parameters.AddWithValue("@RestaurantId", restaurantId); cmd.Parameters.AddWithValue("@At", reservation.At); cmd.Parameters.AddWithValue("@Name", reservation.Name.ToString()); cmd.Parameters.AddWithValue("@Email", reservation.Email.ToString()); cmd.Parameters.AddWithValue("@Quantity", reservation.Quantity); await conn.OpenAsync().ConfigureAwait(false); await cmd.ExecuteNonQueryAsync().ConfigureAwait(false); }
This is one method of a class named SqlReservationsRepository, which is an Adapter that makes ADO.NET code look like the application-specific IReservationsRepository interface.
Such Adapters are often as 'thin' as possible. One dimension of measurement is to look at the cyclomatic complexity, where the ideal is 1, the lowest possible score. The code shown here has a complexity measure of 2 because of the null guard, which exists because of a static analysis rule.
In test parlance, we call such thin Adapters Humble Objects. Or, to paraphrase what Kris Jenkins said at the GOTO Copenhagen 2024 conference, separate code into parts that are
- hard to test, but easy to get right
- hard to get right, but easy to test.
You can do the same when sending email, querying a weather service, raising events on pub-sub infrastructure, getting the current date, etc. This isolates your application code from implementation details, such as particular database servers, SDKs, network protocols, and so on.
Shouldn't you be doing the same on the receiving end?
Fat Adapters #
In his article on Hexagonal Architecture Alistair Cockburn acknowledges a certain asymmetry. Some ports are activated by the application. Those are the ones already examined. An application reads from and writes to a database. An application sends emails. An application gets the current date.
Other ports, on the other hand, drive the application. According to Tomas Petricek's distinction between frameworks and libraries (that I also use), this kind of behaviour characterizes a framework. Examples include web frameworks such as ASP.NET, Express.js, Django, or UI frameworks like Angular, WPF, and so on.
While I usually do shield my Domain Model from framework code, I tend to write 'fat' Adapters. As far as I can tell, this is what some people have taken issue with.
Here's an example:
[HttpPost("restaurants/{restaurantId}/reservations")] public async Task<ActionResult> Post(int restaurantId, ReservationDto dto) { if (dto is null) throw new ArgumentNullException(nameof(dto)); Reservation? candidate1 = dto.TryParse(); dto.Id = Guid.NewGuid().ToString("N"); Reservation? candidate2 = dto.TryParse(); Reservation? reservation = candidate1 ?? candidate2; if (reservation is null) return new BadRequestResult(/* Describe the errors here */); var restaurant = await RestaurantDatabase.GetRestaurant(restaurantId) .ConfigureAwait(false); if (restaurant is null) return new NotFoundResult(); using var scope = new TransactionScope(TransactionScopeAsyncFlowOption.Enabled); var reservations = await Repository .ReadReservations(restaurant.Id, reservation.At) .ConfigureAwait(false); var now = Clock.GetCurrentDateTime(); if (!restaurant.MaitreD.WillAccept(now, reservations, reservation)) return NoTables500InternalServerError(); await Repository.Create(restaurant.Id, reservation).ConfigureAwait(false); scope.Complete(); return Reservation201Created(restaurant.Id, reservation); }
This is (still) code originating from the example code base that accompanies Code That Fits in Your Head, although I've here used the variation from Coalescing DTOs. I've also inlined the TryCreate helper method, so that the entire use-case flow is visible as a single method.
In a sense, we may consider this an Adapter, too. This Post action method is part of a Controller class that handles incoming HTTP requests. It is, however, not that class that deals with the HTTP protocol. Neither does it parse the request body, or checks headers, etc. The ASP.NET framework takes care of that.
By following certain naming conventions, adorning the method with an [HttpPost] attribute, and returning ActionResult, this method plays by the rules of the ASP.NET framework. Even if it doesn't implement any particular interface, or inherits from some ASP.NET base class, it clearly 'adapts' to the ASP.NET framework.
It does that by attempting to parse and validate input, look up data in data sources, and in general checking preconditions before delegating work to the Domain Model - which happens in the call to MaitreD.WillAccept.
This is where some people seem to get uncomfortable. If this is an Adapter, it's a 'fat' one. In this particular example, the cyclomatic complexity is 6. Not really a Humble Object.
Shouldn't there be some kind of 'use-case' model?
Use-case Model API #
I deliberately avoid 'use-case' model, 'mediators', or whatever other name people tend to use. I'll try to explain why by going through the exercise of actually extracting such a model. My point, in short, is that I find it not worth the effort.
In the following, I'll call such a model a 'use-case', since this is one piece of terminology that I tend to run into. You may also call it an 'Application Model' or something else.
The 'problem' that I apparently am meant to solve is that most of the code in the above Post method is tightly coupled to ASP.NET. If we want to decouple this code, how do we go about it?
It's possible that my imagination fails me, but the best I can think of is some kind of 'use-case model' that models the 'make a reservation' use case. Perhaps we should name it MakeReservationUseCase. Should it be some kind of Command object? It could be, but I think that this is awkward, because it also needs to communicate with various dependencies, such as RestaurantDatabase, Repository, and Clock. A long-lived service object that can wrap around those dependencies seems like a better option, but then we need a method on that object.
public sealed class MakeReservationUseCase { // What to call this method? What to return? I hate this already. public object MakeReservation(/* What to receive here? */) { throw new NotImplementedException(); } }
What do we call such a method? Had this been a true Command object, the single parameterless method would be called Execute, but since I'm planning to work with a stateless service, the method should take arguments. I played with options such as Try, Do, or Go, so that you'd have MakeReservationUseCase.Try and so on. Still, I thought this bordered on 'cute' or 'clever' code, and at the very least not particularly idiomatic C#. So I settled for MakeReservation, but now we have MakeReservationUseCase.MakeReservation, which is clearly redundant. I don't like the direction this design is going.
The next question is what parameters this method should take?
Considering the above Post method, couldn't we pass the dto object on to the use-case model? Technically, we could, but consider this: The ReservationDto object's raison d'être is to support reception and transmission of JSON objects. As I've already covered in an earlier article series, serialization formats are inexplicably coupled to the boundaries of a system.
Imagine that we wanted to decompose the code base into smaller constituent projects. If so, the use-case model should be independent of the ASP.NET-based code. Does it seem reasonable, then, to define the use-case API in terms of a serialization format?
I don't think that's the right design. Perhaps, instead, we should 'explode' the Data Transfer Object (DTO) into its primitive constituents?
public object MakeReservation( int restaurantId, string? id, string? at, string? email, string? name, int quantity)
I'm not too happy about this, either. Six parameters is pushing it, and this is even only an example. What if you need to pass more data than that? What if you need to pass a collection? What if each element in that collection contains another collection?
Introduce Parameter Object, you say?
Given that this is the way we want to go (in this demonstration), this seems as though it's the only good option, but that means that we'd have to define another reservation object. Not the (JSON) DTO that arrives at the boundary. Not the Reservation Domain Model, because the data has yet to be validated. A third reservation class. I don't even know what to call such a class...
So I'll leave those six parameters as above, while pointing out that no matter what we do, there seems to be a problem.
Return type woes #
What should the MakeReservation method return?
The code in the above Post method returns various ActionResult objects that indicate success or various failures. This isn't an option if we want to decouple MakeReservationUseCase from ASP.NET. How may we instead communicate one of four results?
Many object-oriented programmers might suggest throwing custom exceptions, and that's a real option. If nothing else, it'd be idiomatic in a language like C#. This would enable us to declare the return type as Reservation, but we would also have to define three custom exception types.
There are some advantages to such a design, but it effectively boils down to using exceptions for flow control.
Is there a way to model heterogeneous, mutually exclusive values? Another object-oriented stable is to introduce a type hierarchy. You could have four different classes that implement the same interface, or inherit from the same base class. If we go in this direction, then what behaviour should we define for this type? What do all four objects have in common? The only thing that they have in common is that we need to convert them to ActionResult.
We can't, however, have a method like ToActionResult() that converts the object to ActionResult, because that would couple the API to ASP.NET.
You could, of course, use downcasts to check the type of the return value, but if you do that, you might as well leave the method as shown above. If you plan on dynamic type checks and casts, the only base class you need is object.
Visitor #
If only there was a way to return heterogeneous, mutually exclusive data structures. If only C# had sum types...
Fortunately, while C# doesn't have sum types, it is possible to achieve the same goal. Use a Visitor as a sum type.
You could start with a type like this:
public sealed class MakeReservationResult { public T Accept<T>(IMakeReservationVisitor<T> visitor) { // Implementation to follow... } }
As usual with the Visitor design pattern, you'll have to inspect the Visitor interface to learn about the alternatives that it supports:
public interface IMakeReservationVisitor<T> { T Success(Reservation reservation); T InvalidInput(string message); T NoSuchRestaurant(); T NoTablesAvailable(); }
This enables us to communicate that there's exactly four possible outcomes in a way that doesn't depend on ASP.NET.
The 'only' remaining work on the MakeReservationResult class is to implement the Accept method. Are you ready? Okay, here we go:
public sealed class MakeReservationResult { private readonly IMakeReservationResult imp; private MakeReservationResult(IMakeReservationResult imp) { this.imp = imp; } public static MakeReservationResult Success(Reservation reservation) { return new MakeReservationResult(new SuccessResult(reservation)); } public static MakeReservationResult InvalidInput(string message) { return new MakeReservationResult(new InvalidInputResult(message)); } public static MakeReservationResult NoSuchRestaurant() { return new MakeReservationResult(new NoSuchRestaurantResult()); } public static MakeReservationResult NoTablesAvailable() { return new MakeReservationResult(new NoTablesAvailableResult()); } public T Accept<T>(IMakeReservationVisitor<T> visitor) { return this.imp.Accept(visitor); } private interface IMakeReservationResult { T Accept<T>(IMakeReservationVisitor<T> visitor); } private sealed class SuccessResult : IMakeReservationResult { private readonly Reservation reservation; public SuccessResult(Reservation reservation) { this.reservation = reservation; } public T Accept<T>(IMakeReservationVisitor<T> visitor) { return visitor.Success(reservation); } } private sealed class InvalidInputResult : IMakeReservationResult { private readonly string message; public InvalidInputResult(string message) { this.message = message; } public T Accept<T>(IMakeReservationVisitor<T> visitor) { return visitor.InvalidInput(message); } } private sealed class NoSuchRestaurantResult : IMakeReservationResult { public T Accept<T>(IMakeReservationVisitor<T> visitor) { return visitor.NoSuchRestaurant(); } } private sealed class NoTablesAvailableResult : IMakeReservationResult { public T Accept<T>(IMakeReservationVisitor<T> visitor) { return visitor.NoTablesAvailable(); } } }
That's a lot of boilerplate code, but it's so automatable that there are programming languages that can do this for you. On .NET, it's called F#, and all of that would be a single line of code.
Use Case implementation #
Implementing MakeReservation is now easy, since it mostly involves moving code from the Controller to the MakeReservationUseCase class, and changing it so that it returns the appropriate MakeReservationResult objects instead of ActionResult objects.
public sealed class MakeReservationUseCase { public MakeReservationUseCase( IClock clock, IRestaurantDatabase restaurantDatabase, IReservationsRepository repository) { Clock = clock; RestaurantDatabase = restaurantDatabase; Repository = repository; } public IClock Clock { get; } public IRestaurantDatabase RestaurantDatabase { get; } public IReservationsRepository Repository { get; } public async Task<MakeReservationResult> MakeReservation( int restaurantId, string? id, string? at, string? email, string? name, int quantity) { if (!Guid.TryParse(id, out var rid)) rid = Guid.NewGuid(); if (!DateTime.TryParse(at, out var rat)) return MakeReservationResult.InvalidInput("Invalid date."); if (email is null) return MakeReservationResult.InvalidInput("Invalid email."); if (quantity < 1) return MakeReservationResult.InvalidInput("Invalid quantity."); var reservation = new Reservation( rid, rat, new Email(email), new Name(name ?? ""), quantity); var restaurant = await RestaurantDatabase.GetRestaurant(restaurantId).ConfigureAwait(false); if (restaurant is null) return MakeReservationResult.NoSuchRestaurant(); using var scope = new TransactionScope(TransactionScopeAsyncFlowOption.Enabled); var reservations = await Repository.ReadReservations(restaurant.Id, reservation.At) .ConfigureAwait(false); var now = Clock.GetCurrentDateTime(); if (!restaurant.MaitreD.WillAccept(now, reservations, reservation)) return MakeReservationResult.NoTablesAvailable(); await Repository.Create(restaurant.Id, reservation).ConfigureAwait(false); scope.Complete(); return MakeReservationResult.Success(reservation); } }
I had to re-implement input validation, because the TryParse method is defined on ReservationDto, and the Use-case Model shouldn't be coupled to that class. Still, you could argue that if I'd immediately implemented the use-case architecture, I would never had had the parser defined on the DTO.
Decoupled Controller #
The Controller method may now delegate implementation to a MakeReservationUseCase object:
[HttpPost("restaurants/{restaurantId}/reservations")] public async Task<ActionResult> Post(int restaurantId, ReservationDto dto) { if (dto is null) throw new ArgumentNullException(nameof(dto)); var result = await makeReservationUseCase.MakeReservation( restaurantId, dto.Id, dto.At, dto.Email, dto.Name, dto.Quantity).ConfigureAwait(false); return result.Accept(new PostReservationVisitor(restaurantId)); }
While that looks nice and slim, it's not all, because you also need to define the PostReservationVisitor class:
private class PostReservationVisitor : IMakeReservationVisitor<ActionResult> { private readonly int restaurantId; public PostReservationVisitor(int restaurantId) { this.restaurantId = restaurantId; } public ActionResult Success(Reservation reservation) { return Reservation201Created(restaurantId, reservation); } public ActionResult InvalidInput(string message) { return new BadRequestObjectResult(message); } public ActionResult NoSuchRestaurant() { return new NotFoundResult(); } public ActionResult NoTablesAvailable() { return NoTables500InternalServerError(); } }
Notice that this implementation has to receive the restaurantId value through its constructor, since this piece of data isn't part of the IMakeReservationVisitor API. If only we could have handled all that pattern matching with a simple closure...
Well, you can. You could have used Church encoding instead of the Visitor pattern, but many programmers find that less idiomatic, or not sufficiently object-oriented.
Be that as it may, the Controller now plays the role of an Adapter between the ASP.NET framework and the framework-neutral Use-case Model. Is it all worth it?
Reflection #
Where does that put us? It's certainly possible to decouple the Use-case Model from the specific framework, but at what cost?
In this example, I had to introduce two new classes and one interface, as well as four private implementation classes and a private interface.
And that was to support just one use case. If I want to implement a query (HTTP GET), I would need to go through similar motions, but with slight variations. And again for updates (HTTP PUT). And again for deletes. And again for the next resource, such as the restaurant calendar, daily schedule, management of tenants, and so on.
The cost seems rather substantial to me. Do the benefits outweigh them? What are the benefits?
Well, you now have a technology-neutral application model. You could, conceivably, tear out ASP.NET and replace it with, oh... ServiceStack. Perhaps. Theoretically. I haven't tried.
This strikes me as an argument similar to insisting that hiding database access behind an interface enables us to replace SQL Server with a document database. That rarely happens, and is not really why we do that.
So to be fair, decoupling also protects us from changes in libraries and frameworks. It makes it easier to modify one part of the system without having to worry (too much) about other parts. It makes it easier to subject subsystems to automated testing.
Does the above refactoring improve testability? Not really. MakeReservationUseCase may be testable, but so was the original Controller. The entire code base for Code That Fits in Your Head was developed with test-driven development (TDD). The Controllers are mostly covered by self-hosted integration tests, and bolstered with a few unit tests that directly call their action methods.
Another argument for a decoupled Use-case Model is that it might enable you to transplant the entire application to a new context. Since it doesn't depend on ASP.NET, you could reuse it in an Android or iPhone app. Or a batch job. Or an AI-assisted chat bot. Right? Couldn't you?
I'd be surprised if that were the case. Every application type has its own style of user interaction, and they tend to be incompatible. The user-interface flow of a web application is fundamentally different from a rich native app.
In short, I consider the notion of a technology-neutral Use-case Model to be a distraction. That's why I usually don't bother.
Conclusion #
I usually implement Controllers, message handlers, application entry points, and so on as fairly 'fat Adapters' over particular frameworks. I do that because I expect the particular application or user interaction to be intimately tied to that kind of application. This doesn't mean that I just throw everything in there.
Fat Adapters should still be covered by automated tests. They should still show appropriate decoupling. Usually, I treat each as an Impureim Sandwich. All impure actions happen in the Fat Adapter, and everything else is done by a pure function. Granted, however, this kind of architecture comes much more natural when you are working in a programming language that supports it.
C# doesn't really, but you can make it work. And that work, contrary to modelling use cases as classes, is, in my experience, well worth the effort.
Phased breaking changes
Giving advance warning before breaking client code.
I was recently listening to Jimmy Bogard on .NET Rocks! talking about 14 versions of Automapper. It made me reminisce on how I dealt with versioning of AutFixture, in the approximately ten years I helmed that project.
Jimmy has done open source longer than I have, and it sounds as though he's found a way that works for him. When I led AutoFixture, I did things a bit differently, which I'll outline in this article. In no way do I mean to imply that that way was better than Jimmy's. It may, however, strike a chord with a reader or two, so I present it in the hope that some readers may find the following ideas useful.
Scope #
This article is about versioning a code base. Typically, a code base contains 'modules' of a kind, and client code that relies on those modules. In object-oriented programming, modules are often called classes, but in general, what matters in this context is that some kind of API exists.
The distinction between API and client code is most clear if you're maintaining a reusable library, and you don't know the client developers, but even internal application code has APIs and client code. The following may still be relevant if you're working in a code base together with colleagues.
This article discusses code-level APIs. Examples include C# code that other .NET code can call, but may also apply to Java objects callable from Clojure, Haskell code callable by other Haskell code, etc. It does not discuss versioning of REST APIs or other kinds of online services. I have, in the past, discussed versioning in such a context, and refer you, among other articles, to REST implies Content Negotiation and Retiring old service versions.
Additionally, some of the techniques outlined here are specific to .NET, or even C#. If, as I suspect, JavaScript or other languages don't have those features, then these techniques don't apply. They're hardly universal.
Semantic versioning #
The first few years of AutoFixture, I didn't use a systematic versioning scheme. That changed when I encountered Semantic Versioning: In 2011 I changed AutoFixture versioning to Semantic Versioning. This forced me to think explicitly about breaking changes.
As an aside, in recent years I've encountered the notion that Semantic Versioning is somehow defunct. This is often based on the observation that Semantic Version 2.0.0 was published in 2013. Surely, if no further development has taken place, it's been abandoned by its maintainer? This may or may not be the case. Does it matter?
The original author, Tom Preston-Werner, may have lost interest in Semantic Versioning. Or perhaps it's simply done. Regardless of the underlying reasons, I find Semantic Versioning useful as it is. The fact that it hasn't changed since 2013 may be an indication that it's stable. After all, it's not a piece of software. It's a specification that helps you think about versioning, and in my opinion, it does an excellent job of that.
As I already stated, once I started using Semantic Versioning I began to think explicitly about breaking changes.
Advance warning #
Chapter 10 in Code That Fits in Your Head is about making changes to existing code bases. Unless you're working on a solo project with no other programmers, changes you make impact other people. If you can, avoid breaking other people's code. The chapter discusses some techniques for that, but also briefly covers how to introduce breaking changes. Some of that chapter is based on my experience with AutoFixture.
If your language has a way to retire an API, use it. In Java you can use the @Deprecated annotation, and in C# the equivalent [Obsolete] attribute. In C#, any client code that uses a method with the [Obsolete] attribute will now emit a compiler warning.
By default, this will only be a warning, and there's certainly a risk that people don't look at those. On the other hand, if you follow my advice from Code That Fits in Your Head, you should treat warnings as errors. If you do, however, those warnings emitted by [Obsolete] attributes will prevent your code from compiling. Or, if you're the one who just adorned a method with that attribute, you should understand that you may just have inconvenienced someone else.
Therefore, whenever you add such an attribute, do also add a message that tells client developers how to move on from the API that you've just retired. As an example, here's an (ASP.NET) method that handles GET requests for calendar resources:
[Obsolete("Use Get method with restaurant ID.")] [HttpGet("calendar/{year}/{month}")] public ActionResult LegacyGet(int year, int month)
To be honest, that message may be a bit on the terse side, but the point is that there's another method on the same class that takes an additional restaurantId. While I'm clearly not perfect, and should have written a more detailed message, the point is that you should make it as easy as possible for client developers to deal with the problem that you've just given them. My rules for exception messages also apply here.
It's been more than a decade, but as I remember it, in the AutoFixture code base, I kept a list of APIs that I intended to deprecate at the next major revision. In other words, there were methods I considered fair use in a particular major version, but that I planned to phase out over multiple revisions. There were, however, a few methods that I immediately adorned with the [Obsolete] attribute, because I realized that they created problems for people.
The plan, then, was to take it up a notch when releasing a new major version. To be honest, though, I never got to execute the final steps of the plan.
Escalation #
By default, the [Obsolete] attribute emits a warning, but by supplying true as a second parameter, you can turn the warning into a compiler error.
[Obsolete("Use Get method with restaurant ID.", true)] [HttpGet("calendar/{year}/{month}")] public ActionResult LegacyGet(int year, int month)
You could argue that for people who treat warnings as errors, even a warning is a breaking change, but there can be no discussion that when you flip that bit, this is certainly a breaking change.
Thus, you should only escalate to this level when you publish a new major release.
Code already compiled against previous versions of your deprecated code may still work, but that's it. Code isn't going to compile against an API deprecated like that.
That's the reason it's important to give client developers ample warning.
With AutoFixture, I personally never got to that point, because I'm not sure that I arrived at this deprecation strategy until major version 3, which then had a run from early 2013 to late 2017. In other words, the library had a run of 4½ years without breaking changes. And when major version 4 rolled around, I'd left the project.
Even after setting the error flag to true, code already compiled against earlier versions may still be able to run against newer binaries. Thus, you still need to keep the deprecated API around for a while longer. Completely removing a deprecated method should only happen in yet another major version release.
Conclusion #
To summarize, deprecating an API could be considered a breaking change. If you take that position, imagine that your current Semantic Version is 2.44.2. Deprecating a method would then required that you release version 3.0.0.
In any case, you make some more changes to your code, reaching version 3.5.12. For various reasons, you decide to release version 4.0.0, in which you can also turn the error flag on. EVen so, the deprecated API remains in the library.
Only in version 5.0.0 can you entirely delete it.
Depending on how often you change major versions, this whole process may take years. I find that appropriate.

Comments
I do not really strongly disagree, but what would you do in the case where you had multiple entry points for your use cases? Ie. I have a http endpoint that creates a reservation, but I also need to be able to listen to a messagebus where reservations can come in. A lot of the logic is the same in both cases.
Thomas, thank you for writing. I'll give you two answers, because I believe that the specific answer doesn't generalize. On the other hand, the specific answer also has merit.
In the particular case, it seems as though an 'obvious' architecture would be to have the HTTP endpoint do minimal work required to parse the incoming data, and then put it on the message bus together with all the other messages. I could imagine situations where that would be appropriate, but I can also image some edge(?) cases where that still couldn't work.
As a general answer, however, having some common function or object that handles both cases could make sense. That's pretty much the architecture I spend this article discouraging. That said, as I tried to qualify, I usually don't run into situations where such an architecture is warranted. Case in point, I haven't run into a scenario like the one you describe. Other people, however, also wrote to tell me that they have two endpoints, such as both gRPC and HTTP, or both SOAP and REST, so while I, personally, haven't seen this much, it clearly does happen.
In short, I don't mind that kind of architecture when it addresses an actual problem. Often, though, that kind of requirement isn't present, and in that case, this kind of 'use-case model' architecture shouldn't be the default.
The reason I also gave you the specific answer is that I often get the impression that people seek general, universal solutions, and this could make them miss elegant shortcuts.