ploeh blog danish software design
Tautological assertions are not always caused by aliasing
You can also make mistakes that compile in Haskell.
Seeing a (unit) test fail before making it pass is an important part of empirical software engineering. This is nothing new. We've known about the red-green-refactor cycle for at least twenty years, so we know that ensuring that a test can fail is of the essence.
A fundamental problem of automated testing is that we're writing code to test code. How do we know that our test code works? After all, it's easy enough to make mistakes, even with simple code.
The importance of discipline #
When I test-drive a programming task, it regularly happens that I write a test that I expect to fail, only for it to pass. Even so, it doesn't happen that often. During a week of intensive coding, it may happen once or twice.
After all, a unit test is supposed to be a simple, short block of code, ideally with a cyclomatic complexity of 1. If you're an experienced programmer, working in a language that you know, you wouldn't expect to make simple mistakes too often.
It's easy to get lulled into a false sense of security. When new tests fail (as they should) more than 95% of the time, you may be tempted to cut corners: Just write the test, implement the desired code, and move on.
My experience is, however, that I inadvertently write a passing test now and then. I've been doing test-driven development (TDD) for more than twenty years, and this still happens. It is therefore important to keep up discipline and run that damned test, even if you don't feel like it. It's exactly when your attention is flagging that you need this safety mechanism the most.
Until you've tried a couple of times writing a test that unexpectedly pass, it can be hard to grasp why the red phase is essential. Therefore I've always felt that it was important to publish examples.
Tautologies #
A new test that passes on the first run is almost always a tautology. Theoretically, it may be that you think that the System Under Test does not yet have a certain capability, but after writing the test, it turns out that, after all, it does. This almost never happens to me. I can't rule out that this may have been the case once or twice in the last few decades, but it's as scarce as hen's teeth.
Usually, the problem is that the test is a tautology. While you believe that the test correctly self-checks something relevant, in reality, it's written in such a way that it can't possibly fail.
The first time I had the opportunity to document such a tautological assertion the underlying problem turned out to be aliasing. The next examples I ran into also had their roots in aliasing.
I began to wonder: Is the problem of tautological assertions mostly related to aliasing? If so, does it mean that the phenomenon of writing a passing test by mistake is mostly isolated to procedural and object-oriented programming? Could it be that this doesn't happen in functional programming?
If it compiles, it works #
Many so-called functional programming languages are in reality mixed-paradigm languages. The one that I know best is F#, which Don Syme calls functional-first. Even so, it's explicitly designed to interact with .NET libraries written in other languages (almost always C#), so it can still suffer from aliasing problems. The same situation applies to Clojure and Scala, which both run on the JVM.
A few languages are, however, unapologetically functional. Haskell is probably the most famous. If you rule out actions that run in IO, shared mutable state is not a concern.
Haskell's type system is so advanced and powerful that there are programmers who still seem to approach the language with an implied attitude that if it compiles, it works. Clearly, as we shall see, that is not the case.
Example #
Last week, I was writing tests against an API that was already given. As the 53rd test, I wrote this:
testCase "Cell 1 does not reproduce" $ let cell1 = Galapagos.CellState (Just cheater) (mkStdGen 0) cell2 = Galapagos.CellState Nothing (mkStdGen 1) -- seeded: no repr. actual = Galapagos.reproduce Galapagos.defaultParams (cell1, cell2) in do -- Sanity check that cell 1 remains, sampling on strategy: ( Galapagos.finchStrategyExp <$> Galapagos.cellFinch (fst actual)) @?= Galapagos.finchStrategyExp <$> Galapagos.cellFinch cell1 ( Galapagos.finchHP <$> Galapagos.cellFinch cell2) @?= Nothing
To my surprise, it immediately passed. What's wrong with it? Before reading on, see if you can spot the problem.
I know that you don't know the problem domain or the particular API. Even so, the problem is in the test itself, not in the implementation code. After all, according to the red-green-refactor cycle, I hadn't yet added the code that would make this test pass.
The error is that I meant to verify that the actual value's second component remained Nothing, but either due to a brain fart, or because I copied an earlier test, the last assertion checks that cell2 is Nothing.
Since cell2 is originally initialized with Nothing, and Haskell values are immutable, there's no way it could be anything else. This is a tautological assertion. The correct assertion is
(Galapagos.finchHP <$> Galapagos.cellFinch (snd actual)) @?= Nothing
Notice that it examines snd actual rather than cell2.
Causes #
How could I be so stupid? First, to err is human, and this is exactly why it's important to start with a failing test. The error was mine, but even so, it sometimes pays to analyse if there might be an underlying driving force behind the error. In this case, I can identify at least two, although they are related.
First, I don't recall exactly how I wrote this test, but looking at previous commits, I find it likely that I copied and pasted an earlier test case. Evidently, I failed to correctly alter the assertion to specify the new test case.
Why was I even copying and pasting the test? Because the test is too complicated. As a rule of thumb, pay attention to copy-and-paste, also of test cases. Test code should be well-factored, without too much duplication, for the same reasons that apply to other code. If a test is too difficult to write, it indicates that the API is too difficult to use. This is feedback about the API design, and you should consider if simplification is possible.
And the test is, indeed, too complicated. What I wanted to verify is that Galapagos.cellFinch (snd actual) is Nothing. If so, why didn't I just write Galapagos.cellFinch (snd actual) @?= Nothing? Because that doesn't compile.
The issue is that the data type in question (Finch) doesn't have an Eq instance, which @?= requires. Thus, I had to project the value I wanted to examine to a value that does have an Eq instance, such finchHP, which is an Int.
Why didn't I assert on isNothing instead? Eventually, I did, but the problem with asserting on raw Boolean values is that when the assertion fails, you get no good feedback. The test runner will only tell you that the expected value was True, but the actual value False.
The assertBool action offers a solution, but then you have to write your own error message, and I wasn't yet ready to do that. Eventually, I did, though.
The bottom line is that the risk of making mistakes increases, the more complicated things become. This also applies to functional programming, but in reality, simple is rarely easy.
Conclusion #
Tautological assertions are not only caused by aliasing, but also plain human error. In this article, you've seen an example of such an error in Haskell. This is a language with a type system that can identify many errors at compile time. Even so, some errors are run-time errors, and when it comes to TDD, in the red phase, the absence of failure indicates an error.
I find it important to share such errors when they occur, because they are at the same time regular and uncommon. While rare, they still happen with some periodicity. Since, after all, they don't happen that often, it may take time if you only have your own mistakes to learn from. So learn from mine, too.
Pattern guards for a protocol
A Haskell example.
Recently, I was doing a Haskell project implementing a cellular automaton according to predefined rules. Specifically, the story was one of Galápagos finches meeting and deciding whether or not to groom each other for parasites, effectively playing out a round of prisoner's dilemma.
Each finch is equipped with a particular strategy for repeated play. This strategy is implemented in a custom domain-specific language that enables each finch to remember past actions of other finches, and make decisions based on this memory.
Meeting protocol #
An evaluator runs over the code that implements each strategy, returning a free monad that embeds the possible actions a finch may take when meeting another finch.
The possible actions are defined by this sum type:
data EvalOp a
= ErrorOp Error
| MeetOp (FinchID -> a)
| GroomOp (Bool -> a)
| IgnoreOp (Bool -> a)
When two finches a and b meet, they must interact according to a protocol.
- Evaluate the strategy of the finch a up to the next effect, which must be a
MeetOp. - Invoke the continuation of the
MeetOpwith thefinchIDof finch b. - Evaluate the strategy up to next effect, which must be
GroomOporIgnoreOp. This decides the behaviour of finch a during this meeting. - Similarly, determine the behaviour of finch b, using the
finchIDof finch a. - For each finch, invoke the continuation of the
GroomOporIgnoreOpwith the behaviour of the other finch (Truefor grooming,Falsefor ignoring), yielding two newStrategys (sic). - The resulting
Strategys (sic) are then stored in theFinchobjects for the next meeting of the finches.
If at any step a strategy does not produce one of the expected effects (or no effect at all), then the finch has behaved illegally. For example, if in step 1 the first effect is a GroomOp, then this is illegal.
This sounds rather complicated, and I was concerned that even though I could pattern-match against the EvalOp cases, I'd end up with duplicated and deeply indented code.
Normal pattern matching #
Worrying about duplication, I tried to see if I could isolate each finch's 'handshake' as a separate function. I was still concerned that using normal pattern matching would cause too much indentation, but subsequent experimentation shows that in this case, it's not really that bad.
Ultimately, I went with pattern guards, but I think that it may be more helpful to lead with an example of what the code would look like using plain vanilla pattern matching.
tryRun :: EvalM a -> FinchID -> Maybe (Bool -> EvalM a, Bool) tryRun (Free (MeetOp nextAfterMeet)) other = case nextAfterMeet other of (Free (GroomOp nextAfterGroom)) -> Just (nextAfterGroom, True) (Free (IgnoreOp nextAfterIgnore)) -> Just (nextAfterIgnore, False) _ -> Nothing tryRun _ _ = Nothing
Now that I write this article, I realize that I should have named the function handshake, but hindsight is twenty-twenty. In the moment, I went with tryRun, using the try prefix to indicate that this operation may fail, as also indicated by the Maybe return type. That naming convention is probably more idiomatic in F#, but I digress.
As announced, that's not half as bad as I had originally feared. There's the beginning of arrow code, but I suppose you could also say that of any use of if/then/else. Imagine, however, that the protocol involved a few more steps, and you'd have something quite ugly at hand.
Another slight imperfection is the repetition of returning Nothing. Again, this code would not keep me up at night, but it just so happened that I originally thought that it would be worse, so I immediately cast about for alternatives.
Using pattern guards #
Originally, I thought that perhaps view patterns would be suitable, but while looking around, I came across pattern guards and thought: What's that?
This language feature has been around since 2010, but it's new to me. It's a good fit for the problem at hand, and that's how I actually wrote the tryRun function:
tryRun :: EvalM a -> FinchID -> Maybe (Bool -> EvalM a, Bool) tryRun strategy other | (Free (MeetOp nextAfterMeet)) <- strategy , (Free (GroomOp nextAfterGroom)) <- nextAfterMeet other = Just (nextAfterGroom, True) tryRun strategy other | (Free (MeetOp nextAfterMeet)) <- strategy , (Free (IgnoreOp nextAfterIgnore)) <- nextAfterMeet other = Just (nextAfterIgnore, False) tryRun _ _ = Nothing
Now that I have the opportunity to compare the two alternatives, it's not clear that one is better than the other. You may even prefer the first, normal version.
The version using pattern guards has more lines of code, and code duplication in the repetition of the | (Free (MeetOp nextAfterMeet)) <- strategy pattern. On the other hand, we get rid of the duplicated Nothing return value. What is perhaps more interesting is that had the handshake protocol involved more steps, the pattern-guards version would remain flat, whereas the other version would require indentation.
To be honest, now that I write this article, the example has lost some of its initial lustre. Still, I learned about a Haskell language feature that I didn't know about, and thought I'd share the example.
Conclusion #
Most mature programming languages have so many features that a programmer may use a language for years, and still be unaware of useful alternatives. Haskell is the oldest language I use, and although I've programmed in it for a decade, I still learn new things.
In this article, you saw a simple example of using pattern guards. Perhaps you will find this language feature useful in your own code. Perhaps you already use it.
Treat test code like production code
You have to read and maintain test code, too.
I don't think I've previously published an article with the following simple message, which is clearly an omission on my part. Better late than never, though.
Treat test code like production code.
You should apply the same coding standards to test code as you do to production code. You should make sure the code is readable, well-factored, goes through review, etc., just like your production code.
Test mess #
It's not uncommon to encounter test code that has received a stepmotherly treatment. Such test code may still pay lip service to an organization's overall coding standards by having correct indents, placement of brackets, and other superficial signs of care. You don't have to dig deep, however, before you discover that the quality of the test code leaves much to be desired.
The most common problem is a disregard for the DRY principle. Duplication abound. It's almost as though people feel unburdened by the shackles of good software engineering practices, and as result relish in the freedom to copy and paste.
That freedom is, however, purely illusory. We'll return to that shortly.
Perhaps the second-most common category of poor coding practices applied to test code is the high frequency of Zombie Code. Commented-out code is common.
Other, less frequent examples of bad practices include use of arbitrary waits instead of proper thread synchronization, unwrapping of monadic values, including calling Task.Result instead of properly awaiting a value, and so on.
I'm sure that you can think of other examples.
Why good code is important #
I think that I can understand why people treat test code as a second-class citizen. It seems intuitive, although the intuition is wrong. Nevertheless, I think it goes like this: Since the test code doesn't go into production, it's seen as less important. And as we shall see below, there are, indeed, a few areas where you can safely cut corners when it comes to test code.
As a general rule, however, it's a bad idea to slack on quality in test code.
The reason lies in why we even have coding standards and design principles in the first place. Here's a hint: It's not to placate the computer.
"Any fool can write code that a computer can understand. Good programmers write code that humans can understand."
The reason we do our best to write code of good quality is that if we don't, it's going to make our work more difficult in the future. Either our own, or someone else's. But frequently, our own.
Forty (or fifty?) years of literature on good software development practices grapple with this fundamental problem. This is why my most recent book is called Code That Fits in Your Head. We apply software engineering heuristics and care about architecture because we know that if we fail to structure the code well, our mission is in jeopardy: We will not deliver on time, on budget, or with working features.
Once we understand this, we see how this applies to test code, too. If you have good test coverage, you will likely have a substantial amount of test code. You need to maintain this part of the code base too. The best way to do so is to treat it like your production code. Apply the same standards and design principles to test code as you do to your production code. This especially means keeping test code DRY.
Test-specific practices #
Since test code has a specialized purpose, you'll run into problems unique to that space. How should you structure a unit test? How should you organize them? How should you name them? How do you make them deterministic?
Fortunately, thoughtful people have collected and systematized their experience. The absolute most comprehensive such collection is xUnit Test Patterns, which has been around since 2007. Nothing in that book invalidates normal coding practices. Rather, it suggests specializations of good practices that apply to test code.
You may run into the notion that tests should be DAMP rather than DRY. If you expand the acronym, however, it stands for Descriptive And Meaningful Phrases, and you may realize that it's a desired quality of code independent of whether or not you repeat yourself. (Even the linked article fails, in my opinion, to erect a convincing dichotomy. Its notion of DRY is clearly not the one normally implied.) I think of the DAMP notion as related to Domain-Driven Design, which is another thematic take on making code fit in your head.
For a few years, however, I did, too, believe that copy-and-paste was okay in test code, but have long since learned that duplication slows you down in test code for exactly the same reason that it hurts in 'real' code. One simple change leads to Shotgun Surgery; many tests break, and you have to fix each one individually.
Dispensations #
All the same, there are exceptions to the general rule. In certain, well-understood ways, you can treat your test code with less care than production code.
Specifically, assuming that test code remains undeployed, you can skip certain security practices. You may, for example, hard-code test-only passwords directly in the tests. The code base that accompanies Code That Fits in Your Head contains an example of that.
You may also skip input validation steps, since you control the input for each test.
In my experience, security is the dominating exemption from the rule, but there may be other language- or platform-specific details where deviating from normal practices is warranted for test code.
One example may be in .NET, where a static code analysis rule may insist that you call ConfigureAwait. This rule is intended for library code that may run in arbitrary environments. When code runs in a unit-testing environment, on the other hand, the context is already known, and this rule can be dispensed with.
Another example is that in Haskell GHC may complain about orphan instances. In test code, it may occasionally be useful to give an existing type a new instance, most commonly an Arbitrary instance. While you can also get around this problem with well-named newtypes, you may also decide that orphan instances are no problem in a test code base, since you don't have to export the test modules as reusable libraries.
Conclusion #
You should treat test code like production code. The coding standards that apply to production code should also apply to test code. If you follow the DRY principle for production code, you should also follow the DRY principle in the test code base.
The reason is that most coding standards and design principles exist to make code maintainability easier. Since test code is also code, this still applies.
There are a few exception, most notably in the area of security, assuming that the test code is never deployed to production.
Result is the most boring sum type
If you don't see the point, you may be looking in the wrong place.
I regularly encounter programmers who are curious about statically typed functional programming, but are struggling to understand the point of sum types (also known as Discriminated Unions, Union Types, or similar). Particularly, I get the impression that recently various thought leaders have begun talking about Result types.
There are deep mathematical reasons to start with Results, but on the other hand, I can understand if many learners are left nonplussed. After all, Result types are roughly equivalent to exceptions, and since most languages already come with exceptions, it can be difficult to see the point.
The short response is that there's a natural explanation. A Result type is, so to speak, the fundamental sum type. From it, you can construct all other sum types. Thus, you can say that Results are the most abstract of all sum types. In that light, it's understandable if you struggle to see how they are useful.
Coproduct #
My goal with this article is to point out why and how Result types are the most abstract, and perhaps least interesting, sum types. The point is not to make Result types compelling, or sell sum types in general. Rather, my point is that if you're struggling to understand what all the fuss is about algebraic data types, perhaps Result types are the wrong place to start.
In the following, I will tend to call Result by another name: Either, which is also the name used in Haskell, where it encodes a universal construction called a coproduct. Where Result indicates a choice between success and failure, Either models a choice between 'left' and 'right'.
Although the English language allows the pun 'right = correct', and thereby the mnemonic that the right value is the opposite of failure, 'left' and 'right' are otherwise meant to be as neutral as possible. Ideally, Either carries no semantic value. This is what we would expect from a 'most abstract' representation.
Canonical representation #
As Thinking with Types does an admirable job of explaining, Either is part of a canonical representation of types, in which we can rewrite any type as a sum of products. In this context, a product is a pair, as also outlined by Bartosz Milewski.
The point is that we may rewrite any type to a combination of pairs and Either values, with the Either values on the outside. Such rewrites work both ways. You can rewrite any type to a combination of pairs and Eithers, or you can turn a combination of pairs and Eithers into more descriptive types. Since two-way translation is possible, we observe that the representations are isomorphic.
Isomorphism with Maybe #
Perhaps the simplest example is the natural transformation between Either () a and Maybe a, or, in F# syntax, Result<'a,unit> and 'a option. The Natural transformations article shows an F# example.
For illustration, we may translate this isomorphism to C# in order to help readers who are more comfortable with object-oriented C-like syntax. We may reuse the IgnoreLeft implementation, also from Natural transformations, to implement a translation from IEither<Unit, R> to IMaybe<R>.
public static IMaybe<R> ToMaybe<R>(this IEither<Unit, R> source) { return source.IgnoreLeft(); }
In order to go the other way, we may define ToMaybe's counterpart like this:
public static IEither<Unit, T> ToEither<T>(this IMaybe<T> source) { return source.Accept(new ToEitherVisitor<T>()); } private class ToEitherVisitor<T> : IMaybeVisitor<T, IEither<Unit, T>> { public IEither<Unit, T> VisitNothing => new Left<Unit, T>(Unit.Instance); public IEither<Unit, T> VisitJust(T just) { return new Right<Unit, T>(just); } }
The following two parametrized tests demonstrate the isomorphisms.
[Theory, ClassData(typeof(UnitIntEithers))] public void IsomorphismViaMaybe(IEither<Unit, int> expected) { var actual = expected.ToMaybe().ToEither(); Assert.Equal(expected, actual); } [Theory, ClassData(typeof(StringMaybes))] public void IsomorphismViaEither(IMaybe<string> expected) { var actual = expected.ToEither().ToMaybe(); Assert.Equal(expected, actual); }
The first test starts with an Either value, converts it to Maybe, and then converts the Maybe value back to an Either value. The second test starts with a Maybe value, converts it to Either, and converts it back to Maybe. In both cases, the actual value is equal to the expected value, which was also the original input.
Being able to map between Either and Maybe (or Result and Option, if you prefer) is hardly illuminating, since Maybe, too, is a general-purpose data structure. If this all seems a bit abstract, I can see why. Some more specific examples may help.
Calendar periods in F# #
Occasionally I run into the need to treat different calendar periods, such as days, months, and years, in a consistent way. To my recollection, the first time I described a model for that was in 2013. In short, in F# you can define a discriminated union for that purpose:
type Period = Year of int | Month of int * int | Day of int * int * int
A year is just a single integer, whereas a day is a triple, obviously with the components arranged in a sane order, with Day (2025, 11, 14) representing November 14, 2025.
Since this is a three-way discriminated union, whereas Either (or, in F#: Result) only has two mutually exclusive options, we need to nest one inside of another to represent this type in canonical form: Result<int, Result<(int * int), (int * (int * int))>>. Note that the 'outer' Result is a choice between a single integer (the year) and another Result value. The inner Result value then presents a choice between a month and a day.
Converting back and forth is straightforward:
let periodToCanonical = function | Year y -> Ok y | Month (y, m) -> Error (Ok (y, m)) | Day (y, m, d) -> Error (Error (y, (m, d))) let canonicalToPeriod = function | Ok y -> Year y | Error (Ok (y, m)) -> Month (y, m) | Error (Error (y, (m, d))) -> Day (y, m, d)
In F# this translations may strike you as odd, since the choice between Ok and Error hardly comes across as neutral. Even so, there's no loss of information when translating back and forth between the two representations.
> Month (2025, 12) |> periodToCanonical;; val it: Result<int,Result<(int * int),(int * (int * int))>> = Error (Ok (2025, 12)) > Error (Ok (2025, 12)) |> canonicalToPeriod;; val it: Period = Month (2025, 12)
The implied semantic difference between Ok and Error is one reason I favour Either over Result, when I have the choice. When translating to C#, I do have a choice, since there's no built-in coproduct data type.
Calendar periods in C# #
If you have been perusing the code base that accompanies Code That Fits in Your Head, you may have noticed an IPeriod interface. Since this is internal by default, I haven't discussed it much, but it's equivalent to the above F# discriminated union. It's used to enumerate restaurant reservations for a day, a month, or even a whole year.
Since this is a Visitor-encoded sum type, most of the information about data representation can be discerned from the Visitor interface:
internal interface IPeriodVisitor<T> { T VisitYear(int year); T VisitMonth(int year, int month); T VisitDay(int year, int month, int day); }
Given an appropriate Either definition, we can translate any IPeriod value into a nested Either, just like the above F# example.
private class ToCanonicalPeriodVisitor : IPeriodVisitor<IEither<int, IEither<(int, int), (int, (int, int))>>> { public IEither<int, IEither<(int, int), (int, (int, int))>> VisitDay( int year, int month, int day) { return new Right<int, IEither<(int, int), (int, (int, int))>>( new Right<(int, int), (int, (int, int))>((year, (month, day)))); } public IEither<int, IEither<(int, int), (int, (int, int))>> VisitMonth( int year, int month) { return new Right<int, IEither<(int, int), (int, (int, int))>>( new Left<(int, int), (int, (int, int))>((year, month))); } public IEither<int, IEither<(int, int), (int, (int, int))>> VisitYear(int year) { return new Left<int, IEither<(int, int), (int, (int, int))>>(year); } }
Look out! I've encoded year, month, and day from left to right as I did before. This means that the leftmost alternative indicates a year, and the rightmost alternative in the nested Either value indicates a day. This is structurally equivalent to the above F# encoding. If, however, you are used to thinking about left values indicating error, and right values indicating success, then the two mappings are not similar. In the F# encoding, an 'outer' Ok value indicates a year, whereas here, a left value indicates a year. This may be confusing if your are expecting a right value, corresponding to Ok.
The structure is the same, but this may be something to be aware of going forward.
You can translate the other way without loss of information.
private class ToPeriodVisitor : IEitherVisitor<int, IEither<(int, int), (int, (int, int))>, IPeriod> { public IPeriod VisitLeft(int left) { return new Year(left); } public IPeriod VisitRight(IEither<(int, int), (int, (int, int))> right) { return right.Accept(new ToMonthOrDayVisitor()); } private class ToMonthOrDayVisitor : IEitherVisitor<(int, int), (int, (int, int)), IPeriod> { public IPeriod VisitLeft((int, int) left) { var (y, m) = left; return new Month(y, m); } public IPeriod VisitRight((int, (int, int)) right) { var (y, (m, d)) = right; return new Day(y, m, d); } } }
It's all fairly elementary, although perhaps a bit cumbersome. The point of it all, should you have forgotten, is only to demonstrate that we can encode any sum type as a combination of Either values (and pairs).
A test like this demonstrates that these two translations comprise a true isomorphism:
[Theory, ClassData(typeof(PeriodData))] public void IsomorphismViaEither(IPeriod expected) { var actual = expected .Accept(new ToCanonicalPeriodVisitor()) .Accept(new ToPeriodVisitor()); Assert.Equal(expected, actual); }
This test converts arbitrary IPeriod values to nested Either values, and then translates them back to the same IPeriod value.
Payment types in F# #
Perhaps you are not convinced by a single example, so let's look at one more. In 2016 I was writing some code to integrate with a payment gateway. To model the various options that the gateway made available, I defined a discriminated union, repeated here:
type PaymentService = { Name : string; Action : string } type PaymentType = | Individual of PaymentService | Parent of PaymentService | Child of originalTransactionKey : string * paymentService : PaymentService
This looks a little more complicated, since it also makes use of the custom PaymentService type. Even so, converting to the canonical sum of products representation, and back again, is straightforward:
let paymentToCanonical = function | Individual { Name = n; Action = a } -> Ok (n, a) | Parent { Name = n; Action = a } -> Error (Ok (n, a)) | Child (k, { Name = n; Action = a }) -> Error (Error (k, (n, a))) let canonicalToPayment = function | Ok (n, a) -> Individual { Name = n; Action = a } | Error (Ok (n, a)) -> Parent { Name = n; Action = a } | Error (Error (k, (n, a))) -> Child (k, { Name = n; Action = a })
Again, there's no loss of information going back and forth between these two representations, even if the use of the Error case seems confusing.
> Child ("1234ABCD", { Name = "MasterCard"; Action = "Pay" }) |> paymentToCanonical;;
val it:
Result<(string * string),
Result<(string * string),(string * (string * string))>> =
Error (Error ("1234ABCD", ("MasterCard", "Pay")))
> Error (Error ("1234ABCD", ("MasterCard", "Pay"))) |> canonicalToPayment;;
val it: PaymentType = Child ("1234ABCD", { Name = "MasterCard"
Action = "Pay" })
Again, you might wonder why anyone would ever do that, and you'd be right. As a general rule, there's no reason to do this, and if you think that the canonical representation is more abstract, and harder to understand, I'm not going to argue. The point is, rather, that products (pairs) and coproducts (Either values) are universal building blocks of algebraic data types.
Payment types in C# #
As in the calendar-period example, it's possible to demonstrate the concept in alternative programming languages. For the benefit of programmers with a background in C-like languages, I once more present the example in C#. The starting point is where Visitor as a sum type ends. The code is also available on GitHub.
Translation to canonical form may be done with a Visitor like this:
private class ToCanonicalPaymentTypeVisitor : IPaymentTypeVisitor< IEither<(string, string), IEither<(string, string), (string, (string, string))>>> { public IEither<(string, string), IEither<(string, string), (string, (string, string))>> VisitChild(ChildPaymentService child) { return new Right<(string, string), IEither<(string, string), (string, (string, string))>>( new Right<(string, string), (string, (string, string))>( ( child.OriginalTransactionKey, ( child.PaymentService.Name, child.PaymentService.Action ) ))); } public IEither<(string, string), IEither<(string, string), (string, (string, string))>> VisitIndividual(PaymentService individual) { return new Left<(string, string), IEither<(string, string), (string, (string, string))>>( (individual.Name, individual.Action)); } public IEither<(string, string), IEither<(string, string), (string, (string, string))>> VisitParent(PaymentService parent) { return new Right<(string, string), IEither<(string, string), (string, (string, string))>>( new Left<(string, string), (string, (string, string))>( (parent.Name, parent.Action))); } }
If you find the method signatures horrible and near-unreadable, I don't blame you. This is an excellent example that C# (together with similar languages) inhabit the zone of ceremony; compare this ToCanonicalPaymentTypeVisitor to the above F# paymentToCanonical function, which performs exactly the same work while being as strongly statically typed.
Another Visitor translates the other way.
private class FromCanonicalPaymentTypeVisitor : IEitherVisitor< (string, string), IEither<(string, string), (string, (string, string))>, IPaymentType> { public IPaymentType VisitLeft((string, string) left) { var (name, action) = left; return new Individual(new PaymentService(name, action)); } public IPaymentType VisitRight(IEither<(string, string), (string, (string, string))> right) { return right.Accept(new CanonicalParentChildPaymentTypeVisitor()); } private class CanonicalParentChildPaymentTypeVisitor : IEitherVisitor<(string, string), (string, (string, string)), IPaymentType> { public IPaymentType VisitLeft((string, string) left) { var (name, action) = left; return new Parent(new PaymentService(name, action)); } public IPaymentType VisitRight((string, (string, string)) right) { var (k, (n, a)) = right; return new Child(new ChildPaymentService(k, new PaymentService(n, a))); } } }
Here I even had to split one generic type signature over multiple lines, in order to prevent horizontal scrolling. At least you have to grant the C# language that it's flexible enough to allow that.
Now that it's possible to translate both ways, a simple tests demonstrates the isomorphism.
[Theory, ClassData(typeof(PaymentTypes))] public void IsomorphismViaEither(IPaymentType expected) { var actual = expected .Accept(new ToCanonicalPaymentTypeVisitor()) .Accept(new FromCanonicalPaymentTypeVisitor()); Assert.Equal(expected, actual); }
This test translates an arbitrary IPaymentType into canonical form, then translates that representation back to an IPaymentType value, and checks that the two values are identical. There's no loss of information either way.
This and the previous example may seem like a detour around the central point that I'm trying to make: That Result (or Either) is the most boring sum type. I could have made the point, including examples, in a few lines of Haskell, but that language is so efficient at that kind of work that I fear that the syntax would look like pseudocode to programmers used to C-like languages. Additionally, Haskell programmers don't need my help writing small mappings like the ones shown here.
Conclusion #
Result (or Either) is as a fundamental building block in the context of algebraic data types. As such, this type may be considered the most boring sum type, since it effectively represents any other sum type, up to isomorphism.
Object-oriented programmers trying to learn functional programming sometimes struggle to see the light. One barrier to understanding the power of algebraic data types may be related to starting a learning path with a Result type. Since Results are equivalent to exceptions, people understandably have a hard time seeing how Result values are better. Since Result types are so abstract, it can be difficult to see the wider perspective. This doubly applies if a teacher leads with Result, with it's success/failure semantics, rather than with Either and its more neutral left/right labels.
Since Either is the fundamental sum type, it follows that any other sum type, being more specialized, carries more meaning, and therefore may be more interesting, and more illuminating as examples. In this article, I've used a few simple, but specialized sum types with the intention to help the reader see the difference.
Empirical software prototyping
How do you add tests to a proof-of-concept? Should you?
This is the second article in a small series on empirical test-after development. I'll try to answer an occasionally-asked question: Should one use test-driven development (TDD) for prototyping?
There are variations on this question, but it tends to come up when discussing TDD. Some software thought leaders proclaim that you should always take advantage of TDD when writing code. The short response is that there are exceptions to that rule. Those thought leaders know that, too, but they choose to communicate the way that they do in order to make a point. I don't blame them, and I use a similar style of communication from time to time. If you hedge every sentence you utter with qualifications, the message often disappears in unclear language. Thus, when someone admonishes that you should always follow TDD, what they really mean (I suppose; I'm not a telepath) is that you should predominantly use TDD. More than 80% of the time.
This is a common teaching tool. A competent teacher takes into account the skill level of a student. A new learner has to start with the basics before advanced topics. Early in the learning process, there's no room for sophistication. Even when a teacher understands that there are exceptions, he or she starts with a general rule, like 'you should always do TDD'.
While this may seem like a digression, this detour answers most of the questions related to software prototyping. People find it difficult to apply TDD when developing a prototype. I do, too. So don't.
Prototyping or proof-of-concept? #
I've already committed the sin of using prototype and proof-of-concept interchangeably. This only reflects how I use these terms in conversation. While I'm aware that the internet offers articles to help me distinguish, I find the differences too subtle to be of use when communicating with other people. Even if I learn the fine details that separate one from the other, I can't be sure that the person I'm talking to shares that understanding.
Since prototype is easier to say, I tend to use that term more than proof-of-concept. In any case, a prototype in this context is an exploration of an idea. You surmise that it's possible to do something in a certain way, but you're not sure. Before committing to the uncertain idea, you develop an isolated code base to vet the concept.
This could be an idea for an algorithm, use of a new technology such as a framework or reusable library, a different cloud platform, or even a new programming language.
Such exploration is already challenging in itself. How is the API of the library structured? Should you call IsFooble or HasFooble here? How do you write a for loop in APL? How does one even compile a Java program? How do you programmatically provision new resources in Microsoft Fabric? How do you convert a JPG file to PDF on the server?
There are plenty of questions like these where you don't even know the shape of things. The point of the exercise is often to figure those things out. When you don't know how APIs are organized, or which technologies are available to you, writing tests first is difficult. No wonder people sometimes ask me about this.
Code to throw away #
The very nature of a prototype is that it's an experiment designed to explore an idea. The safest way to engage with a prototype is to create an isolated code base for that particular purpose. A prototype is not an MVP or an early version of the product. It is a deliberately unstructured exploration of what's possible. The entire purpose of a prototype is to learn. Often the exploration process is time-boxed.
If the prototype turns out to be successful, you may proceed to implement the idea in your production code base. Even if you didn't use TDD for the prototype, you should now have learned enough that you can apply TDD for the production implementation.
The most common obstacle to this chain of events, I understand, is that 'bosses' demand that a successful prototype be put into production. Try to resist such demands. It often helps planning for this from the outset. If you can, do the prototype in a way that effectively prevents such predictable demands. If you're exploring the viability of a new algorithm, write it in an alternative programming language. For example, I've written prototypes in Haskell, which very effectively prevents demands that the code be put into production.
If your organization is a little behind the cutting edge, you can also write the prototype in a newer version of your language or run-time. Use functional programming if you normally use object-oriented design. Or you may pick an auxiliary technology incompatible with how you normally do things: Use the 'wrong' JSON serializer library, an in-memory database, write a command-line program if you need a GUI, or vice versa.
You're the technical expert. Make technical decisions. Surely, you can come up with something that sounds convincing enough to a non-technical stakeholder to prevent putting the prototype into production.
To be sure we're on firm moral ground here: I'm not advocating that you should be dishonest, or work against the interests of your organization. Rather, I suggest that you act politically. Understand what motivates other people. Non-technical stakeholders usually don't have the insight to understand why a successful prototype shouldn't be promoted to production code. Unfortunately, they often view programmers as typists, and with that view, it seems wasteful to repeat the work of typing in the prototype code. Typing, however, is not a bottleneck, but it can be hard to convince other people of this.
If all else fails, and you're forced to promote the prototype to production code, you now have a piece of legacy code on hand, in which case the techniques outlined in the previous article should prove useful.
Prototyping in existing code bases #
A special case occurs when you need to do a prototype in an existing code base. You already have a big, complicated system, and you would like to explore whether a particular idea is applicable in that context. Perhaps data access is currently too slow, and you have an idea of how to speed things up, for example by speculative prefetching. When the problem is one of performance, you'll need to measure in a realistic environment. This may prevent you from creating an isolated prototype code base.
In such cases, use Git to your advantage. Make a new prototype branch and work there. You may deliberately choose to make it a long-lived feature branch. Once the prototype is done, the code may now be so out of sync with master that 'merge conflicts' sounds like a plausible excuse to a non-technical stakeholder. As above, be political.
In any case, don't merge the prototype branch, even if you could. Instead, use the knowledge gained during the prototype work to re-implement the new idea, this time using empirical software engineering techniques like TDD.
Conclusion #
Prototyping is usually antithetical to TDD. On the other hand, TDD is an effective empirical method for software development. Without it, you have to seek other answers to the question: How do we know that this works?
Due to the explorative nature of prototyping, testing of the prototype tends to be explorative as well. Start up the prototype, poke at it, see if it behaves as expected. While you do gain a limited amount of empirical knowledge from such a process, it's unsystematic and non-repeatable, so little corroboration of hypothesis takes place. Therefore, once the prototype work is done, it's important to proceed on firmer footing if the prototype was successful.
The safest way is to put the prototype to the side, but use the knowledge to test-drive the production version of the idea. This may require a bit of political manoeuvring. If that fails, and you're forced to promote the prototype to production use, you may use the techniques for adding empirical Characterization Tests.
100% coverage is not that trivial
Dispelling a myth I helped propagate.
Most people who have been around automated testing for a few years understand that code coverage is a useless target measure. Unfortunately, through a game of Chinese whispers, this message often degenerates to the simpler, but incorrect, notion that code coverage is useless.
As I've already covered in that article, code coverage may be useful for other reasons. That's not my agenda for this article. Rather, something about this discussion have been bothering me for a long time.
Have you ever had an uneasy feeling about a topic, without being able to put your finger on exactly what the problem is? This happens to me regularly. I'm going along with the accepted narrative until the cognitive dissonance becomes so conspicuous that I can no longer ignore it.
In this article, I'll grapple with the notion that 'reaching 100% code coverage is easy.'
Origins #
This tends to come up when discussing code coverage. People will say that 100% code coverage isn't a useful measure, because it's easy to reach 100%. I have used that argument myself. Fortunately I also cited my influences in 2015; in this case Martin Fowler's Assertion Free Testing.
"[...] of course you can do this and have 100% code coverage - which is one reason why you have to be careful on interpreting code coverage data."
This may not be the only source of such a claim, but it may have been a contributing factor. There's little wrong with Fowler's article, which doesn't make any groundless claims, but I can imagine how semantic diffusion works on an idea like that.
Fowler also wrote that it's "a story from a friend of a friend." When the source of a story is twice-removed like that, alarm bells should go off. This is the stuff that urban legends are made of, and I wonder if this isn't rather an example of 'programmer folk wisdom'. I've heard variations of that story many times over the years, from various people.
It's not that easy #
Even though I've helped promulgate the idea that reaching 100% code coverage is easy if you cheat, I now realise that that's an overstatement. Even if you write no assertions, and surround the test code with a try/catch block, you can't trivially reach 100% coverage. There are going to be branches that you can't reach.
This often happens in real code bases that query databases, call web services, and so on. If a branch depends on indirect input, you can't force execution down that path just by suppressing exceptions.
An example is warranted.
Example #
Consider this ReadReservation method in the SqlReservationsRepository class from the code base that accompanies my book Code That Fits in Your Head:
public async Task<Reservation?> ReadReservation(int restaurantId, Guid id) { const string readByIdSql = @" SELECT [PublicId], [At], [Name], [Email], [Quantity] FROM [dbo].[Reservations] WHERE [PublicId] = @id"; using var conn = new SqlConnection(ConnectionString); using var cmd = new SqlCommand(readByIdSql, conn); cmd.Parameters.AddWithValue("@id", id); await conn.OpenAsync().ConfigureAwait(false); using var rdr = await cmd.ExecuteReaderAsync().ConfigureAwait(false); if (!rdr.Read()) return null; return ReadReservationRow(rdr); }
Even though it only has a cyclomatic complexity of 2, most of it is unreachable to a test that tries to avoid hard work.
You can try to cheat in the suggested way by adding a test like this:
[Fact] public async Task ReadReservation() { try { var sut = new SqlReservationsRepository("dunno"); var actual = await sut.ReadReservation(0, Guid.NewGuid()); } catch { } }
Granted, this test passes, and if you had 0% code coverage before, it does improve the metric slightly. Interestingly, the Coverlet collector for .NET reports that only the first line, which creates the conn variable, is covered. I wonder, though, if this is due to some kind of compiler optimization associated with asynchronous execution that the coverage tool fails to capture.
More understandably, execution reaches conn.OpenAsync() and crashes, since the test hasn't provided a connection to a real database. This is what happens if you run the test without the surrounding try/catch block.
Coverlet reports 18% coverage, and that's as high you can get with 'the easy hack'. 100% is some distance away.
Toward better coverage #
You may protest that we can do better than this. After all, with utter disregard for using proper arguments, I passed "dunno" as a connection string. Clearly that doesn't work.
Couldn't we easily get to 100% by providing a proper connection string? Perhaps, but what's a proper connection string?
It doesn't help if you pass a well-formed connection string instead of "dunno". In fact, it will only slow down the test, because then conn.OpenAsync() will attempt to open the connection. If the database is unreachable, that statement will eventually time out and fail with an exception.
Couldn't you, though, give it a connection string to a real database?
Yes, you could. If you do that, though, you should make sure that the database has a schema compatible with readByIdSql. Otherwise, the query will fail. What happens if the implied schema changes? Now you need to make sure that the database is updated, too. This sounds error-prone. Perhaps you should automate that.
Furthermore, you may easily cover the branch that returns null. After all, when you query for Guid.NewGuid(), that value is not going to be in the table. On the other hand, how will you cover the other branch; the one that returns a row?
You can only do that if you know the ID of a value already in that table. You may write a second test that queries for that known value. Now you have 100% coverage.
What you have done at this point, however, is no longer an easy cheat to get to 100%. You have, essentially, added integration tests of the data access subsystem.
How about adding some assertions to make the tests useful?
Integration tests for 100% #
In most systems, you will at least need some integration tests to reach 100% code coverage. While the code shown in Code That Fits in Your Head doesn't have 100% code coverage (that was never my goal), it looks quite good. (It's hard to get a single number, because Coverlet apparently can't measure coverage by running multiple test projects, so I can only get partial results. Coverage is probably better than 80%, I estimate.)
To test ReadReservation I wrote integration tests that automate setup and tear-down of a local test-specific database. The book, and the Git repository that accompanies it, has all the details.
Getting to 100%, or even 80%, requires dedicated work. In a realistic code base, the claim that reaching 100% is trivial is hardly true.
Conclusion #
Programmer folk wisdom 'knows' that code coverage is useless. One argument is that any fool can reach 100% by writing assertion-free tests surrounded by try/catch blocks.
This is hardly true in most significant code bases. Whenever you deal with indirect input, try/catch is insufficient to control whereto execution branches.
This suggests that high code-coverage numbers are good, and low numbers bad. What constitutes high and low is context-dependent. What seems to remain true, however, is that code coverage is a useless target. This has little to do with how trivial it is to reach 100%, but rather everything to do with how humans respond to incentives.
Empirical Characterization Testing
Gathering empirical evidence while adding tests to legacy code.
This article is part of a short series on empirical test-after techniques. Sometimes, test-driven development (TDD) is impractical. This often happens when faced with legacy code. Although there's a dearth of hard data, I guess that most code in the world falls into this category. Other software thought leaders seem to suggest the same notion.
For the purposes of this discussion, the definition of legacy code is code without automated tests.
"Code without tests is bad code. It doesn't matter how well written it is; it doesn't matter how pretty or object-oriented or well-encapsulated it is. With tests, we can change the behavior of our code quickly and verifiably. Without them, we really don't know if our code is getting better or worse."
As Michael Feathers suggest, the accumulation of knowledge is at the root of this definition. As I outlined in Epistemology of software, tests are the source of empirical evidence. In principle it's possible to apply a rigorous testing regimen with manual testing, but in most cases this is (also) impractical for reasons that are different from the barriers to automated testing. In the rest of this article, I'll exclusively discuss automated testing.
We may reasonably extend the definition of legacy code to a code base without adequate testing support.
When do we have enough tests? #
What, exactly, is adequate testing support? The answer is the same as in science, overall. When do you have enough scientific evidence that a particular theory is widely accepted? There's no universal answer to that, and no, p-values less than 0.05 isn't the answer, either.
In short, adequate empirical evidence is when a hypothesis is sufficiently corroborated to be accepted. Keep in mind that science can never prove a theory correct, but performing experiments against falsifiable predictions can disprove it. This applies to software, too.
"Testing shows the presence, not the absence of bugs."
The terminology of hypothesis, corroboration, etc. may be opaque to many software developers. Here's what it means in terms of software engineering: You have unspoken and implicit hypotheses about the code you're writing. Usually, once you're done with a task, your hypothesis is that the code makes the software work as intended. Anyone who's written more than a hello-world program knows, however, that believing the code to be correct is not enough. How many times have you written code that you assumed correct, only to find that it was not?
That's the lack of knowledge that testing attempts to address. Even manual testing. A test is an experiment that produces empirical evidence. As Dijkstra quipped, passing tests don't prove the software correct, but the more passing tests we have, the more confidence we gain. At some point, the passing tests provide enough confidence that you and other stakeholders consider it sensible to release or deploy the software. We say that the failure to find failing tests corroborates our hypothesis that the software works as intended.
In the context of legacy code, it's not the absolute lack of automated tests that characterizes legacy code. Rather, it's the lack of adequate test coverage. It's that you don't have enough tests. Thus, when working with legacy code, you want to add tests after the fact.
Characterization Test recipes #
A test written after the fact against a legacy code base is called a Characterization Test, because it characterizes (i.e. describes) the behaviour of the system under test (SUT) at the time it was written. It's not a given that this behaviour is correct or desirable.
Michael Feathers gives this recipe for writing a Characterization Test:
- "Use a piece of code in a test harness.
- "Write an assertion that you know will fail.
- "Let the failure tell you what the behavior is.
- "Change the test so that it expects the behavior that the code produces.
- "Repeat."
Notice the second step: "Write an assertion that you know will fail." Why is that important? Why not write the 'correct' assertion from the outset?
The reason is the same as I outlined in Epistemology of software: It happens with surprising regularity that you inadvertently write a tautological assertion. You could also make other mistakes, but writing a failing test is a falsifiable experiment. In this case, the implied hypothesis is that the test will fail. If it does not fail, you've falsified the implied prediction. To paraphrase Dijkstra, you've proven the test wrong.
If, on the other hand, the test fails, you've failed to falsify the hypothesis. You have not proven the test correct, but you've failed in proving it wrong. Epistemologically, that's the best result you may hope for.
I'm a little uneasy about the above recipe, because it involves a step where you change the test code to pass the test. How can you know that you, without meaning to, replaced a proper assertion with a tautological assertion?
For that reason, I sometimes follow a variation of the recipe:
- Write a test that exercises the SUT, including the correct assertion you have in mind.
- Run the test to see it pass.
- Sabotage the SUT so that it fails the assertion. If there are several assertions, do this for each, one after the other.
- Run the test to see it fail.
- Revert the sabotage.
- Run the test again to see it pass.
- Repeat.
The last test run is strictly not necessary if you've been rigorous about how you revert the sabotage, but psychologically, it gives me a better sense that all is good if I can end each cycle with a green test suite.
Example #
I don't get to interact that much with legacy code, but even so, I find myself writing Characterization Tests with surprising regularity. One example was when I was characterizing the song recommendations example. If you have the Git repository that accompanies that article series, you can see that the initial setup is adding one Characterization Test after the other. Even so, as I follow a policy of not adding commits with failing tests, you can't see the details of the process leading to each commit.
Perhaps a better example can be found in the Git repository that accompanies Code That Fits in Your Head. If you own the book, you also have access to the repository. In commit d66bc89443dc10a418837c0ae5b85e06272bd12b I wrote this message:
"Remove PostOffice dependency from Controller
"Instead, the PostOffice behaviour is now the responsibility of the EmailingReservationsRepository Decorator, which is configured in Startup.
"I meticulously edited the unit tests and introduced new unit tests as necessary. All new unit tests I added by following the checklist for Characterisation Tests, including seeing all the assertions fail by temporarily editing the SUT."
Notice the last paragraph, which is quite typical for how I tend to document my process when it's otherwise invisible in the Git history. Here's a breakdown of the process.
I first created the EmailingReservationsRepository without tests. This class is a Decorator, so quite a bit of it is boilerplate code. For instance, one method looks like this:
public Task<Reservation?> ReadReservation(int restaurantId, Guid id) { return Inner.ReadReservation(restaurantId, id); }
That's usually the case with such Decorators, but then one of the methods turned out like this:
public async Task Update(int restaurantId, Reservation reservation) { if (reservation is null) throw new ArgumentNullException(nameof(reservation)); var existing = await Inner.ReadReservation(restaurantId, reservation.Id) .ConfigureAwait(false); if (existing is { } && existing.Email != reservation.Email) await PostOffice .EmailReservationUpdating(restaurantId, existing) .ConfigureAwait(false); await Inner.Update(restaurantId, reservation) .ConfigureAwait(false); await PostOffice.EmailReservationUpdated(restaurantId, reservation) .ConfigureAwait(false); }
I then realized that I should probably cover this class with some tests after all, which I then proceeded to do in the above commit.
Consider one of the state-based Characterisation Tests I added to cover the Update method.
[Theory] [InlineData(32, "David")] [InlineData(58, "Robert")] [InlineData(58, "Jones")] public async Task UpdateSendsEmail(int restaurantId, string newName) { var postOffice = new SpyPostOffice(); var existing = Some.Reservation; var db = new FakeDatabase(); await db.Create(restaurantId, existing); var sut = new EmailingReservationsRepository(postOffice, db); var updated = existing.WithName(new Name(newName)); await sut.Update(restaurantId, updated); var expected = new SpyPostOffice.Observation( SpyPostOffice.Event.Updated, restaurantId, updated); Assert.Contains(updated, db[restaurantId]); Assert.Contains(expected, postOffice); Assert.DoesNotContain( postOffice, o => o.Event == SpyPostOffice.Event.Updating); }
This test immediately passed when I added it, so I had to sabotage the Update method to see the assertions fail. Since there are three assertions, I had to sabotage the SUT in three different ways.
To see the first assertion fail, the most obvious sabotage was to simply comment out or delete the delegation to Inner.Update:
//await Inner.Update(restaurantId, reservation) // .ConfigureAwait(false);
This caused the first assertion to fail. I was sure to actually look at the error message and follow the link to the test failure to make sure that it was, indeed, that assertion that was failing, and not something else. Once I had that verified, I undid the sabotage.
With the SUT back to unedited state, it was time to sabotage the second assertion. Just like FakeDatabase inherits from ConcurrentDictionary, SpyPostOffice inherits from Collection, which means that the assertion can simply verify whether the postOffice contains the expected observation. Sabotaging that part was as easy as the first one:
//await PostOffice.EmailReservationUpdated(restaurantId, reservation) // .ConfigureAwait(false);
The test failed, but again I meticulously verified that the error was the expected error at the expected line. Once I'd done that, I again reverted the SUT to its virgin state, and ran the test to verify that all tests passed.
The last assertion is a bit different, because it checks that no Updating message is being sent. This should only happen if the user updates the reservation by changing his or her email address. In that case, but only in that case, should the system send an Updating message to the old address, and an Updated message to the new address. There's a separate test for that, but as it follows the same overall template as the one shown here, I'm not showing it. You can see it in the Git repository.
Here's how to sabotage the SUT to see the third assertion fail:
if (existing is { } /*&& existing.Email != reservation.Email*/) await PostOffice .EmailReservationUpdating(restaurantId, existing) .ConfigureAwait(false);
It's enough to comment out (or delete) the second Boolean check to fail the assertion. Again, I made sure to check that the test failed on the exact line of the third assertion. Once I'd made sure of that, I undid the change, ran the tests again, and committed the changes.
Conclusion #
When working with automated tests, a classic conundrum is that you're writing code to test some other code. How do you know that the test code is correct? After all, you're writing test code because you don't trust your abilities to produce perfect production code. The way out of that quandary is to first predict that the test will fail and run that experiment. If you haven't touched the production code, but the test passes, odds are that there's something wrong with the test.
When you are adding tests to an existing code base, you can't perform that experiment without jumping through some hoops. After all, the behaviour you want to observe is already implemented. You must therefore either write a variation of a test that deliberately fails (as Michael Feathers recommends), or temporarily sabotage the system under test so that you can verify that the new test fails as expected.
The example shows how to proceed empirically with a Characterisation Test of a C# class that I'd earlier added without tests. Perhaps, however, I should have rather approached the situation in another way.
Empirical test-after development
A few techniques for situations where TDD is impractical.
In Epistemology of software I described how test-driven development (TDD) is a scientific approach to software development. By running tests, we conduct falsifiable experiments to gather empirical evidence that corroborate our hypothesis about the software we're developing.
TDD is, in my experience, the most effective way to deliver useful software within reasonable time frames. Even so, I also understand that there are situations where TDD is impractical. I can think of a few overall categories where this is the case, but undoubtedly, there are more than those I enumerate in this article.
Not all is lost in those cases. What do you do when TDD seems impractical? The key is to understand how empirical methods work. How do you gather evidence that corroborates your hypotheses? In subsequent articles, I'll share some techniques that I've found useful.
Each of these articles will contain tips and examples that apply in those situations where TDD is impractical. Most of the ideas and techniques I've learned from other people, and I'll be as diligent as possible to cite sources of inspiration.
Epistemology of software
How do you know that your code works?
In 2023 I gave a conference keynote titled Epistemology of software, a recording of which is available on YouTube. In it, I try to answer the question: How do we know that software works?
The keynote was for a mixed audience with some technical, but also a big contingent of non-technical, software people, so I took a long detour around general epistemology, and particularly the philosophy of science as it pertains to empirical science. Towards the end of the presentation, I returned to the epistemology of software in particular. While I recommend that you watch the recording for a broader perspective, I want to reiterate the points about software development here. Personally, I like prose better than video when it comes to succinctly present and preserve ideas.
How do we know anything? #
In philosophy of science it's long been an established truth that we can't know anything with certainty. We can only edge asymptotically closer to what we believe is the 'truth'. The most effective method for that is the 'scientific method', which grossly simplified is an iterative process of forming hypotheses, making predictions, performing experiments, and corroborating or falsifying predictions. When experiments don't quite turn out as predicted, you may adjust your hypothesis accordingly.
An example, however, may still be useful to set the stage. Consider Galilei's idea of dropping a small and a big ball from the Leaning Tower of Pisa. The prediction is that two objects of different mass will hit the ground simultaneously, if dropped from the same height simultaneously. This experiment have been carried out multiple times, even in vacuum chambers.
Even so, thousands of experiments do not constitute proof that two objects fall with the same acceleration. The experiments only make it exceedingly likely that this is so.
What happens if you apply scientific thinking to software development?
Empirical epistemology of software #
Put yourself in the shoes of a non-coding product owner. He or she needs an application to solve a particular problem. How does he or she know when that goal has been reached?
Ultimately, he or she can only do what any scientist can do: Form hypotheses, make predictions, and perform experiments. Sometimes product owners assign these jobs to other people, but so do scientists.
Testing can be ad-hoc or planned, automated or manual, thorough or cursory, but it's really the only way a product owner can determine whether or not the software works.
When I started as a software developer, testing was often the purview of a dedicated testing department. The test manager would oversee the production of a test plan, which was a written document that manual testers were supposed to follow. Even so, this, too, is an empirical approach to software verification. Each test essentially implies a hypothesis: If we perform these steps, the application will behave in this particular, observable manner.
For an application designed for human interaction, letting a real human tester interact with it may be the most realistic test scenario, but human testers are slow. They also tend to make mistakes. The twentieth time they run through the same test scenario, they are likely to overlook details.
If you want to perform faster, and more reliable, tests, you may wish to automated the tests. You could, for example, write code that executes a test plan. This, however, raises another problem: If tests are also code, how do we know that the tests contain no bugs?
The scientific method of software #
How about using the the scientific method? Even more specifically, proceed by making incremental falsifiable predictions about the code you write.
For instance, write a single automated test without accompanying production code:
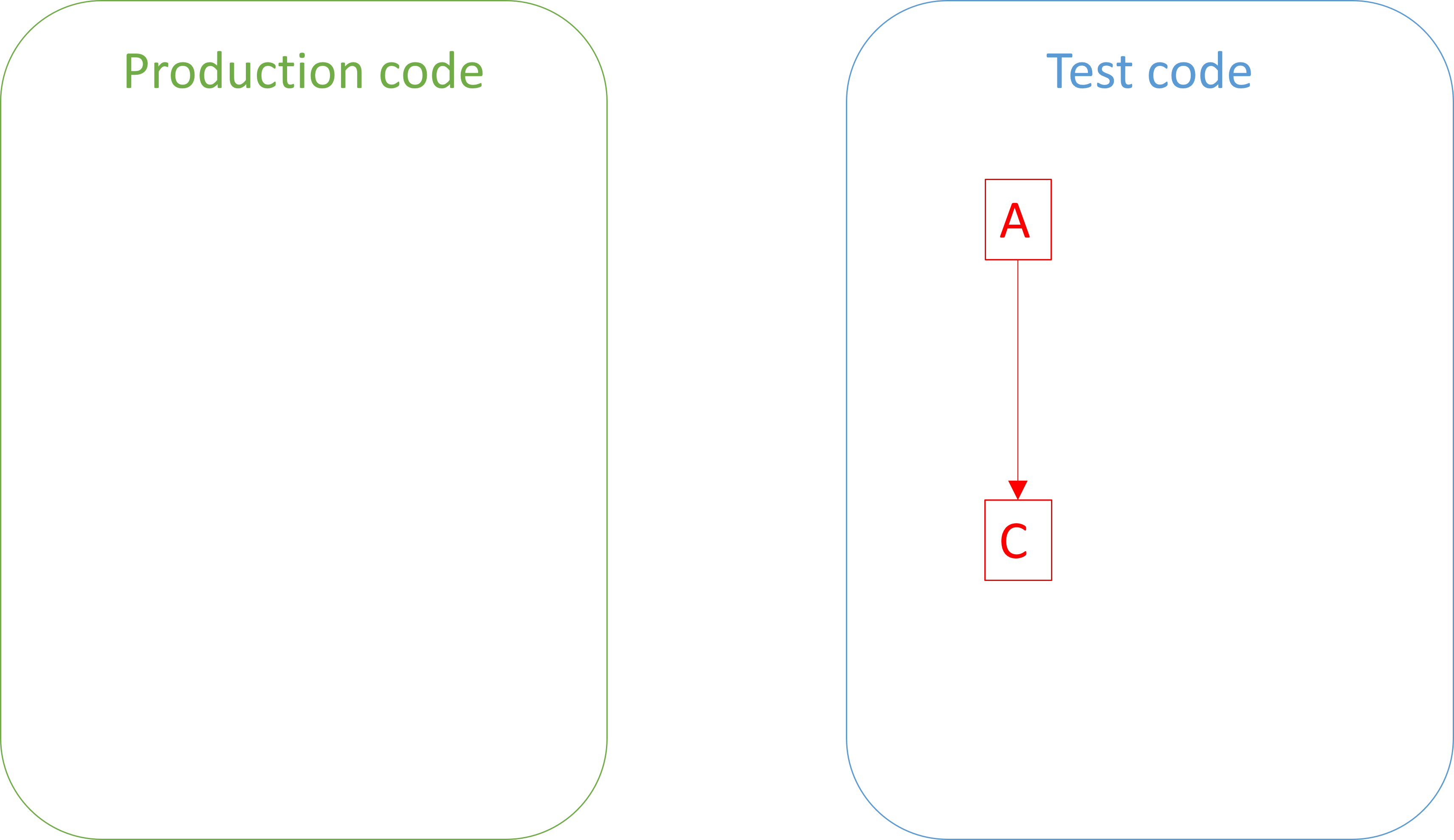
Before you run the test code, you make a prediction based on the implicit hypothesis formulated by the red-green-refactor checklist: If this test runs, it will fail.
This is a falsifiable prediction. While you expect the test to fail, it may succeed if, for example, you've inadvertently written a tautological assertion. In other words, if your prediction is falsified, you know that the test code is somehow wrong. On the other hand, if the test fails (as predicted), you've failed to falsify your prediction. As empirical science goes, this is the best you can hope for. It doesn't prove that the test is correct, but corroborates the hypothesis that it is.
The next step in the red-green-refactor cycle is to write just enough code to pass the test. You do that, and before rerunning the test implicitly formulate the opposite hypothesis: If this test runs, it will succeed.
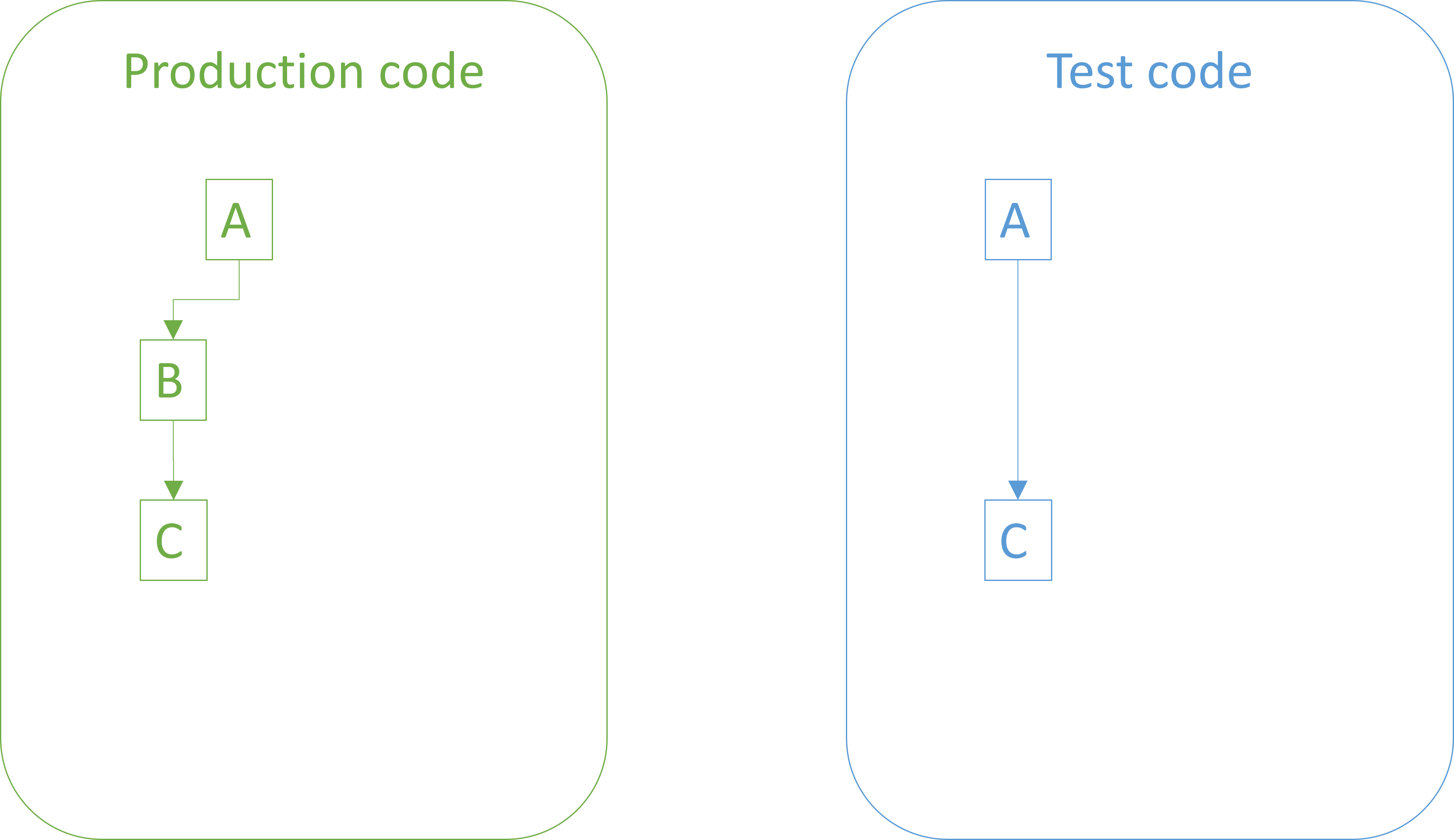
This, again, is a falsifiable prediction. If, despite expectations, the test fails, you know that something is wrong. Most likely, it's the implementation that you just wrote, but it could also be the test which, after all, is somehow defective. Or perhaps a circuit in your computer was struck by a cosmic ray. On the other hand, if the test passes, you've failed to falsify your prediction, which is the best you can hope for.
You now write a second test, which comes with the implicit falsifiable prediction: If I run all tests, the new test will fail.
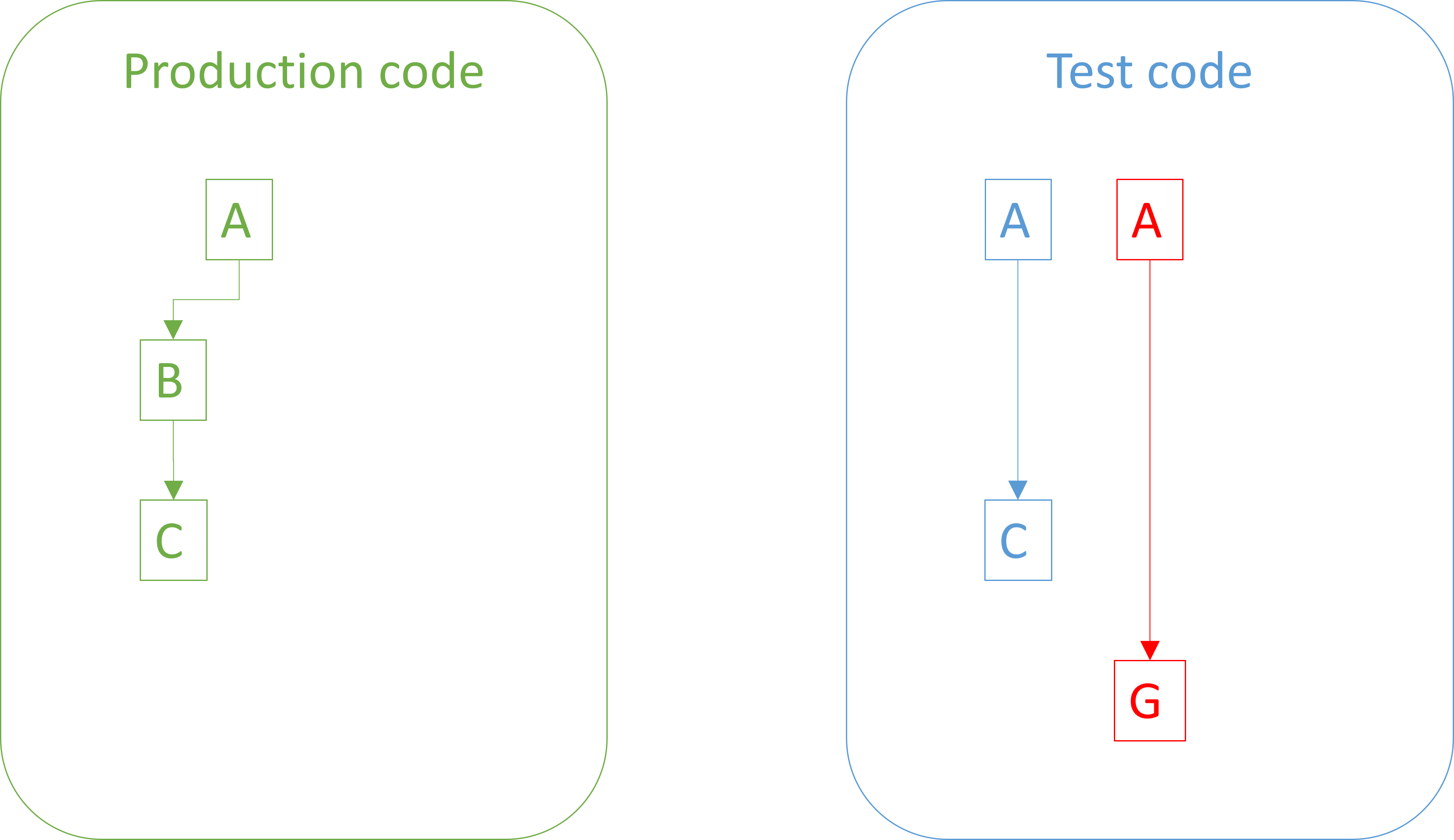
The process repeats. A succeeding test falsifies the prediction, while a failing test only corroborates the hypothesis.
Again, implement just enough code for the hypothesis that if you run all tests, they will pass.
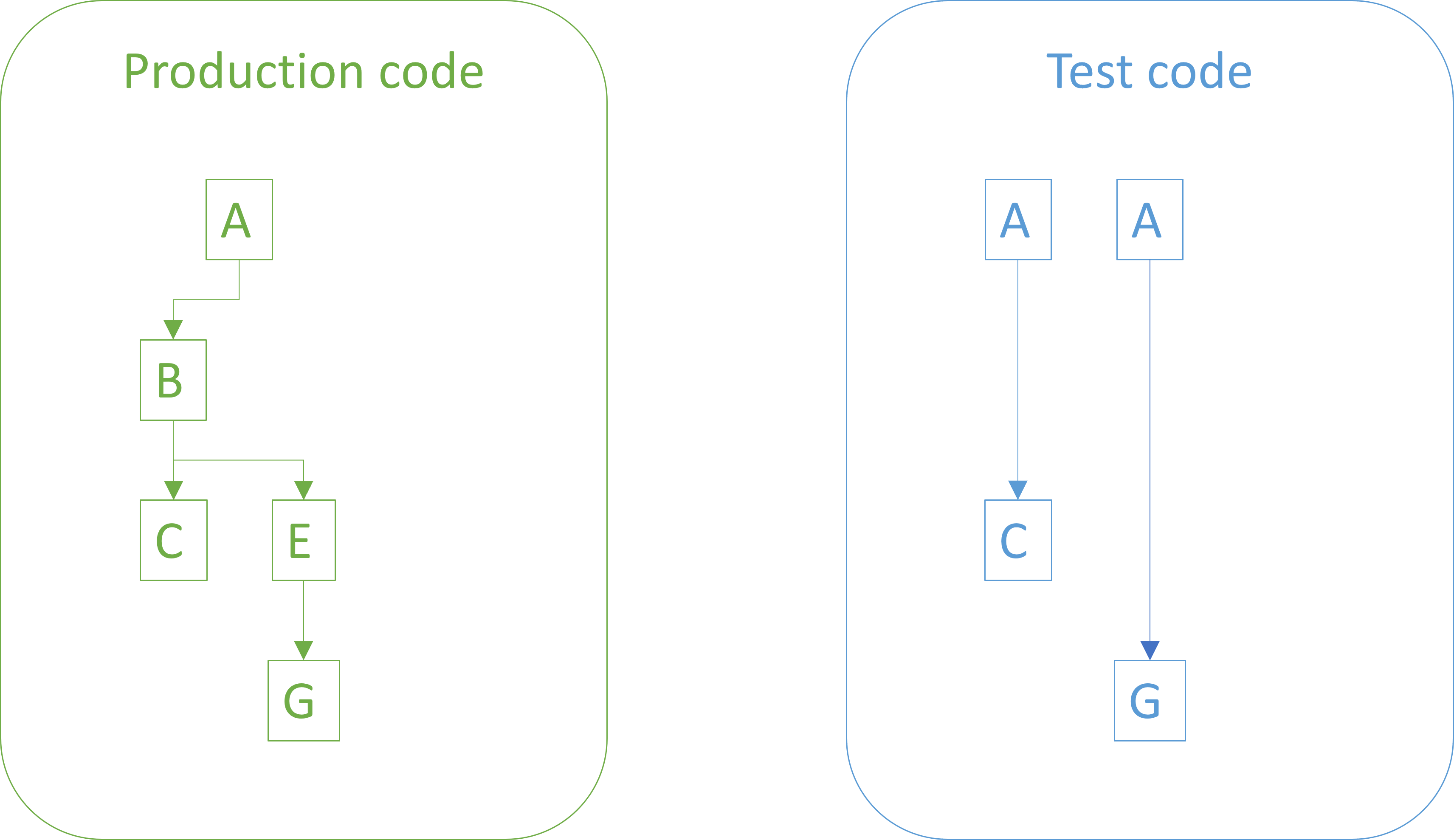
If this hypothesis, too, is corroborated (i.e. you failed to falsify it), you move on until you believe that you're done.
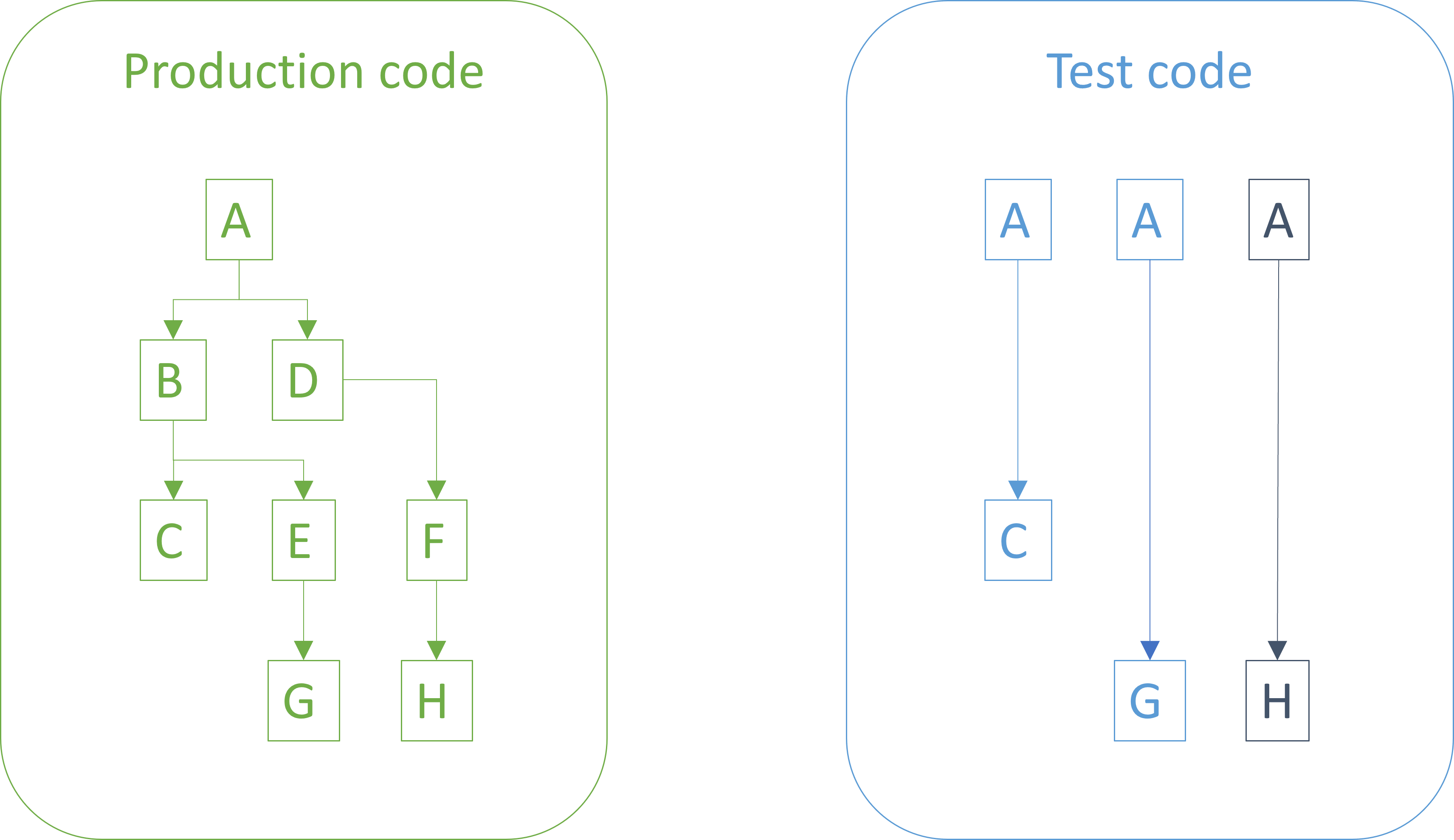
As this process proceeds, you corroborate two related hypotheses: That the test code is correct, and that the production code is. None of these hypotheses are ever proven, but as you add tests that are first red, then green, and then stay green, you increase confidence that the entire code complex works as intended.
If you don't write the test first, you don't get to perform the first experiment: That you predict the new test to fail. If you don't do that, you collect no empirical evidence that the tests work as hypothesized. In other words, you'd lose half of the scientific evidence you otherwise could have gathered.
TDD is the scientific method #
Let me spell this out: Test-driven development (TDD) is an example of the scientific method. Watching a new test fail is an important part of the process. Without it, you have no empirical reason to believe that the tests are correct.
While you may read the test code, that only puts you on the same scientific footing as the ancient Greeks' introspective philosophy: The four humours, extramission, the elements, etc. By reading test code, or even writing it, you may believe that you understand what the code does, but reading it without running it gives you no empirical way to verify whether that belief is correct.
Consider: How many times have you written code that you believed was correct, but turned out contained errors?
If you write the test after the system under test (SUT), you can run the test to see it pass, but consider what you can only falsify in that case: If the test passes, you've learned little. It may be that the test exercises the SUT, but it may also be that you've written a tautological assertion. It may also be that you've faithfully captured a bug in the production code, and now preserved in for eternity as something that looks like a regression test. Or perhaps the test doesn't even cover the code path that you believe it covers.
Conversely, if such a test (that you believe to be correct) fails, you're also in the dark. Was the test wrong, after all? Or does the SUT have a defect?
This is the reason that the process for writing Characterization Tests includes a step where you
"Write an assertion that you know will fail."
I prefer a variation where I write what I believe is the correct assertion, but then temporarily sabotage the SUT to fail the assertion. The important part is to see the test fail, because the failure to falsify a strong prediction is important empirical evidence.
Conclusion #
How do we know that the software we develop works as intended? The answer lies in the much larger question: How do we know anything?
Scientific thinking effectively answers this by 'the scientific method': Form a hypothesis, make falsifiable predictions, perform experiments, adjust, repeat.
We can subject software to the same rigorous regimen that scientists do: Hypothesize that the software works in certain ways under given conditions, predict observable behaviour, test, record outcomes, fix defects, repeat.
Test-driven development closely follows that process, so is a highly scientific methodology for developing software. It should be noted that science is hard, and so is TDD. Still, if you care that your software behaves as it's supposed to, it's one of the most rigorous and effective processes I'm aware of.
Result isomorphism
Result types are roughly equivalent to exceptions.
This article is part of a a series about software design isomorphisms, although naming this one an isomorphism is a stretch. A real isomorphism is when a lossless translation exists between two or more different representations. This article series has already shown a few examples that fit the definition better than what the present article will manage.
The reader, I hope, will bear with me. The overall series of software design isomorphisms establishes a theme, and even when a topic doesn't fit the definition to a T, I find that it harmonizes well enough that it still belongs.
In short, the claim made here is that 'Result' (or Either) types are equivalent to exceptions.
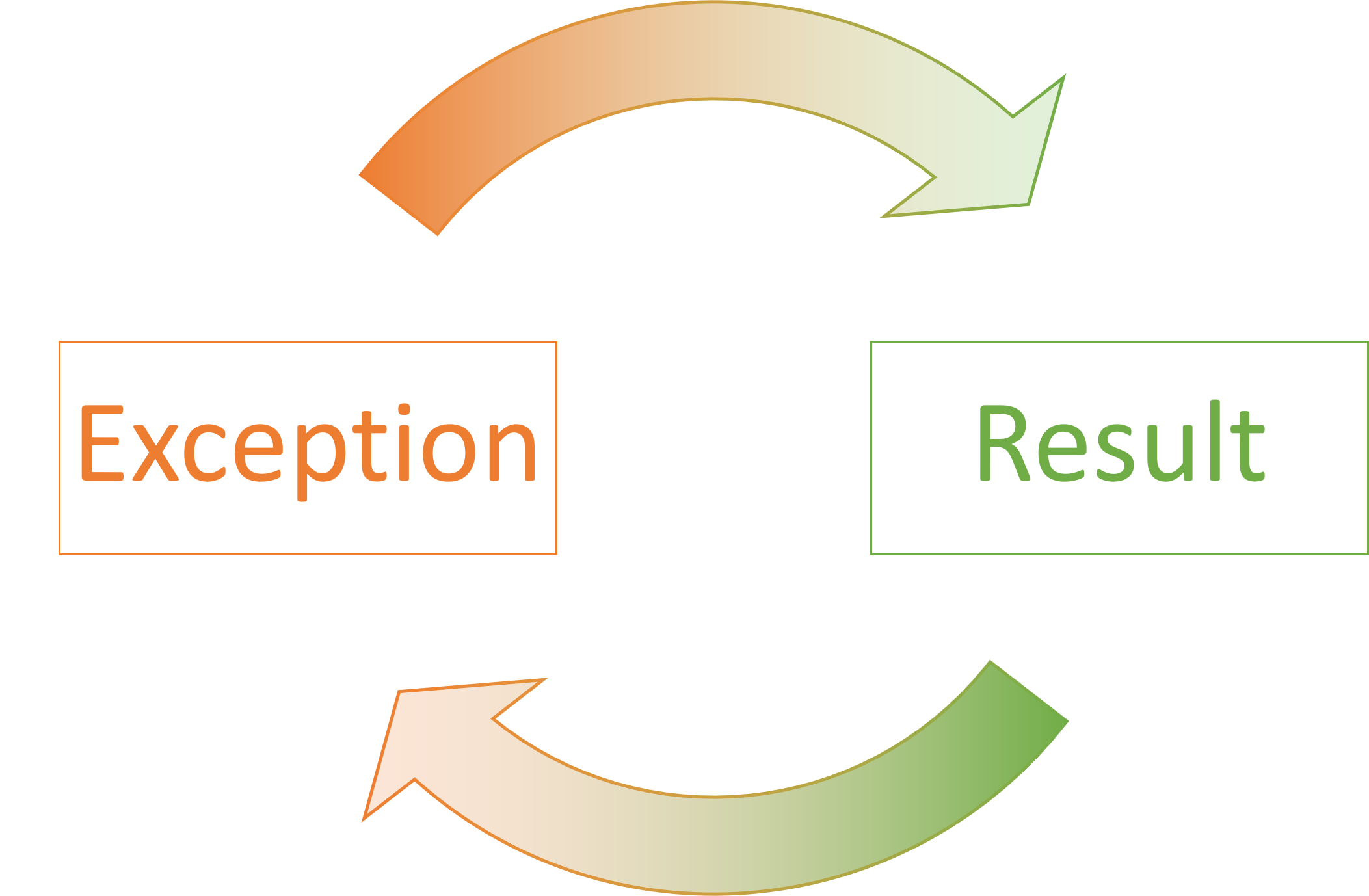
I've deliberately drawn the arrows in such a way that they fade or wash out as they approach their target. My intent is to suggest that there is some loss of information. We may consider exceptions and result types to be roughly equivalent, but they do, in general, have different semantics. The exact semantics are language-dependent, but most languages tend to align with each other when it comes to exceptions. If they have exceptions at all.
Checked exceptions #
As far as I'm aware, the language where exceptions and results are most similar may be Java, which has checked exceptions. This means that a method may declare that it throws certain exceptions. Any callers must either handle all declared exceptions, or rethrow them, thereby transitively declare to their callers that they must expect certain exceptions to be thrown.
Imagine, for example, that you want to create a library of basic statistical calculations. You may start out with this variation of mean:
public double mean(double[] values) { if (values == null || values.length == 0) { throw new IllegalArgumentException( "The parameter 'values' must not be null or empty."); } double sum = 0; for (double value : values) { sum += value; } return sum / values.length; }
Since it's impossible to calculate the mean for an empty data set, this method throws an exception. If we had omitted the Guard Clause, the method would have returned NaN, a questionable language design choice, if you ask me.
One would think that you could add throws IllegalArgumentException to the method declaration in order to force callers to deal with the problem, but alas, IllegalArgumentException is a RuntimeException, so no caller is forced to deal with this exception, after all.
Purely for the sake of argument, we may introduce a special StatisticsException class as a checked exception, and change the mean method to this variation:
public static double mean(double[] values) throws StatisticsException { if (values == null || values.length == 0) { throw new StatisticsException( "The parameter 'values' must not be null or empty."); } double sum = 0; for (double value : values) { sum += value; } return sum / values.length; }
Since the new StatisticsException class is a checked exception, callers must handle that exception, or declare that they themselves throw that exception type. Even unit tests have to do that:
@Test void meanOfOneValueIsTheValueItself() throws StatisticsException { double actual = Statistics.mean(new double[] { 42.0 }); assertEquals(42.0, actual); }
Instead of 'rethrowing' checked exceptions, you may also handle them, if you can.
Handling checked exceptions #
If you have a sensible way to deal with error values, you may handle checked exceptions. Let's assume, mostly to have an example to look at, that we also need a function to calculate the empirical variance of a data set. Furthermore, for the sole benefit of the example, let's handwave and say that if the data set is empty, this means that the variance is zero. (I do understand that that's not how variance is defined, but work with me: It's only for the sake of the example.)
public static double variance(double[] values) { try { double mean = mean(values); double sumOfSquares = 0; for (double value : values) { double deviation = value - mean; sumOfSquares += deviation * deviation; } return sumOfSquares / values.length; } catch (StatisticsException e) { return 0; } }
Since the variance function handles StatisticsExceptions in a try/catch construction, the function doesn't throw that exception, and therefore doesn't have to declare that it throws anything. To belabour the obvious: The method is not adorned with any throws StatisticsException declaration.
Refactoring to Result values #
The claim in this article is that throwing exceptions is sufficiently equivalent to returning Result values that it warrants investigation. As far as I can tell, Java doesn't come with any built-in Result type (and neither does C#), mostly, it seems, because Result values seem rather redundant in a language with checked exceptions.
Still, imagine that we define a Church-encoded Either, but call it Result<Succ, Fail>. You can now refactor mean to return a Result value:
public static Result<Double, StatisticsException> mean(double[] values) { if (values == null || values.length == 0) { return Result.failure(new StatisticsException( "The parameter 'values' must not be null or empty.")); } double sum = 0; for (double value : values) { sum += value; } return Result.success(sum / values.length); }
In order to make the change as understandable as possible, I've only changed the function to return a Result value, while most other design choices remain as before. Particularly, the failure case contains StatisticsException, although as a general rule, I'd consider that an anti-pattern: You're better off using exceptions if exceptions are what you are dealing with.
That said, the above variation of mean no longer has to declare that it throws StatisticsException, because it implicitly does that by its static return type.
Furthermore, variance can still handle both success and failure cases with match:
public static double variance(double[] values) { return mean(values).match( mean -> { double sumOfSquares = 0; for (double value : values) { double deviation = value - mean; sumOfSquares += deviation * deviation; } return sumOfSquares / values.length; }, error -> 0.0 ); }
Just like try/catch enables you to 'escape' having to propagate a checked exception, match allows you to handle both cases of a sum type in order to instead return an 'unwrapped' value, like a double.
Not a true isomorphism #
Some languages (e.g. F# and Haskell) already have built-in Result types (although they may instead be called Either). In other languages, you can either find a reusable library that provides such a type, or you can add one yourself.
Once you have a Result type, you can always refactor exception-throwing code to Result-returning code. This applies even if the language in question doesn't have checked exceptions. In fact, I've mostly performed this manoeuvre in C#, which doesn't have checked exceptions.
Most mainstream languages also support exceptions, so if you have a Result-valued method, you can also refactor the 'other way'. For the above statistics example, you simply read the examples from bottom toward the top.
Because it's possible to go back and forth like that, this relationship looks like a software design isomorphism. It's not quite, however, since information is lost in both directions.
When you refactor from throwing an exception to returning a Result value, you lose the stack trace embedded in the exception. Additionally, languages that support exceptions have very specific semantics for that language construct. Specifically, an unhandled exception crashes its program, and although this may look catastrophic, it usually happens in an orderly way. The compiler or language runtime makes sure that the process exits with a proper error code. Usually, an unhandled exception is communicated to the operating system, which logs the error, including the stack trace. All of this happens automatically.
As Eirik Tsarpalis points out, you lose all of this 'convenience' if you instead use Result values. A Result is just another data structure, and the semantics associated with failure cases are entirely your responsibility. If you need an 'unhandled' failure case to crash the program, you must explicitly write code to make the program return an error code to the operating system.
So why would you ever want to use Result types? Because you also, typically, lose information going from Result-valued operations to throwing exceptions.
Most importantly, you lose static type information about error conditions. Java is the odd man out in this respect, since checked exceptions actually do statically advertise to callers the error cases with which they must deal. Even so, in the first example, above, IllegalArgumentException is not part of the statically-typed method signature, since IllegalArgumentException is not a checked exception. Consequently, I had to invent the custom StatisticsException to make the example work. Other languages don't support checked exceptions, so there, a compiler or static analyser can't help you identify whether or not you've dealt with all error cases.
Thus, in statically typed languages, a Result value contains information about error cases. A compiler or static analyser can check whether you've dealt with all possible errors. If you refactor to throwing exceptions, this information is lost.
The bottom line is that you can refactor from exceptions to Results, or from Results to exceptions. As far as I can tell, these refactorings are always possible, but you gain and lose some capabilities in both directions.
Other languages #
So far, I've only shown a single example in Java. You can, however, easily do the same exercise in other languages that support exceptions. My article Non-exceptional averages goes over some of the same ground in C#, and Conservative codomain conjecture expands on the average example in both C# and F#.
You can even implement Result types in Python; the reusable library returns, for example, comes with Maybe and Result. Given that Python is fundamentally dynamically typed, however, I'm not sure I'm convinced of the utility of that.
At the other extreme, Haskell idiomatically uses Either for most error handling. Even so, the language also has exceptions, and even if some may think that they're mostly present for historical reasons, they're still used in modern Haskell code to model predictable errors that you probably can't handle, such as various IO-related problems: The file is gone, the network is down, the database is not responding, etc.
Finally, we should note that the similarity between exceptions and Result values depends on the language in question. Some languages don't support parametric polymorphism (AKA generics), and while I haven't tried, I'd expect the utility of Result values to be limited in those cases. On the other hand, some languages don't have exceptions, C being perhaps the most notable example.
Conclusion #
All programs can fail. Over the decades, various languages have had different approaches to error handling. Exceptions, including mechanisms for throwing and catching them, is perhaps the most common. Another strategy is to rely on Result values. In their given contexts, each offer benefits and drawbacks.
In many languages, you have a choice of both. In Haskell, Results (Either) is the idiomatic solution, but exceptions are still possible. In C-like languages, ironically, exceptions are the norm, but in many (like Java and C#) you can bolt on Results if you so decide, although it's likely to alienate some developers. In a language like F#, both options are present at an almost equal proportion. I'd consider it idiomatic to use Result in 'native' F# code, while when interoperating with the rest of the .NET ecosystem (which is almost exclusively written in C#) it may be more prudent to just stick to exceptions.
In those languages where you have both options, you can go back and forth between exceptions and Result values. Since you can refactor both ways, this relationship looks like a software design isomorphism. It isn't, though. There are differences in language semantics between the two, so a choice of one or the other has consequences. Recall, however, as Sartre said, not making a choice is also making a choice.
Next: Builder isomorphisms.
Comments
Thank you for the article — an interesting perspective on comparing exceptions and the Result pattern. I recently wrote an article where I explored specific scenarios in which the Result pattern offers advantages over exceptions, and vice versa. Exception Handling in .NET I’d be very interested to hear your thoughts on it.
Thank you for writing. Proper exception-throwing and -handling is indeed complicated, and I can tell from your article that you've seen many of the same antipatterns and much of the same cargo-cult programming that I have. Clearly, there's a need for content such as your article to educate people on better modelling of errors.

Comments
What are your thoughts on abstractions in test code? I have never found it necessary, but have at times been tempted to create abstractions in my test projects that themselves would require testing. This is usually only a consideration in projects with a complex test setup or very large test suites.
I am also curious about your thoughts on adding additional logic to the implementation code with the sole purpose of making it easier to test. As an example: Adding a method to a class that makes it a more complete abstraction, but that method is never called in production code.
My own opinion is split between keeping tests readable and potentially easier to maintain by using reusable abstractions, and keeping them simple and robust.
Thank you for writing. Regarding abstractions in test code, the answer depends on how you define the term abstraction. I find Robert C. Martin's definition useful.
Using this definition, I have no objection to adding abstractions to test code if necessary, but as you imply, if the test code is simple enough, it may not be necessary. You could consider Test Data Builders, custom assertions, setup methods, etc. as test-specific abstractions. But again, if you simplify the System Under Test (SUT) by making data immutable, you don't need Test Data Builders either, so I agree that the need for substantial test abstractions may be a smell indicating that the SUT is too complicated.
Regarding your other question, I try to avoid APIs that exist exclusively to support testing, but even so, I think you can subcategorize doing that into a few buckets. Adding new methods or constructors that exist only to be called from unit tests? I don't do that, although you could argue that Constructor Injection is just that: Dependency Injection is often introduced to support testing, but it's also applicable in production code. The constructor that receives dependencies is also used to compose the production application.
Additionally, people often ask whether it's okay to make
internalorprivatemethodspublicso that it's possible to test them. In a code base created with test-driven development, this shouldn't be necessary, but again, if you have a legacy code base, other rules apply.Another category of code that may at first spring into existence to support testing is what we may term inspection APIs. This could be a read-only property or field accessor that you can query in order to make an assertion. You may also decide to give an composite value structural equality to improve testing. Or, in property-based testing, you may use the There and back again technique, where one of the directions isn't entirely required. For example, if I were to repeat the Roman Numerals kata with property-based testing today, I'd add a 'formatter' or 'serializer', so that I could take any normal integer, format it as a Roman numeral, and then parse it again. This is quite common when testing parsers and the like. You could argue that the formatter isn't strictly required for the job, but it makes testing easier, and usually turns out to be handy in its own right.
This tends to be a generalizable observation. A test is the first client of the SUT, so if a test needs a capability, it's likely that other client code might find that capability useful, too. It happens that I write a bit of test-helper code that I eventually decide to move to the production code base for that reason.